アナログであれデジタルであれ、あらゆる測定デバイスは、特定のエラーとノイズを伴う結果を示します。 GPSセンサーの誤差は、センサー自体の誤差と、衛星の地形、速度、数、位置などの要因によって決まります。
このアプリケーションでは、ユーザーに旅行のルートを詳細に表示する機会を提供します。 そして、未加工のフィルタリングされていないデータを表示すると、ルートは道路に沿ってではなく、建物または水を通り、ルートの一部のポイントが隣接するポイントから遠く離れているか、ルートの一部が欠落していることがわかります。
マップマッチングサービスを提供するソリューションが市場に存在することは誰にとっても秘密ではないと思います。 座標処理を実行し、その結果、道路に付加された座標を生成します。 ただし、データの詳細を理解するサービスはないため、生データを処理した結果が最良とは限りません。 この点に関して、道路上のセンサーからのデータをフィルタリングして重ね合わせることを可能にするソリューションを開発しました。
入力データ
開発の開始時に、OBDドングルはテレマティクスデータをポイントの形式でサーバーに送信していました。各データには次のパラメーターがありました。
- GPSセンサーから受信した座標。
- 車から受け取った速度。
- 車から受け取ったエンジンターン。
- 特定のポイントの時間。
ポイントは、次のアルゴリズムに従って送信されました-3秒ごとまたは20メートルごとに1回。 転送アルゴリズムは理想的ではありませんが、特定の問題の枠組みの中で、変更しないことに決めました。 より高度なアルゴリズムを使用してポイントを転送すると、結果が改善されるだけであることは明らかです。 ドングルは次のようなデータも収集しました:ヘディング(動きベクトル)および精度の希釈(大まかに言えば、GPS精度)ですが、このデータはサーバーに送信されませんでした。
アルゴリズム
使用したアルゴリズムは、2つの部分に分けることができます。
- データのフィルタリング。
- マップマッチング;
- 部分的な処理。
フィルタリング
自分のデータの詳細を知っている人は誰もいません。 私たちは知識を活用して、独自のサービス側でデータフィルタリングを行うことにしました。 ルートの簡単な例を見てみましょう:

グラフは、車からドングルが受け取った車の速度と、GPSから計算された速度を示します。 ご覧のとおり、グラフには多くの異常値があります-上下両方です。 標準のフィルタリングアルゴリズムがすぐに思い浮かびます:カルマンフィルター、アルファベータフィルター。 最初にそれらを取り上げました。 ただし、このようなフィルターは最良の面を示していません。 これにはいくつかの理由がありました。データの低周波数と絶対的な不均一性(適切なエラーを伴う単一の修正アルゴリズムを選択するのは困難です)、受信データの変換の存在は受け入れられませんでした。 速度のはるかに単純な線形フィルターは、テスト中にはるかに良くなりました。 アルゴリズムの本質は非常に単純です:すべての隣接ポイントについて、GPS速度を計算し、車から受信した速度と比較し、差が許容誤差よりも大きい場合、ポイントの1つを捨てます。
擬似コードは次のとおりです。
`for i in range(1、len(data)):
velocity_gps = calc_dist(データ[i-1] .lat、データ[i-1] .lon、データ[i] .lat、データ[i] .lon)/(データ[i]-データ[i-1])
velocity_vehicle =(データ[i-1] .speed +データ[i] .speed)/ 2
relative_error = abs(velocity_gps-velocity_vehicle)/(velocity_vehicle)
relative_error> 1.5の場合:
data.remove(data [i]) `
フィルタリングの結果、排出量のないデータを取得しますが、ポイントはまだ道路上にありません。 ただし、マップマッチング手順の前に、データを間引く必要があります。 2つのポイントがラインを決定するのに十分な場合、1つのライン上にある10ポイントを転送することは意味がありません。 それでも、マップマッチングサービスはデータノイズを考慮する可能性があるため、フィルタリングにはあまり注意しないでください。 余分なポイントを削除するには、Ramer-Douglas-Peuckerアルゴリズムを使用するか、わずかに修正したバージョンを使用しました。

ポイントの時間順にパックの場合、パックの最初のポイントと最後のポイントを結ぶアークまでのすべてのポイントの距離を計算します。 各ポイントからの距離がEの特定の値より小さい場合、パケットの開始ポイントと終了ポイントのみを返します。 それ以外の場合は、パックを2つに分割し、分割はアークから可能な限り離れた場所で行われ、手順を繰り返します。
マップマッチング
モバイルアプリケーションとポータルのマップはMapboxサービスによって提供されるという事実により、マップマッチングサービスを使用することが決定されました。 しかし、すぐにリクエストで100ポイントの制限に直面しました。 RDPアルゴリズムによるフィルタリングとポイント数の削減を考慮しても、ルートの平均数は250ポイントです。 したがって、バッチ(バッチ)に加えてすべてをラップして処理する必要があります。 場合によっては、単純なバッチ処理で処理エラーが発生します。 バッチ処理アルゴリズムは次のとおりです。
- Nは、オーバーラップ処理のポイント数です。
- ルートを100-N以下のサイズのバッチにカットします。

