
この記事では、REST APIプロジェクトの有用で関連する仕様の作成とサポートに焦点を当てます。これにより、多くの余分なコードが節約され、プロジェクト全体の整合性、信頼性、透明性が大幅に向上します。
RESTful APIとは何ですか?

これは神話です。
真剣に、あなたのプロジェクトがRESTful APIを持っていると思うなら、間違いなく間違いです。 RESTfulの考え方は、RESTスタイルで記述されたアーキテクチャのルールと制限にすべての点で準拠するAPIを構築することですが、実際の状況ではこれはほとんど不可能です。
一方で、RESTには曖昧で曖昧な定義が多すぎます。 たとえば、HTTPメソッドおよびステータスコードのディクショナリからの一部の用語は、実際には意図された目的に使用されず、それらの多くはまったく使用されません。
一方、RESTは非常に多くの制限を作成します。 たとえば、現実世界でのリソースのアトミックな使用は、モバイルアプリケーションで使用されるAPIにとって合理的ではありません。 リクエスト間で状態を保存することを完全に拒否することは、多くのAPIで使用されるユーザーセッションメカニズムの禁止です。
しかし、すべてがそれほど悪いわけではありません!
なぜREST API仕様が必要なのですか?
これらの欠点にも関わらず、合理的なアプローチで、RESTは依然として本当にクールなAPIを設計するための優れた基盤のままです。 このようなAPIには、内部の均一性、明確な構造、便利なドキュメント、および優れた単体テストのカバレッジが必要です。 これらはすべて、APIの品質仕様を開発することで実現できます。
ほとんどの場合、REST API 仕様はそのドキュメントに関連付けられています 。 最初のAPI(APIの正式な説明)とは異なり、ドキュメントは人々が読むことを目的としています。たとえば、APIを使用するモバイルまたはWebアプリケーションの開発者です。
ただし、実際にドキュメントを作成することに加えて、適切なAPIの説明には多くの利点があります。 仕様の有能な使用を使用して、次のことができる方法の例を共有したい記事で:
- 単体テストをよりシンプルで信頼性の高いものにします。
- 入力データの前処理と検証を構成します。
- シリアル化を自動化し、応答の整合性を確保します。
- さらに静的型付けを利用します。
Openapi

現在REST APIを記述するために一般的に受け入れられている形式はOpenAPIであり、これはSwaggerとしても知られています。 この仕様は、JSONまたはYAML形式の単一ファイルであり、3つのセクションで構成されています。
- APIの名前、説明、バージョン、および追加情報を含むヘッダー。
- 識別子、HTTPメソッド、すべての入力パラメーター、および応答本文のコードと形式を含むすべてのリソースの説明と、定義へのリンク。
- 入力パラメーターと応答の両方で使用できるJSONスキーマ形式のオブジェクトのすべての定義。
OpenAPIには重大な欠点があります- 構造の複雑さと、多くの場合、冗長性 。 小さなプロジェクトの場合、仕様JSONファイルの内容はすぐに数千行に達する可能性があります。 この形式でこのファイルを手動で管理することはできません。 これは、APIの進化に合わせて最新の仕様を維持するという考えに対する深刻な脅威です。
APIを記述し、結果のOpenAPI仕様を作成できるビジュアルエディターが多数あります。 同様に、追加のサービスとクラウドソリューションは、たとえばSwagger 、 Apiary 、 Stoplight 、 Restletなどに基づいています。
しかし、私にとっては、仕様をすばやく編集してコード記述プロセスと組み合わせることが難しいため、このようなサービスはあまり便利ではありませんでした。 もう1つのマイナス点は、特定の各サービスの機能セットへの依存です。 たとえば、クラウドサービスだけで本格的な単体テストを実装することはほとんど不可能です。 エンドポイント用のコード生成、さらには「プラグ」の作成は、非常に可能性があるように見えますが、実際には実際には役に立ちません。
Tinyspec
この記事では、ネイティブREST API記述形式-tinyspecに基づく例を使用します。 形式は、プロジェクトで使用されるエンドポイントとデータモデルを直感的な構文で記述する小さなファイルです。 ファイルはコードの隣に保存されます。これにより、ファイルの作成プロセスでファイルを確認して編集することができます。 同時に、tinyspecは、プロジェクトですぐに使用できる本格的なOpenAPIに自動的にコンパイルされます。 正確な方法を説明する時が来ました。
この記事では、Node.js(koa、express)とRuby on Railsの例を示しますが、これらのプラクティスはPython、PHP、Javaなどのほとんどのテクノロジーに適用されます。
仕様が非常に役立つ場合
1.エンドポイントの単体テスト
行動駆動開発(BDD)は 、REST APIの開発に最適です。 単体テストを記述する最も便利な方法は、個々のクラス、モデル、コントローラーではなく、特定のエンドポイント用です。 各テストでは、実際のHTTP要求をエミュレートし、サーバーの応答を確認します。 Node.jsには、テストリクエストをエミュレートするためのスーパーテストとchai-httpがあり、Ruby on Railsに搭載されています。
User
スキーマと、すべてのユーザーを返すGET /users
エンドポイントがあるとします。 これを説明するtinyspec構文は次のとおりです。
- User.models.tinyspecファイル:
User {name, isAdmin: b, age?: i}
- users.endpoints.tinyspecファイル:
GET /users => {users: User[]}
これがテストの外観です。
Node.js
describe('/users', () => { it('List all users', async () => { const { status, body: { users } } = request.get('/users'); expect(status).to.equal(200); expect(users[0].name).to.be('string'); expect(users[0].isAdmin).to.be('boolean'); expect(users[0].age).to.be.oneOf(['boolean', null]); }); });
