
こんにちは、Habr。
Tutuのオフィスでの最近の会議で、私はsuperjob.ruの再設計の一環として、 ReactJS上の美しい単一ページアプリケーションとスマートPHPバックエンドアプリケーションを使用して、モノリシックアプリケーションからAPIベースのアーキテクチャに移行する方法について話しました。 この記事では、実際にスマートになるようにバックエンドアプリケーションを最適化した方法について詳しく説明します。
興味のある人-猫をお願いします。
初期設定
Yii1にモノリシックアプリケーションがありました。 いくつかのSymfonyコンポーネントがYiiに追加されました:たとえば、DI、Doctrine、EventDispatcherおよびその他の魔法。 これらはすべて、PHP 7.1では回転していました。
サイトの再設計の一環として、モノリスを2つのアプリケーションに分割することにしました。1つはビジネスロジックとAPIを担当し、もう1つはレンダリングのみを担当します。 Superjobのコードベースのサイズは経験豊富なファイターにとって尊重されており、経験の浅い恐怖を恐れて、すべてをゼロから書き直す/行く/するという冷静な考えは再びゼロから拒否されました。 ビジネスロジックの管理者およびAPIプロバイダーとして、Yiiのモノリスの一部を使用することが決定され、ReactJSの新しいアプリケーションがレンダリングを担当する必要があります。 アプリケーションは、 JSON APIを介して互いに通信する必要があります 。 したがって、次のセットアップを取得したいと考えました。

YiiアプリケーションにJSON APIでの会話を教えるために、よく考えてから、独自の名前であるMapperを使用してソリューションを実装しました 。これはすでにHabréに関する記事でした 。
Mapperを使用すると、yaml-configファイルを使用してJSON APIエンティティでモデル変換を記述し、php-codeにコンパイルできます。 次のようになりました。

これにより、手作業で大幅に少ないコードを記述でき、API内の特定のタイプのエンティティの均一性も保証されました。
さらに、マッパーは次のような多くのことを自動化しました。
- トランスポート層のJSON APIを操作し、
- データベース(ActiveRecord、Doctrine)との相互作用、
- サービスおよびDIとの通信、
- 認可チェック
- モデル検証
- ドキュメント生成
- あなたの手でやるのがとても面倒なことは何でも。
Mapperのおかげで、新しいエンドポイントを可能な限り迅速に実装することができました。これは、開発が並行して行われたフロントエンドアプリケーションによってすぐに採用されました。
最適化
フロントエンドアプリケーションの最初の結果を分析した結果、 1ページあたり平均約10のAPIリクエストが生成されることがわかりました。つまり、バックエンドの最適化を真剣に検討する必要があることを意味します。APIの実行が遅くなるほど、特にフロントが強制的に実行される場合リクエストを順番に。
マッパーの最適化
APIのコアから-最も明白なものから始めることにしました。
まず、マッパーが同じ作業を数回行わないことを確認しました。 多くの場合、APIレスポンスでは同じエンティティが複数回言及されることがあります(たとえば、1つの会社に接続している複数の空席、1人の人物に属する複数の履歴書など)が、同じものを複数回処理する必要はまったくありません。 そのため、現在のリクエストのフレームワーク内のどのモデルを迅速に理解し、すでに働いているか、重複を除外するようにマッパーに教えました。 ここは複雑だと思われますか? 特定のプロパティ/ゲッターで一意の値を持つ特定のタイプのモデルを転送できることがわかっている場合、問題は簡単に解決されます。 しかし、より一般的なケースでは、型も一意の属性も保証されておらず、転送された構造がツリーのようになりうる場合、すべてがより複雑になります。 Mapperの場合、 spl_object_hashとモデル固有の追加チェックの組み合わせを使用して、重複を見つける問題を解決しました。 ただし、私たちの道を繰り返したいと思っている若いパダワン人に警告したいと思います。spl_object_hashのドキュメントで
