過去数年間のバークレー、Google Brain、DeepMind、およびOpenAIの記事が主に引用されています。これらの記事は私の観点から最も目立つからです。 私はほぼ確実に古い文献や他の組織から何かを見逃したので、私は謝罪します-結局のところ、私はただ一人です。

はじめに
Facebookで次のことを述べました。
誰かが強化学習(RL)で問題を解決できるかどうか尋ねると、すぐには答えられません。 これは少なくとも70%のケースで当てはまると思います。強化されたディープラーニングには、大量の誇大宣伝が伴います。 そして、正当な理由があります! 強化学習(RL)は信じられないほど一般的なパラダイムです。 原則として、信頼性が高く高性能なRLシステムはすべてにおいて完璧でなければなりません。 このパラダイムとディープラーニングの経験的な力の融合は自明です。 Deep RLは最も強力なAIのように見えますが、これは一種の夢であり、数十億ドルの資金調達を促進します。
残念ながら、実際にはこのことはまだ機能しません。
しかし、私は彼女が撃つと信じています。 信じられなかったら、このトピックでは料理をしませんでした。 しかし、先には多くの問題があり、その多くは根本的に複雑です。 訓練されたエージェントの美しいデモは、作成中にこぼれた血、汗、涙をすべて隠します。
数回、最近の結果に人々が誘惑されるのを見ました。 彼らは最初に深いRLを試し、常に困難を過小評価していました。 間違いなく、この「モデルタスク」は見かけほど単純ではありません。 そして、疑いもなく、この分野は彼らが研究に現実的な期待を設定することを学ぶ前に、彼らを数回破りました。
個人的な間違いはありません。 これはシステムの問題です。 ポジティブな結果についてストーリーを描くのは簡単です。 これをネガティブにしてみてください。 問題は、研究者がほとんどの場合正確に否定的な結果を得るということです。 ある意味では、そのような結果は肯定的な結果よりもさらに重要です。
この記事では、ディープRLが機能しない理由を説明します。 私の意見では、それがまだ機能する場合の例と、将来より信頼性の高い作業を達成する方法を示します。 これは、深いRLで作業している人を止めるためではありませんが、誰もが問題を理解していれば進歩しやすいからです。 あなたが本当に問題について話すならば、合意に達するのは簡単です、そして、お互いに別々に同じレーキに何度も何度もつまずかない。
ディープRLのトピックに関する研究をもっと楽しみたいです。 新しい人がここに来るように。 そして、彼らは自分が何に興味を持っているのかを知るように。
先に進む前に、いくつかの発言をさせてください。
- いくつかの科学論文がここに引用されています。 私は通常、説得力のあるネガティブな例を挙げ、ポジティブなことについては黙っています。 これは、私が科学研究が好きではないという意味ではありません 。 彼らはすべて良いです-時間があれば読む価値があります。
- 私の日常業務では、RLは常に深いRLを意味するため、「強化学習」と「深層強化学習」という用語を同義語として使用します。 一般的に強化を伴う学習よりも強化を伴う深層学習の経験的な行動を批判します。 引用された記事は通常、ディープニューラルネットワークを持つエージェントの仕事について説明しています。 経験的批判は線形RL(線形RL)または表形式RL(表形式RL)にも当てはまるかもしれませんが、この批判をより小さなタスクに拡張できるかどうかはわかりません。 深いRLを取り巻く誇大広告は、RLが、良好な近似関数が必要な大規模で複雑な多次元環境のソリューションとして提示されているという事実によるものです。 特に、この誇大広告でそれを整理する必要があります。
- この記事は、悲観論から楽観論に移行するように構成されています。 私はそれが少し長いことを知っています、しかし、あなたが答える前にあなたがそれを全部読むのに時間をかけるならば、私は非常に感謝します。
これ以上苦労することなく、ディープRLがクラッシュするいくつかのケースを以下に示します。
強化されたディープラーニングは非常に効果が低い場合があります
強化を伴うディープラーニングの最も有名なベンチマークは、Atariゲームです。 よく知られている記事Deep Q-Networks(DQN)に示されているように、Qラーニングを適切なサイズのニューラルネットワークといくつかの最適化のトリックと組み合わせると、いくつかのAtariゲームで人間のパフォーマンスを達成したり、それらを上回ることができます。
ゲームAtariゲームは毎秒60フレームで実行されます。 結果を人として表示するために最適なDQNを処理するために必要なフレーム数をすぐに把握できますか?
答えはゲームによって異なるため、最近のDeepmindの記事-Rainbow DQN(Hessel et al、2017)をご覧ください。 元のDQNアーキテクチャへの連続した強化のいくつかが結果をどのように改善するかを示し、すべての改善を組み合わせることが最も効果的です。 ニューラルネットワークは、57のアタリゲームのうち40以上で人間の結果を超えています。 結果はこの便利なチャートに示されています。
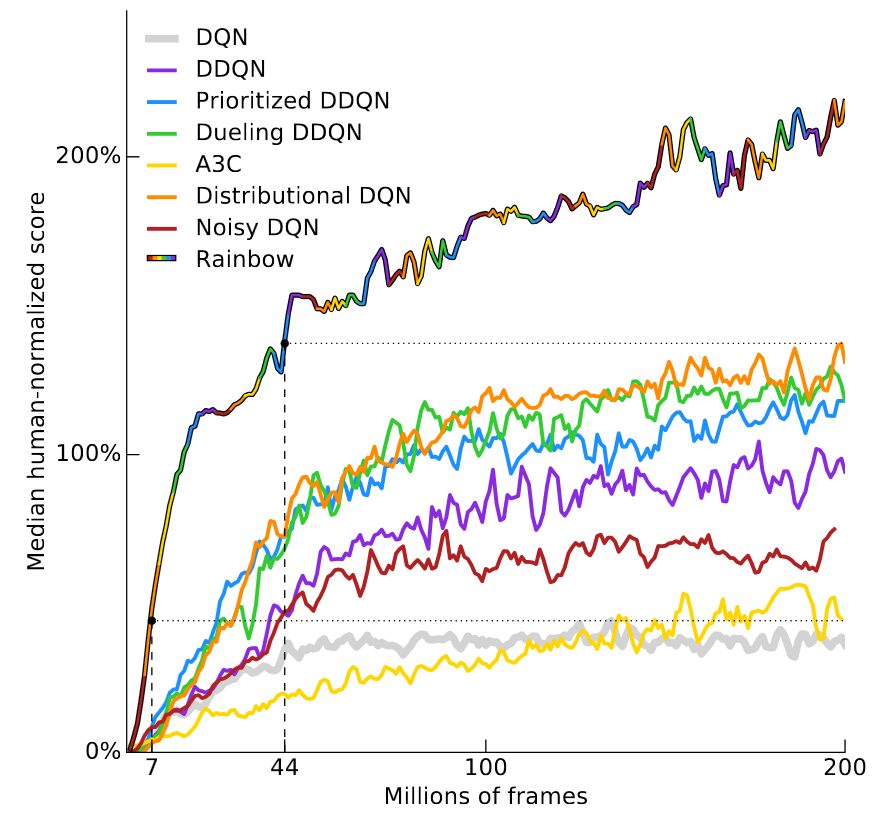
縦軸は、「人間に対して正規化された平均結果の中央値」を示しています。 アタリゲームごとに57個のDQNニューラルネットワークをトレーニングし、人間の結果を100%とするときに各エージェントの結果を正規化し、57ゲームの平均中央値を計算することによって計算されます。 RainbowDQNは、1800 万フレームを処理した後、100%のマイルストーンを超えています。 これは、約83時間のプレイに加えて、どれだけ時間がかかってもトレーニング時間に相当します。 これは、ほとんどの人が数分でつかむ単純なAtariゲームの多くの時間です。
前のレコードは分布DQNシステムに属していたため(Bellemare et al、2017) 、100%の結果を達成するには7000万フレーム、つまり約4倍の時間が必要だったため、実際には1800万フレームが非常に良い結果であることに留意してください。 Nature DQN(Mnih et al、2015)に関しては、2億フレーム後でも、100%の中央値に達することはありません。
「計画エラー」の認知バイアスは、タスクの完了に通常予想よりも長い時間がかかることを示しています。 強化学習には独自の計画ミスがあります。通常、トレーニングには思ったよりも多くのサンプルが必要です。
問題はAtariゲームに限定されません。 2番目に人気のあるテストは、MuJoCo物理エンジンのタスクセットであるMuJoCoベンチマークです。 これらのタスクでは、通常、ロボットのシミュレーションにおける各ヒンジの入力と速度が入力で与えられます。 視覚の問題を解決する必要はありませんが、RLシステムは、 前に タスクに応じた手順。 これは、このような単純な環境での制御には信じられないほどです。
