
今日は自然言語のような興味深い話題に触れます 。 現在、この分野に多くのお金が投資されており、多くのさまざまな問題を解決しています。 業界だけでなく、科学界の注目を集めています。
車は考えることができますか?
研究者は、自然言語分析を基本的な質問に関連付けます。機械は考えることができますか? 有名な哲学者ルネ・デカルトは明らかに否定的な答えを与えました。 XVII世紀の技術の発展レベルを考えると、驚くことではありません。 デカルトは、機械はどのように考えているのかわからず、考えることを決して学ばないと信じていました。 機械は、自然な音声を使用して人と通信することはできません。 私たちが彼女に単語の使用方法と発音方法を説明しても、それはまだ記憶されたフレーズ、標準的な答えです-マシンはそれらを超えません。
チューリング試験
それから何年も経ち、テクノロジーは大きく変化し、20世紀にはこの問題が再び重要になりました。 1950年の有名な科学者アランチューリングは、機械が考えられないことを疑い、テストのために彼の有名なテストを提供しました。
伝説によると、テストのアイデアは、学生パーティーで実践されたゲームに基づいています。 会社の2人の男(男と女)が別々の部屋に入り、残りの人はメモを使って彼らとやり取りしました。 プレーヤーの仕事は、彼らが誰を扱っているかを推測することでした:男性または女性。 そして、女の子と一緒の男は、他のプレイヤーを惑わすためにお互いのふりをしました。 チューリングはかなり簡単な修正を加えました。 彼は、隠されたプレーヤーの1人をコンピューターに置き換え、参加者に、人や機械と対話する相手を認識するよう招待しました。
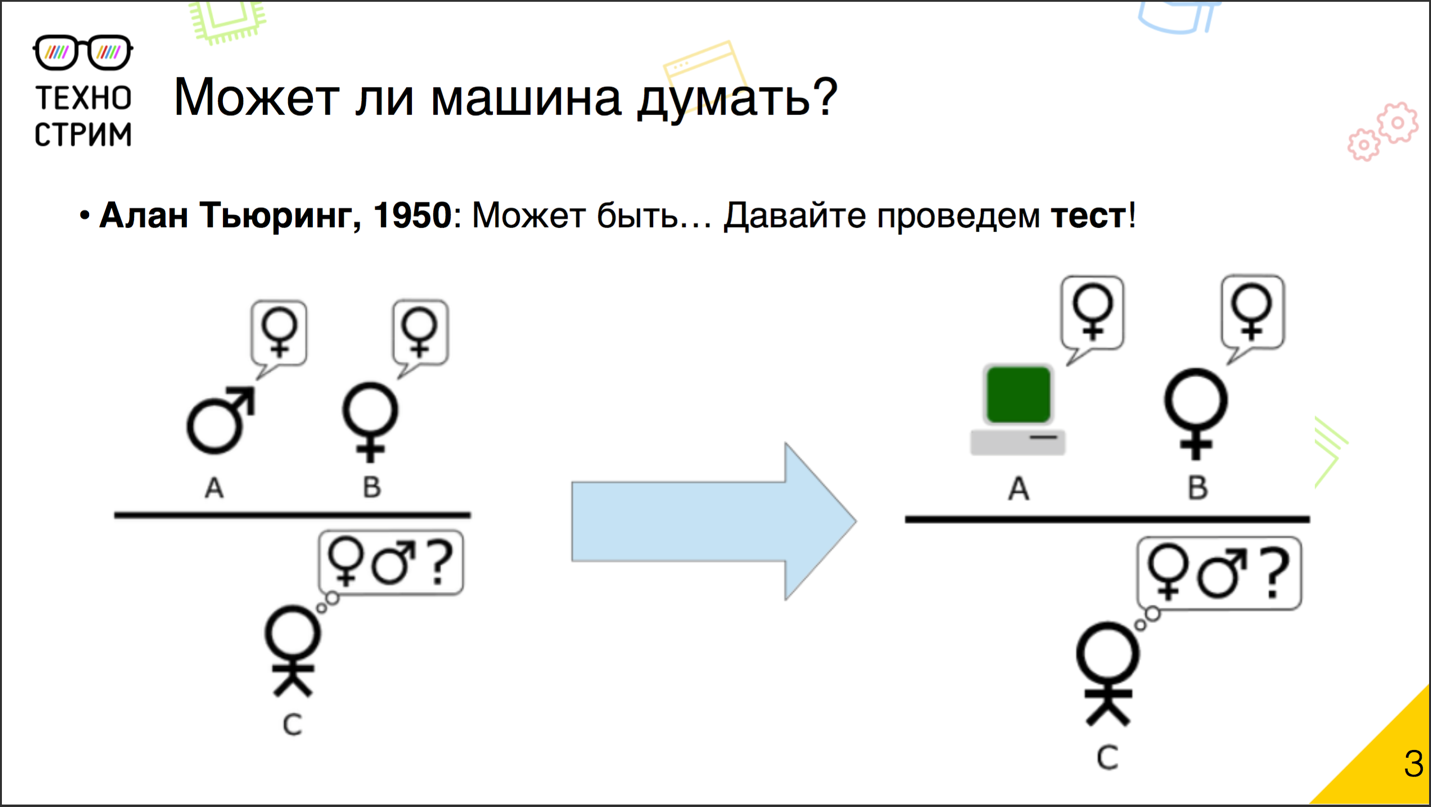
チューリングテストは、半世紀以上前に発明されました。 プログラマーは、彼らの頭脳がテストに合格したと繰り返し述べています。 毎回、これが真実かどうかについて、物議を醸す要件と疑問が生じました。 誰かがメインのチューリングテストを管理したかどうかの公式の信頼できるバージョンはありません。 そのバリエーションのいくつかは実際に正常に完了しています。
ジョージタウン実験
1954年、 ジョージタウンの実験は合格しました。 ロシア語からフランス語に60文を自動的に翻訳するシステムを示しました。 主催者は、たった3年でグローバルな目標を達成したことを確信していました。機械翻訳の問題を完全に解決するでしょう。 そして惨めに失敗しました。 12年後、プログラムは終了しました。 誰もこの問題を解決することができませんでした。
現代の観点から言えば、主な問題は少数の提案でした。 このバージョンでは、タスクを解決することはほとんど不可能です。 また、実験者が6万、あるいは600万の文章で実験を実施した場合、彼らはチャンスを得るでしょう。
最初のチャットボット
1960年代、最初のチャットボットが登場しましたが、これは非常に原始的なものでした。基本的に、他の人が話したことを言い直しました。 最新のチャットボットは先祖からそれほど遠くありません。 チューリングテストのバージョンの1つに合格したと考えられている有名なチャットボットのZhenya Gustmanでさえ、 cなアルゴリズムのおかげではありませんでした。 演技ははるかに有用でした:著者は彼の性格をよく考えました。
形式的オントロジー、 チョムスキー文法理論
それから正式な方法の時代が来ました。 それは世界的な傾向でした。 科学者は、すべてを形式化し、形式モデル、オントロジー、概念、関係、構文解析の一般的な規則および普遍的な文法を構築しようとしました。 次に、チョムスキー文法の理論が登場しました。 これらはすべて非常に美しく見えましたが、多くの骨の折れる手作業が必要だったため、適切な実用的なアプリケーションには達しませんでした。 したがって、1980年代には、機械学習アルゴリズムといわゆるコーパス言語学という別のクラスのシステムに注目が移りました。
機械学習とケース言語学
コーパス言語学の主なアイデアは何ですか? 十分な大きさのドキュメントのコレクションである軍団を組み立て、機械学習法と統計分析を使用して、問題を解決するシステムを構築しようとします。
1990年代、この領域は、検索が必要なカタログ化が必要な、構造化されていない多数のテキストを含むWorld Wide Webの開発により、非常に強力な推進力を受けました。 2000年代には、自然言語分析がインターネットの検索だけでなく、さまざまな問題の解決にも適用されるようになりました。 テキストを含む大規模なデータセットが登場し、多くのさまざまなツールがあり、企業はそれに多くのお金を投資し始めました。
