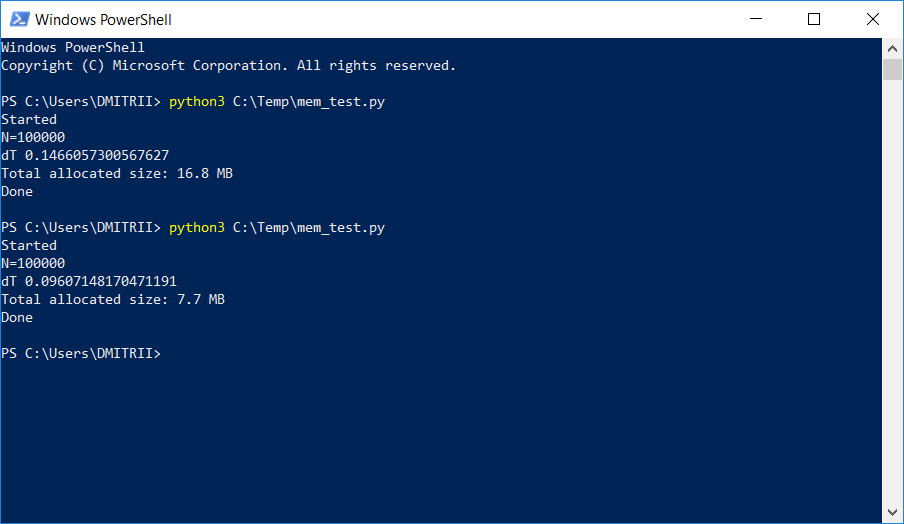
かなり大きな動的リストを保存および処理する必要があるプロジェクトの1つで、テスターはメモリ不足について不平を言い始めました。 コードを1行だけ追加することで、「小さな血」の問題を解決する簡単な方法を以下に説明します。 写真の結果:
それがどのように機能するか、カットの下で続けられました。
簡単な「トレーニング」の例を考えてみましょう-名前、年齢、住所など、
class DataItem(object): def __init__(self, name, age, address): self.name = name self.age = age self.address = address
「子供」の問題は、そのようなオブジェクトがメモリをどれだけ使用するかということです。
額で解決策を試してみましょう。
d1 = DataItem("Alex", 42, "-") print ("sys.getsizeof(d1):", sys.getsizeof(d1))
56バイトの応答が返されます。 少し、かなり満足しているようです。
ただし、さらにデータがある別のオブジェクトをチェックします。
d2 = DataItem("Boris", 24, "In the middle of nowhere") print ("sys.getsizeof(d2):", sys.getsizeof(d2))
答えは再び56です。この時点で、私たちは何かがここに正しくなく、すべてが一見したように単純であるとは限らないことを理解します。
直観は私たちを失敗させません、そして、すべては本当にそれほど単純ではありません。 Pythonは動的型付けを備えた非常に柔軟な言語であり、その作業のために、多くの追加データを格納します。 それ自体が多くを占めます。 例として、sys.getsizeof( "")は33を返します-はい、空行ごとに最大33バイトです! また、sys.getsizeof(1)は、整数に対して24〜24バイトを返します(Cプログラマーに、画面から離れて、さらに読むことはせず、美しいものへの信頼を失わないように依頼します)。 辞書などのより複雑な要素の場合、sys.getsizeof(dict())は272バイトを返します-これは空の辞書用です。 私はこれ以上続けません。原理が明確で
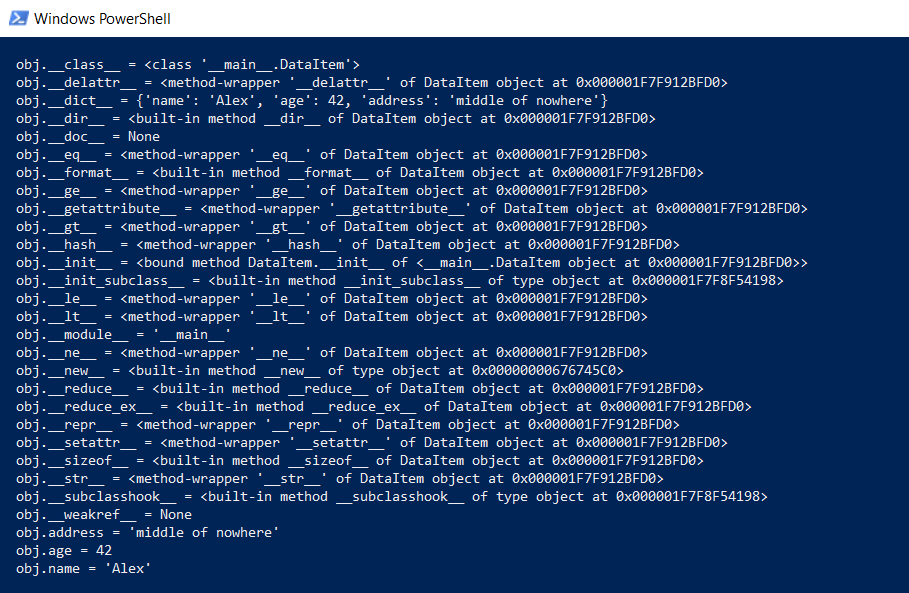
しかし、DataItemクラスと「子」の質問に戻ります。 そのようなクラスはどれくらいの時間メモリを使用しますか? まず、クラスのコンテンツ全体を下位レベルで表示します。
def dump(obj): for attr in dir(obj): print(" obj.%s = %r" % (attr, getattr(obj, attr)))
この関数は、「フードの下」に隠されているものを表示するため、すべてのPython関数(入力、継承、およびその他の機能)が機能します。
結果は印象的です:
全体としてどれくらいかかりますか? githubには、実際のデータ量を計算する関数があり、すべてのオブジェクトに対して再帰的にgetsizeofを呼び出していました。
def get_size(obj, seen=None): # From https://goshippo.com/blog/measure-real-size-any-python-object/ # Recursively finds size of objects size = sys.getsizeof(obj) if seen is None: seen = set() obj_id = id(obj) if obj_id in seen: return 0 # Important mark as seen *before* entering recursion to gracefully handle # self-referential objects seen.add(obj_id) if isinstance(obj, dict): size += sum([get_size(v, seen) for v in obj.values()]) size += sum([get_size(k, seen) for k in obj.keys()]) elif hasattr(obj, '__dict__'): size += get_size(obj.__dict__, seen) elif hasattr(obj, '__iter__') and not isinstance(obj, (str, bytes, bytearray)): size += sum([get_size(i, seen) for i in obj]) return size
やってみます:
d1 = DataItem("Alex", 42, "-") print ("get_size(d1):", get_size(d1)) d2 = DataItem("Boris", 24, "In the middle of nowhere") print ("get_size(d2):", get_size(d2))
それぞれ460バイトと484バイトを取得しますが、これはより真実に近いものです。
この機能を使用すると、多くの実験を実行できます。 たとえば、DataItem構造体をリストに入れると、どのくらいのスペースデータが占有されるのだろうかと思います。 get_size([d1])関数は532バイトを返します-明らかに、これらは同じ460 +いくらかのオーバーヘッドです。 ただし、get_size([d1、d2])は863バイトを返します(460 + 484未満)。 さらに興味深いのは、get_size([d1、d2、d1])の結果です-871バイト、もう少し、つまり Pythonは、同じオブジェクトにメモリを2回割り当てないほど賢いです。
次に、質問の2番目の部分に移ります。メモリ消費を削減することは可能ですか? はい、できます。 Pythonはインタープリターであり、たとえば新しいフィールドを追加するなど、いつでもクラスを拡張できます。
d1 = DataItem("Alex", 42, "-") print ("get_size(d1):", get_size(d1)) d1.weight = 66 print ("get_size(d1):", get_size(d1))
これはすばらしいことですが、この機能が必要ない場合は、__ slots__ディレクティブを使用してインタープリターにクラスオブジェクトを強制的にリストさせることができます。
class DataItem(object): __slots__ = ['name', 'age', 'address'] def __init__(self, name, age, address): self.name = name self.age = age self.address = address
詳細については、ドキュメント(RTFM)を参照してください。「__ slots__を使用すると、明示的にデータメンバー(プロパティなど)を宣言でき、__ dict__および__weakref__の作成を拒否できます 。
チェック:はい、本当に重要です。get_size(d1)は... 460ではなく64バイトを返します。 7倍少ない。 おまけとして、オブジェクトは約20%速く作成されます(記事の最初のスクリーンショットを参照)。
残念ながら、実際の使用では、メモリのこのような大きな増加は他のオーバーヘッドによるものではありません。 要素を追加するだけで100,000の配列を作成し、メモリ消費量を確認してみましょう。
data = [] for p in range(100000): data.append(DataItem("Alex", 42, "middle of nowhere")) snapshot = tracemalloc.take_snapshot() top_stats = snapshot.statistics('lineno') total = sum(stat.size for stat in top_stats) print("Total allocated size: %.1f MB" % (total / (1024*1024)))
__slots__なしで16.8 MBあり、_slots__なしで6.9 MBです。 もちろん7回ではありませんが、コードの変更が最小限であることを考えると、非常にうまくいきます。
今、欠点について。 __slots__をアクティブにすると、__ dict__を含むすべての要素の作成が禁止されます。これは、たとえば、構造をjsonに変換するコードが機能しないことを意味します。
def toJSON(self): return json.dumps(self.__dict__)
ただし、修正は簡単です。プログラムでディクショナリを生成し、ループ内のすべての要素をソートします。
def toJSON(self): data = dict() for var in self.__slots__: data[var] = getattr(self, var) return json.dumps(data)
また、クラスに新しい変数を動的に追加することもできませんが、私の場合、これは必要ありませんでした。
そして今日の最後のテスト。 プログラム全体がどれだけのメモリを消費するかを見るのは興味深いです。 プログラムが終了しないようにプログラムの最後に無限ループを追加し、Windowsタスクマネージャーでメモリ消費を確認します。
__slots__なし:
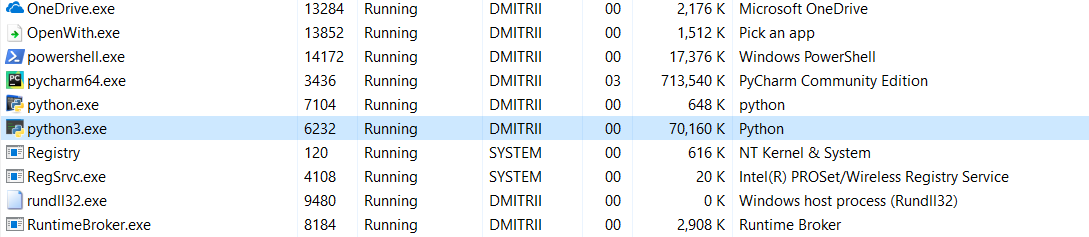
16.8MBはなんとか奇跡的に(編集-以下の奇跡の説明)70MBになりました(Cプログラマーがまだ画面に戻っていないことを望みますか?)
