「機械学習の力は私たちの中にあり、その方法は私たちを取り囲み、私たちを縛ります。 私の周りの力、どこでも、私とあなたとの間、決定的な木、なげなわ、家紋、参照ベクトルだから、おそらく、ヨーダはデータサイエンスの方法を教えてくれたら教えてくれるだろう。
残念ながら、私の知り合いの間では緑肌のしわのある人格は観察されませんが、したがって、 絶対に初心者のレベルから最終的に判明するものの
最後の2つの記事では、光源をスペクトルに従って分類する問題を解決しました(それぞれPythonとC#で )。 今回は、照明強度曲線(照明器具が床に映るスポットに応じて)に従って器具を分類する問題を解決しようとします。
既にパワーの経路を理解している場合は、 Githubにデータセットをすぐにダウンロードして、このタスクを自分で試すことができます。 しかし、私のように、誰もがタックルを求めます。
幸いなことに、今回のタスクは非常に単純であり、それほど時間はかかりません。

私は本当に記事の目次を第4エピソードから始めたかったのですが、その名前は意味に合いませんでした。
エピソード I:隠された脅威、または以前の一連の記事全体を読んでいない場合にあなたを脅かすもの。
まあ、原則として、何も脅かすものではありませんが、データサイエンス(データサイエンス)を完全に初めて使用する場合は、最初の記事を正しい年代順に見ることをお勧めします。これは、何らかの方法で初心者の目を通してデータサイエンスを見る貴重な経験なので、今、自分の道を説明しなければならないとしたら、私はそれらの感情を思い出すことができず、問題のいくつかは私にとってばかげているように見えるでしょう。 したがって、あなたが始めたばかりの場合、基本を学んでどのように苦しめられた(そして今も苦しんでいる)かを見てください。
したがって、ここに記事のリストが登場順に(最初から最後まで)あります
- “ 大小さまざまなデータをキャッチ! »-(認知クラスデータサイエンスコースの概要)
- 「 今、彼もあなたを数えています 」またはData Science from Scratch
- “ オスカーの代わりに氷山! 「または、どのようにしてkaggleでDataScienceの基本を学ぼうとしたのか
- データサイエンスの初心者から見た「できる列車」または「機械学習とデータ分析の専門化」
- 「Rise of the Machines Learning」、またはデータサイエンスの趣味と光スペクトルの分析を組み合わせたもの
- " "ノートのように! "またはAccord.NET Frameworkを使用したC#の機械学習(データサイエンス)
また、この記事から作業者、特にユーザーGadPetrovichの要求に応じて、資料の目次を作成します。
内容:
エピソードI:幻影の脅威、または以前の一連の記事全体を読んでいない場合にあなたを脅かすもの。
エピソードII:クローンの攻撃またはこのタスクは過去とあまり変わらないようです
エピソードIII:シスの復ven、またはデータマイニングの難しさについて少し
エピソードIV:すべてが簡単かつ簡単に分類されるという新しい希望
エピソードV:帝国が反撃するか、「戦闘」で簡単にデータを準備することが難しい
エピソードVI:ジェダイの帰還、またはあなたのモデルのために誰かによって事前に書かれた力を感じる!
エピソードVII:フォースが目覚める-結論の代わりに
エピソード II:クローンの攻撃、またはこのタスクは過去とあまり変わらないようです。
うーん、2番目の見出しであり、このスタイルを維持し続けることは難しいとすでに考えています。
前回 、機械学習タスク用の独自のデータセットの作成、ロジスティック回帰とランダムフォレストの例を使用したこれらのデータの分類子のトレーニングモデル、PCA、T-SNEおよびDBSCAN
今回は、兆候は少なくなりますが、タスクに根本的な違いはありません。
少し先に進むと、タスクが過去のクローンのように見えないようにするために、今回の例ではSVC分類子に対応し、ソースデータのスケーリングが非常に役立つことを確認します。
エピソード III:シスの復ven、またはマイニングデータの難しさについて少し。
まず、光度曲線(CSC)とは何ですか?