Ruby on Rails
describe 'GET /users' do it 'List all users' do get '/users' expect_status(200) expect_json_types('users.*', { name: :string, isAdmin: :boolean, age: :integer_or_null, }) end end
サーバーの応答形式を記述する仕様がある場合、テストを単純化し、 この仕様に対して応答をチェックするだけです。 これを行うには、tinyspecモデルがOpenAPI定義に変換されるという事実を利用します。OpenAPI定義はJSONスキーマ形式に対応します。
JSのリテラルオブジェクト (またはRubyのHash
、Pythonのdict
、PHPの連想配列 、さらにはJavaのMap
)は、JSONスキームへの準拠をテストできます。 また、フレームワークをテストするための適切なプラグインもあります。たとえば、 RSpecのjest-ajv (npm)、 chai-ajv-json-schema (npm)、 json_matchers (rubygem)です。
スキームを使用する前に、それらをプロジェクトに接続する必要があります。 最初に、tinyspecに基づいてopenapi.json仕様ファイルを生成します(このアクションは、各テストの実行前に自動的に実行できます)。
tinyspec -j -o openapi.json
Node.js
これで、受信したJSONをプロジェクトで使用して、そこからdefinitions
キーを取得できます。これには、すべてのJSONスキームが含まれています。 スキームには相互参照( $ref
)を含めることができます。したがって、ネストされたスキーム(たとえば、 Blog {posts: Post[]}
)がある場合、検証で使用するためにそれらを「展開」する必要があります。 このために、 json-schema-deref-sync (npm)を使用します。
import deref from 'json-schema-deref-sync'; const spec = require('./openapi.json'); const schemas = deref(spec).definitions; describe('/users', () => { it('List all users', async () => { const { status, body: { users } } = request.get('/users'); expect(status).to.equal(200); // Chai expect(users[0]).to.be.validWithSchema(schemas.User); // Jest expect(users[0]).toMatchSchema(schemas.User); }); });
Ruby on Rails
json_matchers
は$ref
リンクを処理できますが、特定の方法でファイルシステムにスキームを持つ個別のファイルが必要なので、最初にswagger.json
を多くの小さなファイルに「分割」するswagger.json
があります(詳細はこちら )。
# ./spec/support/json_schemas.rb require 'json' require 'json_matchers/rspec' JsonMatchers.schema_root = 'spec/schemas' # Fix for json_matchers single-file restriction file = File.read 'spec/schemas/openapi.json' swagger = JSON.parse(file, symbolize_names: true) swagger[:definitions].keys.each do |key| File.open("spec/schemas/#{key}.json", 'w') do |f| f.write(JSON.pretty_generate({ '$ref': "swagger.json#/definitions/#{key}" })) end end
その後、次のようにテストを記述できます。
describe 'GET /users' do it 'List all users' do get '/users' expect_status(200) expect(result[:users][0]).to match_json_schema('User') end end
注:この方法でテストを書くことは非常に便利です。 特に、IDEがテストの実行とデバッグ(WebStorm、RubyMine、Visual Studioなど)をサポートしている場合。 したがって、他のソフトウェアはまったく使用できず、API開発サイクル全体が3つの連続したステップに短縮されます。
- 仕様設計(例:tinyspec);
- 追加/変更されたエンドポイントのテストの完全なセットを作成します。
- すべてのテストを満たすコードの開発。
2.入力の検証
OpenAPIは、応答だけでなく入力データの形式も記述します。 これにより、リクエスト中にユーザーから受信したデータを検証できます。
ユーザーデータの更新と、変更可能なすべてのフィールドを説明する次の仕様があるとします。
# user.models.tinyspec UserUpdate !{name?, age?: i} # users.endpoints.tinyspec PATCH /users/:id {user: UserUpdate} => {success: b}
以前、テスト内の検証用のプラグインを検討しましたが、より一般的な場合にはajv (npm)およびjson-schema (rubygem)検証モジュールがあります。それらを使用して検証付きのコントローラーを作成しましょう。
Node.js(Koa)
