SmartData 2017カンファレンスの前夜、Anna Veronika Dorogushは、勾配ブースティングに関する機械学習用の比較的若いライブラリである
SmartData 2017カンファレンスの前夜、Anna Veronika Dorogushは、勾配ブースティングに関する機械学習用の比較的若いライブラリであるCatBoost
、現状についてインタビューを行いました。 アンナは、Yandexで機械学習アルゴリズムを開発するグループの責任者です。
インタビューでは、勾配ブースティングに基づく新しい機械学習方法について説明します。 ランク付け、予測、および推奨事項の作成の問題を解決するためにYandexで開発されました。 この技術に慣れていない場合は、Habréの発表を読むことをお勧めします。
-CatBoostには、XGBoost、LightGBM、H20など、いくつかの直接的な競合相手がいます。既存の製品を使用するのではなく、独自の製品を作成するときだと理解した兆候を教えてください。
Anna :Matrixnetは上記のアルゴリズムよりも早く作成されました。さらに、ほとんどのタスクで競合他社よりも良い結果が得られました。 CatBoostは次のバージョンです。
-CatBoostの開発にはどれくらい時間がかかりましたか? 新しいアイデアをスムーズに導入したのですか、それとも1つの大きなプロジェクト「CatBoost」を計画し、それを意図的に実装したのですか? どのように見えましたか?
アンナ :当初はアンドレイ・グリンが率いるパイロットプロジェクトでした。このプロジェクトの主なタスクは、カテゴリー要因を扱う最適な方法を考え出すことでした。 結局のところ、そのような要因は自然に現れ、勾配ブースティングはそれらと連携することができませんでした。 最初、Andrei Gulinのチームは数年間プロジェクトに取り組み、膨大な数の実験と多くの仮説をテストしました。 その結果、最も効果的なアイデアがいくつかあるという結論に達しました。 Andrey GulinがCatBoostアルゴリズムの最初の実装を作成しました。現在、私たちのチームはこのアルゴリズムを開発しており、積極的な開発が進行中です。
伝記:アンドレイ・グリン 
彼はMEPhIで応用数学と物理学を学びました。 2000年以来、彼はプロとしてNival社でゲームをプレイし、同時に新しいゲームを作成しました。 2005年、彼はYandexに移り、その後検索品質の向上に取り組んできました。 MatrixNet機械学習アルゴリズムの作成と実行の背後にあるインスピレーションの1つ。
彼はMEPhIで応用数学と物理学を学びました。 2000年以来、彼はプロとしてNival社でゲームをプレイし、同時に新しいゲームを作成しました。 2005年、彼はYandexに移り、その後検索品質の向上に取り組んできました。 MatrixNet機械学習アルゴリズムの作成と実行の背後にあるインスピレーションの1つ。
-ベンチマークによると、生産性は0.12%から18%に向上しています。 それは本当に重要ですか? 勾配ブーストライブラリはどのアプリケーションアーキテクチャでボトルネックになりますか? 実際に機能するYandexサービスでは、このパフォーマンスの向上が最も重要な役割を果たしますか?
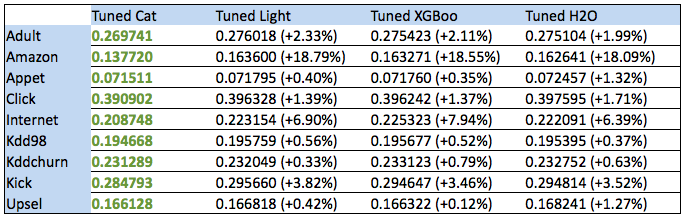
アンナ :違いの大きさはデータに大きく依存しています。 場合によっては、私たちは興味のために戦います。一部では-わずかな割合で、それはタスクに大きく依存します。
ボトルネック-アプリケーションの速度または品質の面で?
