
背景
労働市場は常にダイナミクスにあり、新しい職業が出現し、他の職業は消えつつあります。関連する履歴書の分類が必要です。 hh.ruの専門分野と専門分野のカタログは古くから古くなっています。多くはそれに関連しているため、長い間変更を加えていません。 これらのカテゴリを簡単に編集する方法を学ぶと便利です。 これらのカテゴリを自動的に識別しようとしています。 今後、これが問題の解決に役立つことを願っています。
選択したアプローチとクラスタリングについて
クラスタリングすることで、1つのグループ内で最も類似した機能を持つオブジェクトの組み合わせを理解できます。 私の場合、オブジェクトの下は履歴書と見なされ、オブジェクトの兆候の下には要約データがあります。たとえば、履歴書の「マネージャー」という単語の頻度や給与のサイズです。 オブジェクトの類似性は、事前に選択されたメトリックによって決定されます。 これまでのところ、入力で2つのオブジェクトを受け取るブラックボックスと考えることができ、出力は、たとえばベクトル空間でのオブジェクト間の距離を反映する数値を生成します。距離が小さいほど、オブジェクトは類似しています。
私が使用したアプローチは、上方凝集型階層クラスタリングと呼ぶことができます。 クラスタリングの結果はバイナリツリーであり、葉には個々の要素があり、ツリーのルートはすべての要素のコレクションです。 クラスタリングはツリーの最下位レベルで始まり、各要素がクラスターと見なされる葉を持つため、アセンダントと呼ばれます。

次に、最も近い2つのクラスターを見つけて、それらを新しいクラスターにマージする必要があります。 すべてのオブジェクトが内部にあるクラスターが1つだけになるまで、この手順を繰り返す必要があります。 クラスターが結合されると、クラスター間の距離が記録されます。 将来的には、これらの距離を使用して、選択したクラスターを個別と見なすのに十分な距離がある場所を決定できます。
ほとんどのクラスタリング方法では、クラスターの数が事前にわかっていることを前提としています。または、アルゴリズムとこのアルゴリズムのパラメーターに応じて、クラスターを個別に分離しようとします。 階層クラスタリングの利点は、結果のツリーのプロパティを調べることで必要なクラスター数を決定できることです。たとえば、サブツリーを選択して、距離が非常に大きい異なるグループに分けます。 結果の構造を操作して、その中のクラスターを検索すると便利です。 便利なことに、このような構造は一度構築されるため、必要な数のクラスターを検索するときに再構築する必要はありません。
欠点の中で、私はアルゴリズムが消費されるメモリをかなり要求していることに言及します。 そして、特定のクラスを割り当てる代わりに、履歴書がそのクラスに属している可能性を持たせて、最も近い専門ではなく全体を調べたいと思います。
データの収集と準備
データの操作で最も重要な部分は、属性の準備、選択、取得です。 最終的にどのような兆候が得られるかに基づいて、パターンが存在するかどうか、これらのパターンが期待される結果に対応するかどうか、そしてこの「期待される結果」がまったく可能かどうかに依存します。 ある種の機械学習アルゴリズムにデータを供給する前に、各特性、ギャップがあるかどうか、属性が属するタイプ、このタイプの属性が持つプロパティ、この属性の値の分布を把握する必要があります。 また、利用可能なデータを処理する適切なアルゴリズムを選択することも非常に重要です。