これは、Expressの後継であるKoaの例ですが、Expressの場合、コードは同様になります。
import Router from 'koa-router'; import Ajv from 'ajv'; import { schemas } from './schemas'; const router = new Router(); // Standard resource update action in Koa. router.patch('/:id', async (ctx) => { const updateData = ctx.body.user; // Validation using JSON schema from API specification. await validate(schemas.UserUpdate, updateData); const user = await User.findById(ctx.params.id); await user.update(updateData); ctx.body = { success: true }; }); async function validate(schema, data) { const ajv = new Ajv(); if (!ajv.validate(schema, data)) { const err = new Error(); err.errors = ajv.errors; throw err; } }
この例では、入力データが仕様を満たしていない場合、サーバーはクライアントに500 Internal Server Error
応答を返します。 これを防ぐために、バリデータエラーをインターセプトし、独自の回答を作成できます。これには、テストに合格しなかった特定のフィールドに関する詳細情報が含まれ、仕様にも準拠します。
FieldsValidationError
ファイルにFieldsValidationError
モデルの説明を追加します。
Error {error: b, message} InvalidField {name, message} FieldsValidationError < Error {fields: InvalidField[]}
そして今、私たちはそれをエンドポイントの可能な答えの1つとして示します:
PATCH /users/:id {user: UserUpdate} => 200 {success: b} => 422 FieldsValidationError
このアプローチにより、クライアントから受信した不正なデータを使用してエラーの形成が正しいことを検証する単体テストを作成できます。
3.モデルのシリアル化
ほとんどすべての最新のサーバーフレームワークは、 何らかの方法でORMを使用します。 つまり、システム内のAPIで使用されるほとんどのリソースは、モデル、そのインスタンス、およびコレクションの形式で提示されます。
API応答で送信するためにこれらのエンティティのJSON表現を生成するプロセスは、 シリアライゼーションと呼ばれます。 たとえば、 sequelize-to-json (npm)、 acts_as_api (rubygem)、 jsonapi-rails (rubygem)など、シリアル化機能を実行するさまざまなフレームワーク用のプラグインがいくつかあります。 実際、これらのプラグインを使用すると、特定のモデルでJSONオブジェクトに含める必要があるフィールドのリストを指定したり、追加のルール(名前の変更や値の動的な計算など)を指定したりできます。
困難は、同じモデルの複数の異なるJSON表現が必要な場合、またはオブジェクトにネストされたエンティティ(関連付け)が含まれる場合に始まります。 シリアライザーの継承、再利用、リンクが必要です。
さまざまなモジュールがこれらの問題をさまざまな方法で解決しますが、仕様が再び役立つかどうか考えてみましょう。 実際、JSON表現の要件に関するすべての情報、ネストされたエンティティを含むフィールドの可能なすべての組み合わせは、すでにそこにあります。 したがって、自動シリアライザーを作成できます。
小さなモジュールsequelize-serialize (npm)に注目してください。これにより、Sequelizeモデルでこれを行うことができます。 モデルインスタンスまたは配列、および必要な回路の入力を受け取り、すべての必要なフィールドを考慮し、関連するエンティティにネストされた回路を使用して、シリアル化されたオブジェクトを繰り返し構築します。
そのため、ブログの投稿(コメントへのコメントを含む)を持っているすべてのユーザーをAPIから返す必要があるとします。 これについては、次の仕様を使用して説明します。
# models.tinyspec Comment {authorId: i, message} Post {topic, message, comments?: Comment[]} User {name, isAdmin: b, age?: i} UserWithPosts < User {posts: Post[]} # blogUsers.endpoints.tinyspec GET /blog/users => {users: UserWithPosts[]}
これで、Sequelizeを使用してクエリを構築し、上記の仕様に正確に一致するシリアル化されたオブジェクトを返すことができます。
import Router from 'koa-router'; import serialize from 'sequelize-serialize'; import { schemas } from './schemas'; const router = new Router(); router.get('/blog/users', async (ctx) => { const users = await User.findAll({ include: [{ association: User.posts, required: true, include: [Post.comments] }] }); ctx.body = serialize(users, schemas.UserWithPosts); });
それはほとんど魔法ですよね?