さて、これは次のようなものです:
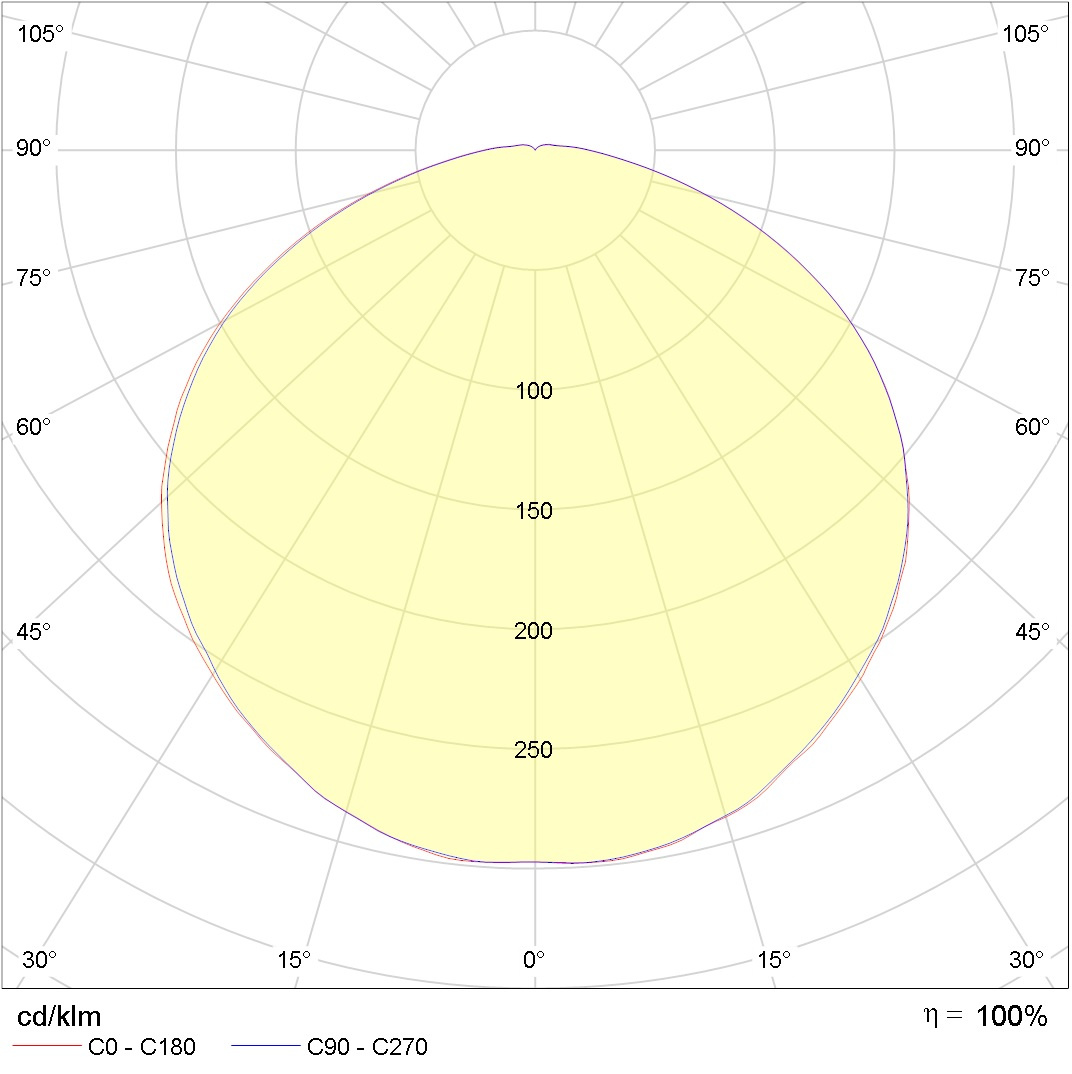
少しはっきりさせるために、頭の上にランプがあり、その下に立っている場合(街灯からの光のスポットのように)そのような光の円錐が足の下に落ちると想像してください。
この写真は、異なる極角(これが白熱灯の縦断面であると想像してください)、2つの方位角0-180と90-270(白熱灯の横断面であると想像してください)のギャップでの光強度(円上の値)を示しています。 多分、私は非常に正確に説明しませんでした。詳細については、照明工学ガイドページ833以降の Julian Borisovich Aisenbergに
しかし、元のデータに戻って、広告とは考えないでください。しかし、今日分類する備品はすべて、あるメーカー、つまり照明技術会社のものです。 私は彼らとは何の関係もありませんし、彼らの言及から「硬貨」で私のポケットは満たされません
それでなぜ彼らは? すべてが非常にシンプルで、みんなはそれが私たちにとって便利であることを確認しました。
データを引き出すために必要なKSSおよび.iesファイルからの写真は、対応するアーカイブに既に収集されています。ダウンロードするだけで 、ネットワーク全体を少しずつ収集するよりもはるかに便利です。
おそらく注意深い読者は、それがすべてどこから来たのか、なぜこのセクションはシスの復venと呼ばれるのかを尋ねるのをすでにイライラして待っていますか? 残酷な復venはどこですか?!