- 次に、最初のバッチを処理します。
- 処理されたデータの最後のNポイントと2番目のバッチを取得します。
- 最後のバッチに進みます。
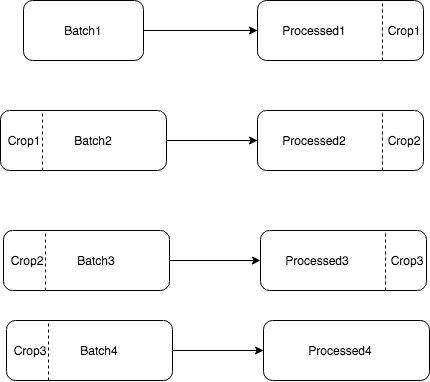
- 最終結果は、Processed1、Processed2、Processed3、Processed4で構成されます。

次の問題は、データの正確性を判断することでした。 Mapbox APIでは、送信されるデータの精度を指定する必要がありますが、このパラメーターはドキュメントでオプションとして指定されています。 渡さない場合、デフォルト値から設定されます。 精度を担当するパラメーターはgps_precisionです。 これについてのドキュメントの内容は次のとおりです。
使用される追跡デバイスの想定精度を示すメートル単位の整数。 ノイズの多いトレースには大きな数値(5〜10)を使用し、クリーンなトレースには小さな数値(1〜3)を使用します。 デフォルト値は4です。
ただし、サービスの開発時にこのデータをドングルから送信しませんでした。 データの頻度はまれであるため、ノイズレベル決定アルゴリズムを使用することはできませんでした。 したがって、一定数のルートを処理し、最適なパラメーターを見つけようとしました。 しかし、1000ルートに最適なパラメーターを選択する方法は? これを手動で行うことは実用的ではありません。 パラメーターの選択に失敗した結果の詳細により、このプロセスを自動化できることが判明しました。 低すぎるパラメータ値を選択すると、ルートの一部が消え、パラメータを過大評価すると、余分なループが表示されます。