過去6か月間に更新された履歴書を取りました。 履歴書のデータから、私が思ったように、履歴書のメンバーシップが1つまたは別のグループに依存する最も単純な標識を選択しました。 今後、すべての履歴書を一度にクラスタリングした結果は満足できなかったと思います。 そのため、まず履歴書を既存の28の専門分野で分割する必要がありました。
各特性について、分布をプロットして、データがどのように見えるかを把握しました。 おそらくそれらは何らかの形で変換されるか、完全に放棄されるべきです。
地域 この機能の値を互いに比較できるように、この地域に属する履歴書の総数を各地域に割り当て、この数値から対数を取り、大都市と小都市の違いを滑らかにしました。
ポール バイナリ記号に変換されます。
生年月日 。 月数でカウントされます。 誰もが誕生日を迎えるわけではありません。 この履歴書が属する専門分野の平均年齢値でギャップを埋めました。
教育レベル 。 これはカテゴリカルサインです。 LabelBinarizerでエンコードしました。
ラインアイテムの名前 。 ngram_range =(1,2)でTfidfVectorizerを運転し、 ステマーを使用しました。
給与 。 ルーブルのすべての値を翻訳しました。 私は年齢と同じように隙間を埋めました。 値から対数を取りました。
勤務スケジュール 。 エンコードされたLabelBinarizer。
雇用率 。 私はそれをバイナリにし、フルタイムとその他すべての2つの部分に分けました。
言語能力 。 最もよく使用されるトップを選択しました。 各言語は個別の機能として設定されます。 所有権のレベルは、0〜5の数字と一致します。
キースキル 。 TfidfVectorizerを運転しました。 ストップワードとして、私は一般的なスキルと単語の小さな辞書をまとめました。 すべての単語はステマーを通過します。 各キースキルは、1つの単語だけでなく、複数の単語で構成することもできます。 キースキルの複数の単語の場合、単語をソートし、各単語を個別の属性として使用しました。 多くの場合、人々は自分の専門分野に関連するスキルを示すため、この機能は専門分野の「情報技術、インターネット、通信」でのみうまくいきました。 他の専門分野では、一般的な単語のスキルが豊富であるため、私はそれを使用しませんでした。
専門分野 。 ユーザー指定の各スペシャライゼーションをバイナリ属性として設定します。
仕事の経験 。 仕事経験のない人がいるため、彼は月数+ 1の対数を取りました。
標準化
その結果、各履歴書は数字記号のベクトルになり始めました。 選択したクラスタリングアルゴリズムは、オブジェクト間の距離の計算に基づいています。 各フィーチャがこの距離にどのように寄与するかを決定する方法は? たとえば、バイナリ記号-0と1があり、別の記号は0から1000までの値を取ることができます。
標準化が助けになります。 StandardScalerを使用しました。 彼は、平均値がゼロで、平均からの標準偏差が1になるように、各特徴を変換します。 したがって、すべてのデータを同じ分布(標準正規分布)にしようとしています。 もちろん、データ自体が正規分布の性質を持っているという事実からはほど遠いです。 これは、パラメーターの分布をプロットし、それらがガウス分布のように見えることを喜んでいる理由の1つにすぎません。
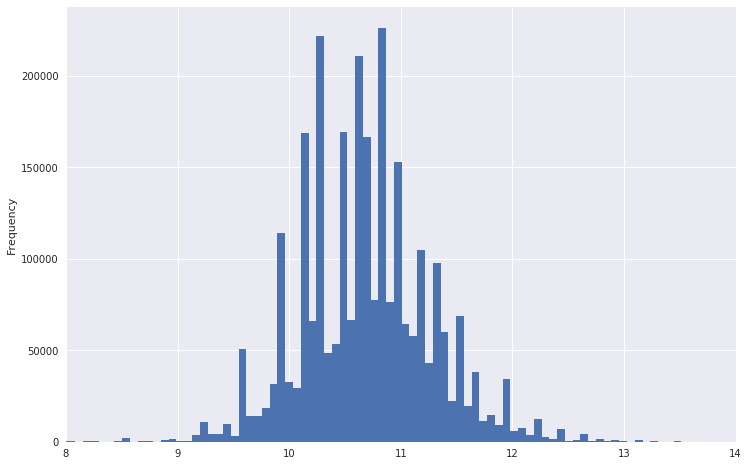
したがって、たとえば、給与分布図は次のようになりました。

彼が非常に重い尻尾を持っていることは明らかです。 分布をより標準に近づけるために、このデータから対数を取得できます。 同時に、排出量はそれほど強くありません。