まあ、どうやら詩の復geは、長年、数学、プログラミング、照明、機械学習以外のことをやっていて、今は神経細胞でお金を払っているということでした。
遠くから少し始めましょう...
これは、単純な.iesファイルがどのように見えるかです
IESNA:LM-63-1995
[TEST] SL20695
[MANUFAC] PHILIPS
[LUMCAT]
[LUMINAIRE] NA
[LAMP] 3 Step Switch A60 220-240V9.5W-60W 806lm 150D 3000K-6500K Non Dim
[BALLAST] NA
[OTHER] B-Angle = 0.00 B-Tilt = 0.00 2015-12-07
TILT=NONE
1 806.00 1 181 1 1 2 -0.060 -0.060 0.120
1.0 1.0 9.50
0.00 1.00 2.00 3.00 4.00 5.00 6.00 7.00 8.00 9.00
10.00 11.00 12.00 13.00 14.00 15.00 16.00 17.00 18.00 19.00
20.00 21.00 22.00 23.00 24.00 25.00 26.00 27.00 28.00 29.00
30.00 31.00 32.00 33.00 34.00 35.00 36.00 37.00 38.00 39.00
40.00 41.00 42.00 43.00 44.00 45.00 46.00 47.00 48.00 49.00
50.00 51.00 52.00 53.00 54.00 55.00 56.00 57.00 58.00 59.00
60.00 61.00 62.00 63.00 64.00 65.00 66.00 67.00 68.00 69.00
70.00 71.00 72.00 73.00 74.00 75.00 76.00 77.00 78.00 79.00
80.00 81.00 82.00 83.00 84.00 85.00 86.00 87.00 88.00 89.00
90.00 91.00 92.00 93.00 94.00 95.00 96.00 97.00 98.00 99.00
100.00 101.00 102.00 103.00 104.00 105.00 106.00 107.00 108.00 109.00
110.00 111.00 112.00 113.00 114.00 115.00 116.00 117.00 118.00 119.00
120.00 121.00 122.00 123.00 124.00 125.00 126.00 127.00 128.00 129.00
130.00 131.00 132.00 133.00 134.00 135.00 136.00 137.00 138.00 139.00
140.00 141.00 142.00 143.00 144.00 145.00 146.00 147.00 148.00 149.00
150.00 151.00 152.00 153.00 154.00 155.00 156.00 157.00 158.00 159.00
160.00 161.00 162.00 163.00 164.00 165.00 166.00 167.00 168.00 169.00
170.00 171.00 172.00 173.00 174.00 175.00 176.00 177.00 178.00 179.00
180.00
0.00
