この投稿のコードは、投稿自体と同様にgithubに投稿されます。
最近まで、正規表現はある種の魔法のように思えました。 文字列が特定の正規表現に一致するかどうかを判断する方法がわかりませんでした。 そして今、私はそれを手に入れました! 以下は、200行未満のコードでの単純な正規表現エンジンの実装です。
パート1:解析
仕様書
正規表現を完全に実装するのは非常に困難な作業です。 さらに悪いことに、彼女はあなたにほとんど教えません。 私たちが実装しているバージョンは、ルーチンにスリップすることなくトピックを研究するのに十分です。 正規表現言語は次をサポートします。
.
-任意の文字に一致-
|
cde
またはcde
一致 -
+
-前のパターンの1つ以上に一致 -
*
-0個以上の前のパターンと一致 -
(
i)
-グループ化
オプションのセットは小さいですが、たとえば
m (t|n| ) | b
などの興味深い正規表現を作成するために使用できます
m (t|n| ) | b
m (t|n| ) | b
Star Trekの字幕なしでStar Warsの字幕を検索できるようにするか、
(..)*
ですべての長さの偶数行のセットを検索できます。
攻撃計画
3つの段階で正規表現を分析します。
- 正規表現を構文木に解析(解析)する
- 構文木を状態機械に変換する
- 私たちのラインのステートマシン分析
正規表現を分析するには(これについては以下で詳しく説明します)、 NFAと呼ばれるステートマシンを使用します。 高レベルでは、NFAは正規表現を表します。 入力を受信すると、NFAの状態から状態に移動します。 有効な遷移を行うことが不可能なポイントに到達した場合、正規表現は文字列と一致しません。
このアプローチは、Unixの著者の1人であるケントンプソンによって初めて実証されました。 CACM誌の1968年の記事で、彼はテキストエディターを実装するための原則を概説し、このアプローチを正規表現インタープリターとして追加しました。 唯一の違いは、彼の記事がマシンコード7094で書かれていることです。その時点では、すべてがよりハードコアでした。
このアルゴリズムは、RE2のような逆引き参照のないエンジンが、証明可能な線形時間で正規表現を分析する方法を単純化したものです。 これは、逆ルックアップを使用するPythonおよびJavaの正規表現エンジンとは大きく異なります。 細い線のある入力データの場合、それらはほぼ無限に実行されます。 実装は
O(length(input) * length(expression)
ます。
私のアプローチは、ラスコックスが彼の素晴らしい投稿でレイアウトした戦略とほぼ一致しています。
正規表現表現
一歩下がって、正規表現の提示方法について考えてみましょう。 正規表現の分析を開始する前に、コンピューターで使用できるデータ構造に変換する必要があります。 文字列の構造は線形ですが、正規表現には自然な階層があります。
文字列
abc|(c|(de))
見てみましょう。 文字列として残した場合は、戻ってトランジションを実行し、式を分析するときにブラケットのさまざまなセットを追跡する必要があります。 1つの解決策は、コンピューターを簡単にバイパスできるツリーに変換することです。 たとえば、
b+a
は次のようになります。
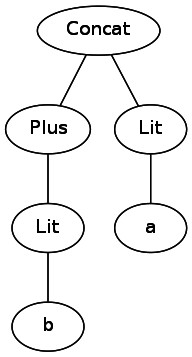
ツリーを表すには、クラス階層を作成する必要があります。 たとえば、
Or
クラスには、その両側を表す2つのサブツリーが必要です。 仕様から、正規表現の4つの異なるコンポーネント、
+
、
*
、
|
を認識する必要があることは明らかです
|
およびのような文字リテラル
.
