アンケートマーケティング調査では、回答者が可能な回答のリストからいくつかの適切なオプションを選択できる質問があります(質問に当てはまるものすべてをチェックします)。 このような質問への回答者は、複数回答のある変数(複数回答変数)によって尋ねられます。 多重応答変数を操作するための適切な統計的方法は広く知られていません。 この記事では、例として自動車の定格に関するデータを使用して、このような変数の分析を検討します。
データ
これは、いくつかの回答が可能なアンケートの質問の典型的な例です。
顧客満足度調査テンプレート。 出典: Survey Monkey
この記事では、自動車の評価データを使用します(Van Gysel 2011)。 これらはフリーウェアであり、 plfm Rパッケージに含まれています。 これらのデータは、数学的手法と視覚化ツールを示すためのオブジェクトとしてのみ使用する必要があります。 結果がグループの完全な代表的調査に基づいていると仮定しないでください。
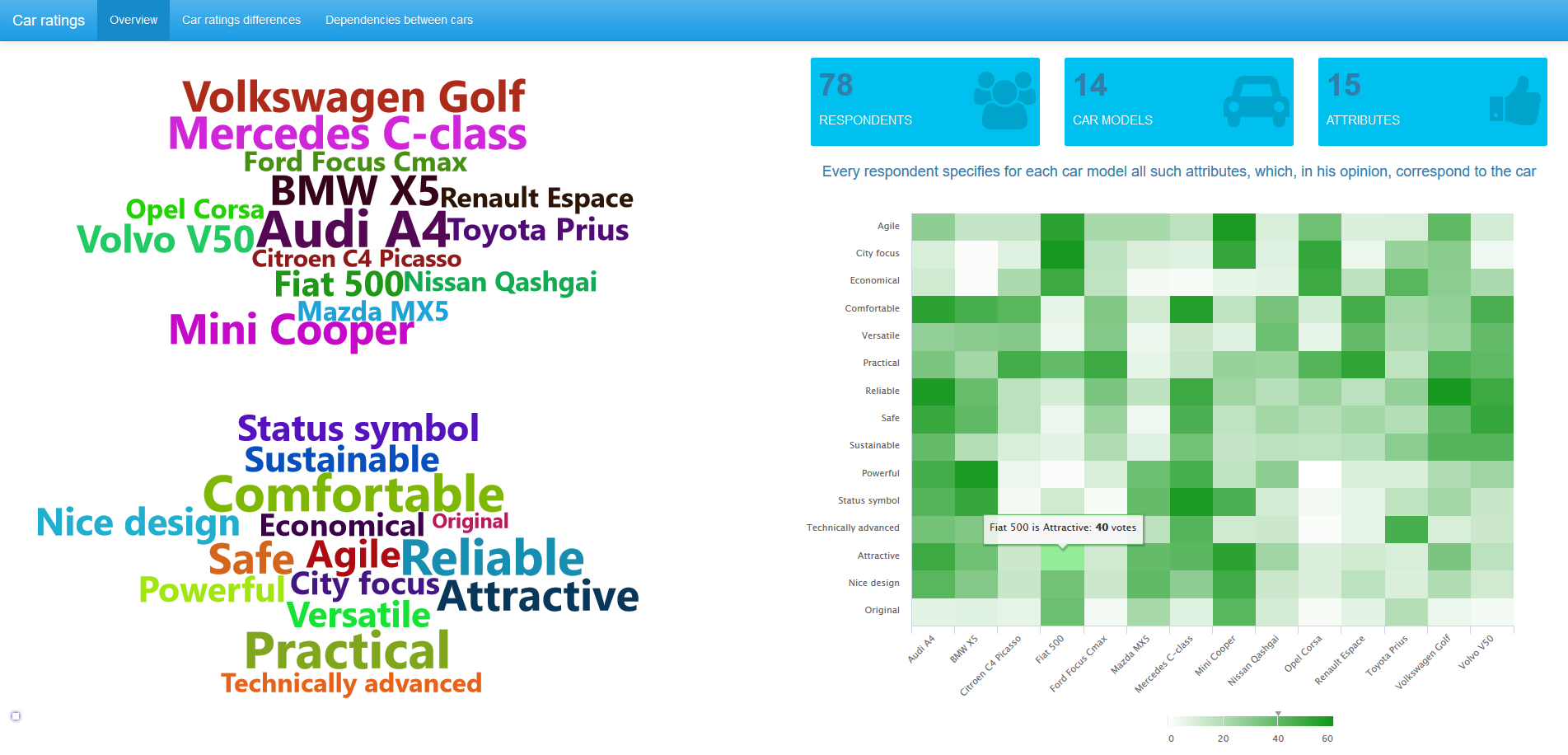
