画像認識用のディープニューラルネットワークの開発は、機械学習の既知の研究分野に新たな生命を吹き込んでいます。 そのような領域の1つは、ドメイン適応です。 この適応の本質は、ソースドメイン(ソースドメイン)のデータでモデルをトレーニングし、ターゲットドメイン(ターゲットドメイン)で同等の品質を示すことです。 たとえば、ソースドメインは安価に生成できる合成データであり、ターゲットドメインはユーザーの写真です。 次に、ドメイン適応のタスクは、合成データでモデルをトレーニングすることです。これは、「実際の」オブジェクトでうまく機能します。
マシンビジョングループVision.BIZ.Ruでは、さまざまな応用問題に取り組んでいますが、その中にはトレーニングデータがほとんどないものもあります。 これらの場合、合成データの生成と、それらでトレーニングされたモデルの適応が非常に役立ちます。 このアプローチの良い応用例は、店舗の棚にある商品を検出して認識するタスクです。 このような棚の写真を取得してマークアップするのはかなり面倒ですが、非常に簡単に生成できます。 そのため、ドメイン適応のトピックをさらに深く掘り下げることにしました。

ドメイン適応の研究は、新しいタスクでニューラルネットワークによって得られた以前の経験の使用に影響します。 ネットワークはソースドメインからいくつかの機能を抽出し、ターゲットドメインで使用できますか? 機械学習のニューラルネットワークは人間の脳のニューラルネットワークとは遠い関係にありますが、人工知能研究者の聖杯は、ニューラルネットワークに人が持つ能力を教えることです。 そして、人々は以前の経験と蓄積された知識を使用して新しい概念を理解することができます。
さらに、ドメイン適応は、ディープラーニングの基本的な問題の1つを解決するのに役立ちます。大規模なネットワークを高い認識品質でトレーニングするには、非常に大量のデータが必要です。 1つの解決策は、事実上無制限の量で生成できる合成データにドメイン適応方法を使用することです。
適用される問題では、多くの場合、1つのドメインのデータのみがトレーニングに使用でき、モデルを別のドメインに適用する必要があります。 たとえば、写真の美的品質を決定するネットワークは、アマチュアのWebサイトから収集されたネットワーク上で利用可能なデータベースでトレーニングできます。 そして、このネットワークを通常の写真で使用する予定であり、その品質のレベルは、専門の写真サイトの写真のレベルとは平均して異なります。 解決策として、通常のラベルのない写真にモデルを適合させることを検討できます。
このような理論上および応用上の問題は、ドメイン適応分野にあります。 この記事では、ディープラーニングに基づいたこの分野の主要な研究と、さまざまな方法を比較するためのデータセットについて説明します。 ディープドメイン適応の主なアイデアは、ソースドメインでディープニューラルネットワークをトレーニングすることです。これにより、イメージは、ターゲットドメインで使用されると高品質が得られるような埋め込み(通常はネットワークの最後の層)に変換されます。