現代のトレンド
今何が起こっていますか? 自然言語の分析で確認できる主な傾向は、教師なしで教育モデルを積極的に使用することです。 これらを使用すると、事前に決められたルールなしでコーパスのテキストの構造を識別できます。 パブリックドメインには、マーク付きであるかどうかに関係なく、品質の異なる多数の手頃な価格のケースが多数あります。 クラウドソーシングに基づいたモデルがありました。私たちは機械を使って何かを理解しようとしているだけでなく、テキストが書かれている言語をわずかな費用で決定する人々をつないでいます。 ある意味では、正式なオントロジーを使用するという考え方は復活し始めましたが、現在ではオントロジーはクラウドソースの知識ベース、特にLinked Open Dataに基づくデータベースを中心に展開しています。 これはナレッジベースのセット全体であり、その中心は、クラウドソーシングモデルが実装されているWikipedia DBpediaの機械可読バージョンです。 世界中の人々がそこに何かを追加できます。
約6年前、NLP(自然言語処理)は主に他の分野の技術と方法を吸収していましたが、やがてそれらをエクスポートし始めました。 自然言語分析の分野で開発された方法は、他の分野でうまく適用され始めています。 そして、もちろん、ディープラーニングがなければどこで? 現在、自然言語を分析するとき、ディープニューラルネットワークも使用され始めており、これまでのところさまざまな成功を収めています。
NLPとは何ですか? これは、NLPが特定のタスクであると言うことではありません。 NLPは、さまざまなレベルの膨大なタスクです。 たとえば、詳細レベルごとに、次のように分類できます。

信号レベルでは、入力信号を変換する必要があります。 これは、スピーチ、原稿、印刷されたスキャンテキストなどです。 マシンで使用できる文字で構成されるレコードに変換する必要があります。
次は単語レベルです。 私たちの仕事は、一般的な言葉があることを理解し、その形態学的分析を行い、エラーがあればそれを修正することです。 コロケーションのレベルは少し高くなっています。 その上に、決定する必要がある品詞が表示され、名前付きエンティティを認識するタスクが発生します。 一部の言語では、単語を強調表示するタスクも簡単ではありません。 たとえば、ドイツ語では、単語間に必ずしもスペースが必要というわけではなく、長いレコードから単語を分離できる必要があります。
フレーズから形成された文です。 文を疑問視する場合は、必要に応じて単語の曖昧さを排除するために、時には構文解析を行い、答えを定式化するために、それらを強調する必要があります。
これらのタスクは、構文解析と生成に関連するものの2つの方向に進むことに注意してください。 特に、質問に対する答えが見つかった場合、それを読む人の観点から適切に見える提案を作成し、質問に答える必要があります。
文は段落にグループ化されています。ここでは、リンクを解決し、異なる文で言及されたオブジェクト間の関係を確立するという問題が生じます。
段落を使用すると、新しい問題を解決できます。テキストの感情的な色付けを分析し、テキストの言語を決定します。
段落はドキュメントを形成します 。 このレベルでは、最も興味深いタスクが機能します。 特に、セマンティック分析(ドキュメントとは何ですか?)、自動注釈および自動要約の生成、ドキュメントの翻訳および作成。 よく知られているSCIgenの科学記事ジェネレーターを知っていたはずです。この記事ジェネレーターは、「The Rooter:An Algorithm for the Unified and Access Point and Redundancy」という記事を作成しました。 SCIgenは定期的に科学雑誌の編集委員会をテストしています。
しかし、体全体に関連するタスクがあります。 特に、膨大な量のドキュメントを重複排除するには、その中の情報を探します。
タスクの例:OK.RUの投稿を誰に表示しますか?
たとえば、Odnoklassnikiとして知られているOK.RUプロジェクトには、ストリーム内のコンテンツをランク付けするタスクがあります。 友人やグループの誰かが投稿を行いますが、特に友人が投稿したメモを考慮すると、原則としてそのような投稿が多数あります。 あなたに最適なレコードをさまざまなレコードから選択する必要があります。 課題と機会は何ですか?
