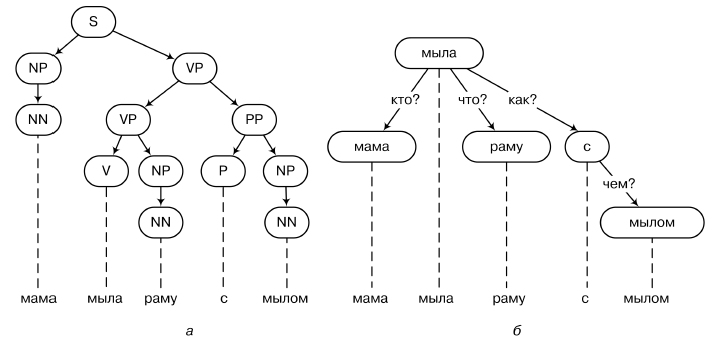
解析ツリーの例を上の図に示します(a-直接コンポーネントの構造に基づく解析、b-依存関係の文法に基づく)。 生成文法は、S→NP VPまたはVP→V NPという形式のルールのセットであり、これらのツリーを使用して生成できます。 構文解析のツリー上で、かなり厳密な構造を構築し、例えば、自然言語の論理を、実際の公理と推論のルールで決定しようとすることができます。
現在、構文解析に対するこのアプローチは、構造ベースの分析と呼ばれています。
直接のコンポーネント、またはフレーズ構造文法(フレーズ構造ベースの解析)。 チョムスキーは、もちろん、他の仮説を提示しました。特に、彼の中心的なアイデアの1つは、人間の言語の「普遍的な文法」のアイデアでした。これは、少なくとも部分的に、子供の誕生前であっても、遺伝的レベルで定められましたが、今では重要です自然言語と数学のこの新しいつながりが、時間の経過とともに言語学を人文科学の最も「正確な」ものに変えてきました。
人工知能の場合、最初はこの言語のブレークスルーは、無制限の楽観主義のdul味のように見えました。自然言語はそのような厳密な数学的構造の形で表現できるため、すぐにそれを完全に形式化し、形式化をコンピューターに転送し、すぐに話しかけることができるように見えました。 しかし、実際には、このプログラムは、軽度の重大な困難を課すために満たされました。自然言語は、以前のように形式的ではなく、最も重要なことは、形式化するのが容易ではない暗黙の仮定に大きく依存していることが判明しました。 さらに、自然言語を理解するためには、文字や単語のシーケンスとして十分に明確に定義された形式オブジェクトを「解析」するだけでなく、「常識」、周囲の世界の考え方、これにより、コンピュータはまだ非常に悪いです。
このような非常に複雑なタスクの単純で理解可能な例は、照応の解決(照応の解決)、つまり、本文またはこの代名詞が何を指しているのかを理解することです。 2つの文を比較してください:「ママはフレームを洗って、今は輝いている」と「ママはフレームを洗って、今は疲れている」。 構造的には、まったく同じです。 しかし、代名詞「彼女」がこれらのフレーズのそれぞれで何を指しているかを正確に判断するために、コンピューターがどれだけ知って理解する必要があるかを想像してください。
そして、これは特別に考案されたひねくれた例ではなく、あなたと私たちの言語の日常の現実です。 私たちは人々が「自然な方法で」理解しているものを常に参照しています...しかし、コンピューターモデルにとってこれは完全に非論理的です! 現代の自然言語処理の主な障害は「常識的推論」です。 ちなみに、自然言語処理の専門家は、この方向に具体的に取り組むことを長い間試みてきました。 10年以上にわたり、「常識」に関する年次セミナー、常識推論の論理的形式化に関する国際シンポジウムが開催され、最近、テリーヴィノグラードを称えるWinograd Schema Challengeと呼ばれる常識タスクコンテストも開始されました。
仕事は次のとおりです。「カップが大きすぎたためスーツケースに収まりませんでした。 スーツケースやカップが大きすぎたのは何ですか?」
そのため、人々はワープロに取り組んでおり、大幅な進歩を遂げていますが、コンピューターはまだ話すことを学んでいません。 はい、書かれたテキストを理解することは依然として災害です。ただし、彼らは音声認識と合成の深層学習の助けも借りて働きます。 しかし、ニューラルネットワークを自然言語に適用し始める前に、読者がすでに提起しているはずの別の質問を議論する必要があります。実際、「テキストを理解する」とはどういう意味ですか。 機械学習のレッスンでは、まずタスク、最適化する目標関数を定義する必要があることを学びました。 「理解」を最適化するには?