4.静的型付け
TypeScriptまたはFlowを使用しているほどクールな場合は、 「私の親愛なる静的型はどうなの?!」 。 sw2dtsまたはswagger -to-flowtypeモジュールを使用すると、JSONスキームに基づいて必要なすべての定義を生成し、テスト、入力データ、 シリアライザーの静的型付けに使用できます。
tinyspec -j sw2dts ./swagger.json -o Api.d.ts --namespace Api
これで、コントローラーで型を使用できます。
router.patch('/users/:id', async (ctx) => { // Specify type for request data object const userData: Api.UserUpdate = ctx.request.body.user; // Run spec validation await validate(schemas.UserUpdate, userData); // Query the database const user = await User.findById(ctx.params.id); await user.update(userData); // Return serialized result const serialized: Api.User = serialize(user, schemas.User); ctx.body = { user: serialized }; });
そしてテストでは:
it('Update user', async () => { // Static check for test input data. const updateData: Api.UserUpdate = { name: MODIFIED }; const res = await request.patch('/users/1', { user: updateData }); // Type helper for request response: const user: Api.User = res.body.user; expect(user).to.be.validWithSchema(schemas.User); expect(user).to.containSubset(updateData); });
生成されたタイプ定義は、APIプロジェクト自体だけでなく、クライアントアプリケーションプロジェクトでも使用して、APIが機能する関数のタイプを記述することができることに注意してください。 Angularの顧客開発者は、このギフトに特に満足しています。
5.型キャストクエリ文字列
何らかの理由でAPIがapplication/json
ではなくMIMEタイプapplication/x-www-form-urlencoded
リクエストを受け入れる場合、リクエストの本文は次のようになります。
param1=value¶m2=777¶m3=false
同じことがクエリパラメータにも適用されます(たとえば、GET要求の場合)。 この場合、Webサーバーはタイプを自動的に認識できません。すべてのデータは文字列の形式であるため( ここではqpm npmモジュールリポジトリで説明します)、解析後に次のオブジェクトを取得します。
{ param1: 'value', param2: '777', param3: 'false' }
この場合、要求はスキームに従って検証されません。つまり、各パラメーターの形式が正しいことを手動で確認し、必要なタイプにする必要があります。
ご想像のとおり、これは仕様からすべて同じスキームを使用して実行できます。 このようなエンドポイントとスキームがあると想像してください:
# posts.endpoints.tinyspec GET /posts?PostsQuery # post.models.tinyspec PostsQuery { search, limit: i, offset: i, filter: { isRead: b } }
このようなエンドポイントへのリクエストの例を次に示します
