こんにちは 土曜日とAvito Data Science Meetup:Computer Visionを待っている間に、 KONICA MINOLTA Pathological Image Segmentation Challengeの機械学習コンテストへの参加についてお話しします。 私はこれに数日しか費やしていませんでしたが、2位になったことは幸運でした。 解決策の説明と切り分けられた探偵小説。

タスクの説明
顕微鏡の画像の領域を分割するアルゴリズムを開発する必要がありました。 どうやら、これらは上皮の癌細胞のいくつかの病巣でした。 下の写真-与えられたものとその方法:
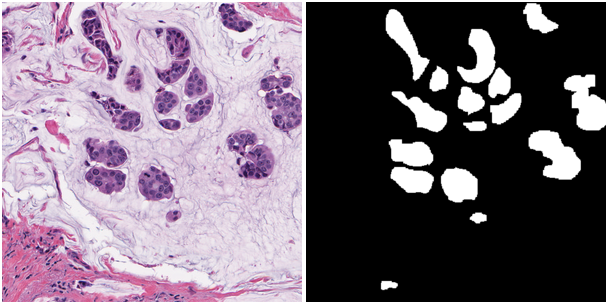
トレーニングおよびテストサンプルは、それぞれ168および162個のこのような画像で構成され、サイズは500x500ピクセルです。 ターゲットメトリックは、F1-microとインスタンスごとのDice x 1,000,000の算術平均です。
サイトについての印象を持つ叙情的な余談
コンテストはTopcoder Webサイトで開催されました。 おそらく、このサイトは機械学習やニューラルネットワークよりも読者にとってオリンピアードプログラミングを連想させるものでしょう。 しかし、どうやら男たちもトレンドに参加することにした。 データの準備という点だけでなく(以下で詳しく説明する)、ユーザビリティの面でも疑わしいことがわかりました。 ソリューションを提出するには、以下を行う必要があります。
- 列車を予測し(!)、テストします。
- txtでマスクを追い越し、それらを転置することを忘れないでください。
- マスクをアーカイブにパックし、gdrive / dropbox /などにアップロードします。
- コンテストの提出システムに入り、アーカイブリンクを取得するJavaクラスを記述します。
提出物は2時間ごとに送信できます。 15分ごとに1回、列車のチェックが可能です。 したがって、ある時点で何かがおかしくなった場合、2時間歩きます。 アーカイブ内のファイルをルートではなくフォルダにアップロードしました。残念です。マスクが見つかりませんでした。確認してください。2時間あります。 私は電車の仮面を完成させるのを忘れていました-2時間後、よく見てください。 そのようなシステムと混同して、すでに送信したソリューションを送信するのは簡単だと言っているのではありません。 まあ、朝の1時にようやく次の機能強化を終えてアーカイブを収集して間違えたときはとてもクールです。眠らないか、朝まで待つかのどちらかです。
また、提出物のいくつかを最終的なものとして選択するオプションもありませんでした。 最後に送信する必要がありました。 もちろん、間違いはありません。 今後は、中国のプラットフォームchallenger.aiが粘り強さでトップコーダーを上回ったと言わなければなりませんが、次回はそれについてさらに詳しく説明します。
最初の反復
私は長い間、参加したくなかったと言わなければなりません。なぜなら、これもまたセグメンテーションであり、サイトが奇妙だからです。 しかし、 ウラジミール・イグロビコフとエフゲニー・ニジビツキーは私に参加を促しました。
いつものように、ベースラインから始めることにしました。 彼のために、私はZFTurboコードを選択しました。彼は、 衛星を使ってkaggle'aの後にコーミングしてレイアウトしました。 トレーニング用のモデルとコードの例はすでにありました。 私はそれを5つに分けて補いました。 電車のすべてのマスクをエリアでソートし、分割するたびにエリアの分布が同じになるように分割して作成しました。 私は折り目を階層化することを望んでいた、私はどれだけ間違っていた...