以下に示すParkour DeepMindの記事(Heess et al、2017)は 、100人以上の従業員64人を使用してトレーニングされています。 この記事ではワーカーが何であるかを指定していませんが、これは単一のプロセッサーを意味すると想定しています。
これは最高の結果です。 彼が最初に出てきたとき、私は深いRLが実行中にそのような歩行を一般的に学ぶことができたことに驚きました。
しかし、プロセッサー時間は6400時間かかり、少し残念です。 期待していた時間が短いわけではありません...単純なスキルでは、深いRLが実際に役立つトレーニングのレベルよりも1桁劣っていることは残念です。
明らかな反論があります。トレーニングの効果を単に無視した場合はどうでしょうか? エクスペリエンスを簡単に生成できる特定の環境があります。 たとえば、ゲーム。 しかし、これが不可能な環境では、RLは大きな課題に直面します。 残念ながら、ほとんどの環境はこのカテゴリに分類されます。
最終的なパフォーマンスのみに関心がある場合は、他の方法で多くの問題を解決した方がよいでしょう。
問題の解決策を探すとき、通常、さまざまな目標を達成するために妥協点を見つける必要があります。 この特定の問題に対する本当に良い解決策に集中することも、研究全体への最大限の貢献に集中することもできます。 最良の問題は、優れた解決策を得るために研究への貢献が必要な場合です。 しかし実際には、これらの基準を満たす問題を見つけることは困難です。
純粋に最大限の効率を実証するという点で、深いRLは他の方法よりも常に優れているため、それほど印象的な結果を示しません。 インタラクティブなパス最適化によって制御されるMuJoCoロボットのビデオを次に示します。 正しいアクションは、オフライン学習なしで、ほぼリアルタイムでインタラクティブに計算されます。 はい、すべてが2012年の機器で動作します( Tassa et al、IROS 2012 )。
この作業は、パルクールに関するDeepMindの記事と比較できると思います。 それらはどう違うのですか?
違いは、ここでは著者が予測モデルで制御を適用し、地球の実際のモデル(物理エンジン)で作業することです。 RLにはそのようなモデルはないため、作業が大幅に複雑になります。 一方、モデルベースの行動計画が結果を大幅に改善するのであれば、なぜRLトレーニングをだましてやる必要があるのでしょうか?
同様に、モンテカルロ(MCTS)ターンキーツリー検索ソリューションを使用すると、AtariのDQNニューラルネットワークを簡単に上回ることができます。 以下は、 Guo et al、NIPS 2014の主要な指標です。 著者は、訓練されたDQNの結果をUCTエージェントの結果と比較します(これは最新のMCTSの標準バージョンです)。


繰り返しますが、これは不公平な比較です。DQNは検索を行わず、MCTSは地球物理学の実際のモデル(Atariエミュレーター)を使用して正確に検索を行うためです。 しかし、状況によっては、気にしない場合があります。これは、正直なまたは不正な比較です。 動作するために必要な場合もあります(完全なUCT評価が必要な場合は、元の科学記事Arcade Learning Environment(Bellemare et al、JAIR 2013 )の付録を参照してください。
強化学習は、世界の未知のモデルを含む環境を含むすべてに理論的に適しています。 それにもかかわらず、そのような汎用性は高価です。学習に役立つ可能性のある特定の情報を使用することは困難です。 このため、最初からハードコーディングできることを学習するには、多くのサンプルを使用する必要があります。
経験から、まれなケースを除き、特定のタスクに合わせて調整されたアルゴリズムは強化学習よりも高速で優れた動作をすることが示されています。 深在性RLのために深在性RLを開発している場合は問題ではありませんが、個人的には、RL cの有効性を...他の何かと比較するのは気分を害します。 AlphaGoがとても好きだった理由の1つは、それがディープRLにとって明確な勝利だったからです。
これらすべての理由から、私のタスクがとてもクールで複雑で面白い理由を人々に説明することはより困難です。なぜなら、彼らはしばしばなぜ難しいのかを評価するための背景や経験がないからです。 ディープRLの機能について人々が考えることと、実際の機能との間には明確な違いがあります。 今、私はロボット工学の分野で働いています。 ロボット工学について言及する場合、ほとんどの人の頭に浮かぶ会社を考えてみましょう:Boston Dynamics。
このことは強化トレーニングを使用しません。 ここでRLが使用されていると思った人に何度か会いましたが、いません。 開発者グループから発行された科学論文を探すと、 線形2次レギュレータ、時変2次計画法ソルバー、凸最適化に関する記事が見つかります。 言い換えれば、彼らは主に古典的なロボット工学の方法を適用します。 これらの古典的な手法は、適切に適用すればうまく機能することがわかりました。
強化トレーニングには通常、報酬機能が必要です
強化された学習は、報酬関数の存在を意味します。 通常、最初に存在するか、オフラインモードで手動で構成され、トレーニング中は変更されません。 シミュレーショントレーニングやリバースRL(報酬関数が事後的に復元される場合)などの例外があるため、「通常」と言いますが、ほとんどの場合、RLは報酬としてオラクルとして使用します。
RLが適切に機能するためには、報酬機能が必要なものを正確にカバーする必要があることに注意することが重要です。 そして私は正確に意味します 。 RLは煩わしくオーバーフィットしやすいため、予期しない結果につながります。 それが、Atariが非常に優れたベンチマークである理由です。 多くのサンプルを入手するのは簡単なだけでなく、すべてのゲームには明確な目標(ポイント数)があるため、報酬関数を見つけることを心配する必要はありません。 そして、あなたは他の誰もが同じ機能を持っていることを知っています。
MuJoCoタスクの人気は、同じ理由によるものです。 シミュレーションで機能するため、オブジェクトの状態に関する完全な情報が得られるため、報酬関数の作成が大幅に簡素化されます。
Reacherタスクでは、中心点に接続された2セグメントのアームを制御します。目標は、アームの端を特定のターゲットに移動することです。 学習の成功例については、以下を参照してください。
すべての座標が既知であるため、報酬は手の端からターゲットまでの距離に加えて、移動するための短い時間として定義できます。 原則として、現実の世界では、座標を正確に測定するのに十分なセンサーがあれば、同じ実験を行うことができます。 しかし、システムが何をする必要があるかに応じて、合理的な報酬を決定することは困難です。
報酬関数自体がなければ、大きな問題にはなりません...
