
ハミングコードは、この記事の目的ではありません。 彼の例を使って、コーディングのまさにその原理を紹介したいと思います。 しかし、厳密な定義、数学的定式化などはありません。 これは、より複雑なブロックコードを理解するための良い出発点です。
おそらく最も有名なハミングコード(7.4)。 これらの数字はどういう意味ですか? 2番目-情報ワードのビット数-そのまま伝えたい。 そして、最初はコードワードのサイズです。冗長性を備えた情報です。 ちなみに、「情報語」と「コード語」という用語は、エラー訂正コーディングの理論に関する7冊すべてで使用されています。
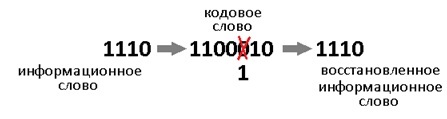
このようなコードは1つのエラーを修正します。 そして、それがどこから来たとしても。 冗長性は3ビットの情報を伝達します。これは、エラーの7つの規定の1つを示すか、そうでないことを示すのに十分です。 それはまさに私たちが待っている8つの答えです。 そして、8 = 2 ^ 3、それがすべての偶然の一致です。
コードワードを取得するには、情報ワードを多項式の形式で提示し、生成多項式g(x)で乗算する必要があります。 任意の数のバイナリ形式への変換は、多項式として表すことができます。 これは奇妙に思えるかもしれませんが、準備のできていない読者はただ1つの質問を投げかけます。 最初の結果が得られると、それは自動的に消えます。
たとえば、情報語1010、各放電の値は、多項式の係数です。

多くの本は反対のx + x ^ 3を書いています。 2桁の16進数のエントリでは、最下位桁が右に移動し、これに基づいて左/右にシフトするため、挑発に屈しないでください。 それでは、この多項式に生成多項式を掛けてみましょう。 ハミング(7.4)専用の生成多項式は、g(x)= x ^ 3 + x + 1を満たします。 彼はどこから来たの? さて、今のところ、それは神によって上から人類に与えられていると考えてください(後で説明します)。

係数を追加する必要がある場合は、モジュロ2を実行します。加算演算は、排他的論理和(XOR)、つまりx ^ 4 + x ^ 4 = 0に置き換えられます。 最後に、4つのメンバーからわかるように、乗算の結果。 バイナリ形式では、これは1001110です。したがって、ノイズの多いチャネルを介してサイドに送信するコードワードを受信しました。 情報ワード(1010)に生成多項式(1011)を通常の数値として乗算すると、別の結果1101110が得られることに注意してください。これは必要ありません。まさに「多項式」乗算が必要です。 このような乗算のソフトウェア実装は非常に簡単です。 2つのXOR演算と2つの左シフトが必要です(最初のビットは1ビットで、2番目のビットはg(x)= 1011に従って)。

次に、結果のコードワードに具体的にエラーを導入しましょう。 たとえば、3番目のカテゴリ。 破損した単語:1000110を取得します。
メッセージを解読してエラーを修正する方法は? もちろん、コードワードをg(x)に「多項式で」分割する必要があります。 それから私はXを書きません。 2を法とする減算は加算と同じであり、排他的論理和と同じであることを忘れないでください。 行こう:

繰り返しますが、ソフトウェアの実装では、複雑なものにすぎません。 分割線(1011)は、左端に3桁シフトされます。 そして、分割可能(100110)の左端の単位を(XORの助けなしではなく)削除し始め、その最下位ビットさえも見ません。 段階110100-> 0011110-> 0001000-> 0000011で配当が減少し、4番目と左の桁にユニットが残っていない場合、停止します。
完全に分割することはできませんでした。つまり、間違いがあります(もちろん)。 この場合の除算の結果は、私たちにとって不要です。 除算の残りはシンドロームであり、そのサイズは冗長性のサイズに等しいため、そこにゼロを追加しました。 この場合、シンドロームの内容は、損傷の場所を見つけるのに役立ちません。 なんて残念。 しかし、他の情報語、たとえば1100を使用する場合、同じ方法でg(x)を乗算し、1110100を取得し、同じカテゴリ1111100でエラーを導入します。g(x)で除算し、剰余と同じシンドロームを取得します011.そして、3番目のカテゴリにエラーがあるすべてのコードワードについて、このようなシンドロームが常識的に発生することを保証します。 結論は、7つのエラーすべてについてシンドロームのテーブルを作成し、それぞれを具体的に作成してシンドロームをカウントできることを示唆しています。