データの概要はヘッダー画像に表示され、クリックするとすべての画像がフルサイズで開きます。 78人の回答者が調査に参加したことがわかります。 この調査アンケートでは、14の自動車ブランドに関する意見が明らかになりました。 それぞれについて、回答者は、車が対応する特性(提案された15の名前のリストから)を書き留めました。 上の写真は、40人の回答者がフィアット500は魅力的な車だと考えていることを示しています。
評価の比較
2台の車の特性の評価を比較するために、よく知られているMcNemarテスト、より正確にはMcNemar mid-pテストのバリエーションが使用されます。 このテストは、ペアの観測を分析します。 mid-p補正により、小さなサンプルを扱うことができ、正確な二項検定よりも保守的ではありません。 詳細については、たとえばこの記事(Fagerland、Lydersen、およびLaake 2013)を参照してください。
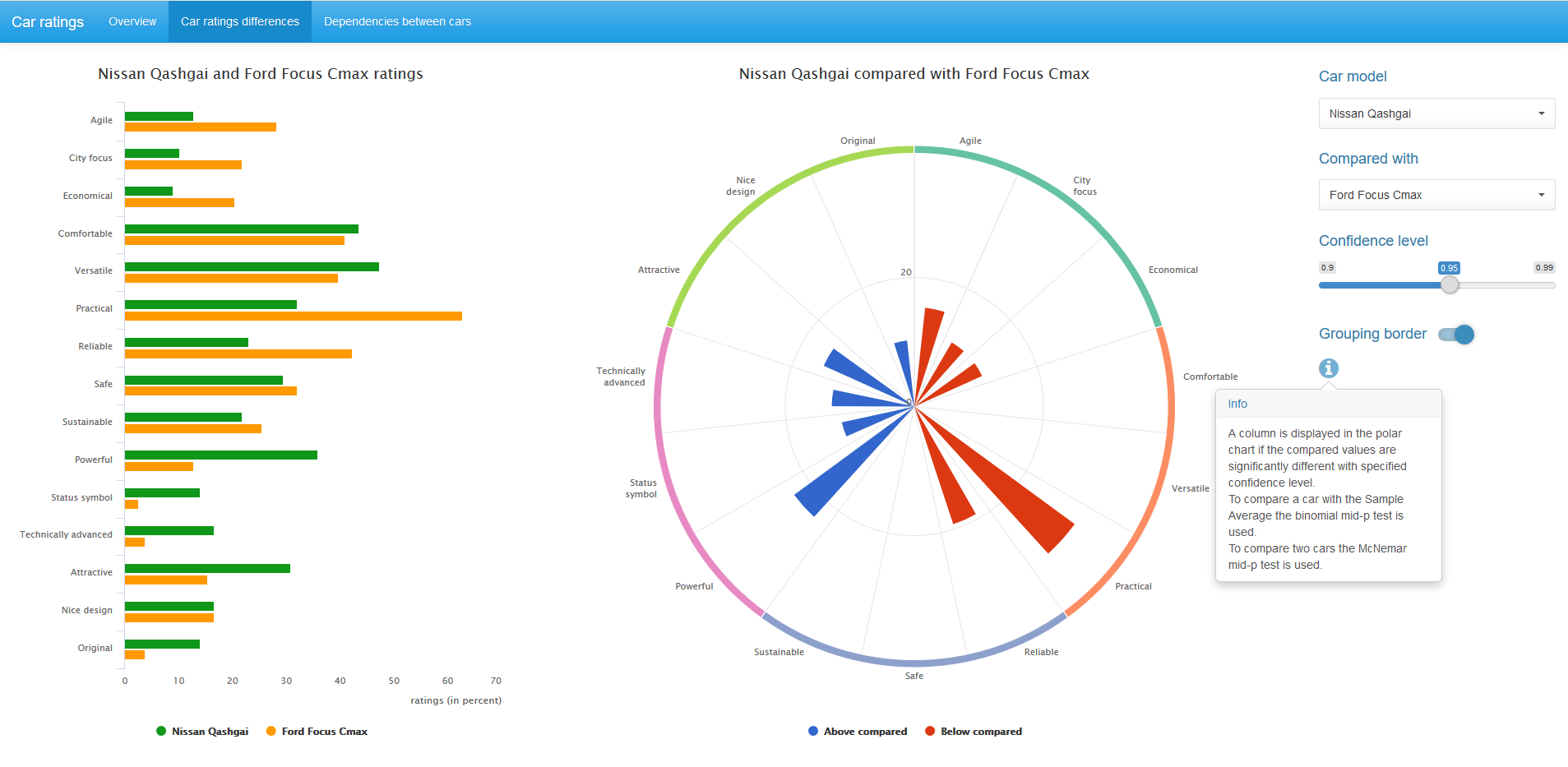
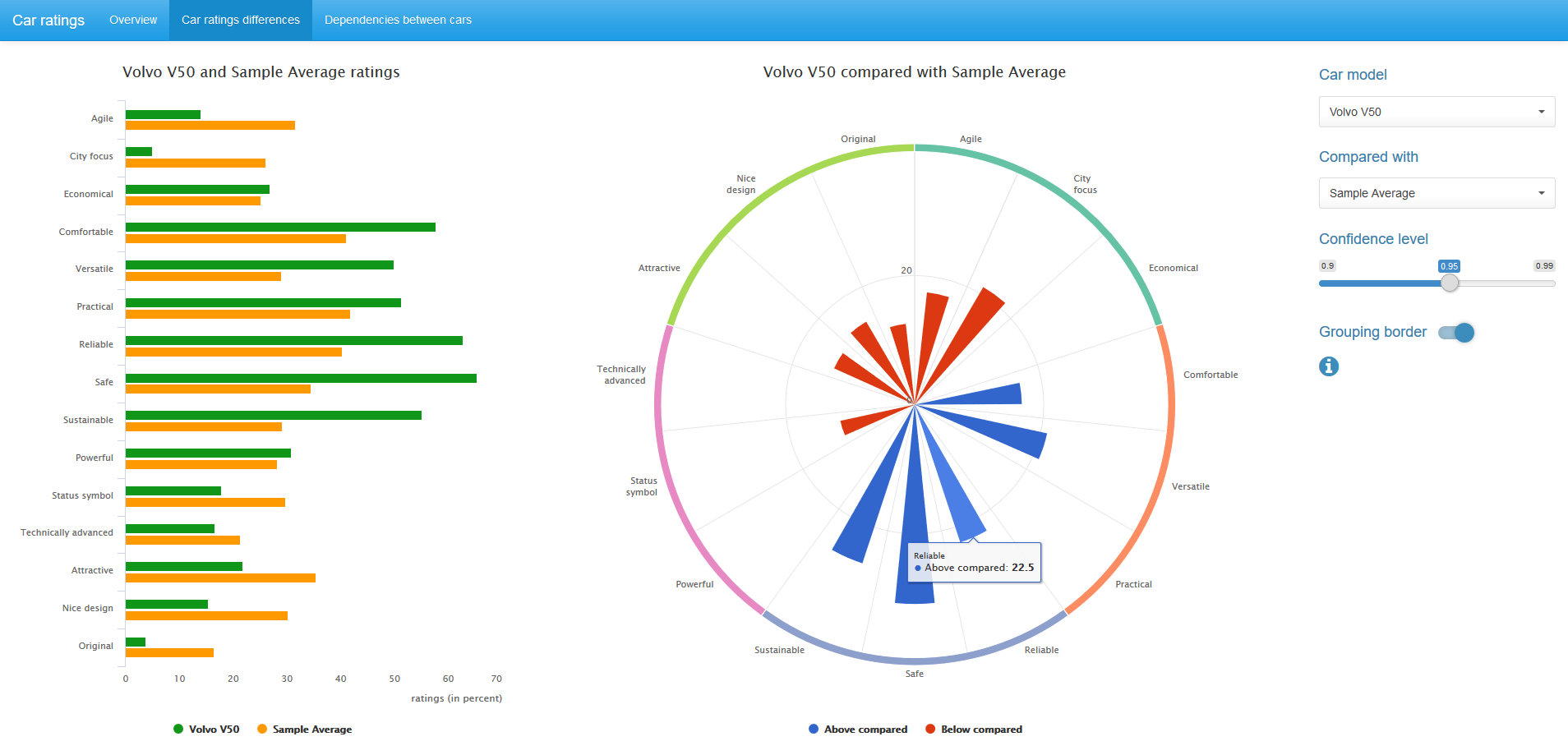
中央のチャートでは、統計的に有意なだけで、与えられた信頼レベルに対して、比較された車のペア間の格付けの違いが表示されます。 青色は最初の車の高い評価値に対応し、赤色は2番目の車の評価値に対応します。
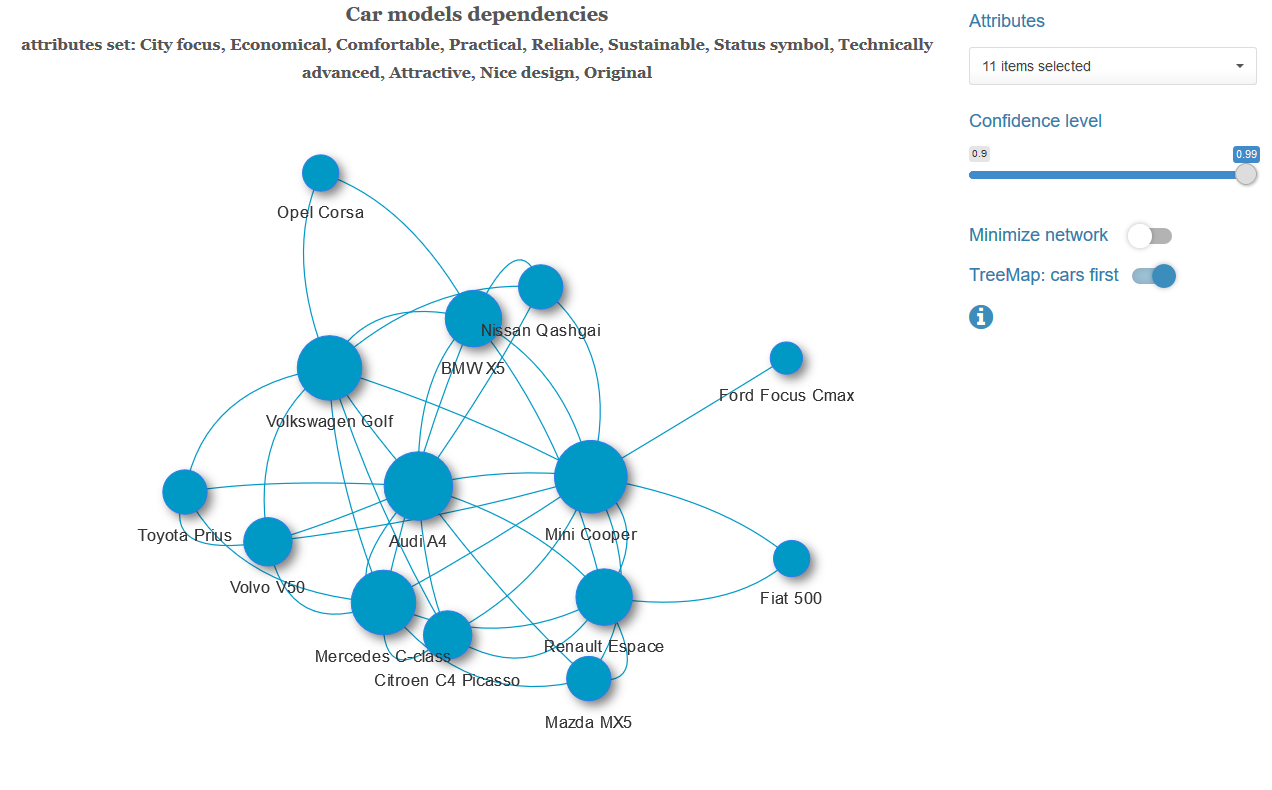