コアベンチマーク
機械学習のどの分野でもそうであるように、一定期間の領域適応には一定量の研究が蓄積されており、それらを互いに比較する必要があります。 このために、コミュニティはデータセットを開発します。データセットは、モデルがトレーニングされるトレーニング部分と、テスト部分で比較されます。 深い領域適応のための研究の領域はまだ比較的新しいという事実にもかかわらず、これらの記事で使用されている記事とデータベースはすでにかなり多数あります。 合成データのドメインを「本物」に適合させることに焦点を当てて、主なものをリストします。
フィギュア
どうやら、 Yann LeCun (ディープラーニングの先駆者の1人、Facebook AI Researchのディレクター)によって制定された伝統によれば、コンピュータービジョンでは、最も単純なデータセットは手書きの数字または文字に関連付けられています。 画像認識モデルを実験するために最初に登場した数字のデータセットがいくつかあります。 ドメイン適応に関する記事では、ソースとターゲットのドメインのペアでさまざまな組み合わせを見つけることができます。 これらのデータセットの中:
- MNIST-手書きの数字、追加のプレゼンテーションは必要ありません。
- USPS-低解像度の手書き数字。
- SVHN -Googleストリートビューでの家番号。
- 名前が示すように、 シンセ番号は合成番号です。
「現実の」世界で使用する合成データのトレーニングのタスクの観点から、最も興味深いのはペアです:
- ソース:MNIST、ターゲット:SVHN;
- ソース:USPS、ターゲット:MNIST;
- ソース:シンセ番号、ターゲット:SVHN。

ほとんどの方法には、「デジタル」データセットに関するベンチマークがあります。 しかし、他のタイプのドメインは、すべての記事から遠く離れたところにあります。
オフィス
このデータセットには、31のカテゴリのさまざまなアイテムが含まれています。各カテゴリは、Amazonの画像、Webカメラの写真、デジタルカメラの写真の3つのドメインで表されます。

ターゲットドメインに背景と品質を追加することにモデルがどのように反応するかを確認するのに役立ちます。
交通標識
合成データでモデルをトレーニングし、それを「実際の」データに適用するための別のデータセットのペア:
- 出典:Synth Signs-道路上の実際の標識のように見えるように生成された道路標識の画像。
- ターゲット: GTSRBは、ドイツの道路からの標識を含むかなりよく知られている認識ベースです。

このデータベースのペアの特徴は、Synth Signsからのデータが「実際の」データと非常によく似ているため、ドメインが非常に近いことです。