大規模なデータセットがあり、すでに20億を超える投稿があり、1日に数百万の新しい投稿が表示される場合があります。 約40の言語が記録にありますが、その中にはかなり研究が不十分なものも含まれています。 ドキュメントには多くのノイズがあります。 これらはニュースや科学記事ではなく、普通の人々によって書かれています-エラー、タイプミス、スラング、スパム、コピーアンドペースト、複製があります。 共同フィルタリングに基づいた多くのメソッドがすでにある場合、なぜコンテンツを分析しようとするのでしょうか? しかし、テープの場合、このような推奨事項はうまく機能しません。ここでは常にコールドスタートの状況が発生します。 新しい施設があります。 誰とどのように彼と交流したかはまだほとんどわかりませんが、誰に見せるか、誰に見せないかをすでに決めなければなりません。 そのため、コールドスタートタスクに従来のワークラウンドを適用し、コンテンツの推奨事項のシステムを構築します。投稿が何について書かれているかを理解するようにマシンに教えましょう。
遠くからの問題
鳥瞰図から問題を見て、メインブロックを強調します。 まず、コーパスは多言語であるため、最初にドキュメントの言語を見つけます。 カスタムテキストにタイプミスが含まれています。 したがって、テキストを標準形式にするために、ある種のタイプミス修正プログラムが必要です。 さらにドキュメントを操作するには、それらをベクトル化できる必要があります。 ケースには多くの重複があるため、 重複排除なしではできません。 しかし、最も興味深いのは、この投稿の内容を知りたいということです。 したがって、 意味解析方法が必要です。 そして、オブジェクトとトピックに対する著者の態度を理解したいと思います。 ここでは、感情的な色の分析が役立ちます。
言語定義
順番に始めましょう。 言語の定義。 教師との標準的な機械学習技術を使用します。 言語別に分類されたコーパスを作成し、分類器をトレーニングします。 原則として、単純な統計分類子は非常にうまく機能します。 これらの分類子の記号として、通常Nグラム、つまりN(たとえば3)連続した文字のシーケンスが使用されます。 文書内のシーケンスの分布のヒストグラムが作成され、それに基づいて言語が決定されます。 より高度なモデルでは、異なる次元のN-gramを使用できます。また、最近の開発から、可変長のN-gram、または著者がそれらを呼び出したインフィニグラムに注目しています。
タスクはかなり古いため、多くの既製の作業ツールがあります。 特に、これは日本語の検出ライブラリであるApache Tikaであり、最新の開発の1つはPythonパッケージLdigで 、これはinfinigramでのみ動作します。
これらの方法は、十分に大きいテキストに適しています。 段落または少なくとも5つの文がある場合、言語は99%以上の精度で決定されます。 しかし、テキストが短い場合、1つの文または複数の単語から、トライグラムに基づく古典的なアプローチは非常にしばしば誤解されます。 Infinigramsは状況を修正できますが、これは新しい分野であり、すべての言語とは異なり、すでに訓練され準備された分類器があります。
正規形式への変換
テキストの言語を定義しました。 正規の形式にする必要があります。 なんで? テキスト分析の重要なオブジェクトの1つは辞書であり、アルゴリズムの複雑さはしばしばそのサイズに依存します。 コーパスで使用されたすべての単語を取ります。 ほとんどの場合、数千語、または数億語になります。 それらをより詳しく見ると、実際にはこれらは必ずしも別個の単語ではなく、単語の形式やエラーのある単語が見つかることがあります。 辞書のサイズ(および計算の複雑さ)を減らし、多くのモデルの作業の品質を向上させるために、単語を標準形式にします。
最初にバグとタイプミスを修正します。 この領域には2つのアプローチがあります。 1つ目は、いわゆる音声マッチングに基づいています。 これが彼の主なアイデアです。 なぜ人は間違っているのですか? 彼は聞いたとおりに言葉を書くからです。 正しい単語とエラーのある単語を取り、両方がどのように聞こえ、発音されるかを書き留めると、同じオプションが得られます。 したがって、エラーは分析に影響しなくなります。
別のアプローチは、いわゆる編集距離であり、これを使用して、最も類似した類似語を辞書で調べます。 編集距離は、ある単語を別の単語にすばやく変換するために必要な変更操作の数を決定します。 必要な操作が少ないほど、より多くの単語が類似します。
そこで、エラーを修正しました。 それでも、同じロシア語では、単語には、さまざまな語尾、接頭辞、接尾辞が付いた膨大な数の正しい単語形式があります。 この辞書は非常に多く爆発します。 言葉を主な形にする必要があります。 そして、2つの概念があります。
最初の概念はステミングで、単語の基礎を見つけようとしています。 言語学者は議論することができますが、これが根であると言えます。 これは、接辞ストリッピングアプローチを使用します。 主なアイデアは、単語の最後から始めまでを単語ごとにカットすることです。 語尾、接頭辞、接尾辞を削除します。その結果、主要部分のみが残ります。 よく知られている実装、いわゆるPorter Stemmer、またはSnowballプロジェクトがあります。 アプローチの主な問題:言語学者はステマーのルールを設定しますが、これは非常に難しい仕事です。 新しい言語を接続する前に、言語研究が必要です。
さまざまなアプローチがあります。 辞書を検索するか、教師なしで教師付きモデルを構築するか、隠れマルコフ連鎖に基づく確率モデルを構築するか、単語を縮小した形に変換するニューラルネットワークをトレーニングします。
スタンミングは長い間使用されてきました。 2000年代初期からGoogleで。 おそらく最も一般的なツールは、 Apache Luceneパッケージの実装です。 しかし、ステミングには欠陥があります。 単語を最後までカットすると、一部の情報が失われます。 私たちはルートしか持っていないので、形容詞か名詞かに関するデータを失う可能性があります。 そして、時にはそれ以上のタスクを設定することが重要です。
2番目の概念は、語幹抽出の代替案であり、 補題化です。 彼女は、語を基本または語根ではなく、基本的な語彙形式、つまり補題に持って行こうとしています。 たとえば、動詞-不定詞へ。 多くの実装があり、テーマはユーザー生成テキスト、ユーザーのうるさいテキスト用に非常にうまく設計されています。 ただし、標準形式へのキャストは依然として困難であり、まだ完全には解決されていません。
ベクトル化
