
すべてのプロジェクト情報は、HP Project and Portfolio Managementからレポートデータベースに複製されます。 Tensorflowニューラルネットワークが学習して予測を行うには、プロジェクトデータをこのAPIにとって理解可能なもの、つまりベクトルに変換する必要があります。
Tensorflow用のベクターの準備
レポートデータベースからデータをインポートすることから始めます。 閉じたプロジェクトのデータはニューラルネットワークのトレーニングに使用され、アクティブなプロジェクトのデータは予測を行うために必要です。 まず、すべてのプロジェクトのデータが一度アップロードされ、その後、タイマーによって変更のみがアップロードされます。 アップロード形式は* .csvです。
一般化された形式で、次の表を取得します。

次のステップでは、これらすべてがMongoDBにロードされます。 十分なデータがないプロジェクトや、他の理由で分析に適さないプロジェクトは処理から除外されます。
次に、プロジェクトのタスクを特定し、それらを典型的なタスクのリストと比較します。 プロジェクト内のタスクは単一の定式化に限定されず、同様のタスクの名前は異なる場合があります。 したがって、認識のために、同義語を含む辞書をコンパイルしました。 異なるプロジェクトの同じタスクは、一意の識別子を受け取ります。 これまでのところ、認識はロシア語でのみ機能します。 タスクの20%未満を認識できたプロジェクト、および何らかの理由で終了タスクがないプロジェクトを除外します。
この段階で、このまたはそのプロジェクトがどのニューラルネットワークに行くかが明らかになります。 2つのニューラルネットワークがあります。1つはプロジェクト終了時のプロジェクト評価を予測し、もう1つはプロジェクト終了日を予測します。 最初のトレーニングでは、評価で終了したプロジェクトが使用され、2番目のトレーニングでは、すべての終了したプロジェクトが使用されます。
「マイルストーンレベル」、「コントロールポイントのタイプ」、「イベント」の列に基づいて、イベントディレクトリを作成します。 次に、イベントをタイムラインに添付して、変更の履歴を1日単位で復元します。 最初の行には、1日のイベントが含まれます。 新しい行にはそれぞれ、前のイベントと新しい日のイベントが含まれています。
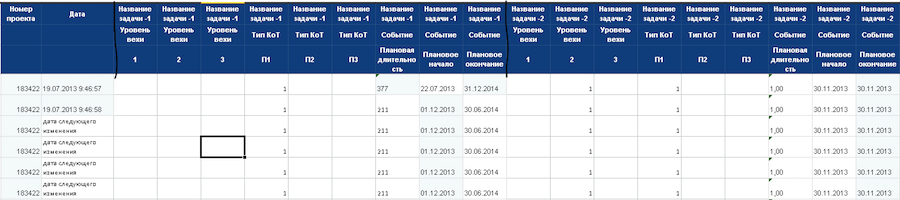
値を0〜1の範囲に変換します。プロジェクトのタイムラインは、特定された同じイベントによって作成されます。このアプローチにより、期間の異なるプロジェクトを比較できます。
エンドポイントとして、プロジェクトの計画終了日は取りません-マージンで計算します。 たとえば、プロジェクトが1年間続く場合、その規模は5年間になります。 これは、プロジェクトの時間枠を超えるイベントを予測するために行われます。

これで、すべてのデータが目的の形式になりました。 ニューラルネットワークの着信ベクトルを準備できます。 表の各列は、プロジェクトタスク、イベント、イベント値の3つの要素の組み合わせであるニューロンです。 現在、約25,000のニューロンがあります。
トレーニング用の合成データ
トレーニングで使用されるデータの量を増やすために、さまざまな歪みを持つ合成データを生成します。
- 隣接するタスクを復元します 。 隣接タスクがない場合、現在のタスクの値は、0%から0.005%のオフセットでコピーされます。
- ぼかし 現在のタスクのニューロンの値から、0%から0.005%が差し引かれます。 この値は半分に分割され、隣接するタスクのニューロンに追加されます。
- ノイズ 。 現在のタスクのニューロンの値は、0.005%の範囲で調整されます。
- ゼロ化 。 現在のタスクのニューロンの値は無効化されています。つまり、そのようなタスクが別のプロジェクトに存在しない可能性があると想定しています。
- 混乱 。 以前の歪みの組み合わせが使用されます。
テンソルフロー作業
ニューラルネットワークを教えるために、プロジェクトデータと最終結果を比較できるコントロールベクトルのセットを使用します。 最初のネットワークはプロジェクトの見積もりを予測することを学習し、2番目のネットワークはプロジェクトの終了日を予測します。
以下は、各ネットワークの制御ベクトルの例です。
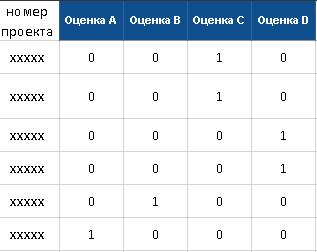
プロジェクト評価を予測するニューラルネットワークの制御ベクトル
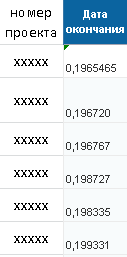
プロジェクトの終了日を予測するニューラルネットワークの制御ベクトル
ロード後、トレーニングは標準のTensorflowツールから始まります。 トレーニングベクトルが入力され、結果が出力で制御ベクトルと比較されます。 比較結果はニューラルネットワークに送り返され、トレーニングが調整されます。 このプロセスは、グラフィカルインターフェイスを介して監視できます。 ネットワークがトレーニングされた後、予測を構築する必要があるプロジェクトのベクトルの入力。 予測には制御ベクトル形式があり、それに基づいて関連するすべてのプロジェクトのレポートが生成されます。
次は?
現在、Jenkinsを使用して、データ準備とニューラルネットワークトレーニングのすべての段階の自動化の作業を完了しています。 通常はアセンブリに使用されますが、ここでは範囲を拡大しました。 彼らは、データのインポート、トレーニングベクトルの準備、ニューラルネットワークのトレーニングのためのタスクを作成しました。 彼らは、予測を構築するためのタスクを構成することを可能にしました。
このシステムには、主に2つの開発方向があります。 新しいデータソースの接続に取り組んでいます-これらはプロジェクト管理に関連するSberbankのさまざまな会計システムです。 また、問題のあるプロジェクトの管理を改善するための推奨事項を発行するアルゴリズムも開発しています。 たとえば、ニューラルネットワークは、プロジェクトを期限内に完了するために、どの専門家をプロジェクトに接続する必要があるかをアドバイスできます。 ニューラルネットワークは、推奨されているとおりに正確に実行する必要がある理由を説明する必要があるため、ここには膨大な数の異なるアイデアが表示されます。 これはExplainable Artificial Intelligence(XAI)と呼ばれます。
私たちに加えて、SberbankとSbertekhには、Machine Learningスタートアップを実行するいくつかのチームがあり、リリースのエラー数、ユーザーフィードバックに基づくインシデント、監視システムからのデータを予測します。 同僚は間違いなく自分のケースを共有します。