車の窓から
セグメンテーション用のデータセット。 かなり興味深いカップル、実際の条件に最も近い。 ソースデータはゲームエンジン(GTA 5)を使用して取得され、ターゲットデータは実際のものです。 自動運転車で使用されるモデルを訓練するために、同様のアプローチが使用されます。

VisDA
このデータセットは、ECVCおよびICCVに関するワークショップの一部であるVisual Domain Adaptation Challengeで使用されます。 ソースドメインには、飛行機、馬、人など、CADを使用して生成されたマークアップされたオブジェクトの12のカテゴリが含まれます。 ターゲットドメインには、ImageNetから取得した同じ12のカテゴリからのラベルなしの画像が含まれています。 2018年に開催されたコンテストでは、13番目のカテゴリ「不明」が追加されました。
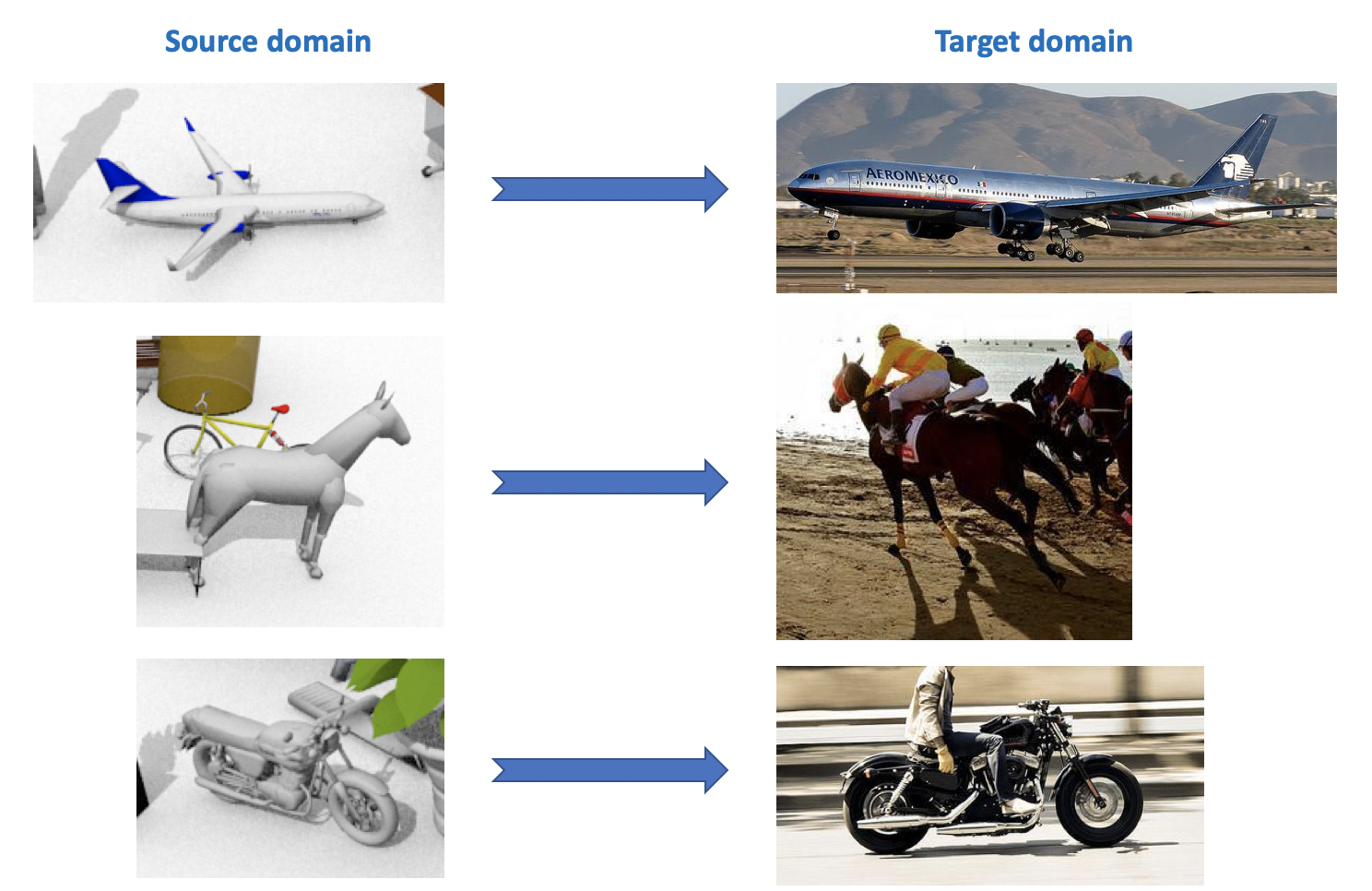
上記のすべてからわかるように、ドメイン適応のための非常に多くの興味深く多様なデータセットがあります。さまざまなタスク(分類、セグメンテーション、検出)およびさまざまな条件(合成データ、写真、ストリートビュー)のためにそれらのモデルをトレーニングおよびテストできます。
深いドメイン適応
ドメイン適応方法にはかなり広範囲かつ多様な分類があります(たとえば、こちらを参照)。 この記事では、主要な機能に応じてメソッドを簡単に分割します。 ディープドメイン適応の最新の方法は、3つの大きなグループに分けることができます。
- 不一致ベース :損失関数にこの距離を導入することにより、ソースドメインとターゲットドメインのベクトル表現間の距離を最小化することに基づくアプローチ。
- 敵対ベース :これらのアプローチは、GANで導入された敵対損失関数を使用して、ドメイン不変ネットワークを訓練します。 このファミリーのメソッドは、ここ数年で積極的に開発されてきました。
- 敵対的な損失を使用しないが、不一致ベースのファミリーのアイデア、および深層学習からの最新の開発を適用する混合方法 :自己集合、新しい層、損失関数など これらのアプローチは、VisDAコンペティションで最高の結果を示しています。
私の意見では、各セクションから、過去1〜3年間に得られたいくつかの基本的な結果が考慮されます。
不一致ベース
モデルを新しいデータに適応させる問題が発生した場合、最初に頭に浮かぶのは、微調整の使用です。 新しいデータでモデルを再トレーニングします。 これを行うには、ドメイン間の不一致を考慮してください。 このタイプのドメイン適応は、クラス基準、統計基準、およびアーキテクチャ基準の3つのアプローチに分類できます。
クラス基準