標準形式に導かれます。 ほぼすべての数学モデルが大きな次元のベクトル空間で機能するため、これをベクトル空間で表示します。 多くのモデルが使用する基本的なアプローチは、 ワードバッグ法です。 次元が辞書のサイズに等しいドキュメントの空間にベクトルを形成します。 各ディメンションには独自のディメンションがあり、ドキュメントには、この単語が使用された頻度のサインを記録します。 ベクターを受け取ります。 それを見つけるには多くのアプローチがあります。 いわゆるTF-IDFが支配的です。 単語の頻度(用語頻度、TF)の定義は異なります。 それは単語数かもしれません。 または、フラグ、単語を見たかどうか。 または、対数的に平滑化された単語への参照の数など、少しトリッキーです。 そして、ここが最も興味深いものです。 文書でTFを定義したら、それを逆文書頻度(IDF)で乗算します。 IDFは通常、エンクロージャー内の文書数の対数を単語が表示されている文書数で割って計算されます。 以下に例を示します。 私たちは、軍団のすべてすべての文書で使用されている言葉に出会いました。 明らかに、対数はゼロになります。 私たちはそのような言葉を付け加えません:それは情報を運ばず、すべての文書にあります。
ワードバッグアプローチの利点は何ですか? 実装が簡単です。 しかし、彼は語順に関する情報を含む情報の一部を失います。 そして今、彼らは単語の順序がどれほど重要であるかというトピックに関する多くのコピーを破壊し続けています。 有名な例が1つあります-マスターヨーダです。 彼は文に単語をランダムに入れます。 ヨーダのスピーチは珍しいですが、私たちはそれを自由に理解しています。つまり、人間の脳は、注文を失っても情報を十分に簡単に回復します。
ただし、この情報は重要な場合があります。 たとえば、感情的な色付けを分析する場合、「いい」または「ない」という言葉が何を指しているのかは、比較的重要です。 次に、単語の袋と一緒に、N-gramの袋が役立ちます。単語だけでなくフレーズも辞書に追加します。 これは組み合わせの爆発につながるため、すべてのフレーズを紹介しませんが、しばしば使用される統計的に有意なペアまたは名前付きエンティティに対応するペアを追加でき、これにより最終モデルの品質が向上します。
「単語の袋」が情報を失うか歪める可能性がある状況の別の例-単語は同義語またはいくつかの異なる意味を持つ単語(たとえば、ロック)です。 一部では、これらの状況により、たとえば有名なword2vecやよりファッショナブルなskip-grammなど、「 単語のベクトル表現 」を構築する方法を処理できます。
重複排除
ベクトル化。 次に、重複からケースをクリーンアップします。 原理は明確です。 ベクトル空間にはベクトルがあり、それらの近接度を決定し、コサインを取得できます。他の近接度メトリックも使用できますが、通常はコサインを使用します。 余弦が1に近い共通グループのドキュメントを結合します。
すべてがシンプルで理解しやすいように思えますが、1つだけあります。20億のドキュメントがあります。 20億を20億倍すると、余弦を数え終わることはありません。 コサインを計算するための候補をすばやく選択し、徹底的な検索を排除できる最適化が必要です。 そして、ここでローカルに敏感なハッシュが役立ちます。 標準ハッシュ関数は、ハッシュスペースにデータを均一に拡散します。 ローカルに敏感なハッシュは、オブジェクトのスペースに同様のオブジェクトを密接に配置します。 ある程度の確率で、彼は通常それらに同じハッシュを与えることができます。
さまざまな類似性メトリックのローカルに敏感なハッシュを計算するための多くの手法があります。 コサインに関しては、 ランダム射影法がよく使用されます。 ランダムなベクトルからランダムな基底を選択します。 基底ベクトルの1つを使用してドキュメントのコサインを検討します。 ゼロより大きい場合、単位を設定します。 ゼロ未満またはそれに等しい-ゼロを設定します。 次に、それを2番目の基底ベクトルと比較し、もう1つ0または1を取得します。 基礎にあるベクトルの数-終了するビットの数。これがハッシュです。
利点は何ですか、なぜ機能するのですか? 2つのドキュメントが互いに余弦に近い場合、高い確率で、それらは基底ベクトルから同じ側にあります。 したがって、類似のドキュメントには1つのドキュメントが含まれる可能性が高くなります。 それにもかかわらず、排出があります。 それらを修正するには、手順を繰り返します。 実際には、通常2回実行します。 最初に、24ビットハッシュを計算し、ほとんど同一のドキュメントを多数削除します。 次に、別のハッシュを別の方法で検討しますが、すでに16ビットであり、重複を追加します。 その後、コピーは残りません。または、コピーが非常に少ないため、モデルの品質に大きな影響を与えることはできません。
セマンティック分析
そして、私たちは最も興味深いものにゆっくりと進んでいます。 ドキュメントの内容をどのように理解しますか? セマンティック分析のタスクは非常に古いです。 昔ながらのアプローチはこれです:事前に説明したオントロジーを作成し、厳密に解析し、構文ツリーのノードをオントロジーの概念にマッピングし、多くの手書きルールを作成します-など、セマンティクスを取得します。 これはすべて理論的には美しいですが、実際には機能しません。手書きのルールがたくさんある場合、機能するのは困難です。
最新のアプローチは、教師なしでのセマンティクスの分析です。したがって、隠された(潜在的な)セマンティクスの分析と呼ばれます。 このメソッド(またはメソッドファミリー)は、大規模なケースでうまく機能します-大規模なケースでのみ非表示のセマンティクスの検索を実行するのは理にかなっています。 そこには、原則として、旧式のアプローチのルールを持つシートとは異なり、色付けできるパラメーターが比較的少なく、既製のツールがあります:使用してください。
潜在セマンティックインデックス
歴史的に、潜在意味解析への最初のアプローチは潜在意味索引付けです。 アイデアはとてもシンプルです。 私たちはすでに、実証済みのマトリックス分解手法を使用して、協調的な推奨事項を解決しています。
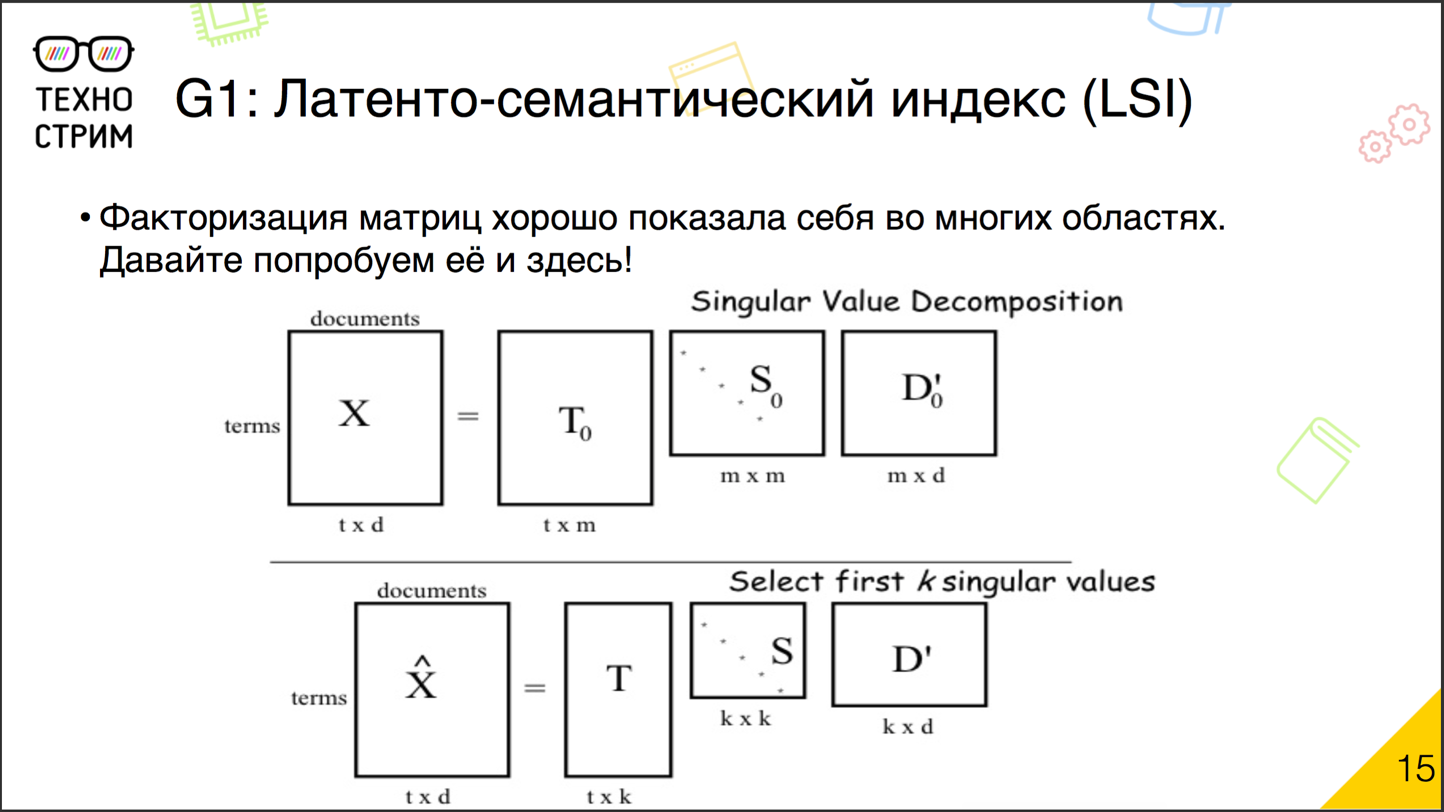
因数分解の本質は何ですか? 推奨事項には、ユーザー-アイテム(ユーザーがアイテムを気に入っている限り)の大きなマトリックスがあります。 それを小さな行列の積に分解します。 これで、ユーザーの要素とアイテムの要素のマトリックスができました。 次に、これらの2つの行列(ユーザー-因子および因子-項目)を取得し、乗算します。 新しいユーザー-アイテムマトリックスを取得します。 因数分解を正しく実行した場合、最初にレイアウトしたマトリックスに可能な限り一致します。 同じことをドキュメントで行うことができます。 マトリックス「文書-単語」または「単語-文書」を取り、それを「文書-因子」と「因子-単語」の2つのマトリックスの積に分解します。 それは簡単です、既製のツールがあります。 このアプローチでは、さまざまな意味を持つ同義語を自動的に考慮します。 ケースに多くのタイプミスがある場合、スペルミスの単語がそのような隠された要因を指していることを認識します。 最小限のパラメーター、既製のツール。1990年代の初めから、これらの手法が使用されてきました。ただ一つのこと:得られたセマンティクスがあまりにも隠されています。文書要素と単語要素のベクトルから、コーパスについて何かを言うことは非常に困難です。共同推奨のタスクでこの問題がそれほど重要でない場合、多くの問題の自然言語の分析では状況が異なります。私たちが解釈できない数学的モデルは、私たちに新しい知識を与えません。したがって、彼らは代替案を探し始めました。
確率的潜在セマンティックインデックス
- . .