、
a
および
b
さらに、ある式が別の式の後に続く場合も表す必要があります。 クラスは次のとおりです。
abstract class RegexExpr // ., a, b case class Literal(c: Char) extends RegexExpr // a|b case class Or(expr1: RegexExpr, expr2: RegexExpr) extends RegexExpr // ab -> Concat(a,b); abc -> Concat(a, Concat(b, c)) case class Concat(first: RegexExpr, second: RegexExpr) extends RegexExpr // a* case class Repeat(expr: RegexExpr) extends RegexExpr // a+ case class Plus(expr: RegexExpr) extends RegexExpr
正規表現解析
文字列からツリービューに移動するには、 解析(解析)と呼ばれる変換プロセスを使用する必要があります。 パーサーの構築については詳しく説明しません。 代わりに、独自の記述を行う場合に適切な方向を示すのに十分な情報を説明します。 パーサーコンビネーターライブラリ Scalaを使用して正規表現を解析する方法について簡単に説明します。
Scalaパーサーライブラリを使用すると、言語を記述する一連のルールを記述するだけで、パーサーを記述できます 。 残念ながら、それは多くの愚かなキャラクターを使用しますが、私はあなたがノイズを乗り越えて何が起こっているのか一般的な理解を得ることを望みます。
パーサーを実装するとき、操作の順序を決定する必要があります。 算術のように、PEMDASが使用されます[約。 あたり P arentheses、 E xponents、Ultiplication / D ivision、Addition / S ubtractionは、算術演算の順序を覚えることができるニーモニックです。] 、正規表現では異なるルールセットが適用されます。 演算子をその隣のシンボルに「リンク」するというアイデアの助けを借りて、これをより正式に表現できます。 異なる演算子は、異なる強度で「バインド」されます-同様に、5 + 6 * 4のような式で
*
、演算子
*
+
よりも多くバインドされます。 正規表現では、
*
|
よりも強力に付加されます
|
。 これは、最も弱い演算子が最上位にあるツリーの形で想像できます。
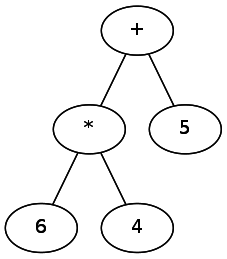
したがって、最も弱い演算子を最初に解析し、次に強い演算子を解析する必要があります。 解析では、これは演算子を抽出してツリーに追加し、文字列の残りの2つの部分を再帰的に処理することと考えることができます。
正規表現では、結合強度は次の順序です。
- 文字リテラルと括弧
-
+
および*
- 連結-bの後にa
-
|
4つのレベルの結合力があるため、4種類の式が必要です。 それらを(ランダムに)命名しました:
lit
、
lowExpr
(
+
、
*
)、
midExpr
(連結)および
highExpr
(
|
)。 コードに移りましょう。 最初に、最も基本的なレベル、つまり単一のキャラクター用のパーサーを作成します。
object RegexParser extends RegexParsers { def charLit: Parser[RegexExpr] = ("""\w""".r | ".") ^^ { char => Literal(char.head) }
構文を少し説明しましょう。 このコードは、
RegexExpr
を収集するパーサーを定義しています。 右側には、「
\w
(任意の単語文字)またはピリオドに一致するものを検索します。 見つかったら、
Literal
に変えてください。
括弧は最も強力なバインディングを持つため、パーサーの最下位レベルで定義する必要があります。 ただし、何かを括弧で囲む必要があります。 次のコードでこれを実現できます。
def parenExpr: Parser[RegexExpr] = "(" ~> highExpr <~ ")" def lit: Parser[RegexExpr] = charLit | parenExpr
ここで
*
と
+
を定義します:
def repeat: Parser[RegexExpr] = lit <~ "*" ^^ { case l => Repeat(l) } def plus: Parser[RegexExpr] = lit <~ "+" ^^ { case p => Plus(p) } def lowExpr: Parser[RegexExpr] = repeat | plus | lit
次に、次のレベルを定義します-連結:
def concat: Parser[RegexExpr] = rep(lowExpr) ^^ { case list => listToConcat(list)} def midExpr: Parser[RegexExpr] = concat | lowExpr
最後に、「または」を定義します。
def or: Parser[RegexExpr] = midExpr ~ "|" ~ midExpr ^^ { case l ~ "|" ~ r => Or(l, r)}
そして最後に
highExpr
を定義します。
highExpr
は
or
であり、最も弱いバインディング演算子
midExpr
。
or
、
or
がない
or
は
midExpr
です。
def highExpr: Parser[RegexExpr] = or | midExpr
次に、いくつかのヘルパーコードを追加して終了します。
def listToConcat(list: List[RegexExpr]): RegexExpr = list match { case head :: Nil => head case head :: rest => Concat(head, listToConcat(rest)) } def apply(input: String): Option[RegexExpr] = { parseAll(highExpr, input) match { case Success(result, _) => Some(result) case failure : NoSuccess => None } } }
そしてそれだけです! このコードをScalaで使用すると、仕様を満たす任意の正規表現の構文ツリーを生成できます。 結果のデータ構造はツリーになります。
正規表現を構文ツリーに変換できるようになったので、構文解析に近づいています。
パート2:NFAの生成
構文ツリーをNFAに変換する
前のパートでは、正規表現のフラットライン表現を階層構文ツリー形式に変換しました。 このパートでは、構文ツリーを状態マシンに変換します。 ステートマシンは、正規表現コンポーネントをグラフの線形形式に変換し、「aがbに続き、cが続く」という関係を作成します。 グラフ表現は、潜在的な行に関する分析を簡素化します。
正規表現に一致するためだけに別の変換を行うのはなぜですか?
もちろん、文字列からステートマシンに直接変換することもできます。 構文ツリーまたは文字列から正規表現を直接解析することもできます。 ただし、はるかに複雑なコードを処理する必要があります。 抽象化のレベルをゆっくりと下げることで、すべての段階でコードが簡単に理解できるようになります。 これは、ほぼ無限の境界線のケースを持つ正規表現インタープリターに似たものを構築する場合に特に重要です。
NFA、DFA、あなた
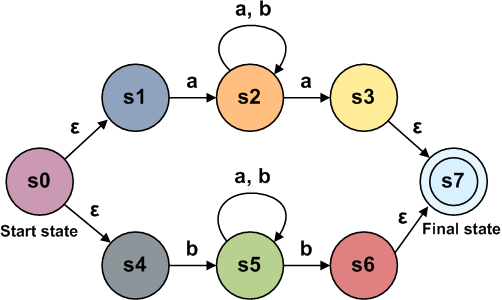
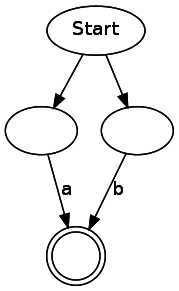
NFAまたは非決定性有限オートマトンと呼ばれる状態マシンを作成します。 状態と遷移の2種類のコンポーネントがあります。 図に表示される場合、状態は円で示され、遷移は矢印で示されます。 一致状態は二重丸で示されます。 遷移にマークが付けられている場合、この遷移を行うには、入力でこのシンボルを取得する必要があることを意味します。 トランジションにもタグがない場合があります。 これは、入力を消費せずに移行できることを意味します。 注:文献では、これはεと呼ばれることもあります。 単純な正規表現「ab」を表す状態マシン:
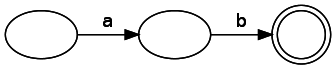
以下の図は、ノードから切り替えるときに同じ入力を消費する2つのパスを示しているため、ノードには特定の入力に対していくつかの正しい後続の状態がある場合があります。
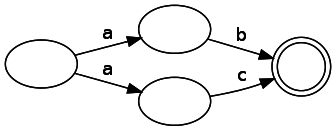
これを決定論的な有限状態マシン(DFA)と比較してください。DFAでは、その名前が示すように、与えられた入力が単一の状態変化を引き起こす可能性があります。 一方で、この制限の削減により、分析が少し複雑になりますが、一方で、すぐにわかるように、ツリーからの生成が大幅に簡素化されます。 基本的に、NFAとDFAは、表現できるステートマシンが互いに似ています。
理論の転換
構文ツリーをNFAに変換する戦略の概要を見てみましょう。 これは恐ろしく思えるかもしれませんが、プロセスを構成可能なフラグメントに分解すると理解しやすくなることがわかります。 変換する必要がある構文要素を思い出してください。
- 文字リテラル:
Lit(c: Char)
-
*
:Repeat(r: RegexExpr)
-
+
:Plus(r: RegexExpr)
- 連結:
Concat(: RegexExpr, : RegexExpr)
-