報酬機能の開発の複雑さ
報酬関数を作成することはそれほど難しくありません。 適切な振る舞いを奨励する機能を作成しようとすると困難が発生し、同時にシステムは学習を維持します。
HalfCheetahには、垂直面に囲まれた2本足のロボットがあります。つまり、前方または後方にしか移動できません。

目標はジョギングを学ぶことです。 報酬はHalfCheetahの速度です( ビデオ )。
これは滑らかな、または形を整えた(形をした)報酬です。つまり、最終目標に近づくにつれて増加します。 目標の最終状態に到達したときにのみ付与される、 まばらな報酬とは対照的に、他の状態では存在しません。 トレーニングが問題の完全な解決策を提供しなかった場合でも、肯定的なフィードバックを提供するため、報酬のスムーズな成長は、多くの場合、習得がはるかに簡単です。
残念ながら、スムーズな成長による報酬には偏りがあります(バイアス)。 すでに述べたように、このため、予期しない望ましくない動作が現れます。 良い例は、 OpenAIブログ記事のボートレースです。 目標はゴールに到達することです。 与えられた時間にレースが終了すると+1の報酬を、それ以外の場合は0の報酬を想像できます。
報酬機能は、チェックポイントを通過するためのポイントと、フィニッシュラインにすばやく到達できるボーナスを収集するためのポイントを提供します。 判明したように、ボーナスを集めることはレースの完了よりも多くのポイントを与えます。
正直なところ、この出版物は最初は少し面倒でした。 彼女が間違っているからではありません! しかし、彼女は明らかなことを実証しているように思えたからです。 もちろん、報酬が誤って定義されている場合、強化学習は奇妙な結果をもたらします! この出版物はこの特定のケースを不当に重要視しているように思えました。
しかし、その後、私はこの記事の執筆を開始し、誤って定義された報酬の最も説得力のある例が、 まさにこのボートレースのビデオであることに気付きました。 それ以来、このトピックに関するいくつかのプレゼンテーションで使用され、問題に注目を集めました。 それでいいのですが、私はしぶしぶ良いブログ投稿だったことを認めます。
RLアルゴリズムは、周囲の世界について多少なりとも推測する必要がある場合、ブラックホールに陥ります。 モデルレスRLの最も汎用性の高いカテゴリは、ブラックボックス最適化のようなものです。 そのようなシステムは、それらがMDP(Markov意思決定プロセス)にあると仮定することだけが許可されます-それ以上はありません。 エージェントは、これはあなたが+1を得るものであると単純に言われますが、あなたはこのためにそれを得るのではなく、あなた自身で他のすべてを見つけるべきです。 ブラックボックスの最適化と同様に、問題は、報酬が間違った方法で受け取られた場合でも、+ 1を与える動作は良いと見なされることです。
古典的な例はRL分野のものではありません-誰かが超小型回路の設計に遺伝的アルゴリズムを適用し、最終設計に1つの接続されていない論理ゲートが必要な回路を受け取ったときです。
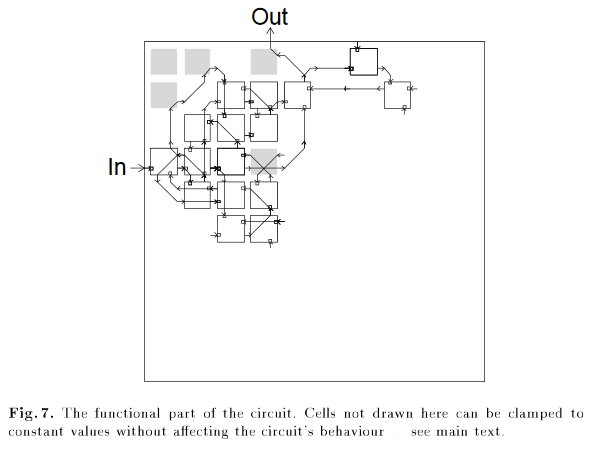
灰色の要素は、左上隅の要素を含む回路の正しい動作に必要ですが、何にも接続されていません。 記事「物理学に絡み合ったシリコンに固有の進化した回路」から
または、より最近の例として、 2017 Salesforceブログ投稿があります。 彼らの目標は、テキストの要約を作成することでした。 基本モデルは教師に教えられた後、ROUGEと呼ばれる自動化されたメトリックによって評価されました。 ROUGEは差別化されていない報酬ですが、RLはそのようなものに対応できます。 そこで、彼らはRLを適用してROUGEを直接最適化しようとしました。 これで高いROUGE(歓声!)が得られますが、歌詞はあまり良くありません。 以下に例を示します。
バトンは、ERSが彼をスタートさせなかった後、マクラーレンの100回目のレースを彼から奪いました。 英国人にとっては悪い週末を終えた。 資格に先んじるボタン。 バーレーンのニコ・ロズベルグに先行してフィニッシュ。 ルイス・ハミルトン。 11レースで..レース。 2,000ラップをリードするために...で... I.- Paulus et al、2017
そして、RLモデルは最大のROUGE結果を示しましたが...
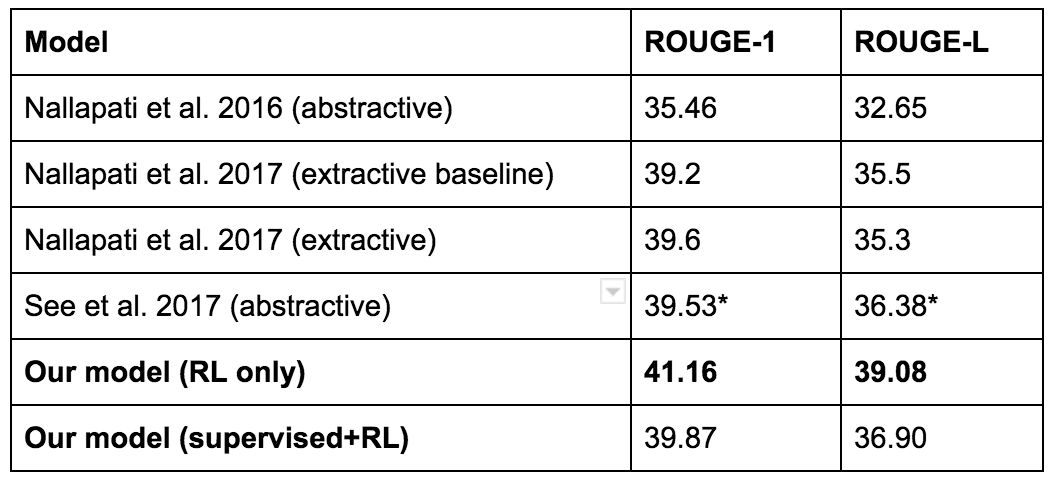
...彼らは最終的に、履歴書を書くために別のモデルを使用することにしました。
別の楽しい例。 これは、「折り畳み式レゴコンストラクターに関する記事」としても知られているPopov et al、2017の記事によるものです。 著者は、DDPGの分散バージョンを使用してキャプチャルールを教えています。 目標は、赤い立方体をつかみ、青の上に置くことです。
彼らは彼女の作品を作ったが、失敗の興味深いケースに直面した。 最初のリフティング動作は、赤いブロックのリフティング高さに基づいて報われます。 これは、立方体の底面のZ座標によって決まります。 失敗オプションの1つでは、モデルは底面を上にして赤い立方体をオンにし、上げないようにすることを学びました。
明らかに、この動作は意図されたものではありません。 しかし、RLは気にしません。 強化訓練の観点から、彼女は立方体を回すことに対する報酬を受け取ったので、彼女は立方体を回し続けます。
この問題を解決する1つの方法は、キューブを接続した後にのみ報酬を与えることで、報酬をまばらにすることです。 まれな報酬が学習に役立つため、これが機能する場合があります。 しかし、多くの場合、これはそうではありません。積極的な強化が不足しているため、事態は複雑になりすぎています。
問題の別の解決策は、報酬の慎重な形成、新しい報酬条件の追加、およびトレーニング中にRLアルゴリズムが望ましい動作を示すまで既存の条件の係数の調整です。 はい、この面でRLを克服することは可能ですが 、そのような闘争は満足をもたらしません。 時にはそれが必要ですが、その過程で何かを学んだとは感じませんでした。
参考までに、レゴコンストラクターの折りたたみに関する記事の報酬関数の1つを次に示します。
この関数の開発にどれだけの時間を費やしたかはわかりませんが、メンバーの数と異なる係数で「たくさん」と言います。
他のRL研究者との会話の中で、誤って設定された報酬を持つモデルの元の行動に関するいくつかの話を聞きました。
- 同僚がエージェントに部屋を移動するように教えます。 エージェントが国境を越えるとエピソードは終了しますが、この場合罰金は科されません。 トレーニングの終わりに、エージェントは自殺行動を採用しました。これは、負の報酬を得るのが非常に簡単で、正の報酬が難しすぎるため、結果が0の迅速な死亡が、負の結果のリスクが高い長寿命よりも望ましいからです。