もちろん、知的テキスト処理は1つのタスクではなく、多くのタスクであり、それらはすべて何らかの形で人間の影響を受けやすく、テキストを理解する「聖杯」に関連付けられています。 簡単に数量化できる主なワードプロセッシングの問題をリストし、簡単にコメントしましょう。 これらのいくつかについては、この章の後半で説明します。 単純なものから複雑なものへと移行し、条件付きで3つのクラスに分割します。
1.最初のクラスのタスクは、条件付きで構文と呼ばれます。 ここで、タスクは原則として非常に明確に定義されており、分類の問題または個別のオブジェクトを生成する問題を表しており、その多くは現在非常によく解決されています。
(i)品詞のタグ付け:品詞(名詞、動詞、形容詞など)に応じて、また場合によっては形態学的特性(性別、格...)に応じて、特定のテキスト内の単語にマークを付けます。
(ii)形態学的セグメンテーション:与えられたテキスト内の単語を形態素、つまり、接頭辞、接尾辞、語尾などの構文単位に分割します。 一部の言語(英語など)では、これはあまり意味がありませんが、ロシア語には多くの形態があります。
(iii)個々の単語の形態の問題の別のバージョン-ステミング、単語の基本を強調する必要がある場合、または単語を基本形(たとえば、男性の性別の単数形)に還元する必要がある補題(lemmatization);
(iv)文の境界の明確化:指定されたテキストを文に分割します。 ドットやその他の句読点で区切られており、大文字で始まっているように見えるかもしれませんが、たとえば、「1995年にT. VinogradがL. Pageの監督になった」ということを思い出してください。 また、中国語などの言語では、スペースのない象形文字のストリームをさまざまな方法で単語に分割できるため、単語分割のタスクも非常に簡単になります。
(v)名前付きエンティティの認識:人、地理、その他のオブジェクトの適切な名前をテキストで検索し、エンティティタイプ(名前、トポニムなど)でそれらをマークします。
(vi)単語の意味の曖昧性除去:同義語のどれを選択し、同じ単語の異なる意味のどれをテキストのこのパッセージで使用するかを選択します。
(vii)構文解析:指定された文(および、場合によってはそのコンテキスト)に従って、チョムスキーに従って構文ツリーを直接構築します。
(viii)相互参照の解決:テキストのどのオブジェクトまたは他の部分が特定の単語やフレーズを参照しているかを決定します。 この問題の特別なケースは、前述の照応のまさに解決です。
2. 2番目のクラスは、一般にテキストの理解を必要とするタスクですが、フォームの観点からは、正解(分類問題など)を備えた明確なタスクであり、疑いのない品質指標を簡単に見つけることができます。 そのようなタスクには、特に以下が含まれます。
(i)言語モデル:テキストの一節について、次の単語または記号を予測します。 このタスクは、たとえば音声認識にとって非常に重要です(以下を参照)。
(ii)GoogleとYandexが解決する中心的なタスクである情報検索:与えられたクエリと膨大な数のドキュメントにより、このクエリに最も関連性の高いドキュメントを見つけます。
(iii)感情分析:テキストからその調性、つまりテキストがポジティブかネガティブかを判断する; 調性分析は、ユーザーのレビューを分析するためのオンライン取引、プレスの記事、会社のレポートなどのテキストを分析するための金融および取引などで使用されます。
(iv)関係または事実の抽出(関係抽出、事実抽出):テキストから、そこに言及されているエンティティに関する明確に定義された関係または事実を抽出する。 たとえば、誰が誰と関係を持っているか、設立されたテキストで言及されている会社は何年ですかなど。
(v)質問に答える質問:質問に答えます。 設定に応じて、純粋な分類(テストのように回答オプションから選択)、または非常に多数のクラスを持つ分類(「誰?」や「何年?」などの実際の質問への回答)、または結果になります。テキスト(自然な対話の一部として質問に答える必要がある場合)。
3.最後に、3番目のクラスでは、すでに書かれたテキストを理解するだけでなく、新しいテキストを生成する必要があるタスクを割り当てます。 ここで、品質指標は必ずしも明確ではないため、以下でこの問題について説明します。 そのようなタスクには、たとえば次のものがあります。
(i)テキストの実際の生成(テキスト生成);
(ii)自動要約:要約、いわば要約を生成するテキストから。 これは、一般的な意味を最もよく反映する既成の文をテキストから選択するようモデルに要求する場合は分類問題と見なすことができ、簡単な要約を最初から書く必要がある場合は生成問題と見なすことができます。