このファミリのメソッドは、主にターゲットドメインのタグ付きデータにアクセスするときに使用されます。 クラス基準の一般的なオプションの1つは、 ディープ転送メトリック学習アプローチです。 名前が示すように、それはメトリック学習に基づいており、その本質は、特定のメトリックに従ってこの表現で1つのクラスの代表が互いに近くなるようなニューラルネットワークから取得したベクトル表現を訓練することです(ほとんどの場合、 またはコサインメトリック)。 ディープトランスファーメトリックラーニング(DTML)の記事では、用語の合計で構成される損失を使用してこのアプローチを実装しています。
- 1つのクラスの代表が互いに近接している(クラス内のコンパクトさ)。
- 異なるクラスの代表間の距離の増加(クラス間分離性);
- ドメイン間の最大平均不一致(MMD)メトリック。 このメトリックは統計基準ファミリーに属しますが(以下を参照)、クラス基準でも使用されます。
ドメイン間のMMDは次のように記述されます
どこで -私たちの場合、これはいくつかのコアです-ネットワークのベクトル表現、 -ソースドメインからのデータ、 -ターゲットドメインからのデータ。 したがって、トレーニング中にMMDメトリックを最小化する場合、そのようなネットワークが選択されます そのため、両方のドメインの平均ベクトル表現が近くなります。 DTMLの主なアイデア:
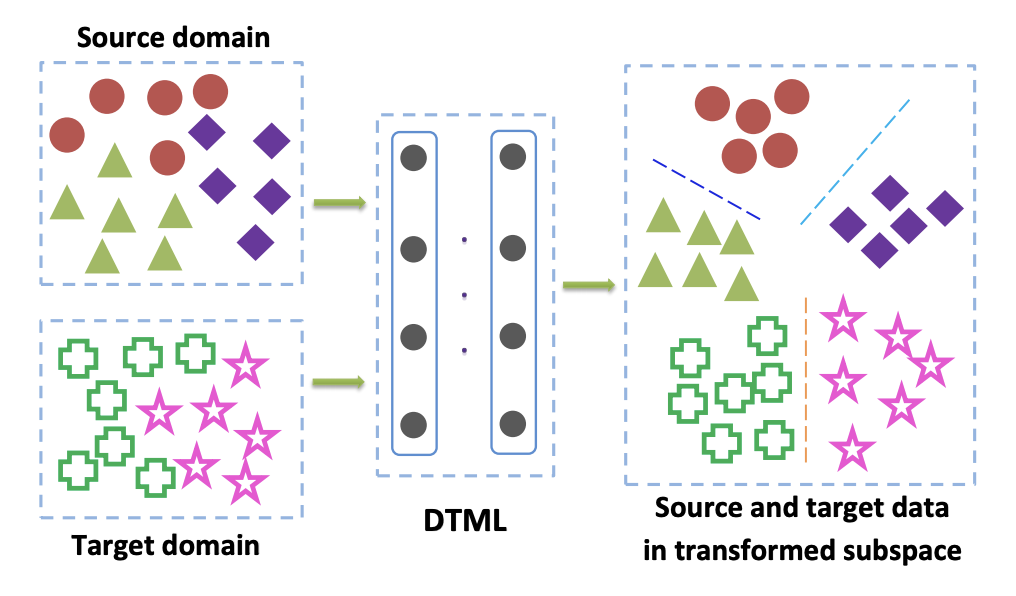
ターゲットドメインのデータにラベルが付けられていない場合(教師なしドメイン適応)、「 クラスウェイトバイアスの考慮:教師なしドメイン適応の重み付き最大平均不一致」で説明されている方法は 、ソースドメインでモデルをトレーニングし、それを使用して擬似ラベル(疑似-ラベル)ターゲットドメイン。 つまり ターゲットドメインからのデータはネットワークを介して実行され、結果は擬似ラベルと呼ばれます。 次に、ターゲットドメインのマークアップとして使用されます。これにより、MMD基準を損失関数に適用できます(異なるドメインを担当するコンポーネントに異なる重みを付けて)。
統計的基準
このファミリーに関連する方法は、教師なしドメイン適応問題を解決するために使用されます。 ターゲットドメインが割り当てられていない場合は多くのタスクで発生し、この記事の後半で説明するドメイン適応のすべての方法は、まさにこのような問題を解決します。
統計的基準に基づくアプローチでは、ソースドメインとターゲットドメインのデータから取得したネットワークのベクトル表現の分布の差を測定しようとします。 次に、計算された差を使用して、これら2つの分布をまとめます。
そのような基準の1つは、前述の最大平均不一致(MMD)です。 そのバリアントは、いくつかの方法で使用されます。
- 深層適応ネットワーク(DAN) ;
- 共同適応ネットワーク(JAN) ;
- 残留転送ネットワーク(RTN) 。 RTNは、ペアMNIST-> SVHNに対して良好な結果を示しています。ターゲットドメインでの精度は90.66%です。