- 友人がロボットアームシミュレーターを訓練して、テーブルの上の特定のポイントに向かって移動しました。 ポイントはテーブルに対して相対的に定義され、テーブルは何にも接続されていなかったことがわかります。 モデルはテーブルを非常に激しくノックすることを学び、テーブルを倒して目標点を動かしました-そしてそれは手の隣にありました。
- 研究者は、ハンマーを使って釘を打つロボットアームのシミュレーターを訓練するためのRLの使用について話しました。 報酬はもともと、釘が穴にどれだけ入ったかによって決まりました。 ロボットはハンマーを拾う代わりに、手足で釘を打ちました。 それから彼らはロボットにハンマーを拾うように奨励する報酬を追加しました。 その結果、ロボットの学習戦略はハンマーを取り、ツールを釘に投げ込み、通常の方法では使用しないことでした。
確かに、これはすべて間違った唇からの物語です。個人的に、私はこの行動をしたビデオを見たことはありません。 しかし、これらの物語はどれも私には不可能ではないようです。 私はRLで何度も火傷を負い、信じられませんでした。
ペーパーオプティマイザーに関する話をしたい人を知っています。 さて、私は正直に理解しています。 しかし、実際には、私はこれらの話を聞くのにうんざりしています。なぜなら、彼らは常に本当の話としての超人的な混乱した強いAIについて話しているからです。 周りに毎日たくさんの実際の物語があるのに、なぜそれを発明するのか。
良い報酬を与えられたとしても、局所的な最適を避けることは困難です。
以前のRLの例は、多くの場合「報酬ハック」と呼ばれます。私にとっては、これはスマートで非標準のソリューションであり、タスクデザイナーから期待されるソリューションよりも多くの報酬をもたらします。
ハッキング報酬は例外です。より一般的なのは、探査と開発の間の誤った妥協から生じる誤った局所的最適の場合です。
これは私のお気に入りのビデオの1つです。HalfCheetahで学習する正規化された特典機能を実装します。部外者の観点から、これは非常に、非常に
バカ。しかし、私たちは、私たちが横から見て、あなたの足で動くことはあなたの背中に横たわるよりも優れているという多くの知識を持っているという理由だけで愚かだと言います。RLはこれを知りません!彼は状態ベクトルを見て、アクションベクトルを送信し、肯定的な報酬を受け取っていることを確認します。以上です。
トレーニング中に何が起こったかについて私が思いつくことができる最も妥当な説明を以下に示します。
- ランダムな研究で、このモデルは、動きを止めないよりも前に倒す方が収益性が高いことを発見しました。
- モデルは、このような動作を「フラッシュ」して継続的に低下し始めるのに十分な頻度でこれを実行しました。
- 前方に倒れた後、モデルは、十分な力を加えると、バックフリップを行うことができ、それがもう少しの報酬を与えることを学びました。
- — , , «» .
- , — « » , ? .
これは非常におもしろいですが、明らかにロボットに望むものではありません。
失敗した別の例を次に示します。今回はReacher(video)に囲まれています。今回の実行では、通常、ランダムな初期重みがアクションに対して強い正または非常に負の値を与えました。このため、ほとんどのアクションは可能な限り最大または最小の加速で実行されました。実際、モデルを非常に簡単にスピンアップできます。各ヒンジに大きな力を加えるだけです。ロボットが回転するとき、この状態から何らかの理解可能な方法で抜け出すことはすでに困難です:横行回転を停止するために、いくつかの偵察手順が取られるべきです。もちろん、これは可能です。しかし、これは今回の実行では発生しませんでした。

どちらの場合も、古典的な偵察/搾取の問題があります。これは、太古から、強化された学習を追求してきました。データは現在のルールから派生しています。現在のルールが広範なインテリジェンスを提供している場合、不要なデータを受け取り、何も学習しません。エクスプロイトが多すぎる-最適でない動作を「縫う」。
このテーマには直感的に楽しいアイデアがいくつかあります。内部の動機と好奇心、カウントに基づく知性などです。これらのアプローチの多くは、80年代以前に最初に提案され、一部はディープラーニングモデル用に改訂されました。しかし、私の知る限り、すべての環境で安定して機能するアプローチはありません。時には役立つこともあれば、役に立たないこともあります。ある種のインテリジェンストリックがどこでも機能するのは良いことですが、近い将来、彼らがこの口径の特効薬を見つけるとは思いません。誰も試みていないからではなく、探査-開発が非常に、非常に、非常に、非常に複雑な問題だからです。多腕バンディットに関するウィキペディアの記事からの引用:
歴史上初めて、この問題は第二次世界大戦の連合国の科学者によって研究されました。ピーター・ホイットルによると、ドイツの科学者もそれに時間を費やすために、ドイツ人に投げつけられるべきであることが示唆されたほど、それは非常に扱いにくいことが判明しました。(情報源:Q-Learning for Bandit
Problem 、Duff 1995)私はあなたの報酬を故意に誤解し、ローカル最適を達成するための最も怠ziな方法を積極的に探している悪魔として深いRLを提示します。少しばかげているが、それは本当に生産的な思考であることが判明した。
ディープRLが機能する場合でも、奇妙な動作に再トレーニングできます。
ディープラーニングは、テストスイートで学習することが社会的に受け入れられる唯一の機械学習領域であるため、人気があります。(出典)
強化トレーニングのプラス面は、特定の環境で良い結果を達成したい場合、狂人として再トレーニングできることです。欠点は、モデルを他の環境に拡張する必要がある場合、恐ろしい再訓練のためにおそらくうまく機能しないことです。
DQNネットワークは、多くのAtariゲームに対応しています。これは、各モデルのすべてのトレーニングが、1つのゲームで最大の結果を達成するという単一の目標に焦点を合わせているためです。最終モデルは他のゲームに拡張することはできません。なぜなら、それはそのように教えられていなかったからです。新しいAtariゲームのトレーニング済みDQNを構成できます(プログレッシブニューラルネットワーク(Rusu et al、2016)を参照))、しかし、そのような転送が行われるという保証はなく、通常誰もこれを期待していません。これは、ImageNetの事前にトレーニングされた機能で人々が目にする大成功ではありません。
