基本的な基本事項を1つのチートシートにまとめて、お客様と共有します。
経験豊富なエンジニアがこの記事から新しいことを学ぶことはまずありませんが、この情報が初心者にとって役立つことを願っています。

要件とその特徴
各プロジェクトには多くの要件があります。 それらをすべて理解し、混同しないようにすることが重要です。
ビジネス要件は、システムがビジネスの観点から何をすべきかを決定します。
たとえば、アプリケーションは、エージェントの販売を増やすために、ユーザーがチケットと追加サービスを販売できるようにする必要があります。
ユーザー要件は、ビジネス要件を実装するためにシステムで作業するユーザーの目標と目的を説明します。 ユーザー要件は、多くの場合、ユーザーケースとして提示されます。
たとえば、ユーザーとして、マイルでサービスを販売する必要があります。
機能要件 -システムが行うべきこと。 ユーザーがユーザーの要件を満たすことができるように、開発者が作成する必要があるシステムの機能(動作)を決定します。
非機能要件 -システムの動作方法。 これには、パフォーマンス、品質、制限、使いやすさなどの要件が含まれます。
課題トラッカーでのタスクの種類と説明の順序
したがって、要件のタイプを説明しました。 次に、それらをタスクのタイプに分割し、各タイプを解読して、それを正しく記述する方法を教えます。

最も壮大な、つまりEpicから始めましょう。
Epicは一般的なタスクであり、サービスの開発時間を考慮してすべてのユーザーストーリーが収集されます。 製品またはサービスの主な目的を説明しています。 Epicの主な目標は、製品にどのような新しい要件が課されても、タスクを収集して1か所に保存することです。 Epicは常にユーザーストーリー以上のものであり、1つの反復に収まらない場合もあります。
Epic問題の解決策により、 MVP (Minimal Viable Product)-最小の実行可能製品を作成できます。 言い換えると、エンドユーザーからのフィードバックに基づいて製品を学習し、適応させるためにリリースする必要があるもの。
EpicはUser Storyとどう違うのですか?
- Epicは単なる大きなユーザーストーリーであり、その特徴はユーザーにとって明確な価値の存在です。
- ユーザーストーリーの作成、つまりプロジェクトの要件の収集を開始すると、通常、一般から特定へと移行します。まず、プロジェクトの概念を決定し、主要な人物(システムのユーザー)を選択し、主要な機能のリストを作成してから、これらの機能を個別の希望で詳細に説明します-ユーザーストーリー。
Epicの説明は次のとおりです。
- タイトル/サマリータイトル -新しい機能の名前。
- 説明/説明 -パターンに従って記述されます:
ユーザーの役割(そのようなユーザーとして、私は...)/ユーザーアクション(私は何かをしたい...)/アクションの結果(結果を得るために...)/興味または利益(私はそのような利益を得ることができます...)。 - MVPを使用したEpicの一部として実装されるサンプル実装計画または主要なユーザーストーリーの簡単な説明。
- 添付ファイル -通信、技術、その他の必要な情報を添付します。
ユーザーストーリーと技術ストーリーの作り方
ユーザーストーリーとテックストーリーの違いは、テックストーリーが考慮すべき機能要件を指し、製品開発時にタスクで説明する必要があることです。 そして消費者の役割には、システムの一部があります。
それらの説明は簡単です。 覚えておくべき主なことは、これがすべて行われている理由です。