ダウングレード
将来、クラスタリングアルゴリズムが許容可能な時間とメモリでそれらを消化できるように、データをより小さな次元のスペースに転送することが理にかなっています。 私はTruncatedSVDを使用しました。これは、スパース行列の操作方法を知っており、出力では通常の密行列を提供するためです。 ところで、TruncatedSVDも標準化されたデータを送信する必要があります。
同じ段階で、結果のデータセットを視覚化して、 t-SNEを使用して2次元空間に変換してみる価値があります。 これは非常に重要なステップです。 結果の画像に構造が表示されていない場合、または逆にこの構造が非常に奇妙に見える場合、データに必要な規則性がないか、どこかでエラーが発生しています。
すべてがうまくいく前に、非常に疑わしい画像がたくさんありました。 たとえば、こんな美しい画像ができたら:

ワームが発生した理由は、データセット内の履歴書識別子を取得することでした。 そして、これは真実により近いものです:

クラスタリング
すべてがデータの順序どおりになっているようであれば、クラスタリングを開始できます。 SciPyの階層クラスタリングパッケージを使用しました。 リンケージ方式を使用したクラスタリングが可能です。 アルゴリズムで提案されているすべてのクラスター距離メトリックを試しました。 最良の結果はワード方式で得られました 。
私が遭遇した主な問題は、クラスタリングアルゴリズムがすべての要素間の距離行列を計算することです。これは、要素数の2次メモリ依存性を意味します。 270万人の履歴書については、成功しませんでした。 必要なメモリの量はテラバイトです。 すべての計算は、通常のコンピューターで実行されました。 RAMがあまりありません。 したがって、最初に近くにある履歴書を結合し、結果のグループの中心を取得し、目的のアルゴリズムでそれらを既にクラスター化できることは理にかなっているように思えました。 MiniBatchKMeansを使用して30,000個のクラスターを形成し、それらを階層クラスターに送信しました。 うまくいきましたが、結果はまあまあでした。 最も印象的な履歴書グループの多くは際立っていましたが、ディテールは専門分野を適切なレベルで見つけるのに十分ではありません。
受け取った専門分野の品質を向上させるために、データを専門分野に分割しました。 40万人以下の履歴書からのデータセットが判明しました。 その瞬間、データサンプルのクラスタリングは、2つのアルゴリズムを連続して使用するよりも優れていることがわかりました。 そのため、MiniBatchKMeansをあきらめ、専門分野ごとに最大100,000件の履歴書を作成して、リンク方式でそれらを消化できるようにしました。 32 GBのRAMでは十分ではなかったため、スワップ用にさらに100 Gbを割り当てました。 結果として、リンケージは、各ステップで結合されたクラスター間の距離と、結果のクラスター内の要素の数を含むマトリックスを提供します。
データセットの異なるバージョンとクラスター間の距離を計算するための異なる方法を比較するための品質管理指標として、アルゴリズムはcophenetから取得したcophenetic相関係数を使用しました 。 この係数は、結果の樹状図がオブジェクト同士の相違点をどれだけ反映しているかを示します。 値が1に近いほど優れています。
可視化
クラスタリングの品質を検証する最良の方法は、視覚化でした。 樹状図法は、樹木図を描画します。樹状図では、距離またはツリーのレベルでクラスターを選択できます。

