
良い一日。
今日は、トレーニング資料の分析をマスターしようとする試み、これらのドキュメントの品質に対する苦労、および私たちが経験した不満についてお話します。 「私たち」は、MSTUの学生です。 N.E.バウマン。 興味があれば、猫へようこそ!
挑戦する
統計指標によってトレーニング資料(ガイドライン、教科書など)の品質を評価します。 そのような指標は多数ありましたが、そのうちのいくつかを以下に示します。「理想」からの章数の偏差(5に等しい)、ページあたりの平均文字数、ページあたりのスキームの平均数など。 そんなに難しくないよね? しかし、これは始まりに過ぎません。さらに、成功した場合には、オントロジーと意味解析の構築を待っていたからです。
ツールとソースデータ
問題はソース資料にあり、それらはすべてPDFのマニュアル/教科書でした。 むしろ、問題は素材自体にあるのではなく、PDFと変換の品質にもありました。
PDFを使用するために、 pdfminer.sixが選択された役割にPythonとファッショナブルな若者ライブラリを使用することが決定されました。
物語
一般に、最初はPython用のさまざまなライブラリを試しましたが、それらはすべてキリル文字にあまり馴染みがなく、文献はロシア語で書かれています。 さらに、最も単純なライブラリーはテキストを引き出すことしかできませんでした。 pdfminer.sixに落ち着いたので、プロトタイプを作成し、実験し、楽しんでいます。 幸いなことに、ドキュメントから例を開始するには十分でした。
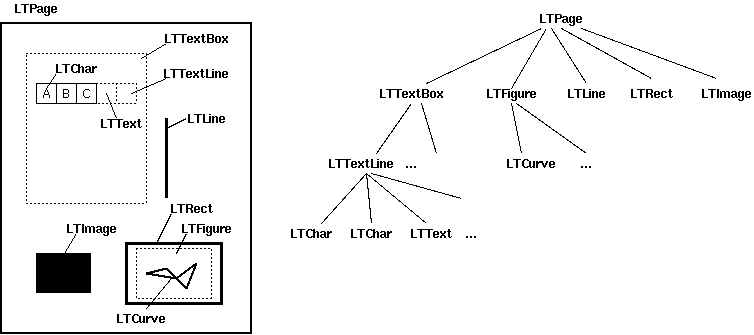
テキスト、画像、表などを含むPDFドキュメントを作成しました。 すべてがうまくいき、ドキュメントから任意の要素を簡単に引き出すことができました。
ここでは、ドキュメントページがビューでどのように表示されるかを示します
文書とのやり取りの小さな例を挙げましょう:文書のテキストを取得します。
file = open(path, 'rb') parser = PDFParser(file) document = PDFDocument(parser) output = StringIO() manager = PDFResourceManager() converter = TextConverter(manager, output, laparams=LAParams()) interpreter = PDFPageInterpreter(manager, converter) for page in PDFPage.get_pages(file): interpreter.process_page(page) converter.close() text = output.getvalue() output.close()
ご覧のとおり、ドキュメントからテキストを取得するのは非常に簡単です。 相互作用は、以下のスキームに従って実行されます
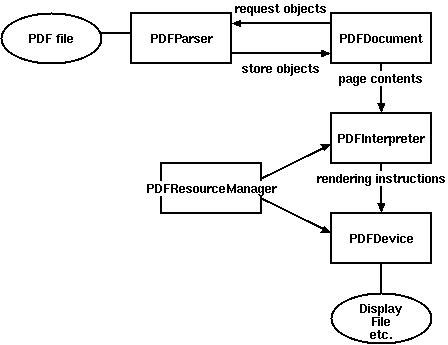
なぜうまくいかなかったのですか?
すべての実験は成功し、テストPDFのすべてが正常でした。 結局のところ、すべてを壊すことは簡単な作業であり、アイデアは厳しい現実にぶつかりました。
実験の後、私たちはいくつかの本当の教科書を取り、何でもうまくいかない可能性があることを見つけました。
最初に気づいたのは、プログラムによってカウントされた画像の数が現実と一致せず、テキストの一部が単に失われていることです。
文書内のテキストの一部(場合によっては多く)がテキストの形式で表示されず、どのように発生したのかは不明であることが判明しました。 この事実は、文字/単語/フレーズの頻度分布、セマンティクス、および実際に他の種類のテキスト分析の分析をすぐに一掃しました。
これらのドキュメントの変換または作成中に予期しないことが発生した可能性がありますが、「正しく」作成する必要のない人がいた可能性があります。 残念ながら、そのような資料の大半があり、そのような分析の考えに失望をもたらしました。
文学
pdfminer.sixリポジトリーのドキュメンテーションセクションは、記事の作成と参照として使用されました。