拡張から、私は標準的なターン、クロップ、リサイズを残しました。 オプティマイザーとしてAdamを選びました。
2回目の反復
モデルが訓練されている間、私はベースラインを改善することに決め、写真を注意深く見ることから始めました。 まず、数学を使って、電車内のショット数を6で割ることに気づいたので、5倍ではなく6倍にしたほうが良いと思いました。折り目の一部を1つの巨大なマスクにします。 そして、ニューラルネットワークの入力の1.5倍以上のランダムなパッチをそこから引き出しました。 imgaugライブラリを使用して、より積極的な拡張を適用しました。
imgaugはskimageを使用していると言っておく価値があります。skimageはpythonで記述されているため、それほど高速ではありません。 この欠点を克服するために、pytorchのdataloaderを使用しました。 それは素晴らしいです。xとy(この場合は画像とマスク)を準備するget_sample関数を本質的に1つ記述する必要があり、イテレータ自体がバッファを使用して複数のストリームでバッチを収集します。 とてもクールなので、kerasやmxnetでも使用できます。 これを行うには、バッチのテンソルを切り取り、numpyで追い越します。
また、2回目の反復で、学習戦略を変更しました。 最初にアダムに低い学習率で教えてからSGDに切り替え、最後にブルーとシャープに関連する画像を増やさずにSGDでトレーニングしました。
さらに、並行して、異なる損失関数を持つ3つのトレーニングを開始しました:バイナリクロスエントロピー(BCE)、BCE-ログ(ジャカード)、BCE-ログ(サイコロ)。

3回目の反復
3回目の実行で、私はU-netアーキテクチャをやめ、他のニューラルネットワークに恋をし、生活を始める時だと判断しました。 レビューの画像を注意深く研究し、 Global Convolutional Networkを選択しました。 大きなカーネル、因数分解された畳み込み、境界を指定するブロック、写真の中のガチョウ...「Easygold!」と思いました。 しかし、2、3晩、このアーキテクチャで適切な結果を得ることはできませんでした。時間は過ぎ、すべての実験はkaggle Carvanaに移りました。
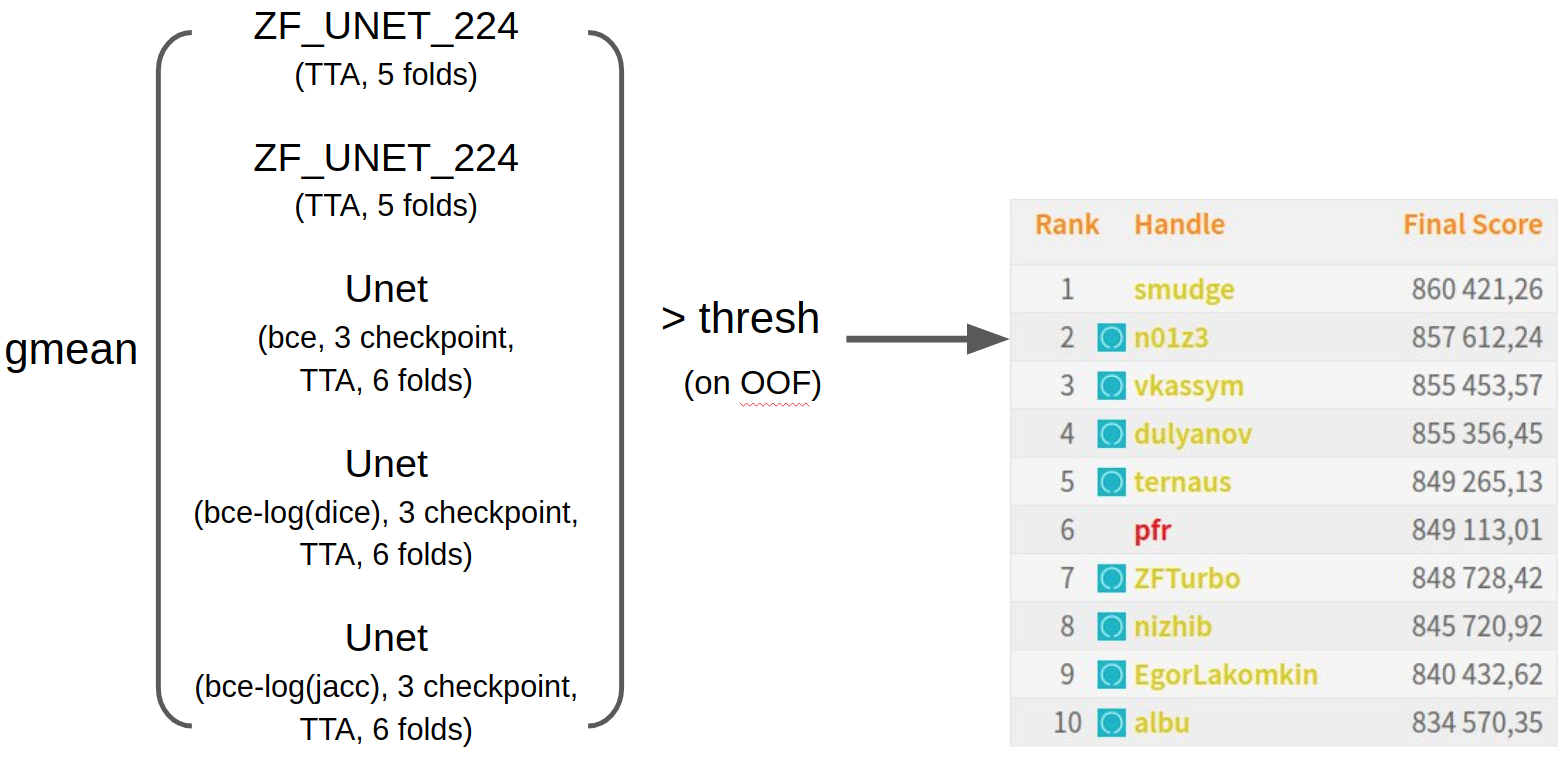