137.49 137.43 137.41 137.32 137.23 137.10 136.97
136.77 136.54 136.27 136.01 135.70 135.37 135.01
134.64 134.27 133.85 133.37 132.93 132.42 131.93
131.41 130.87 130.27 129.68 129.08 128.44 127.78
127.11 126.40 125.69 124.92 124.18 123.43 122.63
121.78 120.89 120.03 119.20 118.26 117.34 116.40
115.46 114.49 113.53 112.56 111.52 110.46 109.42
108.40 107.29 106.23 105.13 104.03 102.91 101.78
100.64 99.49 98.35 97.15 95.98 94.80 93.65
92.43 91.23 89.99 88.79 87.61 86.42 85.17
83.96 82.76 81.49 80.31 79.13 77.91 76.66
75.46 74.29 73.07 71.87 70.67 69.49 68.33
67.22 66.00 64.89 63.76 62.61 61.46 60.36
59.33 58.19 57.11 56.04 54.98 53.92 52.90
51.84 50.83 49.82 48.81 47.89 46.88 45.92
44.99 44.03 43.11 42.18 41.28 40.39 39.51
38.62 37.74 36.93 36.09 35.25 34.39 33.58
32.79 32.03 31.25 30.46 29.70 28.95 28.23
27.48 26.79 26.11 25.36 24.71 24.06 23.40
22.73 22.08 21.43 20.84 20.26 19.65 19.04
18.45 17.90 17.34 16.83 16.32 15.78 15.28
14.73 14.25 13.71 13.12 12.56 11.94 11.72
11.19 10.51 9.77 8.66 6.96 4.13 0.91
0.20 0.17 0.16 0.19 0.19 0.20 0.16
0.20 0.18 0.20 0.20 0.21 0.20 0.16
0.20 0.17 0.19 0.20 0.19 0.18
内部では、メーターの製造業者と実験室に関するデータが縫製されているほか、データが必要な極角と方位角に依存する光の強度など、ランプに関するデータも直接縫製されています。
合計で193個のファイルを選択しましたが、それらを手動で処理しようとすることすらほとんどありませんでした。
一方では、すべてがGiesです。これは.iesファイルの構造を詳細に記述していますが、他方では、必要なデータを自動的に認識して削除することは私が思っていたよりも困難でした。
しかし、あなたにとって、映画の最高の伝統のように、すべての複雑で退屈なものは「舞台裏」のままです。 したがって、データの直接的な説明に移ります。
エピソード IV:新しい希望...すべてが簡単かつ簡単に分類されること。
したがって、上記で参照した文献の助けを借りて主要な問題を掘り下げて、トレーニングとデモの例でフィクスチャを分類するために、この場合のいずれかの方位角に十分なデータスライスがあるという結論に達しますゼロに等しく、0から180までの極角の範囲で、10ずつ増加します(品質のために小さなステップを踏むことに意味はありませんが、これは大きな影響はありません)