. , , , . , . . , . . . ( , , ), , .
, : .
, ? , - — . « — » : « — » « — ». , , - . . . , , , , , , : , .
— TF-. TF-IDF , .
, ? . . , , , , . .

. : , . , . . . « — » « — ». これをどうやってやるの? , .
EM- . , , . . , . γ ijk : , .

. , N ik , γ ijk , — N ij . N jk , , γ ijk , . N k — . , . ijk , N ik , N jk N k γ ijk . — . γ ijk , γ ijk , , . γ ijk . . γ ijk , — γ ijk , . ., .
? -, . — : . . , , , γ ijk . , , γ ijk , . それだけです。 γ ijk . . .
? « », « » « ». . ? . ? . , , .
, , . ? . . : « — » « — », , .

? . ( , ), . . , . , .
, . .

(Latent Dirichlet Allocation, LDA) — . , , .
? : . ? , . , , , . , , , . — , . , - , , . , , : - .
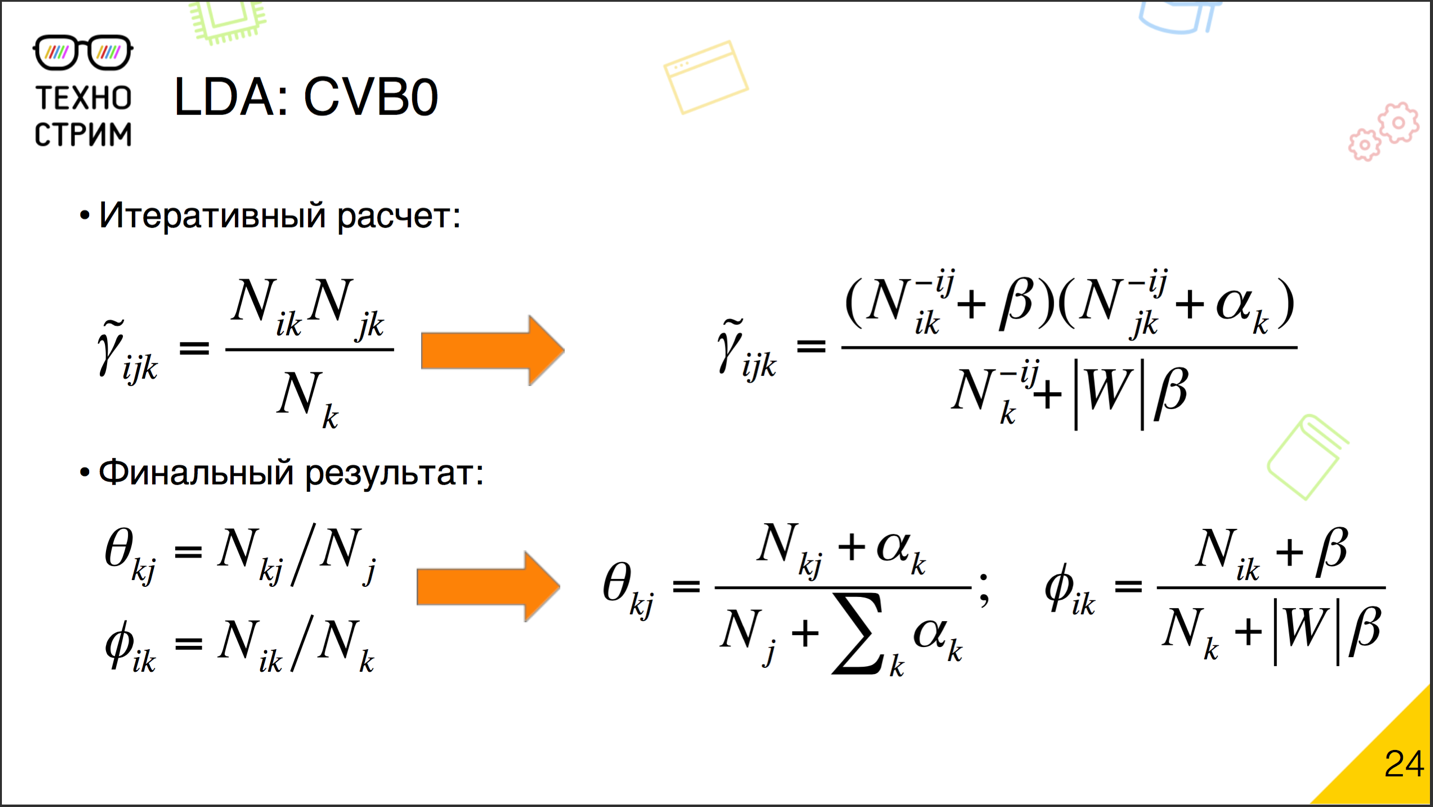
? とても簡単です。 , . γ ijk , . β , — α , , , . ? α β
: -, . , , . , .
. α α , β , β , .
, β , , ; , , , β . α . α — , — , . α . , domain specific themes, α , .
. . . , , . , .
. - .