|
:Or(a: RegexExpr, b: RegexExpr)
その後の変換は、トンプソンが1968年の記事で最初に述べたものです。 変換スキームでは、
In
はステートマシンのエントリポイントを指し、
Out
は出力を指します。 実際には、Match状態、Start状態、またはその他の正規表現コンポーネントになります。
In
/
Out
抽象化により、有限状態マシンを構成および結合することができます-最も重要な結論。 この原則をより一般的な意味で適用して、構文ツリーの各要素を構成可能な状態マシンに変換します。
文字リテラルから始めましょう。 文字リテラルは、ある状態から別の状態への遷移であり、入力データを消費します。 リテラル「a」の消費は次のようになります。
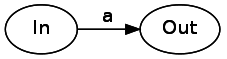
次に、連結を調べてみましょう。 構文ツリーの2つのコンポーネントを連結するには、ラベルなしの矢印でそれらを接続するだけです。 この例では、
Concat
は2つの任意の正規表現の連結を含めることができるため、スキーム内の
A
と
B
は、別々の状態ではなく、有限状態マシンになります。
A
と
B
両方がリテラルである場合、少し奇妙なことが起こります。 中間状態なしで2つの矢印を接続するにはどうすればよいですか? 答えは、リテラルは、ステートマシンの整合性を維持するために、両側にファントム状態を持つことができるということです。
Concat(A, B)
次のように変換されます。

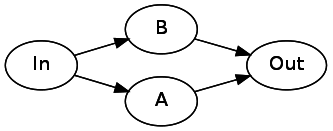
Or(A, B)
を表すには、初期状態から2つの別々の状態に分岐する必要があります。 これらのオートマトンが完了すると、両方とも次の状態(
Out
)を示すはずです。
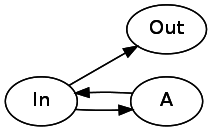
*
見てみましょう。 アスタリスクには、パターンの0回以上の繰り返しを指定できます。 これを実装するには、次の状態を直接指す1つの接続と、
A
介して現在の状態に戻る接続が必要です
A
A*
は次のようになります。
+
については、ちょっとしたトリックを使用します。
a+
は
aa*
です。 要約すると、
Plus(A)
を
Concat(A, Repeat(A))
書き換えることができます。 この場合の特別なパターンを開発する代わりに、そうします。
+
言語に含める特別な理由がありました。私が見逃した他のより複雑な正規表現要素が、私たちの言語のカテゴリーでどのように表現できるかを示したかったのです。
実践への転換
理論的な計画ができたので、コードでそれを実装する方法を理解しましょう。 可変グラフを作成して、ツリーを保存します。 私は不変性を好みますが、不変のグラフを作成することはその複雑さに悩まされ、私は怠け者です。
上記のスキームを基本コンポーネントに還元しようとすると、入力データを消費する矢印、一致状態、2つの状態に分割される1つの状態という3つのタイプのコンポーネントが得られます。 私はこれが少し奇妙に見え、潜在的に不完全であることを知っています。 そのようなソリューションが最もクリーンなコードにつながると私を信じる必要があります。 NFAコンポーネントの3つのクラスは次のとおりです。
abstract class State class Consume(val c: Char, val out: State) extends State class Split(val out1: State, val out2: State) extends State case class Match() extends State
注:通常のクラスではなく、
Match
case-
を作成しました。 Scalaのケースクラスは、デフォルトでクラスに便利な機能を提供します。 値に基づいて同等性を与えるため、私はそれを使用しました。 これにより、すべての
Match
オブジェクトが同等になり、便利な機能になります。 他のタイプのNFAコンポーネントについては、リンクの等価性が必要です。
コードは、構文ツリーを再帰的に走査し、
andThen
オブジェクトをパラメーターとして保存します。
andThen
、式の自由な出力に添付するものです。 構文ツリーの任意のブランチには、さらに先に進むものの十分なコンテキストがないため、必要です-
andThen
、再帰的な走査中にこのコンテキストを渡すことができます。 また、
Match
状態に参加する簡単な方法も提供します。
Repeat
処理に関しては、問題があります。
andThen
自体は分割演算子です。 この問題に対処するために、後でバインドできるようにするプレースホルダーを導入します。 次のクラスでプレースホルダーを表します。
class Placeholder(var pointingTo: State) extends State