そのような場合を識別するには、DTWアルゴリズムが適しています。 1000ルートを処理し、DTWアルゴリズムを使用して結果を比較した結果、3、6、10の精度値(異なる場合)で最良の結果が得られることが明らかになりました。
その結果、精度に関するGPSデータがない場合、3つの異なるgps_precision(3,6,10)で並列処理を開始し、最適なものを選択しました。 ドングルから希釈パラメーターの送信を追加することも計画されていたため、サービスの品質が大幅に向上します。
部分処理
ルートの終点は、多くの場合、地図上で道路が示されていない場所にあります(駐車場、家の間の道など)。 このような状況でのマップマッチングアルゴリズムはうまく機能しません。ユーザーが車を離れた場所をできる限り正確に示したいと思います。 この問題を解決するために、ルート全体ではなく内部ポイントのみを処理するサイクルを作成し始めました。ルートの始点と終点を破棄してから、処理されたデータに元のルートの始点と終点を追加します。 開始と終了は次のように定義されます。車の速度が10 km / hを超える前にルートまたはパーツの5%を取得します。
最終結果
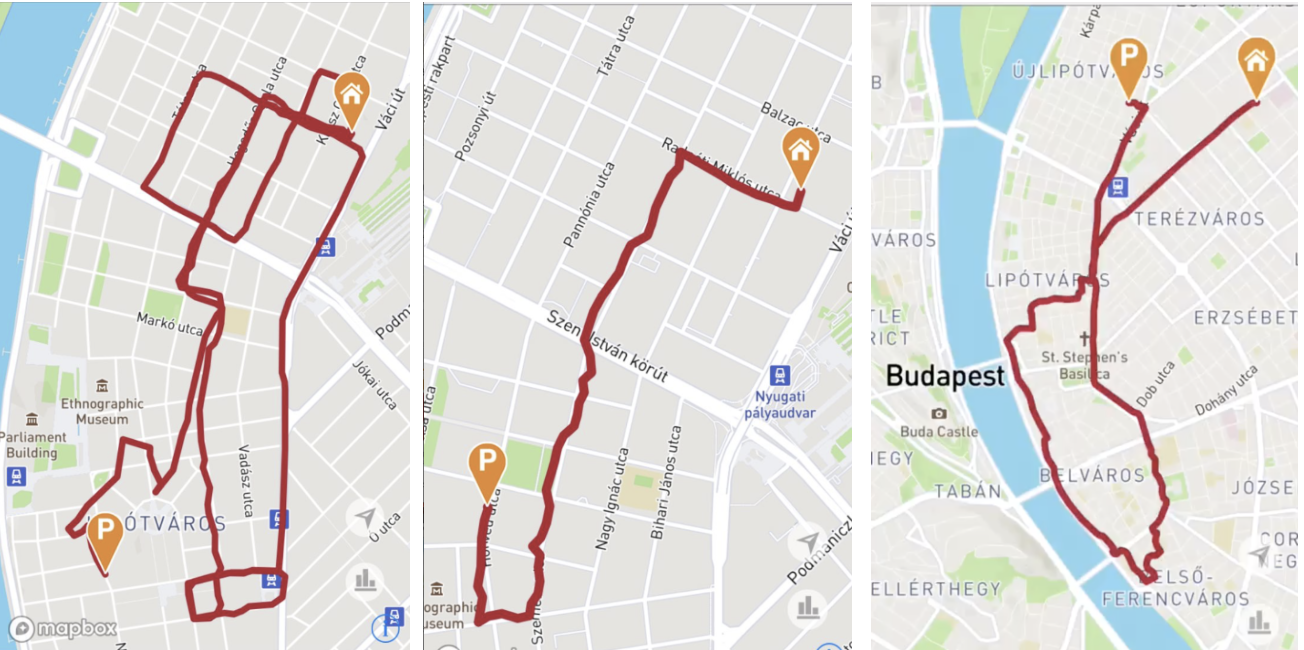
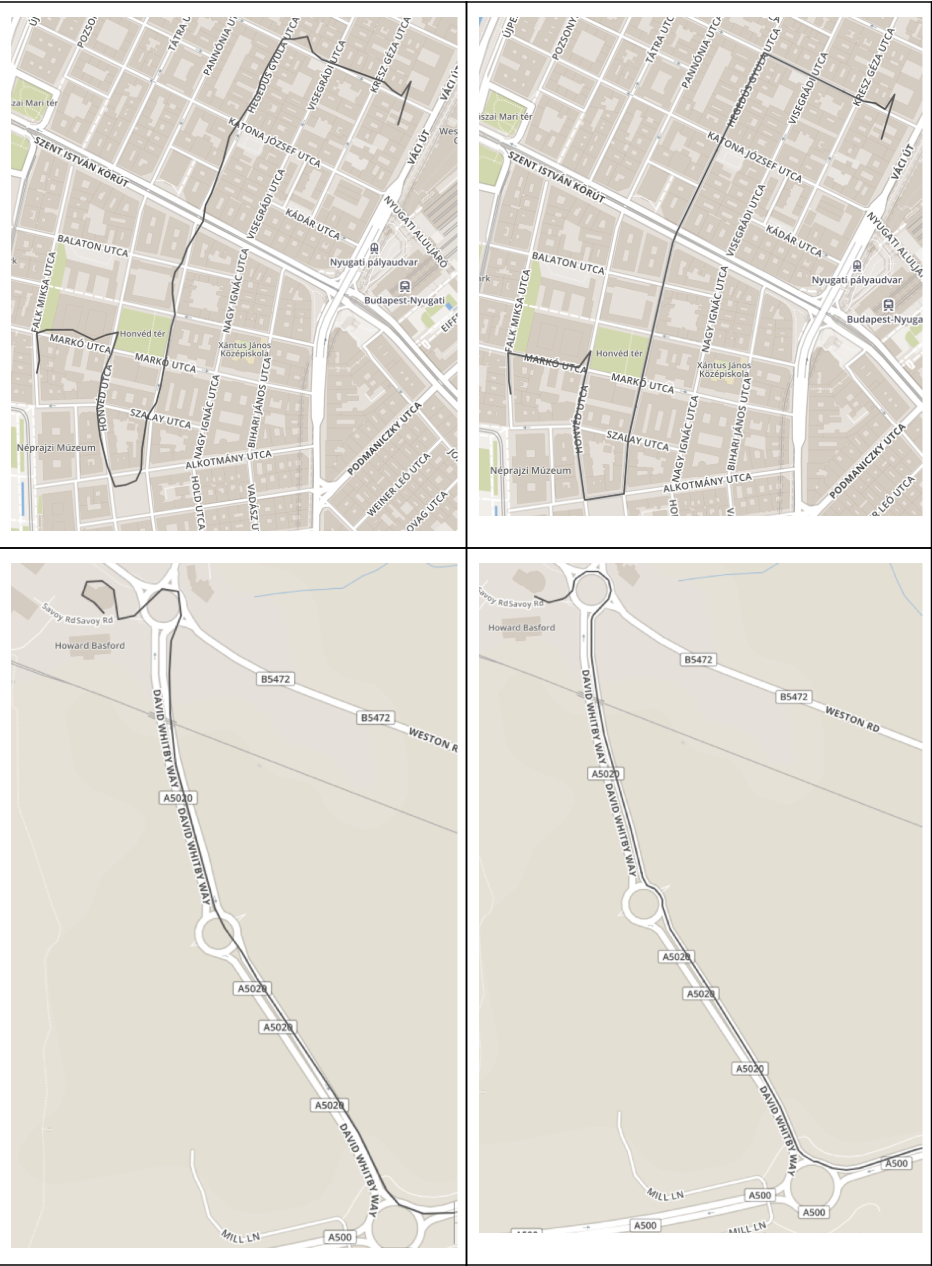
最後に、ルート処理の結果を示したいと思います。 その結果、 ルートは道路に沿ってほぼすべての場所を通過し、大きな音が消え、ルートの欠落した部分が復元されました(リングまたは橋に乗ります)。

投稿者:Kirill Kulchenkov、 kulchenkov32 、シニアソフトウェア開発者、Bright Box。