次のグラフは、クラスタ間の距離の反復ステップ番号への依存性を示しています。反復ステップ番号では、2つの最も近いクラスタが新しいクラスタに結合されます。 緑色の線は、加速度がどのように変化するかを示しています-結合されるクラスター間の距離の速度。
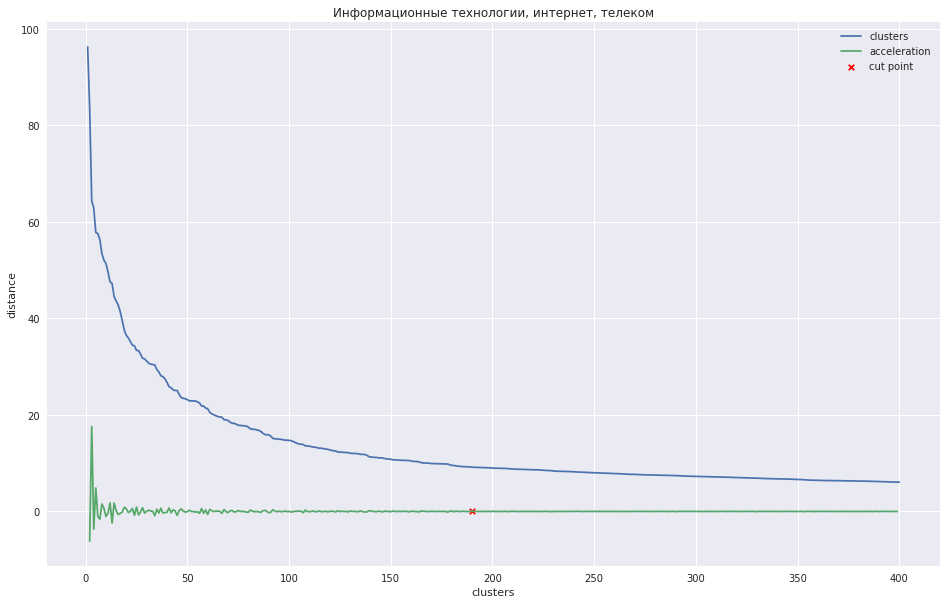
クラスターの数が少ない場合は、加速度が最大になるポイントでツリーを剪定することができます。つまり、2つのクラスターが結合された瞬間の距離はさらに大きく、次のステップで既に小さくなりました。 私の場合、すべてが異なります-私は多くのクラスターを持っています。加速がより単調に減少し始めるポイントで樹状図をトリミングすることをお勧めします。つまり、このレベルのクラスター間の距離はもはや別のグループを示していません。 グラフ上では、この場所はほぼ緑の線が踊るのを止めた地点にあります。
何らかの種類のプログラム手法を思いつくことは可能ですが、28のプロドメインの28の手でこれらの場所をマークし、必要なクラスター数をfclusterメソッドに渡すと、ツリーが適切な場所に切り取られます。
以前にt-SNEから取得したデータを保存し、それらの結果のクラスターに注目しました。 それはかなりよさそうです:

その結果、Webインターフェースを作成して、各クラスターの概要、チャート上のその位置を確認し、意味のある名前を付けることができます。 便宜上、履歴書の最も一般的なタイトルを推測しました-多くの場合、クラスターの名前をよく特徴付けています。
ここでクラスタリングの結果を見ることができます。
私は、システムが機能していることが判明したと自分で結論付けました。 クラスターへの内訳は不完全ですが、いくつかのグループは互いに非常に似ていますが、一部は反対に部分に分割できますが、専門市場の主な傾向ははっきりと見えます。 また、新しいグループがどのように形成されるかを確認できます。 履歴書のアンロードは夏に行われたため、たとえば、ワールドカップで働きたいドライバーは際立っていました。 起動ごとにクラスターを相互に一致させることを学ぶと、時間の経過とともに専門分野の主な領域がどのように変化するかを観察できます。 実際、品質と開発を改善するためのアイデアはまだいっぱいです。 自分の中に正しい動機を見つけることができれば、私はさらに成長します。
追加資料
データ内の構造の検索に関するコースからの凝集型階層クラスタリングに関するビデオ
記号のスケーリングと正規化について
SciPyライブラリからの階層的クラスタリングのチュートリアル。タスクの基礎として使用しました
例としてsklearnライブラリーを使用したさまざまなタイプのクラスタリングの比較
少しボーナス。 誰かがタスクを処理する方法は、人々にとって興味深いと思いました。 いくつかの問題では、このプロジェクトを行っている間、私はうまくいきました。 私はさまざまなオプションを試し、研究し、これまたはそのことがどのように機能するかを考えました。 多くの場所で、優れた数学的基礎の欠如は、機知に富み、多数の試みによって相殺されました。 そして、作業中にメモをとった、苦しんでいるエバーノシートを共有したいと思います。 その中の反省は私だけのために意図されたものであり、多くの異端と無理解がありますが、それは正常だと思います。
UPD: データ準備とクラスタリングコードを備えたラップトップを投稿しました。 コードをアップロードする予定はありませんでしたので、品質にごめんなさい。