品質の場合、ボトルネックが予測の精度と品質であれば、ブースティングがボトルネックになります。 たとえば、アプリケーションが雨を予測し、そこで勾配ブースティングが使用される場合、アプリケーション予測の精度はモデルの精度に直接依存します。
速度が速い場合、モデルのトレーニングがボトルネックになる可能性があります。 ただし、ここでは、トレーニングに費やす時間を理解する必要があります。
他のモデルと同様に、速度向上の別のボトルネックが適用される場合があります。 モデルを非常に高速に適用する必要がある場合は、迅速なアプリケーションが必要です。 CatBoostは、このボトルネックをさまざまな方法で取り除くクイックアプリケーションを投稿しました。
-Amazonベンチマークでは、結果が最も印象的です。 このベンチマークは他のベンチマークとどのように違いますか?
Anna :このデータセットでは、異なるカテゴリ要因を自動的に相互に結合することが重要であることが判明しました。他のアルゴリズムはこれを行う方法を知らず、CatBoostはその方法を知っているため、非常に勝ちました。
-CatBoostとその背後にある理論の点で他のソリューションとの違いは何ですか?
Anna :このアルゴリズムには、カテゴリフィーチャのより複雑な処理、フィーチャの組み合わせを使用する機能、およびリーフの値を計算するための別のスキームがあります。
-プログラミング言語の特定の実装で使用した興味深い技術チップは何ですか? 特別な場合の動作を詳細に説明できる特別なデータ構造、アルゴリズム、またはコーディング手法がありますか?
アンナ :コードには興味深いことがたくさんあります。 たとえば、 機能の二値化コードを調べることができます。 アレクセイ・ポヤルコフによって書かれた非常に重要なダイナミクスがあります。
-CatBoostの実装中に発生した1つの大きな問題またはタスクについて教えてください。 問題は何で、どうやって出ましたか?
Anna :興味深い質問の1つは、回帰モードのカウンターのカウント方法です。 ここで、ターゲットには、効果的に使用したい多くの情報が含まれています。
彼らはこれを決めました:彼らは多くのことを試み、最高の作業方法を選択しました。 これは常に当てはまります。試してみて、最終的に最良のものを選択する必要があります。
-機械学習の世界の他のどのプロジェクトがCatBoostの統合を試みるべきですか? たとえば、Tensorflowとどのように正確に組み合わせることができますか? 実際にどの靭帯を試しましたか?
Anna :チュートリアルには、テキストを処理する必要があるカッグルのコンテストを解決するためのTensorflowとCatBoostの共同使用の例があります。 一般に、ニューラルネットワークを使用して勾配ブースティングの要因を生成することは非常に便利な方法です。Yandexでは、このアプローチは検索を含む多くのプロジェクトで使用されます。
さらに、最近TensorBoardとの統合を実装したため 、このユーティリティを使用してトレーニング中にエラーグラフを見ることができます。
-APIには、Python、R、コマンドラインの3種類があります。 近い将来、使用可能なプログラミング言語とAPIの数を増やす予定ですか?
Anna :新しい言語のサポートを自分で行う予定はありませんが、オープンソースコミュニティの人々が新しいラッパー(Githubのプロジェクトです)を実装すれば、誰でもできるようになります。
CatBoost
APIは、
Pool
、
CatBoost
、
CatBoostClassifier
、
CatBoostRegressor
に加えて、検証およびトレーニングパラメーターが説明されているいくつかのクラスのように見えます。 このAPIは拡張されますか?その場合、近い将来、どの機能を追加する予定ですか? 顧客ができるだけ早く入手したい機能はありますか?
アンナ :はい、ラッパーに新しい機能を追加する予定ですが、事前にお知らせしたくありません。
ツイッターでニュースをフォローしてください。
-CatBoostの開発を一般的にどのように見ていますか?
Anna :アルゴリズムを積極的に開発しています-新しいチップ、新しいモードを追加し、アプリケーションの加速、GPUでの分散学習とトレーニングに積極的に取り組んでおり、アルゴリズムの品質を改善しています。 そのため、CatBoostにはさらに多くの変更が加えられます。
-あなたはSmartData 2017カンファレンスで講演者になります。 レポートについて一言お願いします、何を期待すべきですか?
Anna :レポートでは、アルゴリズムの主要なアイデア、パラメーターに含まれるアルゴリズムの種類、およびそれらを正しく使用する方法について説明します。