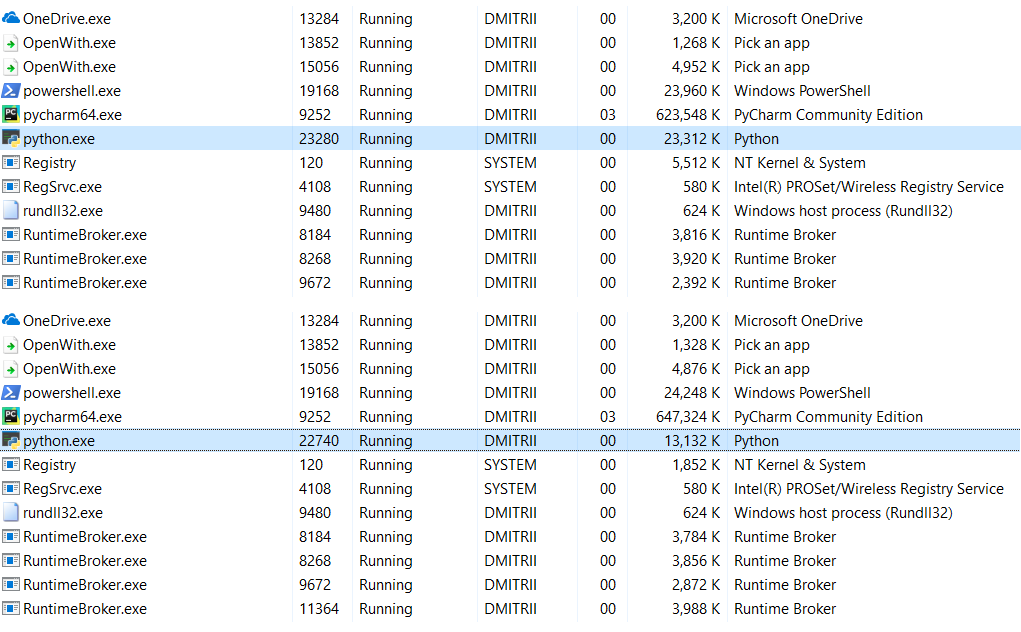
__slots__を有効にした場合:

6.9MBが27MBに変わりました...結局、メモリを節約しました。70行ではなく27MBでも、1行のコードを追加した結果としてそれほど悪くはありません。
編集 :コメント(テストのためにrobert_ayrapetyanに感謝)で、彼らはtracemallocデバッグライブラリの使用が多くの追加のメモリを占有することを示唆しました。 どうやら、作成された各オブジェクトに追加の要素を追加します。 これをオフにすると、合計メモリ消費量ははるかに少なくなります。スクリーンショットには2つのオプションが表示されます。
さらにメモリを節約する必要がある場合はどうすればよいですか? これはnumpyライブラリを使用して可能になります。これにより、Cスタイルの構造を作成できますが、私の場合はコードをさらに詳細に改良する必要があり、最初の方法で十分でした。
__slots__の使用がHabréで詳細に理解されたことがないのは奇妙です。この記事がこのギャップを少し埋めることを願っています。
結論の代わりに。
この記事はPythonの反広告のように見えるかもしれませんが、まったくそうではありません。 Pythonは非常に信頼性が高く(Pythonプログラムを落とすために一生懸命努力する必要があります)、読みやすく、コードを書くのに便利な言語です。 多くの場合、これらの利点は短所を上回りますが、最大のパフォーマンスと効率が必要な場合は、C ++で記述されたnumpyなどのライブラリを使用できます。
ご清聴ありがとうございました