GET /posts?search=needle&offset=10&limit=1&filter[isRead]=true
すべてのパラメーターを必要な型にcastQuery
関数を作成しましょう。 次のようになります。
function castQuery(query, schema) { _.mapValues(query, (value, key) => { const { type } = schema.properties[key] || {}; if (!value || !type) { return value; } switch (type) { case 'integer': return parseInt(value, 10); case 'number': return parseFloat(value); case 'boolean': return value !== 'false'; default: return value; } }); }
ネストされたスキーム、配列、およびnull
型をサポートするより完全な実装は、 cast-with-schema (npm)で利用できます。 これで、コードで使用できます。
router.get('/posts', async (ctx) => { // Cast parameters to expected types const query = castQuery(ctx.query, schemas.PostsQuery); // Run spec validation await validate(schemas.PostsQuery, query); // Query the database const posts = await Post.search(query); // Return serialized result ctx.body = { posts: serialize(posts, schemas.Post) }; });
エンドポイントコードの4行のうち、仕様の3つの使用スキームに注目してください。
ベストプラクティス
作成と変更のための個別のスキーム
通常、サーバーの応答を記述するスキームは、モデルの作成および変更に使用される入力を記述するスキームとは異なります。 たとえば、 POST
およびPATCH
要求で使用可能なフィールドのリストは厳密に制限する必要がありますが、 PATCH
要求では、通常、スキームのすべてのフィールドがオプションになります。 答えを決定するスキームはより自由であるかもしれません。
tinyspec CRUDLエンドポイントの自動生成では、 New
およびUpdate
のポストフィックスを使用します。 User*
は次のように定義できます。
User {id, email, name, isAdmin: b} UserNew !{email, name} UserUpdate !{email?, name?}
古いスキームの再利用または継承による偶発的なセキュリティ問題を回避するために、異なるタイプのアクションに同じスキームを使用しないようにしてください。
スキーマ名のセマンティクス
同じモデルの内容は、エンドポイントによって異なる場合があります。 スキーマ名のWith*
およびFor*
接尾辞を使用して、それらがどのように違い、何のためにあるかを示します。 tinyspecモデルでは、相互に継承することもできます。 例:
User {name, surname} UserWithPhotos < User {photos: Photo[]} UserForAdmin < User {id, email, lastLoginAt: d}
接尾辞はさまざまな組み合わせが可能です。 主なものは、それらの名前が本質を反映し、ドキュメントに精通していることです。
クライアントタイプによるエンドポイントの分離