いくつかの明白なコメントを防ぐために:はい、原則として、幅広い環境でのトレーニングはいくつかの問題を解決できます。場合によっては、モデルのアクションのこのような拡張は単独で発生します。例はナビゲーションです。そこでは、ターゲットのランダムな位置を試して、汎用関数を使用して一般化できます。 (Universal Value Function Approximators、Schaul et al、ICML 2015を参照)この作業は非常に有望であると思いますが、後でこの作業からさらに例を示します。しかし、ディープRLを一般化する可能性は、さまざまなタスクセットに対処するほど大きくないと思います。認識はずっと良くなりましたが、「管理のためのImageNet」が登場する前に、深いRLはまだ先を行っています。 OpenAIユニバースはこのき火に火をつけようとしましたが、聞いたところによると、このタスクは難しすぎてほとんど何もしませんでした。
モデルを一般化するそのような瞬間はありませんが、私たちは驚くほど狭いモデルの範囲に留まっています。例として(そして自分の仕事を笑う言い訳として)、Can Deep RL Solve Erdos-Selfridge-Spencer Gamesの記事を見てください。 (Raghu et al、2017)。最適なゲームのための分析形式での解決策がある2人のプレーヤーのための組み合わせゲームを研究しました。最初の実験の1つでは、プレーヤー1の動作を記録し、RLを使用してプレーヤー2を訓練しました。この場合、プレーヤー1のアクションを環境の一部と見なすことができます。最適なプレーヤー1に対してプレーヤー2を教えると、RLが高い結果を示すことができることが示されました。しかし、最適でないプレーヤー1に同じルールを適用すると、最適でないプレーヤーには適用されなかったため、プレーヤー2の有効性が低下しました。
記事の著者Lanctot et al、NIPS 2017同様の結果が得られました。ここでは、2人のエージェントがレーザータグを再生します。エージェントは、マルチエージェント強化トレーニングを使用してトレーニングされます。一般化をテストするために、5つのランダムな開始点(sid)からトレーニングが開始されました。これは、互いに対戦するように訓練されたエージェントのビデオです。
あなたが見ることができるように、彼らは接近してお互いに撃つことを学びました。その後、著者はある実験からプレーヤー1を取り出し、別の実験からプレーヤー2と一緒に連れてきました。学習したルールを一般化すると、同様の動作が見られるはずです。
ネタバレ:彼には会わない。
これは一般的なマルチエージェントRL問題のようです。エージェントが互いに訓練されると、一種の共同進化が起こります。エージェントは本当にお互いに本当によく戦うように訓練されていますが、彼らが以前に会ったことのないプレーヤーに対して彼らが送られるとき、彼らの有効性は減少します。これらのビデオの唯一の違いはランダムシードであることに注意してください。同じ学習アルゴリズム、同じハイパーパラメーター。動作の違いは、純粋に初期条件のランダムな性質によるものです。
それにもかかわらず、互いに独立した遊びがある環境で得られたいくつかの印象的な結果があります-それらは一般的な論文と矛盾するようです。 OpenAIブログには、この分野での彼らの仕事についての良い投稿があります。。DIYプレイもAlphaGoとAlphaZeroの重要な部分です。私の直感的な考えは、エージェントが同じペースで学習すれば、常に競い合って互いの学習をスピードアップできますが、一方が他方よりもはるかに速く学習した場合、彼も弱者の脆弱性を悪用して再訓練します。対称的なスタンドアロンゲームから一般的なマルチエージェント設定に移行すると、トレーニングが同じ速度であることを確認するのが非常に難しくなります。
一般化を考慮しなくても、最終結果が不安定で再現が難しいことが判明する場合があります。
ほとんどすべての機械学習アルゴリズムには、学習システムの動作に影響するハイパーパラメーターがあります。多くの場合、手動またはランダム検索によって選択されます。
教師のトレーニングは安定しています。データセットを修正し、真のデータでチェックします。ハイパーパラメーターをわずかに変更しても、機能はあまり変化しません。すべてのハイパーパラメーターが適切に機能するわけではありませんが、長年にわたって多くの経験的なトリックが見つかっているため、多くのハイパーパラメーターはトレーニング中に生命の兆候を示します。人生のこれらの兆候は非常に重要です。彼らはあなたが正しい道を進んでおり、合理的なことをしていると言います-そしてあなたはより多くの時間を費やす必要があります。
現在、ディープRLはまったく安定しておらず、研究プロセスで非常に迷惑です。
Google Brainで働き始めたとき、私はすぐに上記の記事Normalized Advantage Function(NAF)からアルゴリズムを実装し始めました。 2〜3週間で済むと思いました。私はいくつかの切り札がありました:Teano(TensorFlowによく移植されています)に精通している人、深いRLでの経験、NAF記事の筆頭著者がBrainにインターンしているので、質問で彼を悩ませることができました。
最終的に、ソフトウェアのいくつかのバグのために、結果を再現するのに6週間かかりました。問題は、なぜこれらのバグが長い間隠れていたのかということです。
この質問に答えるために、OpenAIジムで最も単純な連続管理タスクである振り子タスクを検討してください。この問題では、振り子が特定のポイントに固定され、重力がそれに作用します。入力は3次元の状態です。作用空間は一次元です。それは振り子に加えられる力の瞬間です。目標は、正確に垂直位置で振り子のバランスをとることです。
これは小さな問題であり、明確に定義された報酬のおかげでさらに簡単になります。報酬は振り子の角度に依存します。振り子を垂直位置に戻すアクションは、報酬を与えるだけでなく、それを増やします。
ここにあるビデオモデルで、ほとんどは、動作します。振り子を正確な垂直位置に移動させるわけではありませんが、重力を補正するための正確な力のモーメントを提供します。そして、すべてのエラーを修正した後のパフォーマンスグラフです。各行は、10回の独立した実行の1つからの報酬曲線です。同じハイパーパラメーターで、違いはランダムな開始点のみです。10回の実行のうち7回がうまくいきました。 3つは通過しませんでした。30%の故障率は運用可能と見なされます。これは、変分情報の最大化調査(Houthooft et al、NIPS 2016)の別のグラフです。水曜日-ハーフチーター。詳細はそれほど重要ではありませんが、賞はまばらにされました。 y軸は一時的な報酬、x軸はタイムスライスの数、使用されるアルゴリズムはTRPOです。


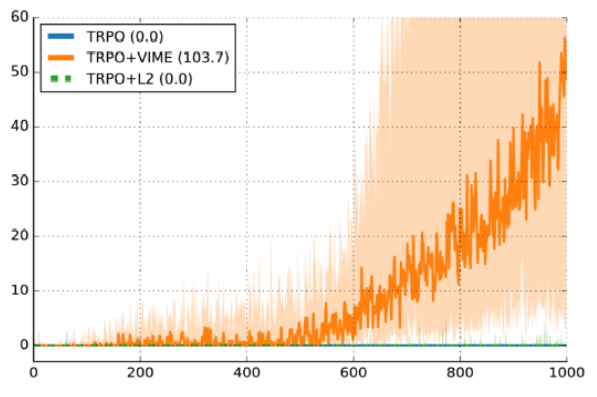
暗い線は10個のランダムsidのパフォーマンスの中央値であり、影付きの領域は25パーセンタイルから75パーセンタイルまでのカバレッジです。誤解しないでください、このグラフはVIMEの良い議論のようです。しかし、一方で、25パーセンタイルの線は本当にゼロに近いです。これは、開始点がランダムであるために約25%が機能しないことを意味します。