(iii)機械翻訳:1つの言語のテキストから、対応する別の言語のテキストを生成します。
(iv)対話および会話モデル:人との会話を維持します。 最初のチャットボットは1970年代に登場し始め、今日では大きな産業となっています。 本格的な対話を実施してチューリングテストに合格することはまだ不可能ですが、対話モデルはすでに懸命に機能しています(たとえば、さまざまな取引サイトの「オンラインコンサルタント」の最初の行はほとんどの場合チャットボットです)。
最後のクラスのモデルの重要な問題は、品質評価です。 良いと思う一連の並列翻訳を作成できますが、モデルによって作成された新しい翻訳をどのように評価しますか? または、さらに興味深いことに、会話における対話モデルの応答を評価する方法は? この質問に対する考えられる答えの1つは、機械翻訳用に設計されたが、他のタスクにも使用されるメトリックのクラスであるBLEU(2か国語による評価の調査)[48]です。 BLEUは、モデルの回答と「正解」の一致の精度を修正したもので、1つの正しい単語からの回答に理想的な評価を与えないように再重み付けされます。 テストケース全体で、BLEUは次のように考慮されます。
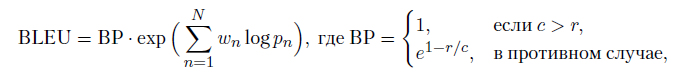
ここで、rは正解の全長、cはモデル応答の長さ、pnは修正された精度、wnは1になる正の重みです。 他の同様のメトリクスがあります:METEOR [298]-ユニグラム上の精度と完全性の調和平均、TER(翻訳編集率)[513]は、参照出力を得るためにモデル出力に対して行う必要のある修正の相対数、ROUGE [326]カウントを計算します標準および結果のテキストの単語のnグラムのセットの共通部分のシェア、およびLEPOR [204]は、いくつかの異なるメトリックを異なる重みで完全に結合し、トレーニングも可能です(これらの記事の多くの著者はフランス語であり、略語はフランス語を話します)。
ただし、BLEUやMETEORのようなメトリックがまだ一般的に使用されていますが、実際にはこれが最良の選択であるという事実はまったくありません。 まず、BLEUには離散的な値のセットがあるため、勾配降下によって直接最適化することはできません。 しかし、さらに興味深いのは、[232]で、対話でのモデル応答の評価のコンテキストでさまざまな同様の品質メトリックを使用した非常に驚くべき結果が示されていることです。 そこでは、回答の質の人間の評価と異なるメトリックによる評価の相関関係(通常とランクの両方)が計算されます...そして、これらの相関関係はほとんど常にゼロに近く、時には完全に負であることがわかります! BLEUは、1つのデータセットで約0.35、もう1つのデータセットで0.12の人間の推定値との相関を達成することができました(このような相関で科学的結果を発表してみてください!)。 さらに、そのような貧弱な結果は、正しい答えがまったく存在しないことを意味しません:異なる人々の評価は常に0.95以上のレベルで相互に相関関係があったため、品質評価の「ゴールドスタンダード」は確かに存在しますが、それを形式化する方法は、まだ全く理解していません。 この批判はすでに自動的に訓練された品質測定基準の新しい設計につながっており[537]、新しい方向がこの方向に現れることを期待しています。 それでも、BLEUのようなメトリックに簡単に適用できる代替手段はありませんが、通常は使用されます。
さらに、テキストに関連する幅広いクラスのタスクがありますが、入力として文字のシーケンスではなく、異なる性質の入力を受け入れます。 たとえば、言語を理解しないと、音声を完全に認識する方法を学ぶことはほとんど不可能です。音声認識は音で音素を分類するタスクにすぎませんが、実際には、人は多くの音を聞き逃し、言語の理解に基づいて聞こえるものの大部分を完了します。 1990年代に、音声認識システムは個々の音素を認識する人間のレベルに達しました。人々をテープレコーダーに装着し、コンテキストなしで音を聞かせ、「a」と「o」を区別するように頼むと、結果は目立たなくなります。 したがって、たとえば、あなたに指示されていることを書き留めるには、それが発生する言語を知る必要があります。 別のクラスは、手書きまたは入力されたテキストの認識です。
将来これらのタスクの多くに戻ります。 ただし、この章の主な内容は、自然言語処理の特定の問題を解決することではなく、そのような問題に対するほとんどすべての最新のニューラルネットワークアプローチの基礎となるデザイン、つまり単語の分散表現について説明することです。
セルゲイ・ニコレンコ、アーサー・カドゥリン、エカテリーナ・アルハンゲリスカヤの著書「深層学習」からの抜粋