多くの場合、同じエンドポイントは、クライアントのタイプまたはエンドポイントにアクセスするユーザーの役割に応じて異なるデータを返します。 たとえば、 GET /users
とGET /messages
のエンドポイントは、モバイルアプリケーションのユーザーとバックオフィスマネージャーで大きく異なる場合があります。 同時に、エンドポイント自体の名前を変更するのは非常に複雑です。
同じエンドポイントを複数回記述するために、パスの後に角かっこでそのタイプを追加できます。 タグを使用すると便利です。これは、エンドポイントのドキュメントをグループに分割するのに役立ちます。各グループは、APIのクライアントの特定のグループ向けに設計されます。 例:
Mobile app: GET /users (mobile) => UserForMobile[] CRM admin panel: GET /users (admin) => UserForAdmin[]
REST APIドキュメント
tinyspec形式またはOpenAPI形式の仕様を作成したら、HTMLで美しいドキュメントを生成し、それをAPIを使用する開発者に公開できます。
前述のクラウドサービスに加えて、OpenAPI 2.0をHTMLおよびPDFに変換するCLIツールがあり、その後、任意の静的ホスティングにダウンロードできます。 例:
- bootprint-openapi (npm、tinyspecでデフォルトで使用)
- swagger2markup-cli (jar、 使用例があり、 tinyspec Cloudで使用されます )
- redoc-cli (npm)
- widdershins (npm)
もっと例を知っていますか? コメントで共有してください。
残念ながら、1年前にリリースされたOpenAPI 3.0はまだ十分にサポートされておらず、それに基づいたドキュメントの適切な例は見つかりませんでした。クラウドソリューションでもCLIツールでもありません。 同じ理由で、tinyspecではOpenAPI 3.0はまだサポートされていません。
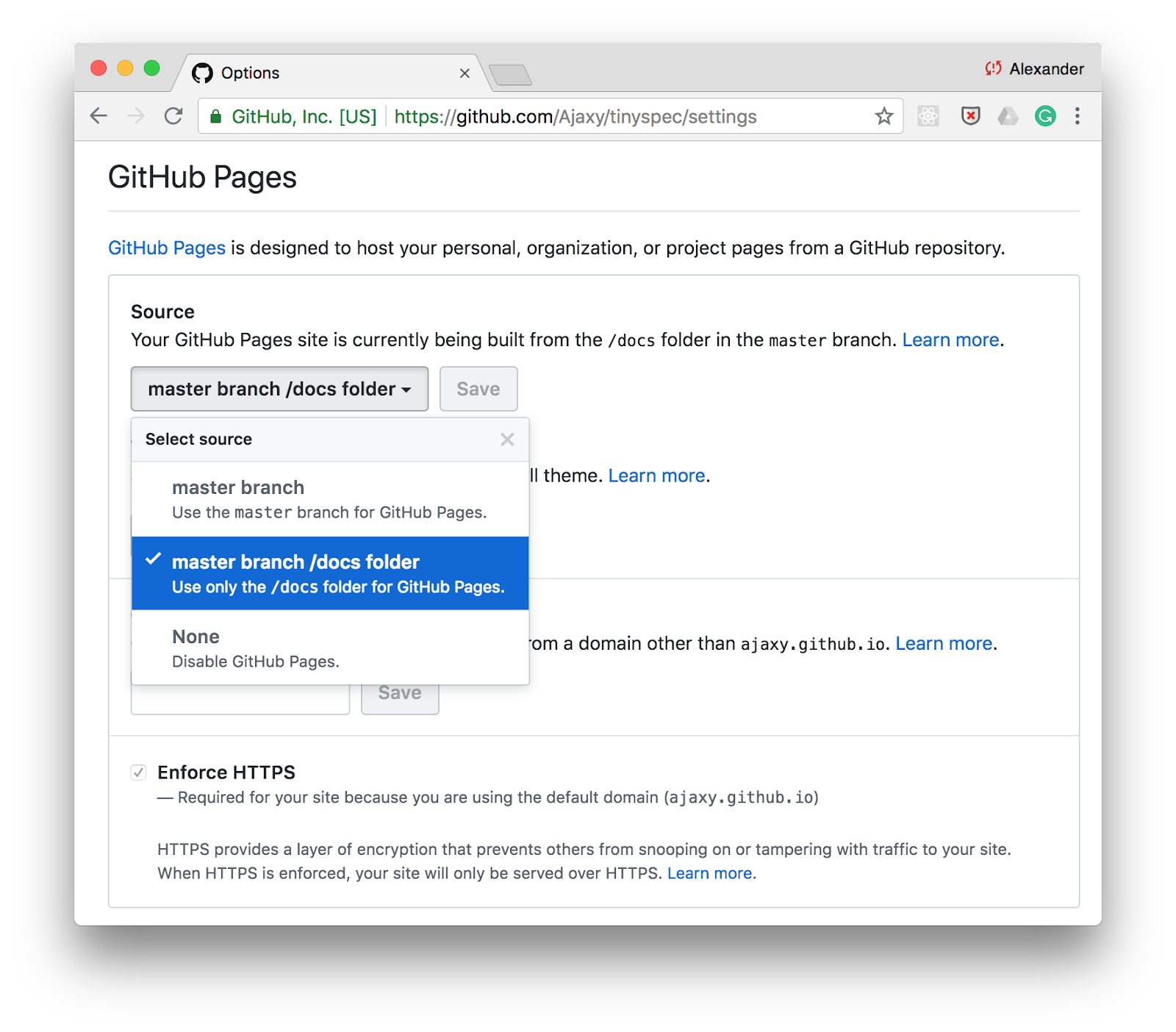
GitHubに公開する
ドキュメントを公開する最も簡単な方法の1つはGitHub Pagesです。 リポジトリ設定で/docs
ディレクトリの静的ページサポートを有効にし、このフォルダーにHTMLドキュメントを保存するだけです。
package.json
のscripts
でtinyspecまたは別のCLIツールを使用してドキュメントを生成するコマンドを追加し、コミットごとにドキュメントを更新できます。
"scripts": { "docs": "tinyspec -h -o docs/", "precommit": "npm run docs" }
継続的インテグレーション
ドキュメントの生成をCIサイクルに含めて、たとえば、環境やAPIのバージョンに応じて異なるアドレスでAmazon S3に発行できます(例: /docs/2.0
/docs/stable
、 /docs/staging
。
Tinyspecクラウド
tinyspec構文が気に入った場合は、tinyspec.cloudでアーリーアダプターとして登録できます。 テンプレートを幅広く選択し、独自のテンプレートを開発する機能を備えたドキュメントを自動的に公開するために、クラウドサービスとCLIを基盤に構築します。
おわりに
REST APIの開発は、おそらく最新のWebおよびモバイルサービスで作業するプロセスに存在するすべての中で最も楽しいアクティビティです。 ブラウザ、オペレーティングシステム、画面サイズの動物園はありません。すべてが「指先で」管理されています。
提供されているさまざまな自動化の形で現在の仕様とボーナスを維持することで、このプロセスはさらに快適になります。 このようなAPIは、構造化され、透過的で信頼性が高くなります。
実際、神話の創造に携わっているとしても、なぜそれを美しくしませんか?