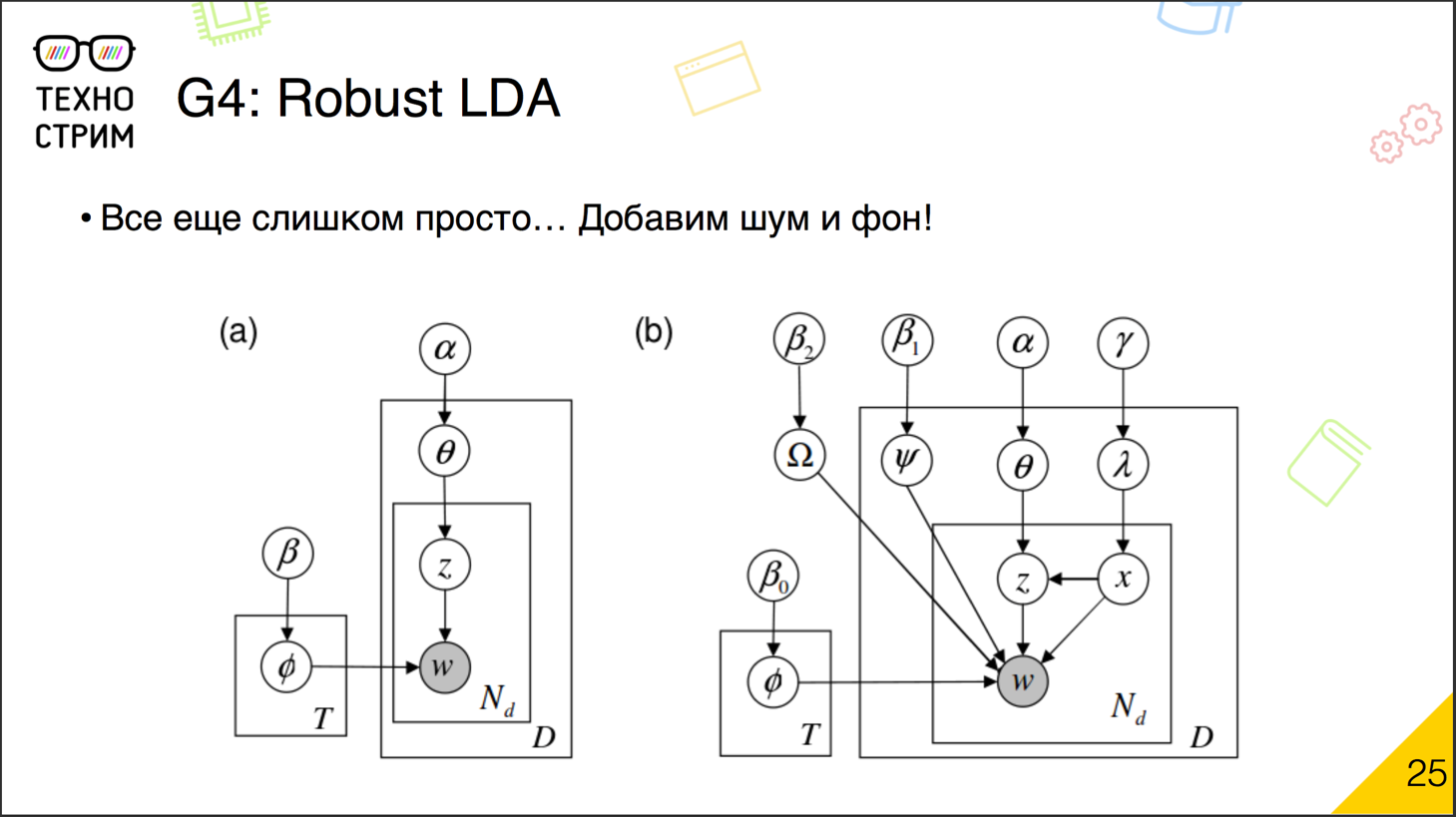
: .
. , — , . , . , -, . : , .
, — , . . — , . — , .
なぜそのような困難なのですか? , . . , , , — .

, John Snow. Snow — , Snow — . snow . , , , , . snow .
, . , , , .
これはどういう意味ですか? — , , α β . , , — , . , , . .

? . , , . γ ijk , , . γ ijk Z , . , . , , , .
, , . — γ ij . : γ ij , . , γ ij , . , , , , , — .
« — » « — » , .
? . , , LDA. α β , , PLSA. α β , — PLSA-. .
. , . . , LDA-. .

, , , . . .

. , , , , , , , , . ? -, .
, . — , 1000, 250 . - , - .

, , , - , - , , , … — , , . . , . . , , , .
?
当然。 多くの開発オプションがあります。 特に、トピック「 Additive regularizers 」は現在ロシアで動いています。 繰り返し更新の一部としてカウントする数式に新しいポストスクリプトを追加し、それぞれがプロセスをモデル化します。 一部は、重みが小さくなりすぎたトピックの一部を削除します。 ある種の背景トピックを侵食したり、逆にドメイントピックを平坦化したりします。
正則化を追加するだけでなく、生成モデルを複雑にすることを目的としたアプローチがあります。 たとえば、新しいエンティティ、タグ、作成者、ドキュメントの読者を追加し、独自のテーマ分布を持つことができ、それらに基づいて共通のものを構築しようとします。
抽象ディリクレ分布ではなく、保持したい先験的分布としてラベル付きケースに関するトピックの分布を選択すると、この教師なしLDA手法とラベル付きケースを交差させる試みがあります。
興味深いことに、生成モデルのこれらすべての確率は、実際には、行列因子分解手法です。 しかし、特異因子分解因子分解とは異なり、これらの手法は何らかの形式の解釈をサポートしています。 そのため、LDAは他の領域で使用されるようになりました。画像行列を因数分解し、それらに関する共同の推奨事項を作成します。 ソーシャルネットワークとグラフの分析の分野では、確率的ブロックモデリングのトピックがあります。 私が理解しているように、それは多かれ少なかれ独立して開発されましたが、実際には、確率的生成モデルを通して行列を因数分解することでもあります。 つまり、LDAとそれから踊るすべてのものは、自然言語の分析から他の領域にエクスポートされるものです。
数値からオフロードする技術について少し。 プロセスは簡単ですが、大きなボディで主題モデルを作成するには時間がかかります。 時間がありません 現在表示されているドキュメントのテーマを理解する必要があります。

このアプローチを使用します。テーマモデルを事前に準備します。 モデルは、トピックと単語のマトリックスに基づいています。 完成したキャッシュトピックワードマトリックスを使用すると、特定の投稿が表示されたときに、ドキュメントトピックの分布を調整できます。 定期的に更新される一般的なテーマモデルがあり、これは標準のmap reduceによって計算され、新しい投稿の連続ストリームがあります。 ストリーミング分析ツールを使用してそれらを処理し、事前に準備された「トピックワード」マトリックスに基づいて、オンザフライでトピックを決定します。 これは典型的な回路です。 本番環境のすべての機械学習アルゴリズムは、通常、次のように機能します。難しい部分はオフラインの準備であり、簡単な部分はオンラインです。
感情的な色付けの分析についてはまだ話していません。 良い:テキストの内容を理解しました;トピックの確率的分布を決定しました。 しかし、著者がトピックに対して肯定的または否定的な態度を持っているかどうかをどのように理解するのでしょうか?