先生と一緒に教えることにも違いがありますが、それほど悪くはありません。ランダムsidを使用した実行の30%でトレーニングコードが教師に対応していなかった場合、データのロード中またはトレーニング中に何らかのエラーが発生したことは間違いありません。補強付きのトレーニングコードがランダム性よりもうまく対処できない場合、それがバグなのか、それとも悪いハイパーパラメーターなのか、私は運が悪いのかわかりません。
これは、「なぜ機械学習が「難しい」のか」という記事の説明です。主要な点は、機械学習がクラッシュスペースに追加の次元を追加し、クラッシュオプションの数を指数関数的に増やすことです。ディープRLは、ランダム性という別の次元を追加します。そして、ランダム性の問題を解決する唯一の方法は、ノイズを除去することです。
学習アルゴリズムのサンプリングが非効率的で、同時に安定していない場合、研究の生産性が大幅に低下します。たぶん彼は100万歩しか必要ないでしょう。しかし、これに5つのランダムな入力値を掛けてから、ハイパーパラメーターの広がりを掛けると、仮説を効果的にテストするために必要な計算が指数関数的に増加します。
それが簡単になったら、私はこれをしばらくやっています-そして、先週約6を費やして、モデルグラデーションをゼロから取得しました。これは、RLタスクの束でケースの50%で動作します。 そして、私はGPUクラスターと、毎日昼食をとる数人の友人がいます。そして、彼らはこの数年間、この分野で働いています。
さらに、畳み込みニューラルネットワークの正しい設計に関する教師とのトレーニング分野から得られた情報は、主な制限がクレジットの分配/ビットレート制御であり、効果的なプレゼンテーションの欠如ではないため、強化されたトレーニングの分野に拡張されないようです。 ResNet、batchnorm、および非常に深いネットワークはここでは機能しません。
[教員養成]働きたい。 何かを台無しにしたとしても、通常は何らかのランダムでない結果が得られます。 RLを機能させる必要があります。 何かを台無しにしたり、十分な設定を行わなかったりすると、ほぼ確実にランダムなルールよりも悪いルールを取得することになります。 そして、すべてが完全に調整されていても、悪い結果はケースの30%にあります。 なんで? はい、そのように。
要するに、あなたの問題は、「ニューラルネットワークの設計」の複雑さよりも、深いRLの複雑さによる可能性が高いです。 -OpenAIで働いていたAndrej KarpathyによるHacker Newsに対するコメント
ランダムシードの不安定性は、炭鉱のカナリアのようなものです。 単純な偶然の一致が実行間のこのような強い違いにつながる場合は、実際のコードの変更による違いを想像してください。
幸いなことに、この思考実験はすでに実施されており、記事「Deep Reinforcement Learning That Matters」(Henderson et al、AAAI 2018)で説明されているため、この思考実験を行う必要はありません。 結論は次のとおりです。
- 定数に報酬を乗算すると、パフォーマンスに大きな違いが生じる可能性があります。
- 5つのランダムシード(レポートの一般的なメトリック)は、重要な結果を示すのに十分ではない場合があります。慎重に選択すると、信頼区間が重複しないためです。
- 同じアルゴリズムの異なる実装は、同じハイパーパラメーターであっても、同じタスクのパフォーマンスが異なります。
私の理論では、データは常にインターネットで収集され、制御される唯一のパラメーターは報酬のサイズであるため、RLは初期化と教育プロセスのダイナミクスの両方に非常に敏感です。 良い学習例にランダムに出会うモデルは、はるかにうまく機能します。 モデルに良い例が見当たらない場合、何も学習していない可能性があります。これは、偏差が決定的でないとますます確信しているためです。
しかし、ディープRLのすべてのすばらしい成果についてはどうでしょうか。
もちろん、徹底的な強化学習はいくつかの優れた結果を達成しています。 DQNはもはや目新しいものではありませんが、かつてはまったくおかしな発見でした。 同じモデルは、各ゲームを個別に調整することなく、ピクセルによって直接研究されます。 AlphaGoとAlphaZeroも非常に印象的な成果を残しています。
しかし、これらの成功に加えて、深層RLが現実の世界にとって実用的な価値がある場合を見つけることは困難です。
現実の世界でディープRLを実際のタスクに使用する方法を考えてみました-これは驚くほど難しいことです。 私は推奨システムでいくらかの用途を見つけると思ったが、私の意見では、 協調フィルタリングとコンテキストバンディットが依然としてそこを支配している。
私が最終的に見つけた最高のものは、2つのGoogleプロジェクトでした。データセンターのエネルギー消費を削減することと、最近発表されたAutoML Visionプロジェクトです。 OpenAIのジャック・クラークは読者に同様の質問をツイートし、同じ結論に達しました 。 (昨年、AutoMLの発表前にツイート)。
NIPSで無人のレーシングカーの小さなモデルを見せ、彼のために深いRLシステムを開発したと言ったので、アウディは深いRLで何か面白いことをしていることを知っています。 大きなテンソルグラフのデバイスの配置を最適化するための巧みな作業が行われていることを知っています(Mirhoseini et al、ICML 2017) 。 Salesforceには、RLをかなり慎重に使用する場合に機能するテキスト要約モデルがあります。 この記事を読んでいる間、金融会社はおそらくRLを実験していますが、これについてはまだ証拠がありません。 (もちろん、金融会社には市場で遊ぶ方法を隠す理由があるため、確固たる証拠を得ることができません)。 Facebookは、チャットボットとスピーチのディープRLに最適です。 歴史上のすべてのインターネット企業は、おそらくRLを広告モデルに導入することを考えたことがありますが、誰かが実際にRLを実装した場合、それについては沈黙しています。
だから、私の意見では、徹底的なRLはまだ学術研究のトピックであり、広範囲に使用するための信頼できる技術ではなく、実際に効果的に機能させることができます-そして成功した人は情報を開示しません。 最初の選択肢の方が可能性が高いと思います。
画像の分類の問題で私に来た場合、事前に訓練されたImageNetモデルをお勧めします-彼らはおそらく完璧に仕事をするでしょう。 私たちは、シリコンバレーシリーズの映画製作者が冗談めかしてホットドッグを認識するための本当のAIアプリケーションを作っている世界に住んでいます。 ディープRLの同じ成功については言えません。
これらの制限がある場合、ディープRLを使用するタイミングは?