重複を取り除くために、別のステップを取りました。JSONAPIでは、クライアントがエンティティの階層関係を要求できるためです。たとえば、次のような接続要求: user.resume.user.resume.user.resumeは非常に正当です。 このようなリンクの処理は非常に苦痛なので、マッパーにそのようなケースの処理方法を教えました。 相互に参照しているリンクは、設定で特別な属性でマークされており、リクエストを解析するときに、Mapperはリンクのリストを正規化し、重複を削除しました。

Mapperでの作業中に、APIの最終応答に影響を与えることができる2つのタイプのサービスを思い付きました。これらはアクセスルールと修飾子です。 前者は特定のエンティティへのアクセスを許可または拒否しましたが、後者はエンティティの属性と関係にさまざまな変換を実行できました。 各エンティティを個別にそのようなサービスに転送するのはかなり費用がかかるため、追加の処理が必要なエンティティをコレクションに結合してからサービスに転送するようにマッパーに指示しました。 本質的に、そのようなコレクションを作成するメカニズムはデータベース内のトランザクションに似ていました:モデルツリーを歩いていくと、単純なエンティティを一度にレンダリングし、複雑なものはコレクションに行き、そこでツリーがトラバースするのを待ちました。 次に、コミットの瞬間が来ました-そして、サービスによって処理されたエンティティは、応答ツリーでそれらの場所を取りました。
マッパーは、エンティティ設定のコンパイルを使用してPHPコードにコンパイルするため(現在、APIには220を超えるエンティティがあります)、コンパイルされたコードが可能な限りコンパクトであることを確認しました。
- 共通の関数と特性に入れるコードの繰り返し。
- オブジェクトのインスタンス化を延期し、オブジェクトが既にインスタンス化されている場合、それらを再利用しようとします。
- コンパイルの段階で、リクエストを処理するときのアクションの数を減らすために、ランタイムに関係なくすべてのチェックを実行しようとします。
ブートストラップ最適化
マッパーを最適化した後、アプリケーションのブートストラップの最適化を開始しました。
各リクエストで何が起こるかを判断するために、まったく役に立たない空のエンドポイントを作成し、それにプロファイラーを設定しました( tideways + blackfire bundleを使用します)。
ブートストラップの問題の1つは、アプリケーションの開始時にインスタンス化されたサービスが多すぎ、その結果、多数の接続ファイルであることが判明しました。 これは修正されているはずです。
ブートストラップ自体がインスタンス化したサービスを分析し、それらのいくつかを放棄しました。 現在のコンテキストに応じて、いくつかのサービスのインスタンス化を開始しました。たとえば、リクエストに承認ヘッダーがない場合、ユーザーの承認を担当するサービスをインスタンス化しませんでした。 インスタンス化に時間がかかったサービスについては、Symfony DI- Lazy Servicesの拡張機能の使用を開始しました。 この拡張機能は、サービスインスタンスを軽量のダミーに置き換えます。サービス自体は、最初の呼び出しまでインスタンス化されません。