最終アンサンブル
その結果、その瞬間に訓練されたすべてのニューラルネットワークを幾何平均と単純に混合しました。 OOF予測のしきい値を選択し、締め切りの数時間前に送信しました。 公の場では11位だったので、自分が2位になったことに非常に驚いた。 私の意見では、私は非常に幸運でした。なぜなら、データには1つのグローバルな妨害がありました。 青いアイコンは、ODS.aiコミュニティの参加者を示します。 襲撃が成功したことがわかります。 チャットの成功をフォローするには、 Twitterに登録できます
エフゲニー・ニジビツキーの刑事履歴書調査
大多数の競技会では、いくつかの品質モデルから始めて、ローカル検証とリーダーボードが一致しなくなります。 そして、この能力も例外ではありません。 ただし、その理由は、単なる異種パーティションよりもはるかに興味深いことが判明しました。
このコンペティションでは、 スペースコンペティションのKaggle Amazonとの類推により、ユージーンニジビツキーは写真を切り取った元のモザイクを組み立てることに決めました。
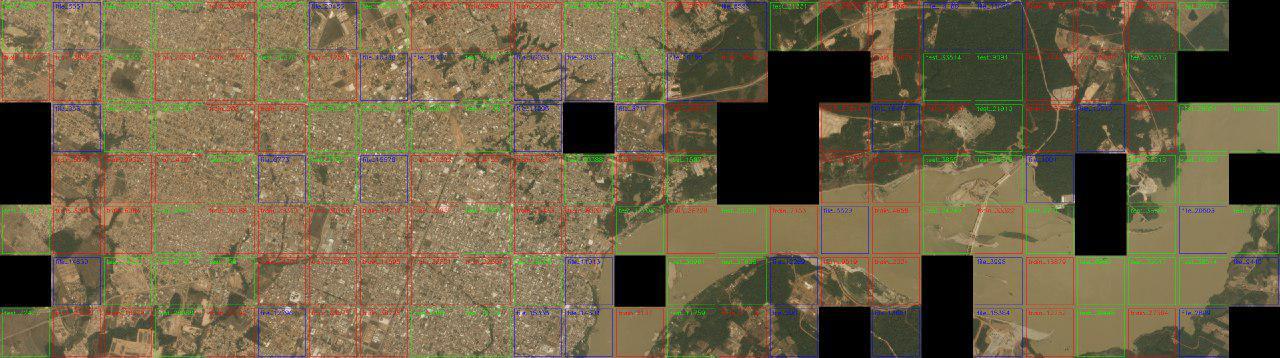
可能なすべての画像について、境界のペア間のL2距離に基づいて近隣が検索されました。 しきい値との比較に基づいて、各画像の近傍とそれらの距離が示されたテーブルが作成されました。 毎回、発見されたペアは目で検証され、正しいものと間違ったものの両方が別々に記憶されました。 その後、しきい値がわずかに増加し、検索が再度実行されました。
モザイクの結果は、データ構造の理解でした-トレーニングサンプルは、42個の正方形1000x1000で構成され、各正方形は4つの小さな正方形にカットされています。 正方形へのテストサンプルは完全に「壊れた」わけではありませんが、162個のテストイメージのうち120個が30個の2x2正方形に結合されています。
この実験から、残念な結論を導き出すことができます-固定のランダムな分割による交差検証は、各固定2x2正方形の6倍で、約50%の確率でその部分が列車と検証の両方に落ちるため、代表的ではありません。