ユーザーストーリーの説明の順序は非常に標準的です:
- タイトル/概要/タイトル-顧客が理解できる言語の新機能または改善点の簡単な説明。
- 説明/説明には、主な目標と望ましい結果が含まれています。 たとえば、<ユーザーロール>、<取得したい>、<アクションの結果>を目標にしています。
- 受け入れ基準は、優先的な製品基準のリストです。 つまり、プロジェクトの利害関係者に受け入れられるように、製品で何をすべきかについての測定可能な定義です。
- テクニカルノート、モデル、レイアウト、ページレイアウト。
- 添付ファイル/添付ファイル-すべての必要な技術、文書、顧客とのやり取り。
バグを説明する方法
バグを報告する際にはどのような情報を示す必要がありますか:
1. タイトル/概要/タイトルは、エラーの本質を簡単に説明し、問題の場所を示します。
2.説明には次の手順が含まれます。
•エラー/再生手順の再現方法、
•現在の結果、
•期待される結果。
3. 添付ファイル/添付ファイル -必要なすべてのログ、スクリーンショット、Kibanaへのリンク、およびその他のファイル。
4. 環境 -エラーが再現される環境と、問題が属するカテゴリ。 たとえば、UIのエラー、COREエラー、SWSエラーなど。
5. 優先度により、チームの各メンバーが問題の重大度を評価し、マネージャーがスプリントの最初の候補のリストでそれを確認できます。
そして、正しい優先度レベルを設定することを忘れないでください:)
作業の一般的な原則を理解したので、展開パイプラインを整理する方法を説明します。
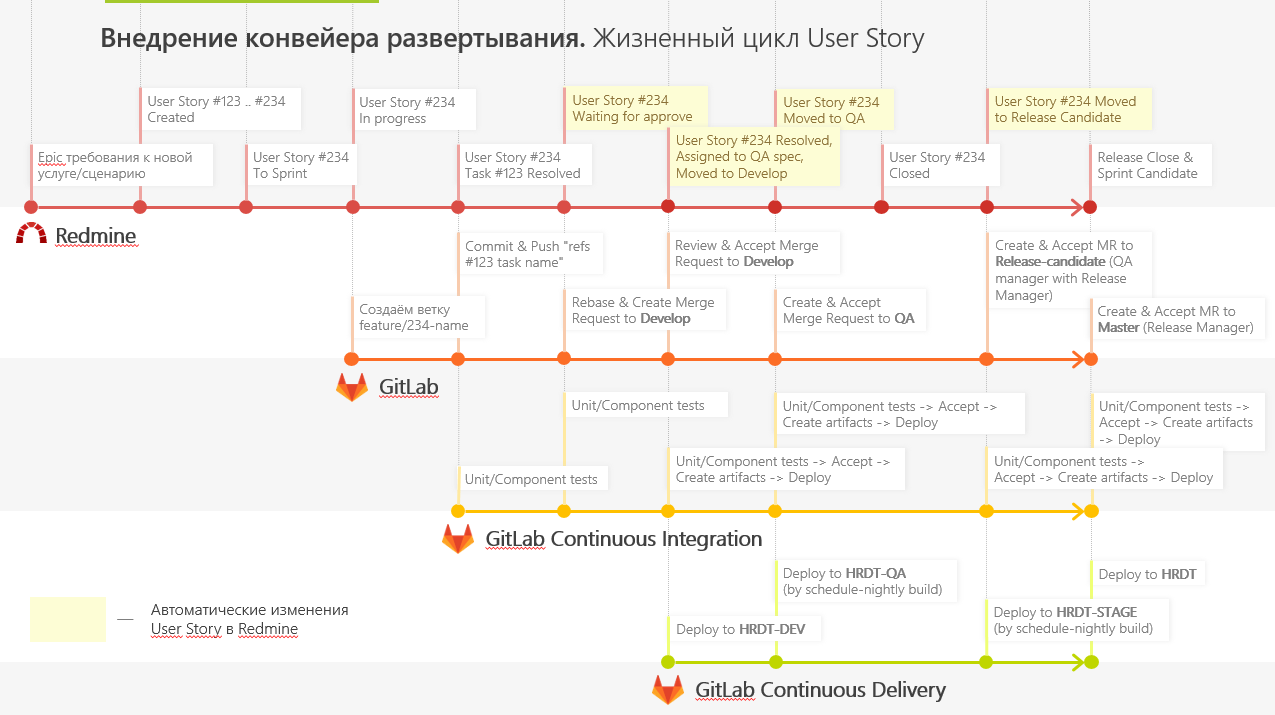
展開パイプライン構成
本番環境へのサービスの配信を高速化するために、新しい展開パイプラインを導入し、GitFlowを使用してコードを操作します。
これを迅速かつ動的に行うために、開発者がプッシュするすべてのタスクを実行するいくつかのGitLabランナーをデプロイしました。 GitLab Flowのアプローチのおかげで、いくつかのサーバーがあります:開発、QA、リリース候補、本番。
継続的インテグレーションは、各コミットのテストの収集と実行、単体テストと統合テストの実行、アプリケーション配信へのアーティファクトの追加を開始しました。

開発は次のように行われます。
- 開発者は、別のブランチ(機能ブランチ)に新しい機能を追加します。 その後、彼は自分のブランチを開発のメインブランチとマージするリクエストを作成します(ブランチへのリクエストのマージ)。
- 他の開発者はマージ要求を見て、それを受け入れ(または受け入れない)、コメントを修正します。 マージ後、トランクブランチで特別な環境が展開され、環境を上げるためのテストが実行されます。
- これらすべての段階が完了すると、QAエンジニアは「QA」ブランチに変更を加えてテストを実施します。
- QAエンジニアが完了した作業に同意すると、変更はRelease-Candidateブランチに移動し、外部ユーザーがアクセスできる環境に展開します。 この環境では、顧客はテクノロジーを受け入れ、検証します。 次に、すべてをプロダクションに蒸留します。
何らかの段階でエラーが発生した場合は、このブランチでエラーを解決し、その後、Developに結果を投稿します。
また、Redmineが機能のステージを通知できるように、小さなプラグインを作成しました。 これにより、テスターはタスクに接続する必要がある段階で評価し、開発者はエラーを修正できます。 そのため、障害がどの段階で発生したかを確認し、特定のブランチに移動してそこでプレイできます。
お役に立てば幸いです。