これら3つの方法の図を以下に示します。 それらでは、MMDバリアントを使用して、ソースドメインとターゲットドメインに適用された畳み込みニューラルネットワークの層の分布の差を決定します。 それぞれがMMD修正を畳み込みネットワークのレイヤー間の損失として使用していることに注意してください(図の黄色の数字)。

CORAL基準(CORrelation ALignment)とDeep CORALネットワークの助けを借りたその拡張は、ドメイン間の2次統計が最大に一致するように、このようなデータ表現を学習することを目的としています。 このために、ネットワークのベクトル表現の共分散行列が使用されます。 場合によっては、両方のドメインの2次統計の収束により、MMDよりも優れた適応結果を得ることができます。
どこで フロベニウス行列ノルムの二乗であり、 そして -ソースドメインとターゲットドメインからの共分散行列データ -ベクトル表現の次元。
Officeデータセットでは、Deep CORALを使用したAmazonドメインとWebcamドメインのペアの適応の平均品質は72.1%です。 Synth Signs-> GTSRB道路標識ドメインでは、結果も非常に平均的です:ターゲットドメインで86.9%の精度。
MMDとCORALのアイデアの開発は、すべての注文のソースドメインとターゲットドメインからのデータの中心モーメントを比較するセントラルモーメント不一致(CMD)の基準です。 包括的( -アルゴリズムのパラメーター)。 Officeデータセットでは、AmazonドメインとWebcamドメインのペアの平均CMD適応品質は77.0%です。
アーキテクチャ基準
このタイプのアルゴリズムは、新しいドメインへの適応に関与する基本情報がニューラルネットワークのパラメーターに埋め込まれているという前提に基づいています。
多くの論文[1] 、 [2]で、レイヤーの各ペアの損失関数を使用してソースおよびターゲットドメインのネットワークをトレーニングする場合、ドメインに関して不変の情報がこれらのレイヤーの重みで研究されます。 そのようなアーキテクチャの例を以下に示します。
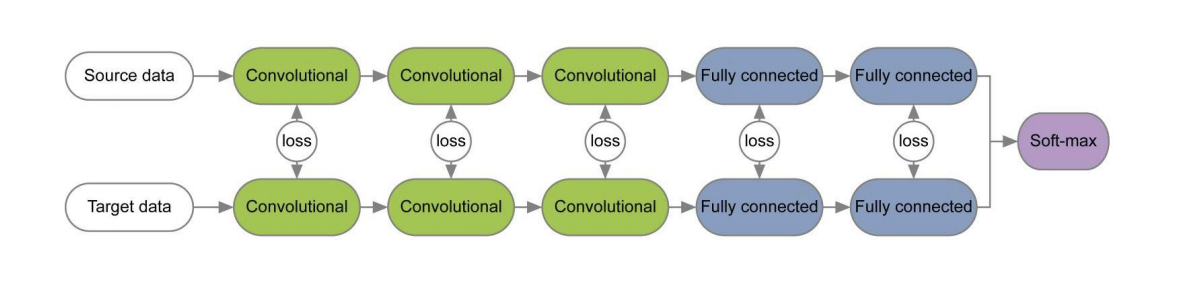
実践的なドメイン適応のためのバッチ正規化の再検討記事では、ネットワークスケールにはネットワークが学習しているクラスに関連する情報が含まれ、ドメイン情報はバッチ正規化(BN)レイヤーの統計(平均および標準偏差)に埋め込まれていることが示唆されました。 したがって、適応のために、ターゲットドメインからのデータに関するこれらの統計を再計算する必要があります。 この手法とCORALを併用すると、AmazonとWebcamのドメインのペアのOfficeデータセットでの適応の品質を最大75.0%向上させることができます。 その後、BNの代わりにインスタンス正規化(IN)レイヤーを使用すると、適応の品質がさらに向上することが示されました。 入力テンソルをバッチで正規化するBNとは異なり、INはチャネルによる正規化の統計を計算するため、バッチとは無関係です。