しかし、好奇心は消えませんでした。生地の42個のタイルがモザイクにならないのはなぜですか。 誤って一致した隣接タイルのスクリーニングプロセスの1つで、誤って接着されたテストタイルとトレインタイルが実際に境界に沿ってマージされなかったことが発見されましたが、ターン後、それらはサブリージョン全体で再生されます!
SURF標識のマッチングを使用した小さな概念実証により、一部のテスト画像が実際に電車の元の大きな画像から実際に切り取られていることがわかりました。

テストのすべての写真から選択しようとした後、モザイクに結合しなかったテストの42枚の写真は、列車の一部に過ぎないことが判明しました。 つまり、乱交パーティーは次のことを行いました。
- 電車のオリジナル(サイズ1000x1000)の42枚の写真とテストの30枚の写真を撮りました。
- 彼らはそれらから500x500のサイズの写真を切り取った。
- テストでは十分な写真がないと判断しました(120)。
- 列車からのランダムに回されたパッチがテストすることが証明されました。
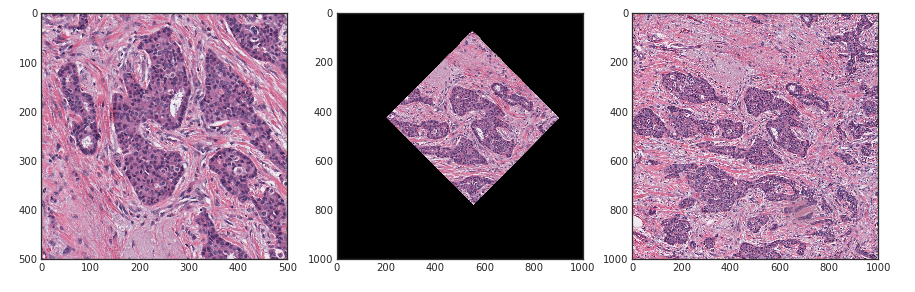
左から右への写真:テストからの1つの写真は、列車に合わせて回転します。最初の正方形は2x2列車です。
その結果、この方法でデータをクリーンアップせず、患者を分割しなかったすべての参加者(つまり、すべてのODS.ai参加者)が過剰に固定されました。 同時に、リーダーボードの改善は、次の2つの理由で発生する可能性があります。未知のデータでモデルの品質を改善することと、列車内の回転したテストで再トレーニングすることです。 また、分割には情報がなかったため、ローカルの検証とリーダーボードとの相関はありませんでした。 結局のところ、ローカルでさえ理解することは不可能でした:モデルは実際に電車で一般化またはオーバーフィットすることを学び、これにより、検証が改善されました。
YandexのMLトレーニングでこの能力について話しました。ビデオを見ることができます。 ボーナスとして、 ウラジミールのスライドをH20のmitapから見ることができます。 Evgeny Nizhibitskyは、 Avitoでのミートアップで今週の終わりに、より高度なセグメンテーションへのアプローチについても話します。 登録は既に終了していますが、イベントの当日12:30からAvitoTech youtubeチャンネルのオンラインブロードキャストに参加することができます。