その結果、症候群のリストを収集し、その後、彼はどの疾患を示しているのかを示します。

これですべてが揃いました。 シンドロームを発見し、エラーを修正し、この場合も1001110を1011に分割し、待望の情報ワード1010をプライベートに受け取りました。修正後のバランスはすでに000です。シンドロームテーブルには、小さなコードの場合の生存権があります。 しかし、いくつかのエラーを修正するコードの場合、シンドロームのリストはペストのように増えます。 したがって、手元にテーブルを持たずに「エラーをキャッチする」方法を検討します。
注意深い読者は、最初の3つの症候群がエラーの位置を明確に示していることに気付くでしょう。 これは、1つのユニットの症候群にのみ適用されます。 シンドロームのユニット数は、その「重量」と呼ばれます。 繰り返しになりますが、3番目のカテゴリーの不運な誤りに戻ります。 覚えているとおり、011症候群があり、その重さは2でしたが、運が悪かったのです。 私たちの耳で気を失いましょう-コードワードの右への循環シフト。 除算0100011/1011の残りは100に等しくなります。これは「良好なシンドローム」であり、エラーが2番目のカテゴリーにあることを示します。 しかし、1つのシフトを行ったので、エラーが1に移動したことを意味します。これが全体のトリックです。 ひどい不運の場合でも、エラーが6番目のカテゴリーにある場合、3つの痛みを伴う分裂の後、汗をかいていますが、それでもエラーを見つけます-これはシンドロームテーブルを使用しなかったという理由だけで勝利です。
他のハミングコードはどうですか? ハミングコードは無限であると言えます:(7.4)、(15.11)、(31.26)、...(2 ^ m-1、2 ^ m-1-m)。 冗長性の量はmです。 それらのすべてが1つのエラーを修正し、情報語の増加に伴い、冗長性が増加します。 ノイズ耐性は弱まっていますが、干渉が弱い場合、コードは非常に経済的です。 さて、たとえば(15,11)の生成関数を見つけるにはどうすればよいですか? 合理的な質問。 巡回符号g(x)の生成多項式が剰余なしに(x ^ n + 1)を分割するという定理があります。 ここで、nはコードワードサイズです。 さらに、生成多項式は単純でなければならず(1で除算し、剰余なしでそれ自体に分割します)、その次数は冗長性のサイズに等しくなります。 ハミング(7.4)の場合:
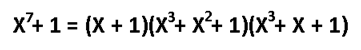
このコードには最大2つの生成多項式があります。 それらのいずれかを使用するのは間違いではありません。 他の「ハミング」には、この原始多項式の表を使用します。
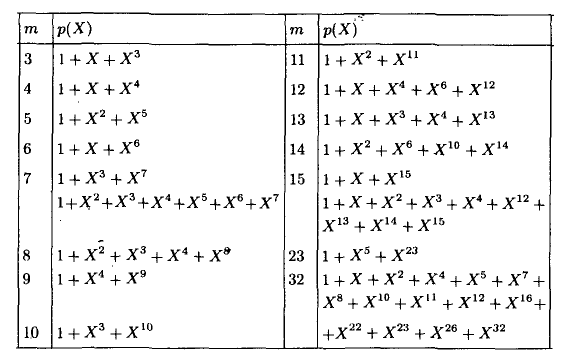
同様に、(15.11)の場合、生成多項式g(x)= x ^ 4 + x + 1。 さて、デザートに目を向けます-マトリックスに。 彼らは通常これから始まりますが、私たちはそこで終わります。 まず、g(x)を行列に変換します。これにより、コードワードを取得して情報ワードを乗算できます。 g = 1011の場合:
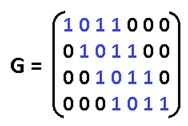
彼らはそれを「生成マトリックス」と呼んでいます。 情報語d = 1010の表記を与え、kをコード化すると、次のようになります。

これはかなりエレガントな声明です。 速度は、多項式の乗算よりもさらに高速です。 そこではシフトを行う必要がありましたが、ここではすべてがすでにシフトしています。 ベクトルdは、どの行を考慮するかを示しています。 マトリックスの最下行はゼロで、行には下から上に番号が付けられます。 はい、はい、すべて下位のランクが右側にあり、それを回避することができないためです。 d = 1010であるため、1行目と3行目を取り、XOR演算を実行して、それらを実行します。 しかし、これだけではありません。驚く準備ができて、まだ検証行列Hがあります。ベクトルに行列を掛けることで、シンドロームを得ることができ、多項式の除算は必要ありません。

上記で得たテスト行列とシンドロームのリストを見てください。 これは、このマトリックスがどこから来たのかという質問に対する答えです。 ここでは、いつものように、3番目のカテゴリのコードワードを台無しにして、同じシンドロームを得ました。 マトリックス自体はシンドロームのリストであるため、エラーの位置をすぐに見つけます。 しかし、いくつかのエラーを修正するコードでは、この方法は機能しません。 上記の方法を使用してエラーをキャッチする必要があります。
エラー訂正の性質をよりよく理解するために、情報ワードは4ビットのみで構成されているため、一般に16コードワードすべてを生成します。

コードワードを注意深く見てください。これらはすべて、少なくとも3ビットは異なります。 たとえば、単語1011000を取得し、その中の任意のビットを変更して1011010を取得します。1011000に類似する単語は見つかりません。ご覧のとおり、計算を実行してコードワードを生成する必要はありません。小さい。 表示される3ビットの差は最小「ハミング距離」と呼ばれ、ブロックコードの特性であり、修正可能なエラー数(d-1)/ 2を判断します。 より一般的な形式では、ハミングコードは(7.4.3)のように記述できます。 ハミング距離は、コードと情報語のサイズの差ではないことに注意してください。 Goleiコード(23,12,7)は3つのエラーを修正します。 コード(48、36、5)は、チャネルの時分割(標準IS-54)によるセルラー通信で使用されました。 リードソロモンコードの場合、同じエントリが適用されますが、これらは既に非バイナリコードです。
使用された文献のリスト:
1. M.ウェルナー。 コーディングの基礎(プログラミングの世界)-2004
2. R.モレロスサラゴサ。 ノイズ耐性コーディングの技術(コミュニケーションの世界)-2006
3. R.ブレイクフート。 エラー制御コードの理論と実践-1986