敵対的アプローチ
過去1〜2年で、深いドメイン適応の結果のほとんどは、敵対者ベースのアプローチに関連しています。 これは主に、 Generative Adversarial Networks(GAN)の急速な発展と人気の高まりによるものです。これは、ドメイン適応に対する敵対ベースのアプローチが、GANと同じ敵対目的関数をトレーニングで使用するためです。 これを最適化することにより、このようなディープドメイン適応手法は、ソースドメインとターゲットドメインのベクトルデータ表現の経験的分布間の距離を最小化します。 この方法でネットワークをトレーニングすることにより、彼らはドメインに関して不変にしようとします。
GANは2つのモデルで構成されます:ジェネレーター 、特定のターゲット分布からのデータが取得される出力で。 および弁別器 、トレーニングセットからのデータを使用するか、 。 これらの2つのモデルは、敵対目的関数を使用してトレーニングされます。
このようなトレーニングにより、ジェネレーターは識別器を「欺く」ことを学習し、ターゲットドメインとソースドメインの分布をまとめることができます。
敵対者ベースのドメイン適応には、ジェネレーターを使用するかどうかで異なる2つの大きなアプローチがあります。 。
非生成モデル
このファミリのメソッドの重要な特徴は、ソースおよびターゲットドメインに関して不変のベクトル表現を使用したニューラルネットワークのトレーニングです。 その後、マークされたソースドメインでトレーニングされたネットワークをターゲットドメインで使用できます。理想的には、実質的に分類品質を損なうことなく使用できます。
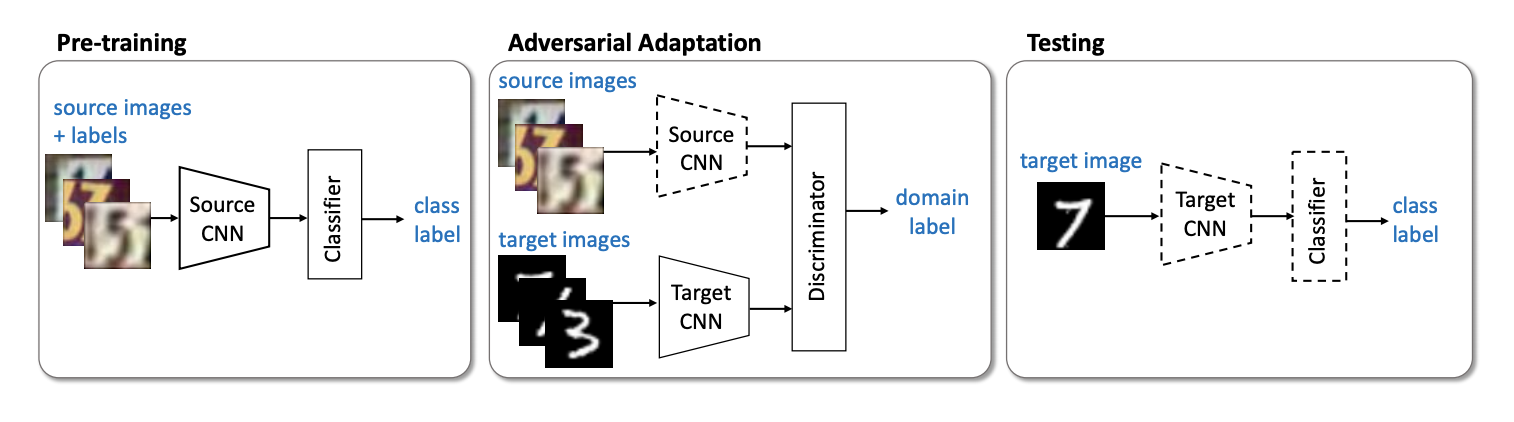
2015年に導入された、ニューラルネットワークのドメイン攻撃トレーニング(DANN)アルゴリズム ( コード )は、3つの部分で構成されています。
- メインネットワーク。これを使用して、ベクトル表現(機能抽出)が取得されます(下の図の緑の部分)。
- ソースドメインの分類を担当する「ヘッド」(図の青い部分);
- ソースドメインのデータとターゲットのデータを区別することを学習する「ヘッド」(図の赤い部分)。
勾配降下法(SGD)を使用してトレーニングする場合(図の入力矢印)、分類と領域損失は最小限に抑えられます。 さらに、ドメインを担当する「ヘッド」に学習エラーが伝播されると、勾配反転レイヤー(図の黒い部分)が使用されます。これは、通過する勾配に負の定数を乗算し、ドメイン損失を増加させます。 これにより、両方のドメインでのベクトル表現の分布が近くなります。
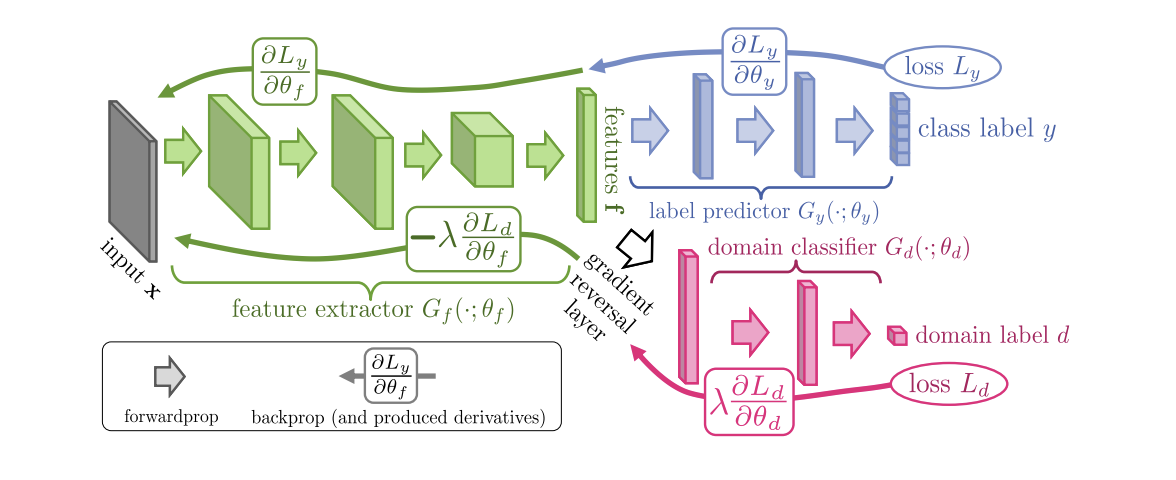
DANNベンチマークの結果:
- 一対のデジタルドメインシンセ番号-> SVHN:91.09%。
- Synth Signs-> GTSRB道路標識では、88.7%のスコアでCORALを超えています。
- Officeデータセットでは、AmazonドメインとWebcamドメインのペアの平均適応品質は73.0%です。
非生成モデルファミリの次の重要な代表は、 Adversarial Discriminative Domain Adaptation(ADDA)メソッド ( code )です。これは、ソースドメインのネットワークとターゲットドメインのネットワークの分離を伴います。 このアルゴリズムは、次の手順で構成されます。
- まず、ソースドメインの分類ネットワークを分類します。 そのベクトル表現を示します 、そして -ソースドメイン。
- ここで、前の手順で学習したネットワークを使用して、ターゲットドメインのニューラルネットワークを初期化します。 彼女を聞かせて 、そして -ターゲットドメイン。
- 敵対的なトレーニングに移りましょう:差別者をトレーニングします 固定で そして 次の目的関数を使用します。
- 弁別器の凍結と再訓練 ターゲットドメイン上:
手順3と4を数回繰り返します。 ADDAの本質は、まずラベル付けされたソースドメインで適切な分類器をトレーニングし、次に敵のトレーニングを使用して、両方のドメインの分類器のベクトル表現が近くなるようにそれを適応させることです。 グラフィカルに、アルゴリズムは次のように表すことができます。
デジタルドメインのペアでは、USPS-> MNIST ADDAはターゲットドメインで90.1%の精度の結果を示しました。
ADDAの修正は、今年のICML 2018 M-ADDA:ディープメトリックラーニングによる教師なしドメイン適応 ( コード ) で導入されました 。
元のアルゴリズムの主なアイデアは異なるドメインのベクトル表現をまとめることであるため、M-ADDAの作成者はメトリック学習を使用して、クラスが メトリック。 これを行うには、ADDAのステップ1で、ソースドメインでネットワークをトレーニングするときに、 三重項損失を使用します (同時に、同じクラスからの正の例間の距離を最小化し、負の例間の距離を最大化します)。 このようなトレーニングの結果、データのベクトル表現は次のように分類される傾向があります クラスター(ここで クラスの数です)。 各クラスターについて、その中心が計算されます 。
次に、ADDAのようなトレーニングがあります。 手順2〜4が実行されます。 手順4が正則化を追加した後にのみ、ターゲットドメイン上のベクトル表現が最も近いクラスターに縮小します。 、それにより、ターゲットドメインでのクラスの分離性が向上します。
ターゲットドメインのモデルトレーニングスキームを以下に示します。
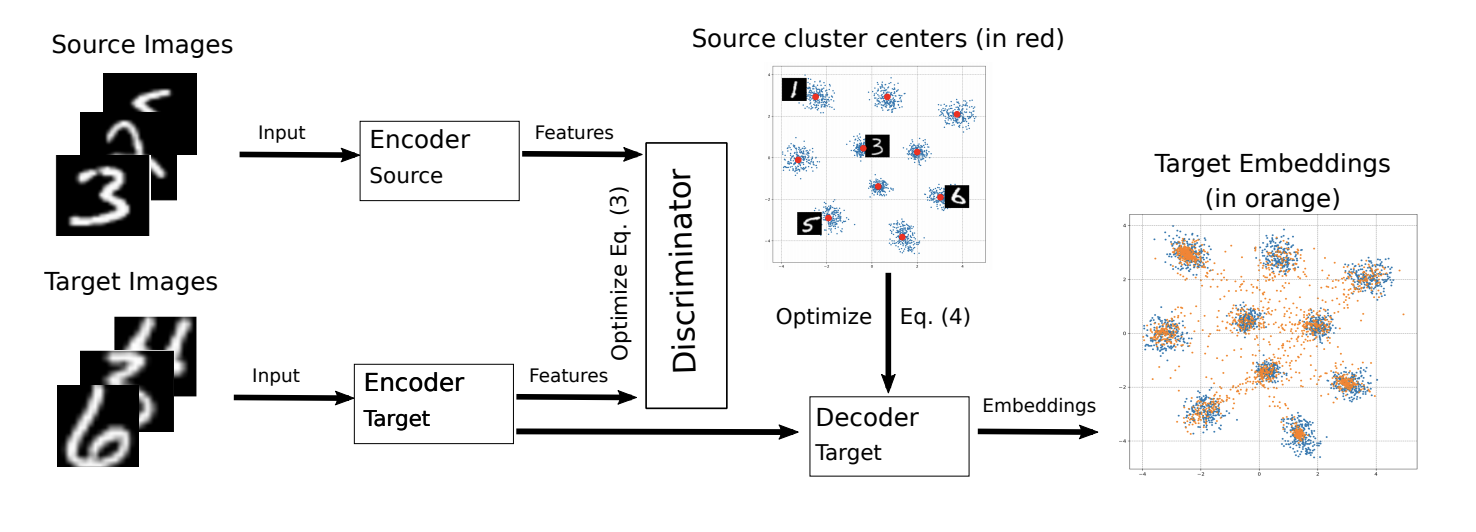