原則として、教師との共同作業に基づく方法が依然としてここで支配的です。 ポジティブな感情とネガティブな感情を持つテキストのラベル付きコーパスが必要であり、その上で分類子を訓練します。 単語の袋に基づくアプローチは、多くの場合、失敗した結果につながります。 感情は時々同じ言葉で表現され、文脈が重要です。 したがって、単語のバッグの代わりに、N-gramバッグがよく使用されます。 標準的な単語またはパーティクルによって(たとえば、「not」によって)、彼らはそれが何であるかを理解しようとします。 彼らはその言葉を研究しながら、旗の前とその距離に「ない」粒子があるかどうかを調べます。 さらに、彼らは、その人がテキストを書いたとき、その人が緊張している、怒っている、または喜んでいるという追加の兆候に注意を払います。 感嘆符、キャップ、単語内に印刷できない文字がたくさんあります(おそらく汚い言語のスクリーニングです)。そして、このすべてについて分類器が訓練されます。
特に分類器を特定のサブジェクトエリア向けにトレーニングする必要がある場合は、かなりうまくいくことがあります。 一連の映画レビューがあれば、感情に関する分類を訓練することはかなり可能です。 問題は、おそらくこの分類子がレストランのレビューで機能しなくなることです。 レストランに対する態度をしばしば表す他の言葉があります。 これまでのところ、感情的な色付けの分析に対する成功したソリューションは、主に特に指向されています。
感情はしばしば変化するため、テキストのサイズは十分に重要です。 ある感情的なメッセージを含む段落または複数の文と、別の感情的なメッセージを含む文がある場合があります。 たとえば、レビューでは、好きなものとそうでないものを書くことがあります。 したがって、ドキュメントをそのような領域に分割する価値があります。
その結果、感情は中程度のテキストに最もよく定義されます。 小さすぎる-十分な情報がないというリスクがありますが、長すぎる-結果がぼやけすぎます。
非常に人気のあるSentiStrengthライブラリには、文章やテキストを打ち負かし、そこに含まれる感情を判断できるWebサービスがあります。 しかし、ここで分類タスクはバイナリではないことを言わなければなりません。原則として、これらの方法は単に「ポジティブ」または「ネガティブ」ではなく、「そのような力でポジティブです」と言います。 おそらく、これはこのスタックで最も達成度の低いタスクの1つであり、さらに多くのタスクをここで開発できます。
最後に、まだ解決されていないタスクをもう少し実行します。
手始めに、これはカスタムテキストを標準形式にキャストしています。 タイプミスやスタンプを修正できます。 これらすべてを組み合わせようとすると、しばしばひどくなります。 短いテキストについては、インフィニグラムに関連するアプローチが必要です。通常の産業用実装はまだないため、機能するかどうかは不明です。 短いテキストの主題モデリングも困難です。 言葉が少なければ少ないほど、その意味を理解するのが難しくなります。
まだ話していない別のタスク。 さて、ドキュメントがどのトピックに関連するかを理解しました。 しかし、ユーザーもいます。 目的:セマンティックプロファイルを作成します。 セマンティクスと感情を組み合わせます。 そのようなトピックや感情があることを理解するだけでは十分ではありません。 どのトピックがどのような感情を引き起こしたかを知る必要があります。
テーマモデルを経時的に調査するのは興味深いことです。テーマモデルがどのように変換されるか、新しいトピックがどのように発生するか、既存のテーマの語彙が変化するかなどです。 重複排除は、コピーを含むテキストではうまく機能しますが、これらのコピーが意図的に歪められたテキストで停止する可能性があります。つまり、スパム対策について話します。 つまり、これは多くの異なるソリューションが存在する巨大な領域ですが、さらに多くの未解決の問題があります。 誰かが機械学習に興味があり、実際の実用的なタスクを扱う場合は、歓迎します。
おわりに
最近、テキスト分析の分野では、人工ニューラルネットワークに基づく方法の導入に多くの注意が払われています。 画像分析の分野でのような圧倒的な成功は、主にテキストにとってはるかに重要なモデルの低い解釈性のために達成できませんでした。 しかし、まだ成功しています。 いくつかの一般的なアプローチを検討してください。
「意味のベクトル 。 」 Googleの2013年の調査では、2層ニューラルネットワークを使用して、コンテキストごとに単語を予測することが提案されました(後に、反対のオプションが登場しました:単語ごとのコンテキストの予測)。 主な結果は予測そのものではなく、単語に対して得られたベクトル表現でした。 著者によると、彼らは言葉の意味についての情報を含んでいた。 ベクトル表現では、単語の「代数演算」の興味深い例を見つけることができます。 たとえば、「王は男+女≈女王です。」 さらに、ベクトル化された単語は、テキストデータを他の機械学習アルゴリズムに転送する便利な形式になり、word2vecモデルの人気が大きく保証されました。
単語の意味のベクトルを使用したアプローチの重要な制限の1つは、文書ではなく単語の意味が決定されたことです。 短いテキストの場合、テキストに含まれる単語のベクトルを平均化することにより、適切な「集約された」意味を得ることができますが、長いテキストの場合、このアプローチはすでに効果がありません。 制限を回避するために、さまざまな修正が提案されました(sentence2vec、paragraph2vec、doc2vec)が、基本モデルのようには広まりませんでした。
リカレントニューラルネットワーク 。 テキストを操作する「古典的な」方法の多くは、大量の単語のアプローチに基づいています。 文中の語順情報が失われます。 多くの問題では、これはそれほど重要ではありません(たとえば、セマンティック分析など)が、逆に、結果が著しく悪化する場合もあります(たとえば、感情的な色付けや機械翻訳の分析など)。 リカレントニューラルネットワーク (RNS)に基づくアプローチは、この制限を回避できます。 RNSは、現在の単語に関する情報と、前の単語からの(および時には反対方向-次からの)同じネットワークの出口に関する情報を考慮して、単語の順序を考慮することができます。
最も成功したRNSアーキテクチャの1つは、LSTM(Long Short Term Memory)ブロックアーキテクチャです。 このようなブロックは、情報の単位を「長い」間記憶し、新しい信号が到着したときに、保存された情報を考慮して答えを出すことができます。 このアプローチは徐々に修正され、2014年にGRU( Gated Recurrent Units )モデルが提案されました。これにより、多くの場合、より少ないパラメーターで同じ(そして時にはより多くの)作業品質を達成できます。
テキストを単語のシーケンスとして考えると、それぞれがベクトル(通常はword2vecベクトル)で表され、短いテキストの分類、機械翻訳(シーケンスからシーケンスへのアプローチ)、チャットボットの開発の問題に対する非常に成功したソリューションであることが判明しました。 ただし、長いテキストには繰り返しブロックの十分なメモリがないことが多く、ニューラルネットワークの「出力」は主にテキストの末尾によって決定されます。
ネットワークジェネレーター。 画像と同様に、ニューラルネットワークを使用して新しいテキストを生成します。 これまでのところ、そのようなネットワークの結果はほとんど「ファン」ですが、それらは毎年発展しています。 この分野の進捗は、たとえばYandex.Autopoetシステム(2013年に開発)を見て、グループNeuron Defense (2016)またはNeurona (2017)のアルバムを聴くことで追跡できます。
N-gramとシンボルに基づくネットワーク 。 単語に基づいてニューラルネットワークの入力を構築することには、多くの困難が伴います。多くの単語が存在する可能性があり、エラーやタイプミスが含まれることもあります。 単語のベクトル表現は最終的にうるさいです。 これに関して、近年では、記号および/またはN-グラム(複数、通常は3つの文字のシーケンス)によるアプローチがますます人気を集めています。
たとえば、文字ベースのリカレントネットワーク( Char-RNN )は、単語(名前など)と文の両方の生成に非常に成功しています。 さらに、十分な量のデータに対して、ネットワークが単語や品詞を「学習」するだけでなく、偏位と活用の基本的なルールを「記憶」することを保証できます。
短いテキストの場合、「トライグラムの袋」アプローチを使用して、多くの問題で良い結果を得ることができます。 この場合、ドキュメントは20〜40千次元のスパースベクトル(各可能なトリグラムには独自の位置が割り当てられます)と照合され、その後、原則として次元が徐々に減少する密なネットワークによって多層処理されます。 このビューでは、システムは多くのタイプのエラーおよびタイプミスに対する耐性を提供し、分類の問題を解決し、通信の検索を成功させることができます(たとえば、質問応答システム)。
信号を処理するレベルのネットワーク 。 生信号の分析におけるニューラルネットワークの例外的な役割に注意する必要があります。 原則として、現代のシステムでの音声はリカレントネットワークを使用して認識されます 。 手書きテキストの分析では、畳み込みネットワークを使用して個々の文字を認識し、リカレントネットワークを使用してストリーム内の文字をセグメント化します。
質疑応答
質問 :ロシア語用のLdigツールはありますか?