これは先験的に難しい質問です。 問題は、同じRLアプローチを異なる環境に適用しようとしていることです。 常に機能するとは限らないのは当然です。
上記に基づいて、強化学習の既存の成果からいくつかの結論を引き出すことができます。 これらは、ディープRLが何らかの質的に印象的な動作を学習するか、この分野の以前のシステムよりもよく学習するプロジェクトです(ただし、これらは非常に主観的な基準です)。
現時点での私のリストです。
- 前のセクションで言及したプロジェクト:DQN、AlphaGo、AlphaZero、パルクールボット、データセンターのエネルギー消費量の削減、およびNeural Architecture SearchによるAutoML。
- OpenAI Dota 2 1v1 Shadow Fiendボット 。 簡素化された戦闘設定で最高のプロを倒します 。
- スーパースマッシュブラザーズメレーボット 、 1v1ファルコンのプロプレイヤーを同じように倒すことができます。 (Firoiu et al、2017)。
(最近の余談:機械学習は最近、プロの無制限のテキサスホールデムプレーヤーを打ち負かしました。このプログラムは、 Libratus(Brown et al、IJCAI 2017)とDeepStack(Moravčíket al、2017)の両方を使用します。ディープRL。両方のシステムは非常に優れていますが、強化されたディープラーニングを使用せず、反省の反事実的最小化のアルゴリズムとサブゲームの有能な反復ソリューションを使用します。
このリストから、学習を促進する共通のプロパティを分離できます。 以下にリストされているプロパティはいずれもトレーニングに必要ではありませんが、存在するほど、結果は確実に良くなります。
- ほぼ無制限のエクスペリエンスの簡単な生成 。 ここで利点は明らかです。 データが多いほど、トレーニングが容易になります。 これは、アタリ、ゴー、チェス、将gi、およびシミュレートされたパルクールボット環境に適用されます。 これはおそらく、データセンターの電源プロジェクトにも当てはまります。これは、以前の研究(Gao、2014)で、ニューラルネットワークがエネルギー効率を高精度で予測できることが示されたためです。 このようなシミュレーションモデルを使用して、RLシステムをトレーニングします。
おそらくこの原則はDota 2とSSBMでの動作に適用されますが、ゲームの最大速度とプロセッサの数に依存します。 - タスクはより単純な形式に簡素化されます。 ディープRLで最もよくある間違いの1つは、野心的な計画と夢です。 強化学習は何でも可能です! しかし、これは一度にすべてを引き受ける必要があるという意味ではありません。
OpenAI Dota 2ボットは、ゲームの開始時にのみ動作し、Shadow Fiend対Shadow Fiend、1x1のみ、特定の設定、固定位置および建物タイプで動作し、おそらくDota 2 APIを使用してグラフィック処理タスクを解決しません。 SSBMボットは超人的なパフォーマンスを発揮しますが、1x1ゲームでのみ、キャプテンファルコンとのみ、無限の試合時間を持つBattlefieldでのみです。
これはボットのbot笑ではありません。 実際、単純な問題が解決されているかどうかさえわからないのに、なぜ複雑な問題を解決するのですか? この分野での一般的なアプローチは、最初にコンセプトの最小限の証明を得て、後でそれを一般化することです。 OpenAIはDota 2の作業を拡大します。作業はSSBMボットを他のキャラクターに拡大する作業を続けています。 - 独立したゲームで学ぶ方法があります。 これが、AlphaGo、AlphaZero、Dota 2 Shadow Fiend、SSBM Falconボットの仕組みです。 独立したゲームとは競争ゲームを意味しますが、両方のプレイヤーは1人のエージェントで制御できます。 どうやら、この設定は最も安定した結果をもたらします。
- 学習に対する適切な報酬を決定する明確な方法があります。 2人用のゲームでは、これは勝つと+1、負けると-1です。 Zophらによる元のNeural Architecture Searchの記事、ICLR 2017では、訓練されたモデルの検証は正確でした。 スムーズな報酬を求めるたびに、間違った目標に合わせてモデルを最適化する最適でないポリシーを学習する機会を導入します。
適切な報酬を得る方法について詳しく知りたい場合は、「 正しいスコアリングルール 」というフレーズを検索してみてください。 このTerrence Taoのブログ投稿は、アクセシブルな例を提供しています。
学習に関しては、何が効果的で何が効果的でないかを試してみる以外にアドバイスはありません。 - 継続的な報酬が決定される場合、少なくともそれは豊かでなければなりません 。 Dota 2では、最新のヒット(プレイヤーによって殺されたモンスターごと)とヘルス(正確な攻撃またはスキルの適用後にトリガーされる)に対して報酬を与えることができます。 これらの信号は迅速かつ頻繁に到着します。 SSBMボットは、攻撃が成功するたびに信号で、行われ、受けたダメージに対して報酬を受け取ることができます。 アクションと結果の間の遅延が短いほど、フィードバックループのクローズが速くなり、強化システムが最大の報酬への道を見つけるのが容易になります。
例:ニューラルアーキテクチャ検索
いくつかの原則を組み合わせて、Neural Architecture Searchの成功を分析できます。 ICLR 2017の元のバージョンによると、12,800のサンプルの後、ディープRLはその種の最高のニューラルネットワークアーキテクチャを設計できます。 確かに、各例では、ニューラルネットワークを収束するようにトレーニングする必要がありましたが、サンプルの数では依然として非常に効果的です。
上記のように、報酬は検証の正確さです。 これは非常に豊富な報酬信号です。ニューラルネットワークの構造の変更によって精度が70%から71%に向上した場合でも、RLはその恩恵を受けます。 さらに、ディープラーニングのハイパーパラメーターが線形独立に近いという証拠があります。 (これは、 ハイパーパラメーター最適化:スペクトルアプローチ(Hazan et al、2017)で経験的に示されています-興味がある場合、私の履歴書はこちらです)。 NASはハイパーパラメーターを特に構成しませんが、ニューラルネットワークの設計決定がこの方法で行われることは非常に合理的だと思います。 ソリューションとパフォーマンスの間に強い相関関係があるため、これは学習にとって朗報です。 最後に、ここでは豊富な報酬だけでなく、モデルを教える際に私たちにとって重要なことはまさにここにあります。
これらの理由から、他の環境で必要な数百万の例と比較して、NASが最適なニューラルネットワークを決定するために約12,800のトレーニング済みネットワークのみを必要とする理由が明らかになります。 さまざまな側面から、すべてがRLに有利に働きます。
一般に、同様の成功事例は依然として例外であり、規則ではありません。 強化された学習が説得力を持って機能するためには、パズルの多くの部分を正しく形成する必要があり、それでも困難です。
一般に、ディープRLはすぐに使用できるテクノロジーではありません。
未来を見る
古いことわざがあります-時間の経過とともに、すべての研究者は自分の研究分野を憎む方法を学びます。 冗談は、彼らが問題をあまりにも好きなので、研究者がまだこれをし続けているということです。
それは、強化されたディープラーニングについて私が感じることです。 上記のすべてにもかかわらず、私は、RLが効果的でない可能性があるものを含むさまざまな問題にRLを使用することを試みる必要があることを絶対に確信しています。 しかし、RLを他にどのように改善できますか?
技術に改善の時間が与えられている場合、ディープRLが将来機能しない理由はありません。 深いRLが広範囲に使用できるほど信頼できるようになると、いくつかの非常に興味深いことが起こり始めます。 問題はこれを達成する方法です。
以下に、もっともらしい将来の開発オプションをリストしました。 この方向に発展するためにさらなる研究が必要な場合、これらの分野の関連する科学論文へのリンクが示されます。
局所的な最適条件で十分です。 人々自身がすべてにおいてグローバルに最適であると主張するのはar慢です。 私たちは文明を作成するために最適化された他の種よりわずかに優れていると思います。 同じ精神で、ローカルソリューションが個人の基本レベルを超えている場合、RLソリューションはグローバルオプティマを追求する必要はありません。
鉄がすべてを決定します 。 AIを作成するための最も重要なことは、単に鉄の速度を上げることだと信じている人々を知っています。 個人的に、私は鉄がすべての問題を解決するのではないかと疑っていますが、確かに重要な貢献をするでしょう。 すべてが高速に動作するほど、サンプルの非効率性に対する懸念が少なくなり、インテリジェンスの問題を通じてブルートフォースを突破しやすくなります。
さらに学習キューを追加します 。 何が効果を正確に与えるかについての情報がほとんどないため、まばらな報酬を同化することは困難です。 幻覚( Hindsight Experience Replay、Andrychowicz et al、NIPS 2017 )の形で肯定的な報酬を生成するか、支援タスク( UNREAL、Jaderberg et al、NIPS 2016 )を定義するか、自己制御トレーニングから始まる世界の良いモデルを構築することが可能です。 いわば、チェリーをケーキに追加します。