信頼レベルの値を変更し、必要に応じて、図のグループ化境界線を削除できます。
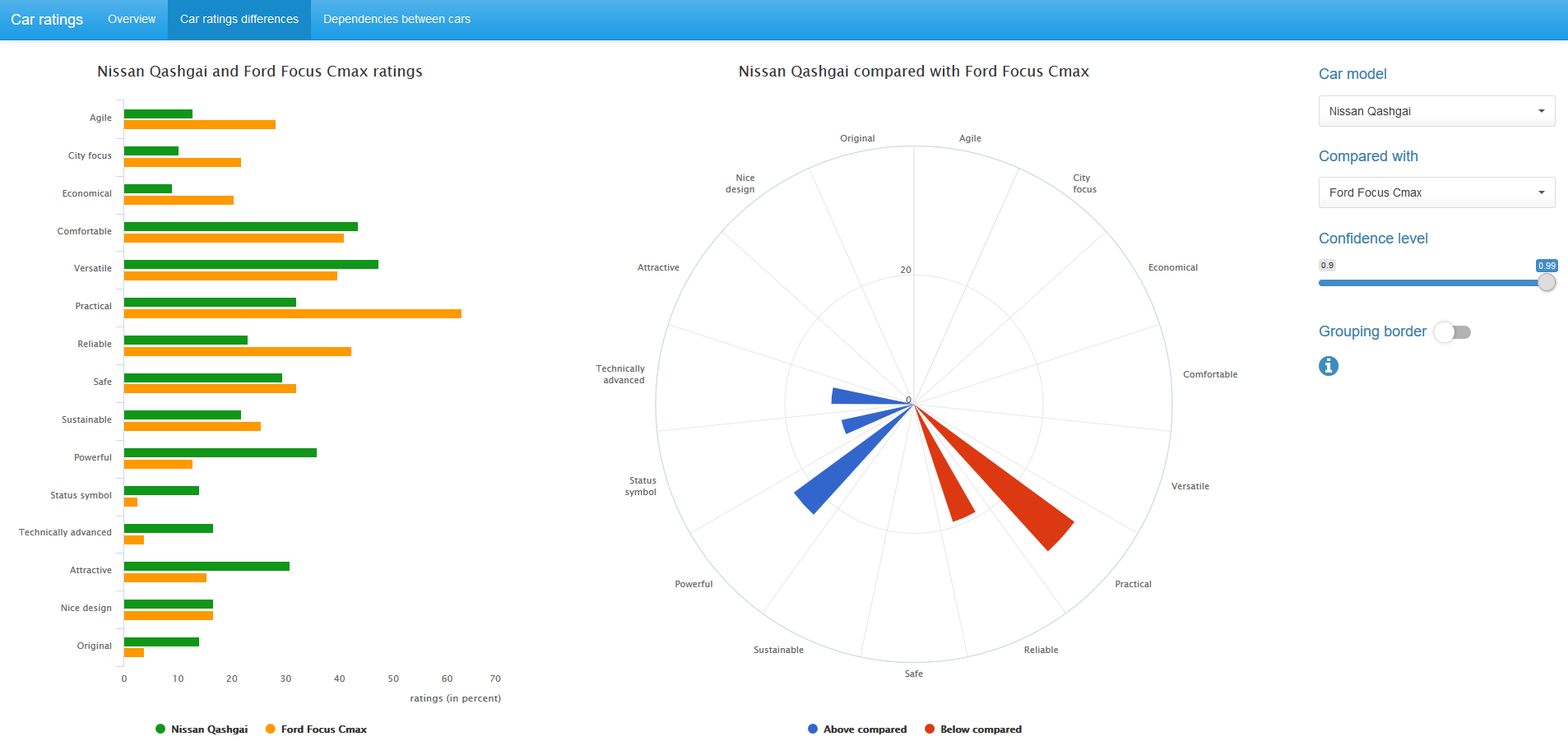
また、車の評価を14台すべての車の平均選択評価と比較することもできます。 この場合、二項mid-p検定が使用されます。
McNemar mid-pテストとbinomial mid-pテストは両方ともexact2x2 Rパッケージで利用できますが、基本的なR
ツールを使用して簡単に実装できます。
2つの多重応答変数間の依存関係
タスクは次のとおりです。任意の特性セットと任意の車モデルのペアを選択しました。 これらの車に対する回答者の回答の分布は独立していると述べることは可能ですか? つまり、特定の特性セットでこれら2つのブランドの格付けに統計的な関係があると信じる理由はありません。
たとえば、8x8のテーブルを考えてみましょう。
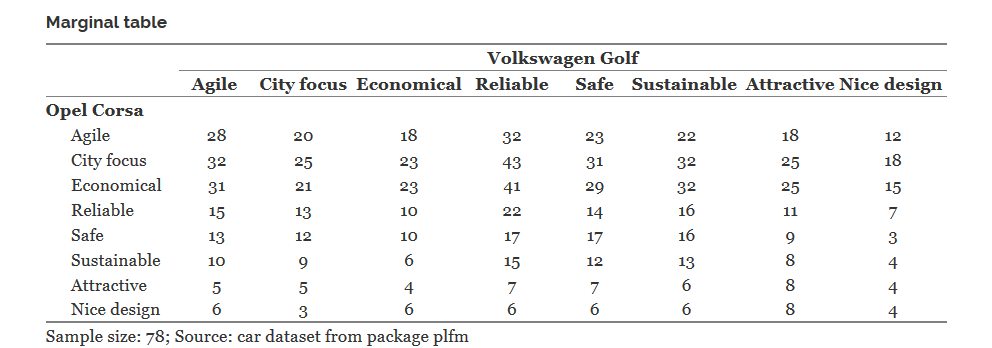
その中にセルの意味があります、とオペル・コルサは言います| 経済的-フォルクスワーゲンゴルフ| 41に相当するRelibleは、正確に41の回答者がオペルコルサは経済的な車であり、フォルクスワーゲンゴルフは信頼できると示していることを意味します。