回答 :私の意見では、ロシア人はいません。 これはPythonパッケージです。選択範囲は非常に限られています。 サイボウズラボで開発されました。 著者はテーマモデルに切り替えて、「それだけです。言語はもはや私たちにとって興味深いものではありません。」 したがって、Ldigを現在開発している人はいません。 私たちは自分自身でいくつかのステップを踏もうとしていますが、それはすべて良いマークの建物の準備に帰着します。 結果がある場合は、投稿するでしょう。 しかし、infinigramsとLdigの間、言語はほとんどありません。 90の言語を持つLangDetectとは異なります。
質問 :PLSA用のオープンツールはありますか?
回答 :ケースが比較的小さい場合、BigARTMライブラリがあります。これは、堅牢なLDAの創設者であるKonstantin Vorontsovの指導の下、モスクワで作成されています。 ダウンロード可能で、軸上で高速かつ並列に開いています。
Mr.のような、分散システム上に構築されたいくつかの実装があります。 LDA。 異なるパッケージには独自の実装があります。 SparkにはVowpal Wabbitがあります。 私の意見では、何かはマハウトにもありました。 1台のマシンのメモリに収まるケースで何かをしたい場合は、BigARTMまたはPythonモジュールを使用できます。 私の知る限り、PythonにはLDAもあります。
質問 :PLSA に関する別の質問。 MLアルゴリズムに収束の保証はありますか?
回答 :収束の数学的分析があり、それに対する保証があります。 実際には、収束しないことを見たことはありません。 むしろ、収束せず、多かれ少なかれ私たちが見ているものを説明する分布を中心に振動します。 つまり、ドキュメントは振動し始める可能性がありますが、辞書は修正されています。 通常、当惑は減少しなくなった後、反復を停止します。
質問 :ドキュメント内のトピックの出現はどのように判断されますか?
回答 :反復プロセスに基づきます。 特定の単語がこのトピックによって特定のドキュメントに持ち込まれる確率カウンターがあります。 これに基づいて、ドキュメント内のトピックのパワーを更新し、すべてを再度カウントし、トピック上のドキュメントのワードカウンターの新しい値を取得します。 そして最後に、分布を取得します。
質問 :テキストからの情報を研究するためにディープラーニングモデルが使用されていますか?
回答 :適用します。 しかし、そのような瞬間があります。 ディープラーニングの場合、よく知られていることはword2vec、doc2vec、sentence2vecです。 厳密に正式にアプローチする場合、それは実際には深層学習ではありませんが、実際には実際の深層ネットワークがあり、それらを適用しようとしています。 私はそのようなネットワークの経験が混在しています。 それらから多くのノイズがあり、実際の実用的な問題を解決しようとすると、ゲームはろうそくの価値がないことがわかります。 しかし、これは私の個人的な意見です。 人々は試みています。
質問 :ドキュメントのテーマと感情的な色付けを定義するための確立されたオープンソースライブラリはありますか?
回答 :BigARTMとVorontsovの彼に関する出版物に助言します。 そして、モスクワにいる人はおそらく彼のためにセミナーに行くことができます。 これはセマンティクスに関するものです。 感情は難しいです。 特に、アカデミックライセンスの下で、ソースコードを提供できるSentiStrengthがあります。 ただし、原則として、このようなタスクでは、主な値はコードではなく、ラベル付きのケースです。 その上で、実験、訓練することができます。 大文字小文字が区別されない場合、コードは役に立ちません。 次に、既に訓練された既製のモデル(そのようなものがある)を使用するか、ケースを作成する必要があります。
質問 :NLP に関するどの本をお勧めしますか?
回答 :テーマモデルでは、Vorontsovの記事を読むのが理にかなっています。 彼らは非常に良い概要を提供します。 NLP全般については、自然言語処理ハンドブックがあります。 かなり概観できますが、ほとんどすべてのトピックがカバーされています。
質問 :興味深いNLP製品または企業は何ですか?
回答 :私は問題を調査していませんが、おそらくそのようなものがあります。 仕事でテクニックを使用する人は? これらは主に検索エンジン(Googleなど)と大規模なテキスト企業を持つ企業です。 Facebookはおそらくその1つだと思います。
質問 :小規模なチームで競争力のあるプログラムを作成するのは現実的ですか?
回答 :本当に。 多くの未解決の質問があります。 特に新しい分野で現在利用可能なソリューションを見ても、それらは多くの場合技術的ではありません。 これは、研究室、学生によって行われます。 ソリューションは松葉杖に満ちており、効果がありません。 優れたエンジニアを採用し、完成したアカデミック製品の最適化に任せれば、素晴らしいものを手に入れることができます。 しかし、学術的な専門知識と優れたエンジニアリングスキルが共存することはめったにありません。
質問 :言語は思考をどのように制限しますか?
回答 :彼がそれを表現していない場合。 言語が思考を表現できない場合、通常は拡張されます。 言語は生きています。 未解決のタスクをテーマモデルの進化と呼んだのはなぜですか? 新しい社会現象に対して言葉がどのように現れるかをよく観察します。 言語はコミュニケーションツールです。 彼がコミュニケーションの問題の解決をやめた場合、彼は改善しています。