Placeholder
var
は、
pointingTo
可変であることを意味します。 これは可変性の孤立した部分であり、循環グラフを簡単に作成できます。 他のすべてのメンバーは変更されていません。
そもそも、
Match()
です。 これは、正規表現に対応するステートマシンを作成することを意味します。このステートマシンは、受信データを消費することなく
Match
状態に移行できます。 コードは短くなりますが、リッチになります。
object NFA { def regexToNFA(regex: RegexExpr): State = regexToNFA(regex, Match()) private def regexToNFA(regex: RegexExpr, andThen: State): State = { regex match { case Literal(c) => new Consume(c, andThen) case Concat(first, second) => { // first NFA. "" // second NFA. regexToNFA(first, regexToNFA(second, andThen)) } case Or(l, r) => new Split( regexToNFA(l, andThen), regexToNFA(r, andThen) ) case Repeat(r) => val placeholder = new Placeholder(null) val split = new Split( // , // - r regexToNFA(r, placeholder), andThen ) placeholder.pointingTo = split placeholder case Plus(r) => regexToNFA(Concat(r, Repeat(r)), andThen) } } }
そしてそれだけです! この部分のコード行に対する文の比率は非常に高く、各行は多くの情報をエンコードしますが、すべては前の部分で説明した変換に帰着します。 説明する価値があります-私はただ座ってこの形式でコードを書き留めたのではありません。 コードの簡潔さと機能性は、データ構造とアルゴリズムの操作を数回繰り返した結果でした。 純粋なコードを書くのは難しいです。
デバッグプロセス中に、NFAから
dot
ファイルを生成する短いスクリプトを作成して、デバッグ用に生成されたNFAを表示できるようにしました。 このコードによって生成されたNFAには、多くの不必要な遷移と状態が含まれていることに注意してください。 記事を書くときは、パフォーマンスを犠牲にしても、コードをできるだけシンプルにするようにしました。 単純な正規表現の例を次に示します。
(..)*
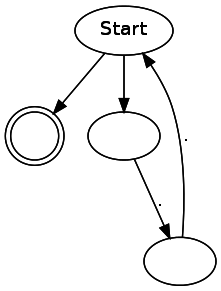
ab

a|b
NFA(最も難しい部分)ができたので、それを分析する必要があります(その部分は簡単です)。
パート3:NFA分析
NFA、DFA、および正規表現
第2部では、確定的と非確定的の2種類の有限状態マシンがあると述べました。 主な違いが1つあります。非決定性有限状態マシンは、1つのトークンに対して1つのノードへの複数のパスを持つことができます。 さらに、入力を受け取らずにパスをたどることができます。 表現力(「パワー」と呼ばれることが多い)の点では、NFA、DFA、および正規表現は似ています。 これは、NFAを使用してルールまたはパターン(偶数長の文字列など)を表現できる場合、DFAまたは正規表現を通じて表現することもできることを意味します。 最初に、DFAとして表される正規表現
abc*
見てみましょう。
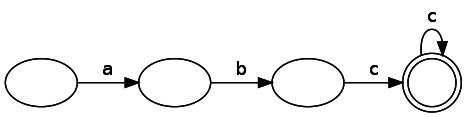
DFA分析は簡単です-入力データの文字列を消費することで、状態から状態に移動するだけです。 一致した状態で入力の消費を終了した場合、一致がありますが、そうでない場合は一致しません。 一方、ステートマシンはNFAです。 この正規表現のコードによって生成されたNFAは次のとおりです。
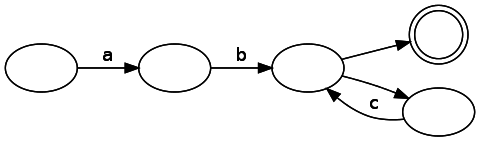
シンボルを消費せずに渡すことができるラベルのないエッジがいくつかあることに注意してください。 それらを効果的に追跡する方法は? 答えは驚くほど簡単です。可能な状態を1つだけ追跡するのではなく、エンジンが現在存在する状態のリストを保存する必要があります。 分岐が発生した場合、両方のパスに従う必要があります(1つの状態を2つに変える)。 状態に現在の入力に対する有効な遷移がない場合、リストから削除されます。