Opel CorsaとVolkswagen Golfの両方が単一応答変数である場合、この表はこれらの変数の共同分布を指定します。 次に、このテーブルにカイ2乗基準を適用して、この変数ペアの独立性を検証できます。 しかし、我々は完全に異なる事例を持ち、この表によれば、例えば、オペルコルサが経済的な車であると信じている回答者の数さえ明らかではありません。
この限界表の各セルの背後には、選択された特性の個別のペアの分布を決定する2x2の表があります。 マージナルテーブルの対角セルのこれらの8つのテーブルは、この車のペアのMcNemarテストで使用されました。
しかし、この64個すべてのテーブルのセットは、それぞれ8つのカテゴリを持つ2つの多重応答変数の共同分布を指定するには不十分です。 一般に、これにはサイズのテーブルが必要になります 。 したがって、2x2テーブルで見つかった64個のカイ2乗統計量の合計は、入力の観測値(変数ではない)の依存性のため、値ではありません 配布。 テーブルからの情報 2次のRao-Scott補正を見つけ、これらの64のカイ2乗値の合計に適用することができます。 独立基準の詳細と表現は、記事(Bilder and Loughin 2004)に記載されています。
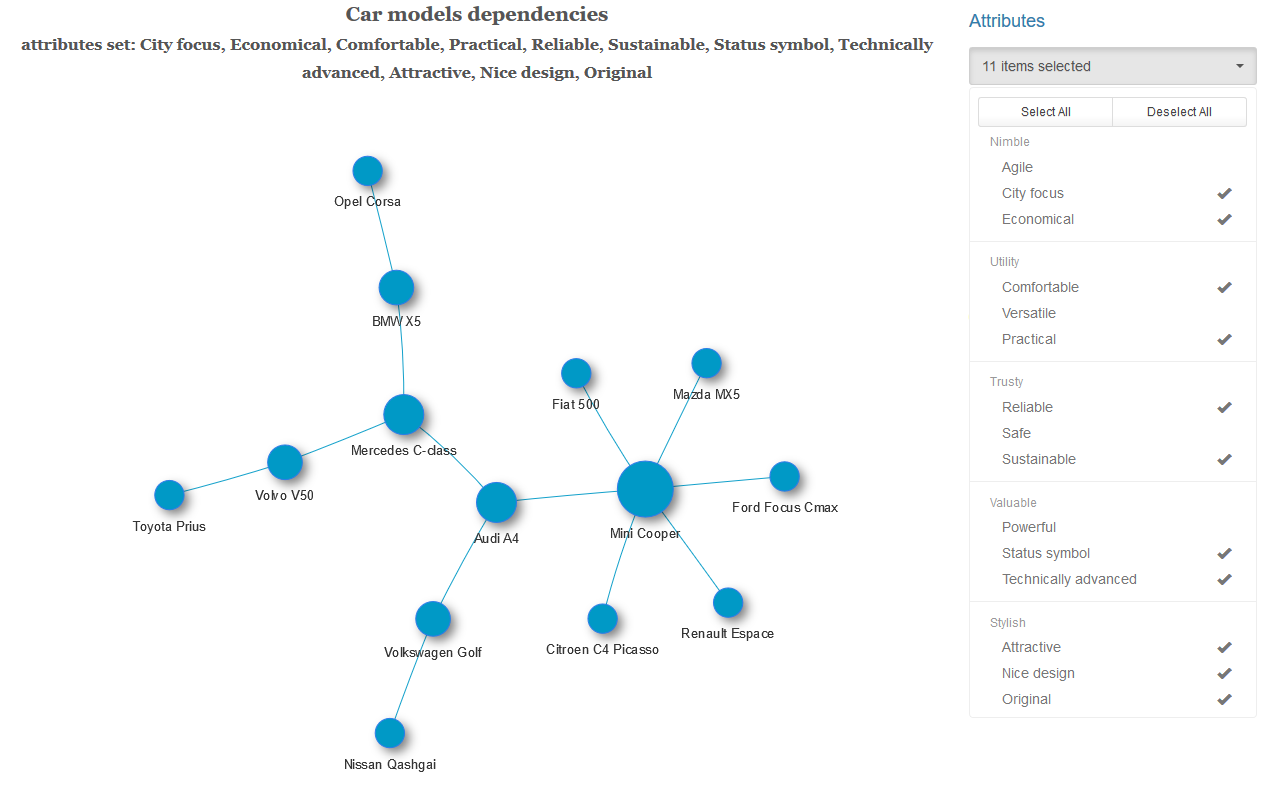