M-ADDAは、USPS-> MNISTペアの元のアルゴリズムの結果を94.0%に改善しました。
非生成ファミリーのかなり非定型の代表は、 教師なしドメイン適応 ( コード ) メソッドの最大分類子不一致です 。 彼はまた、ソースとターゲットのドメインで互いに近くなるように、そのようなベクトル表現(ジェネレーター)を訓練します。 ただし、弁別器として、このメソッドは、ジェネレーターでトレーニングされた2つの分類器間の予測の違いを使用します。
ジェネレーターをしましょう 一種の畳み込みネットワークであり、 そして -ジェネレーターの出力を入力特徴ベクトルとして使用する2つの分類子。 メソッドのアイデアは 、 そして ソースドメインで学ぶ 次に、ターゲットドメインでの不一致を最大化するように分類子が再トレーニングされます。 その後、不一致が最小になるようにジェネレーターが調整されます。 そして最後に更新されます そして 。
説明からわかるように、アルゴリズムはミニマックスの敵対的手順に基づいて構築されており、ネットワークをもたらすはずです ドメインに関して不変。
不一致の尺度(Discrepancy Loss)が使用されます
どこで -クラスの数 -ソフトマックス値 分類子のクラス そして それに応じて。
より正式には、このメソッドは3つのステップで構成されます。
- A. ソースドメインでトレーニングされています 、 そして 。
- B. ジェネレーターは修正されており、分類器の不一致はターゲットドメインからのデータで最大化されます。
- C. 現在、分類子が修正され、ジェネレーターパラメーターは不一致の損失を最小限に抑えるようにトレーニングされています。
3つのステップすべてが繰り返されます。 回(アルゴリズムパラメーター)。 ステップBおよびC:
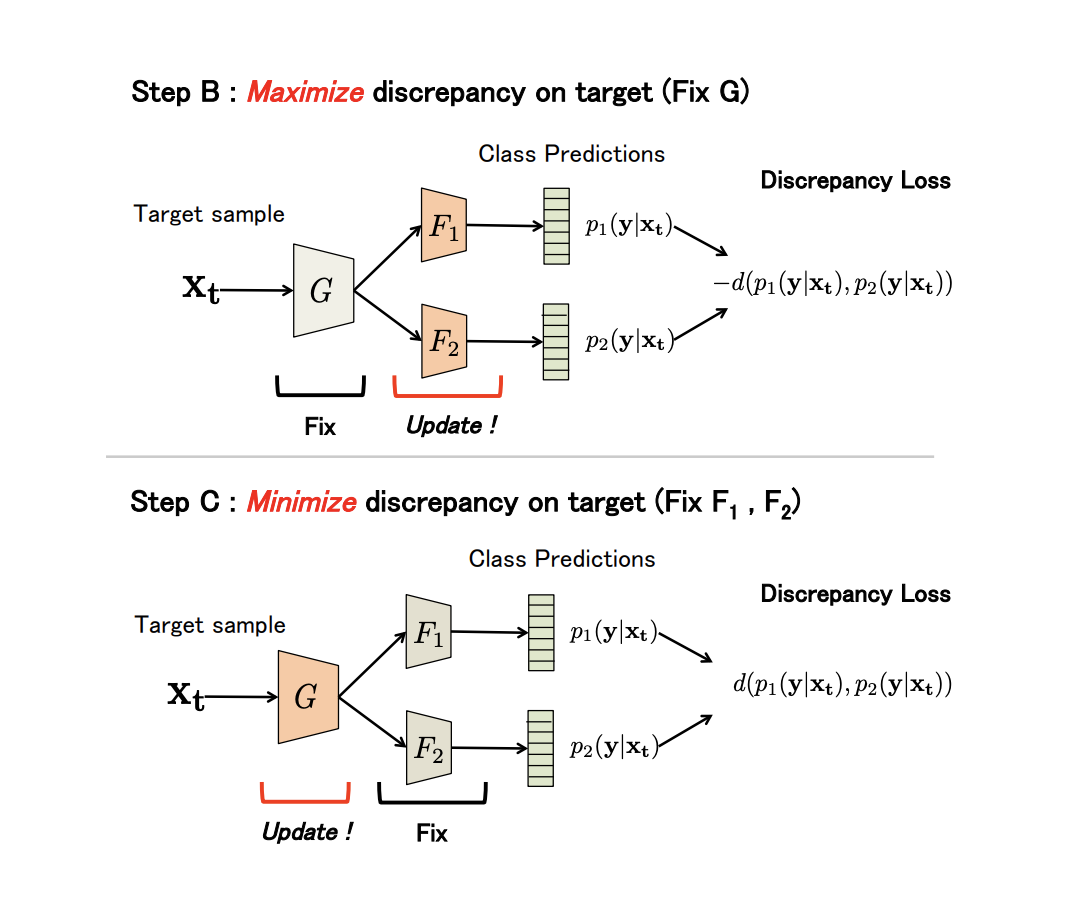
実験の結果:
- USPSデジタルドメインのペア-> MNIST:94.1%。
- 道路標識についてSynth Signs-> GTSRBメソッドは、以前のすべてのメソッドよりも優れています:94.4%。
- VisDAに基づくと、Unknownクラスを含まない12のカテゴリの品質の平均値は71.9%です。
- GTA 5の場合->都市の景観:平均IoU = 39.7%; Synthiaの場合->都市の景観:平均IoU = 37.3%
また 、非生成モデルのファミリーからの次の興味深いアルゴリズムにも注意を払うことができます。
今のところこれで停止します。
ドメイン適応、不一致ベースのアプローチの基本データセット、クラス基準、統計基準、アーキテクチャ基準、および敵ベースの方法の最初の非生成ファミリーを調べました。 これらのアプローチのモデルは、ベンチマークで良好なパフォーマンスを示し、多くの適応タスクに適用できます。 次の部分では、最も複雑で効果的なアプローチを検討します:生成モデルと混合非敵対者ベースの方法。