ここで、2つの微妙な点を考慮する必要があります。グラフ内の無限ループの回避と、入力データのない遷移の正しい処理です。与えられた状態を分析するとき、入力データをさらに消費しない場合、まずすべての状態に移動して、現在の状態から到達可能なすべての可能な状態をリストします。この段階では、グラフの無限ループを回避するために、注意して「多くの訪問」を維持する必要があります。これらのすべての状態を列挙したら、入力データの次のトークンを消費します。これらの状態に行くか、リストから削除します。
object NFAEvaluator { def evaluate(nfa: State, input: String): Boolean = evaluate(Set(nfa), input) def evaluate(nfas: Set[State], input: String): Boolean = { input match { case "" => evaluateStates(nfas, None).exists(_ == Match()) case string => evaluate( evaluateStates(nfas, input.headOption), string.tail ) } } def evaluateStates(nfas: Set[State], input: Option[Char]): Set[State] = { val visitedStates = mutable.Set[State]() nfas.flatMap { state => evaluateState(state, input, visitedStates) } } def evaluateState(currentState: State, input: Option[Char], visitedStates: mutable.Set[State]): Set[State] = { if (visitedStates contains currentState) { Set() } else { visitedStates.add(currentState) currentState match { case placeholder: Placeholder => evaluateState( placeholder.pointingTo, input, visitedStates ) case consume: Consume => if (Some(consume.c) == input || consume.c == '.') { Set(consume.out) } else { Set() } case s: Split => evaluateState(s.out1, input, visitedStates) ++ evaluateState(s.out2, input, visitedStates) case m: Match => if (input.isDefined) Set() else Set(Match()) } } } }
そしてそれだけです!
取引を完了する
すべての重要なコードは完了しましたが、APIは望んでいるほどきれいではありません。ここで、正規表現エンジンを呼び出す単一呼び出しユーザーインターフェイスを作成する必要があります。また、ライン上の任意の場所でパターンを一致させる機能を追加し、構文シュガーを共有します。
object Regex { def fullMatch(input: String, pattern: String) = { val parsed = RegexParser(pattern).getOrElse( throw new RuntimeException("Failed to parse regex") ) val nfa = NFA.regexToNFA(parsed) NFAEvaluator.evaluate(nfa, input) } def matchAnywhere(input: String, pattern: String) = fullMatch(input, ".*" + pattern + ".*") }
そして、使用されるコードは次のとおりです。
Regex.fullMatch("aaaaab", "a*b") // True Regex.fullMatch("aaaabc", "a*b") // False Regex.matchAnywhere("abcde", "cde") // True
そして、私たちはそこで終わります。これで、わずか106行で部分的に機能する正規表現の実装ができました。さらに詳細を追加できますが、コードの価値を高めることなく複雑さを増やさないことにしました。
- キャラクタークラス
- 値の取得
-
?
- エスケープ文字
- そして、はるかに。
この単純な実装が正規表現エンジンの内部で何が起こっているのかを理解するのに役立つことを願っています!通訳のパフォーマンスは嫌で、本当にひどいことを言及する価値があります。おそらく、今後の投稿の1つで、この理由を分析し、最適化する方法について説明します...