与えられた一連の特性を持ち、選択した有意水準の車のペアごとに、これらの変数の独立性の仮説をテストします。 独立仮説が棄却された場合、このペアの車を、得られたラオ・スコット統計のp値に等しい重みを持つエッジに接続します。 重み付きグラフを取得し、オプションで、グラフの接続された各コンポーネントの最小スパニングツリーを見つけるアルゴリズムを適用します。 つまり、最強の債券の最小数を残します。
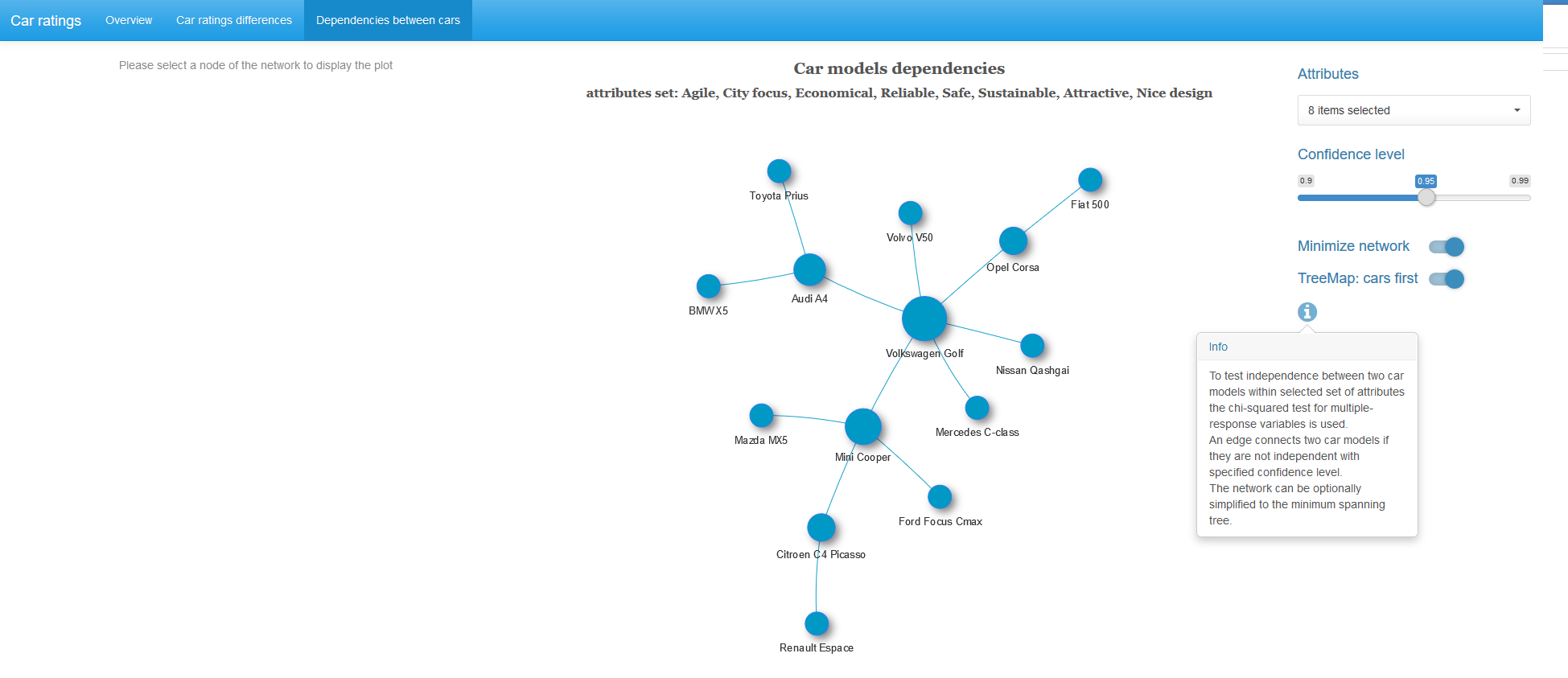
画像をクリックすると、フルサイズで開きます。
得られたグラフのほぼ半分の車がフォルクスワーゲンゴルフに最も強く依存しています。
グラフの頂点を選択すると、さらに、隣接する頂点の特性のペアを含む2x2テーブルのカイ二乗統計のツリーマップが表示されます。
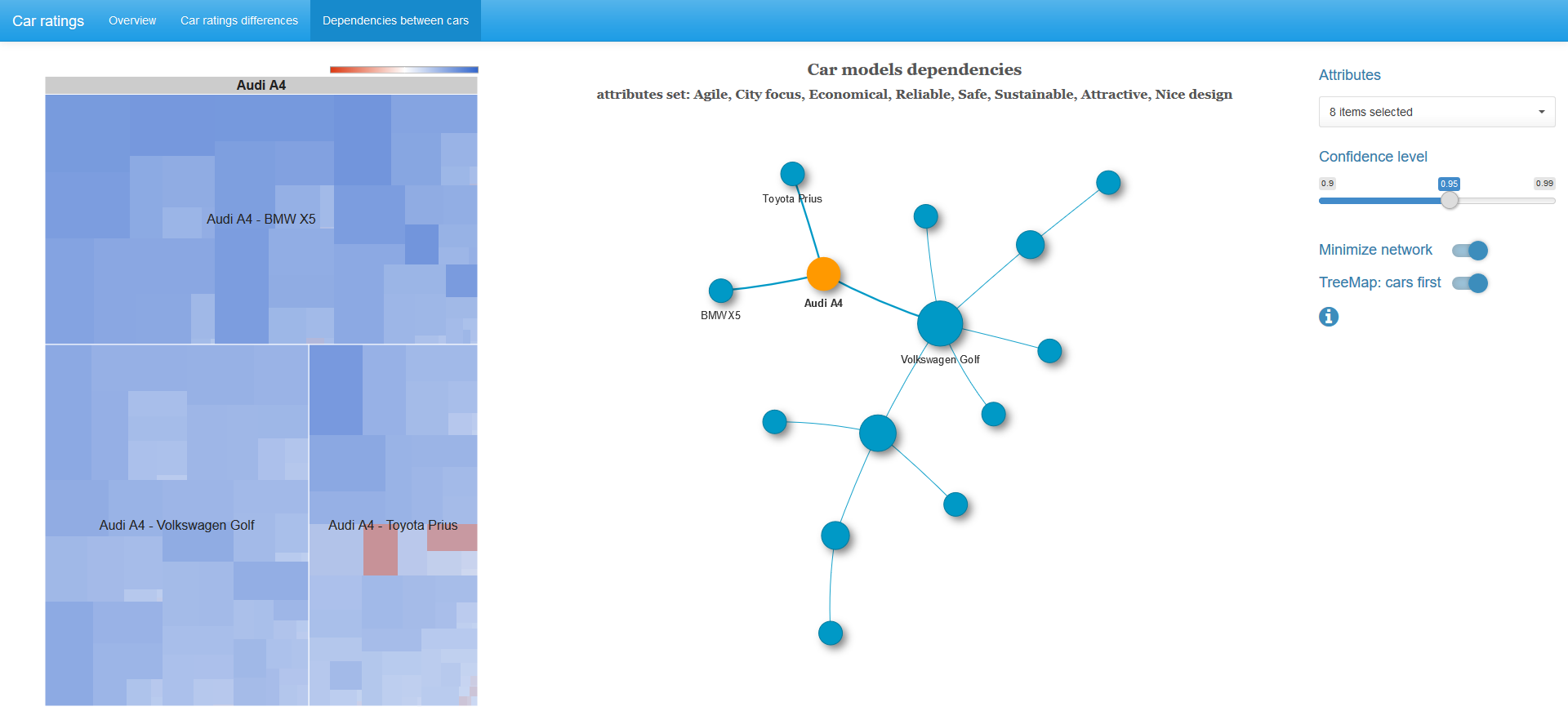
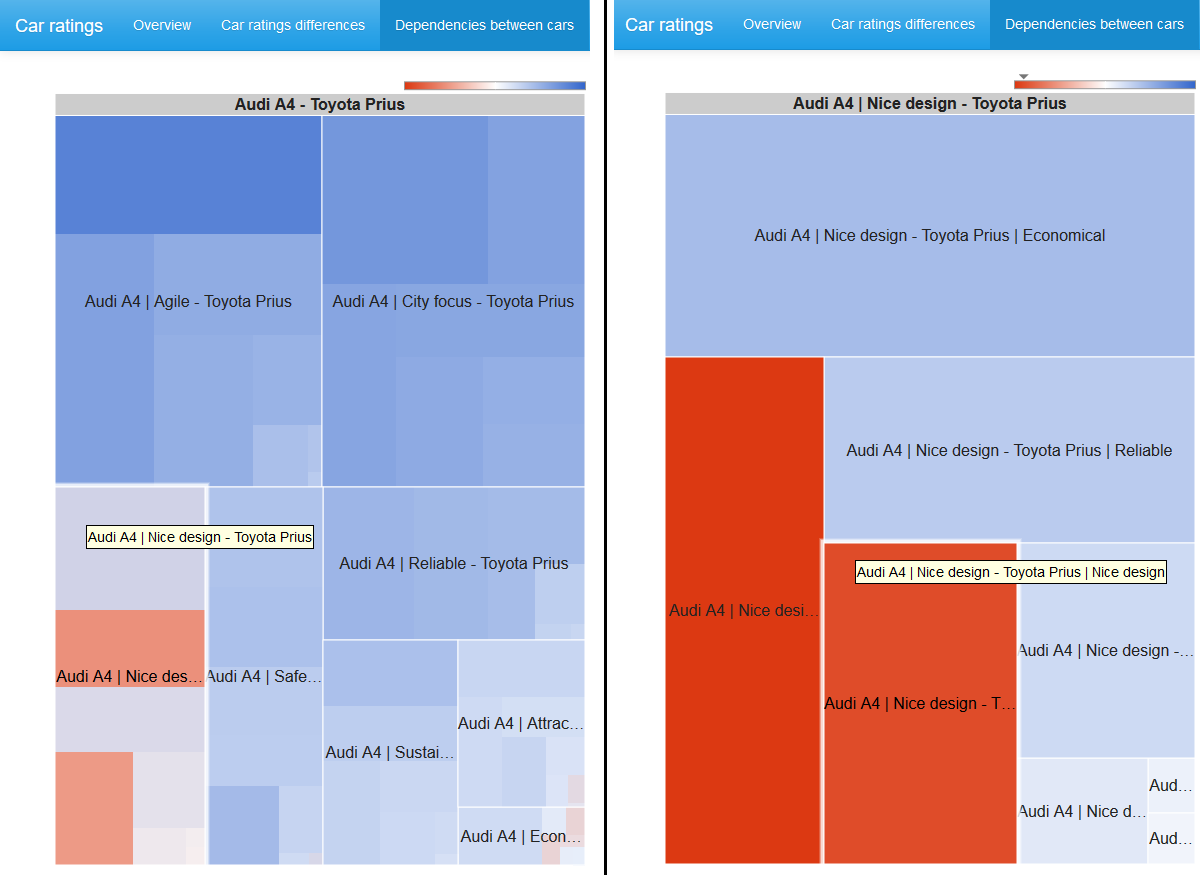
セルのサイズはカイ2乗統計量の値に比例し、色はオッズ比の対数によって決まります。青のスペクトル-正の値、白のカラー-ゼロ、赤のスペクトル-負の値。 カラースケールは対称ではありません。つまり、絶対値の左側の境界線は、スケールの右側の境界線と必ずしも一致しません。