つまり、この場合、データは左側のグラフではなく右側のグラフに表示されます。
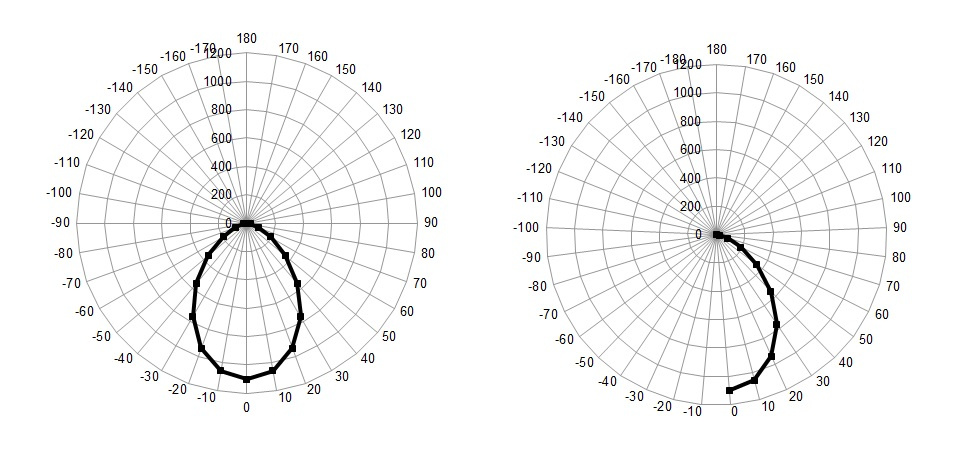
ところで、誰かが知らなかった場合、MS Excelで花びらチャートを使用すると、KCCグラフを簡単にプロットできます。
Lighting Technologiesのアーカイブでは、異なるKSSのランプが不均等に分布しているため、4つのタイプを分析します。これは、元のデータセットに最も多く含まれています。
したがって、次のKCCがあります。
濃縮(K)、深層(G)、余弦(D)、および半幅(L)。
最大光強度の方向の領域は、それぞれ次の角度にあります。
K = 0°-15°; G = 0°-30°; D = 0°-35°; L = 35°-55°;
データセットでラベルがラベルに割り当てられます。
K 1; G = 2; D = 3; L = 4; (最初から始めなければなりませんでしたが、今はやり直すのが面倒です)
実際、照明工学の分野の専門家ではないため、器具を分類することは困難です。たとえば、上の図の器具はKSSが深い器具に起因すると考えられますが、100%確信はありません。
原則として、物議を醸す問題を避け、GOSTと例を見てみましたが、どこかで間違いを犯した可能性があります。クラスラベルの割り当て、書き込みに誤りがある場合は、可能であれば修正します。
エピソード V:帝国が反撃するか、「戦闘」でデータを簡単に準備するのが難しい
さて、データを準備することが困難だった場合、2人でこのゲームをプレイできるようです。分析するのは正反対です。 ゆっくり始めましょう。
以下に示す.ipynb(Jupyter)形式のすべてのソースコードを含むファイルは、 GitHubからダウンロードできることを再度お知らせします
そのため、開始するには、ライブラリをインポートします。
#import libraries import warnings warnings.filterwarnings('ignore') import pandas as pd import numpy as np import matplotlib.pyplot as plt import matplotlib.patches as mpatches from sklearn.model_selection import train_test_split from sklearn . svm import SVC from sklearn.metrics import f1_score from sklearn.ensemble import RandomForestClassifier from scipy.stats import uniform as sp_rand from sklearn.model_selection import StratifiedKFold from sklearn.preprocessing import MinMaxScaler from sklearn.manifold import TSNE from IPython.display import display from sklearn.metrics import accuracy_score from sklearn.model_selection import train_test_split %matplotlib inline <source