モデルベースのトレーニングにより、サンプルの効率が向上します。 モデルに基づいてRLを説明する方法は次のとおりです。「誰もがやりたいと思っていますが、その方法はほとんどわかっていません。」 原則として、優れたモデルは多くの問題を修正します。 AlphaGoの例に見られるように、モデルの存在は原則として、優れたソリューションの検索を非常に容易にします。 世界の良いモデルは新しいタスクにうまく移され、世界のモデルの導入により、新しい経験を想像することができます。 私の経験では、モデルベースのソリューションでは必要なサンプルも少なくなります。
しかし、良いモデルを訓練することは難しいことです。 低次元の状態モデルが時々機能するという印象を受けましたが、通常、画像モデルは難しすぎます。 しかし、それらがより簡単になると、いくつかの興味深いことが起こります。
Dyna(Sutton、1991)およびDyna-2(Silver et al。、ICML 2008)は、この分野の古典作品です。 モデルベースの学習を深層ネットワークと組み合わせる作業の例として、バークレーロボティクス研究所の最近の記事をいくつかお勧めします。
- モデルフリーの微調整を使用したモデルベースのディープRLのニューラルネットワークダイナミクス(Nagabandi et al、2017 ;
- 時間的スキップ接続を使用した自己管理視覚計画(Ebert et al、CoRL 2017) ;
- 軌道中心強化学習のためのモデルベースの更新とモデルフリーの更新の組み合わせ(Chebotar et al、ICML 2017) ;
- 視覚運動学習のための深空間オートエンコーダー(フィンら、ICRA 2016) ;
- ガイド付きポリシー検索(Levine et al、JMLR 2016) 。
強化学習の使用は、微調整として簡単です。 最初のAlphaGoの記事は、教師のトレーニングとRLの微調整から始まりました。 これは、より高速だが強力ではない方法を使用して初期トレーニングを高速化するため、適切なオプションです。 この方法は、異なるコンテキストでも機能しました-Sequence Tutor(Jaques et al、ICML 2017)を参照してください。 別のシステムがこの「事前」の作成に関与している場合、確率(無作為)ではなく、合理的な事前分布のRLプロセスの開始と見なすことができます。
報酬関数は学習可能になります。 機械学習は、データに基づいて、人が設計したものよりも優れたものを構築することを学ぶことができることを約束します。 報酬関数を選択することが非常に難しい場合、このタスクに機械学習を使用してみませんか? シミュレーション学習とRLの反対-これらの豊富な領域は、報酬関数が人からの確認または評価によって暗黙的に決定できることを示しています。
逆RLおよびシミュレーショントレーニングに関する最も有名な科学論文は、Inverse Reinforcement Learning(Ng and Russell、ICML 2000)のアルゴリズム、Inverse Reinforcement Learningを介した実習(Abbeel and Ng、ICML 2004)およびDAgger(Ross、Gordon、and Bagnell、AISTATS)です。 2011) 。
これらのアイデアを深層学習の分野に拡大する最近の作品には、 ガイド付きコスト学習(Finnなど、ICML 2016) 、 時間制約ネットワーク(Sermanet他、2017) 、およびLearning From Human Preferences(Christiano他、NIPS 2017)が含まれます。 特に、リストされている最後の記事は、人々によって付けられた評価に由来する報酬が、実際にトレーニングされた元のハードコーディングされた報酬よりも優れていることを示しています-これは良い実用的な結果です。
詳細なトレーニングを使用しない長期的な仕事の中で、私はInverse Reward Design(Hadfield-Menell et al、NIPS 2017)と物理的な人間の相互作用からの学習ロボット目標(Bajcsy et al、CoRL 2017)の記事が気に入りました 。
転送を学習します。 学習の転送は、以前のタスクの知識を使用して新しいタスクの学習をスピードアップできることを約束します。トレーニングが異種タスクを解決するのに十分に信頼できるようになるとき、私はこれが未来であると絶対に確信しています。まったく勉強できない場合はトレーニングを移管することは難しく、タスクAとBがある場合、タスクAからタスクBへのトレーニングの移管が起こるかどうかを予測することは困難です。私の経験では、ここに非常に明白な答えがあるか、まったく理解できません。そして、最も明白な場合でも、非自明なアプローチが必要です。
この分野での最近の研究は、Universal Value Function Approximators(Schaul et al、ICML 2015)、Distral(Whye Teh et al、NIPS 2017)およびOver 克服Catastrophic Forgetting(Kirkpatrick et al、PNAS 2017)です。古い作品については、Horde(Sutton et al、AAMAS 2011)を参照してください。
たとえば、ロボット工学は、シミュレーターから実世界へのトレーニングの転送(タスクのシミュレーションから実際のタスクへ)で順調に進歩しています。参照してください。ザ・ドメインのランダム化を(トービンら、2017 IROS) 、シム・ツー・実ロボットネッツプログレッシブと学習(Rusuのら、Corl 2017)とGraspGAN(Bousmalisら、2017) 。(免責事項:私はGraspGANに取り組みました)。
良い事前知識は、トレーニング時間を大幅に短縮できます。。これは、以前のポイントのいくつかと密接に関連しています。一方で、学習の移転は、過去の経験を使用して、他のタスクの事前確率分布を作成することです。 RLアルゴリズムは、マルコフの意思決定プロセスで動作するように設計されています。ここで、一般化に問題があります。私たちのソリューションが環境の狭いセクターでのみうまく機能すると信じるなら、これらの環境を効果的に解決するために共通の構造を使用できるはずです。
Pieter Ebbillは、スピーチの中で、現実の世界で解決するようなタスクのみに深いRLを要求する必要があることに注目しています。これは非常に理にかなっていることに同意します。非現実的なタスクの学習を遅くすることで、新しい実際のタスクをすばやく学習できるように、実世界の事前知識が必要です。これは完全に受け入れられる妥協案です。
困難なのは、このような実世界の事前の設計が非常に難しいことです。ただし、これがまだ可能である可能性は十分にあると思います。個人的には、データから合理的な事前分布を生成する方法を提供するため、メタトレーニングに関する最近の研究に満足しています。たとえば、RLを使用して倉庫をナビゲートする場合、まずメタトレーニングを使用して一般的なナビゲーションを教え、次にロボットが移動する特定の倉庫に対して事前にこれを微調整することは興味深いでしょう。これは未来に非常に似ており、問題はメタトレーニングがそこに到達するかどうかです。
最新の学習学習作業の概要については、BAIR(Berkeley AI Research)のこの出版物を参照してください。
より複雑な環境は逆説的に簡単になります。パルクールボットに関するDeepMindの記事の主な結論の1つは、タスクのバリエーションをいくつか追加することでタスクを非常に複雑にすると、実際にはトレーニングを簡素化できるということです。ルールは他のすべてのパラメーターのパフォーマンスを損なうことなく1つの設定で再トレーニングできないためです。ドメインランダム化に関する記事やImageNetでも同様のことがわかりました。ImageNetでトレーニングされたモデルは、CIFAR-100でトレーニングされたモデルよりもはるかに優れた他の環境に拡張できます。先ほど言ったように、もっと普遍的なRLに移行するために、「管理用のImageNet」を作成するだけで十分でしょう。
多くのオプションがあります。OpenAIジムは最も人気のある環境ですが、アーケード学習環境、Roboschool、DeepMind Lab、DeepMind Control Suite、およびELF。
最後に、これは学術的な観点からはs辱的ですが、深いRLの経験的な問題は実際的な観点からは問題ではないかもしれません。架空の例として、金融会社がディープRLを使用しているとします。彼らは、3つのランダムなsidを使用して、過去の米国株式市場データについて販売代理店を訓練します。実際のA / Bテストでは、最初のシードは2%少ない収入をもたらし、2番目のシードは平均収益性で機能し、3番目のシードは2%増加します。この仮想バージョンでは、再現性は重要ではありません-歩留まりが2%高いモデルを展開して喜ぶだけです。同様に、販売代理店が米国でのみうまく機能することは問題ではありません。世界市場でうまく機能しない場合は、そこでは使用しないでください。異常なシステムと再現可能な異常なシステムには大きな違いがあります。おそらく、最初に集中する必要があります。
今どこにいるの
多くの点で、ディープRLの現在の状態に悩まされています。それにもかかわらず、それは研究者の間でそのような強い関心を集めていますが、これは私が他の分野で見たことはありません。私の気持ちは、アンドリュー・ウンがディープラーニングを適用するナッツとボルトとの彼の講演で言及したフレーズによって最もよく表されます:短期的な強い悲観主義、さらに強い長期的な楽観主義とのバランス。ディープRLは少し混chaとしていますが、私はまだ将来を信じています。
ただし、強化学習(RL)で問題を解決できるかどうか再度尋ねられた場合、私はすぐに「いいえ」と答えます。しかし、数年後にこの質問を繰り返すようお願いします。それまでに、おそらくすべてがうまくいくでしょう。