以下は、異なる特性のセットを持つ最小スパニングツリーと完全なリンクのセットを持つグラフの例です。
アプリケーションの計算と実行
(Bilder and Loughin 2004)で提案されているアプローチは、 MRCV Rパッケージに実装されています。 ただし、上記の8x8のマージナルテーブルの場合、このライブラリのこれらの変数の独立性チェック関数はエラーを返します。 サイズ32.0 Gbのベクトルを割り当てることができません 。 その理由は、計算の過程で順序行列が生じるためです 。
R
でのこのテストの実装では、このような大量のメモリを必要とせず、はるかに生産的なアプローチが提案されました。 比較のために、 MRCV
パッケージで14個の頂点と7個の特性を持つ完全なグラフを計算するには、30分以上かかります。 改善された実装では、この計算には約1秒かかります。 このpdfには、この計算方法の詳細が記載されています。 ソースコードとパフォーマンステストはgithubで入手できます。
Rコマンドで実行することにより、この光沢のあるアプリケーションを個別に起動できます。
library(shiny) runGitHub("BrandsAnalysis", "e-chankov")
インストールされていることを確認してください
#### shiny libraries library(shiny) # version 1.0.5 library(shinythemes) # version 1.1.1 library(shinydashboard) # version 0.6.1 library(shinyBS) # version 0.61 library(shinyWidgets) # version 0.3.6 #### libraries for visualization library(wordcloud2) # version 0.2.0 library(highcharter) # version 0.5.0 library(googleVis) # version 0.6.2 library(visNetwork) # version 2.0.1 library(RColorBrewer) # version 1.1-2 #### data munging libraries library(data.table) # version 1.10.4 library(checkmate) # version 1.8.4 library(Matrix) # version 1.2-11 library(igraph) # version 1.1.2 library(stringi) # version 1.1.5
入力データはテキストファイルから読み取られます。 このアプリケーションを使用して、独自の特性を持つブランドの調査データを分析できます。 入力要件は、アプリケーションの説明に記載されています。
文学
Bilder、C。、およびT. Loughin。 2004.「多重応答を伴う2つのカテゴリ変数間の限界独立性のテスト。」バイオメトリクス60(1):241–48。 http://dx.doi.org/10.1111/j.0006-341X.2004.00147.x
Fagerland、Morten W.、Stian Lydersen、Petter Laake。 2013.「バイナリマッチドペアデータのマクネマーテスト:Mid-Pおよび漸近線は、厳密な条件付きよりも優れています。」BMC Medical Research Methodology 13(1):91。 https://doi.org/10.1186/1471-2288-13-91
Van Gysel、E。2011。「自動モデル化されたモデルの確率モデルを分析しました。」
修士論文、Hogeschool-Universiteit Brussel。