lang="python"> #reading data train_df=pd.read_csv('lidc_data\\train.csv',sep='\t',index_col=None) test_df=pd.read_csv('lidc_data\\test.csv',sep='\t',index_col=None) print('train shape {0}, test shape {1}]'. format(train_df.shape, test_df.shape)) display('train:',train_df.head(4),'test:',test_df.head(4)) #divide the data and labels X_train=np.array(train_df.iloc[:,1:-1]) X_test=np.array(test_df.iloc[:,1:-1]) y_train=np.array(train_df['label']) y_test=np.array(test_df['label'])
以前の記事を読んだり、Pythonでの機械学習に精通している場合、ここで紹介するすべてのコードは難しくありません。
ただし、念のため、最初にトレーニングサンプルとテストサンプルのデータを表に読み取り、次に記号(極角の輝度)とクラスラベルを含む配列を切り取ります。もちろん、わかりやすくするために、表の最初の4行を印刷しました。 、ここで何が起こったのですか:
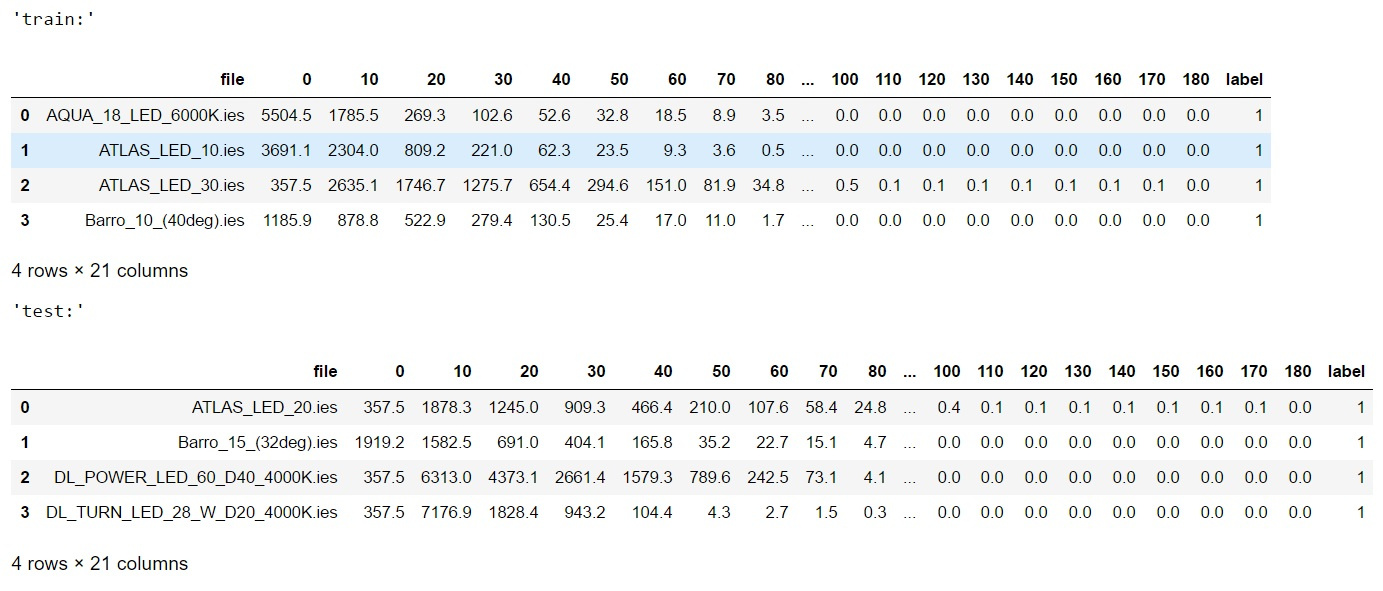
あなたはそれを信じることができます、データはクラスNo.4(曲線L)を除外するためにバランスが悪く、一般的に最初の3つのクラスではトレーニングサンプルで40サンプル、コントロールで12サンプル、教育およびコントロール全体で9であるため、トレーニングサンプルとコントロールサンプルの比率は1/4に近い値が維持されます。
誰かの言葉を信じないことに慣れているなら、コードを実行してください:
#draw classdistributions test_n_max=test_df.label.value_counts().max() train_n_max=train_df.label.value_counts().max() fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(12,5)) train_df.label.plot.hist(ax=axes[0],title='train data class distribution', bins=7,yticks=np.arange(0,train_n_max+2,2), xticks=np.unique(train_df.label.values)) test_df.label.plot.hist(ax=axes[1],ti
そして、あなたは以下を見るでしょう:
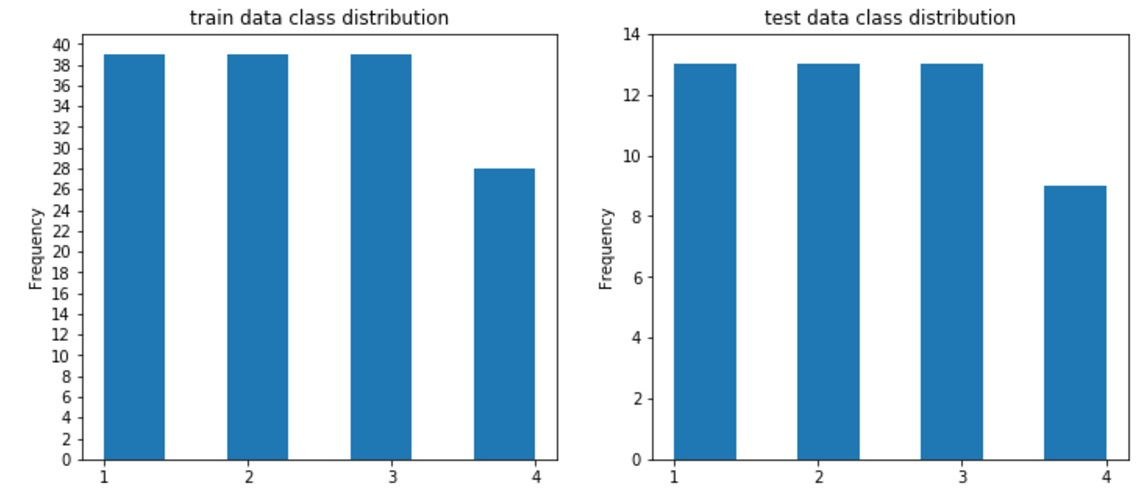
記号に戻りましょう。一方で、それらはすべて同じ値を反映しています。つまり、大まかに言って、自転車の数と気圧は相関していません。値のレベル、今回は値の振幅が数万単位に達する可能性があります。
したがって、標識を拡大縮小することは合理的です。 ただし、scikit-learnのすべてのスケーリングモデルは列ごとにスケーリングするように見えます(または、私はそれを把握しませんでした)。この場合、列ごとにスケーリングすることは意味がありません。これは、「分類」 !