次に、EventDispatcherのパフォーマンスを最適化することにしました。 事実、EventDispatcherはデフォルトですべてのリスナーをインスタンス化するため、このようなリスナーが多数存在する場合、これにより目に見えるオーバーヘッドが発生します。 この問題を解決するために、CompilerPass for DIを作成しました。これは、アプリケーションの機能に基づいて、リスナーをまったくインスタンス化しないか、リスナーの一部をインスタンス化します。
最後に、接続ファイルの数をさらに減らすために、DI自体の小さな最適化を実行しました。 デフォルトでは、DIは1つのクラスのリフレクションキャッシュを複数のキー(この場合はファイル)に追加します。これにより、読み取り操作と逆シリアル化操作が大幅に増加します。 1つのクラスのキャッシュが1つのキーに格納されるように、リフレクションの収集とキャッシュを担当するクラスを書き直しました。 これは、キャッシュサイズがわずかに大きいにも関わらず、読み取り操作の回数が減るため、時間的に有利になりました。
最終的に、すべての最適化によりCPU消費を40%削減し、メモリを節約できました。
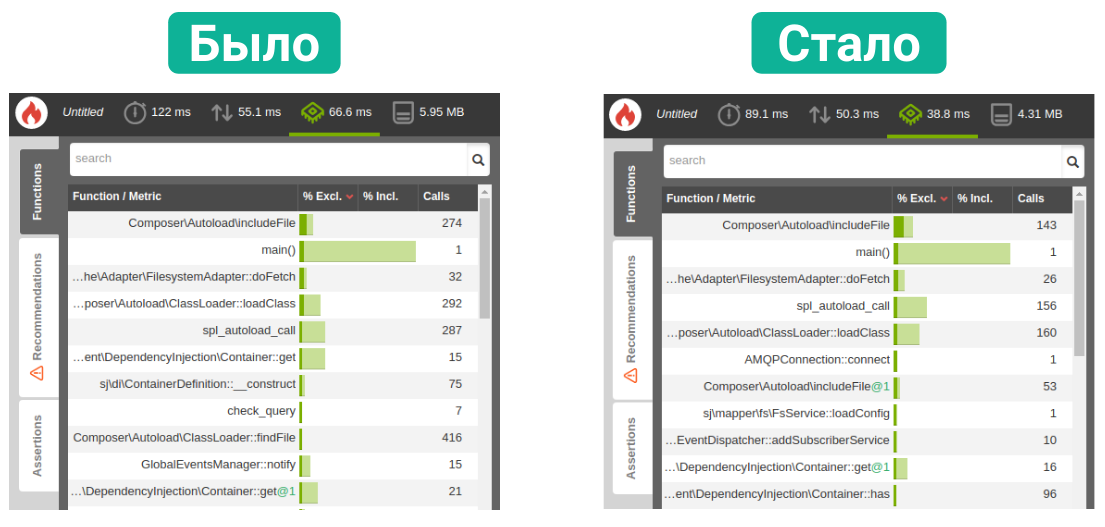
エンドポイントの最適化
最後に、バックエンドの最適化の最後のステップは、特定のエンドポイントの最適化でした。
APIはフロントエンドアプリケーションの唯一の情報ソースであるため、ディレクトリ、辞書、構成、およびその他のめったに変更されないデータを備えた一定数のエンドポイントがありました。 特にそのようなエンドポイントの場合、サーバーキャッシングのサポートを追加しました。Cache-ControlヘッダーとExpiresヘッダーの組み合わせを使用するディクショナリエンドポイントは、nginxに一定時間応答本文をキャッシュするように要求できます。
残りのエンドポイントについては、特別なツールを用意しました。 APIをデバッグパネルに統合しました。各API応答で、エンドポイント内で何が起こっているかを確認できるリンクがパネルに移動しました。

パネルからのデータはピボットテーブルに落ち、そこからエンドポイントの稼働時間に関する情報を取得したり、ブラックファイアのプロファイリングを確認したりできました。
この一連のツールのおかげで、問題のあるエンドポイントは肉眼で文字通り見えましたが、テーブルを分析し、そこで異常を探すスクリプトでまだ武装していました。 後者は通常、2つのタイプに分けられます。エンドポイントが特定のフィルターの組み合わせで遅くなり始めた、または-大量の要求されたデータで。 問題のある各ケースについて、調査を行い、修正を行いました。
まとめ
古いサイトと比較して、バックエンドの負荷が増加しているにもかかわらず、再設計の初期ページの読み込み速度はそれほど変化せず、フロントエンドアプリケーションのアーキテクチャにより、以降のすべての遷移は大幅に速くなりました。遷移ごとにページを完全に再描画する必要はありません。
速度の向上に加えて、背面と前面の両方でよりクリーンなコードを取得しました。背面は表示を考慮せず、前面はビジネスロジックを保存しません。
モノリスを個別のアプリケーションに分離することも、開発の速度とエンドユーザーへの機能の提供に影響を与えました。 バックエンドアプリケーションのルーチンの自動化により、新しい機能のエンドポイントをより速く実装でき、明確な仕様により、フロントチームの同僚がエンドポイントの代わりにmokiを使用して並行して開発を行うことができました。
私たちの経験が誰かにとって有益であり、コメントであなたの質問にいつでも答えられることを願っています。