代わりに、コーナーの光の力の分布の性質を維持するためにサンプルのデータを(行ごとに)スケーリングしますが、同時に全体の広がりを0から1の範囲にドライブします。
良い方法で、私が読んだ本では、彼らはトレーニングセットとコントロール1モデル(トレーニングセットでトレーニングされた)をスケーリングするようアドバイスしていますが、私たちの場合、これは機能の数の不一致のために機能しません(テストセットの行が少なくなり、転置されたマトリックスは列数が少ない)、各サンプルを独自の方法で調整します。
この問題に関連して、先を見据えて、分類プロセス中に、私はそれに関して何も悪いことを発見しませんでした。
#scaled all data for final prediction scl=MinMaxScaler() X_train_scl=scl.fit_transform(X_train.T).T X_test_scl=scl.fit_transform(X_test.T).T #scaled part of data for test X_train_part, X_test_part, y_train_part, y_test_part = train_test_split(X_train, y_train, test_size=0.20, stratify=y_train, random_state=42) scl=MinMaxScaler() X_train_part_scl=scl.fit_transform(X_train_part.T).T X_test_part_scl=scl.fit_transform(X_test_part.T).T
あなたが完全な初心者であっても、記事の過程でscikit-learnセットのすべてのモデルが同様のインターフェースを持っていることに気付くでしょう、データをfitメソッドに渡すことでモデルを訓練し、データを変換する必要がある場合、transformメソッドを呼び出します(この場合、メソッドを使用します2 in 1)、および後でデータを予測する必要がある場合は、predictメソッドを呼び出して、新しい(コントロール)サンプルをフィードします。
さて、もう1つ小さな点として、コントロールサンプル用のタグがないことを想像してみましょう。たとえば、kagle問題を解決します。モデルの予測の品質をどのように評価できますか。
私たちの場合、ビジネス上の問題の解決が必要ではない場合、最も簡単な方法の1つは、トレーニングサンプルを別のトレーニングサンプルに分割し(ただし小さい)、テスト(トレーニングから)することです。これは少し後で役立ちます。 それまでの間、スケーリングに戻り、これがどのように役立つかを見てみましょう。スケーリング機能なしの一番上の画像、スケーリング付きの一番下の画像です。
#not scaled x=np.arange(0,190,10) plt.figure(figsize=(17,10)) plt.plot(x,X_train[13]) plt.plot(x,X_train[109]) plt.plot(x,X_train[68]) plt.plot(x,X_train[127]) c1 = mpatches.Patch( color='blue', label='class 1') c2 = mpatches.Patch( color='green', label='class 2') c3 = mpatches.Patch(color='orange', label='class 3') c4 = mpatches.Patch( color='red',label='class 4') plt.legend(handles=[c1,c2,c3,c4]) plt.xlabel(' (polar angle)') plt.ylabel(' (luminous intensity)') plt.title(' ')
それを異なるセルに「ハンマー」で打ち込む(まあ、またはサブプロットを作成する)
#scaled x=np.arange(0,190,10) plt.figure(figsize=(17,10)) plt.legend() plt.plot(x,X_train_scl[13],color='blue') plt.plot(x,X_train_scl[109],color='green') plt.plot(x,X_train_scl[68], color='orange') plt.plot(x,X_train_scl[127], color='red') c1 = mpatches.Patch( color='blue', label='class 1') c2 = mpatches.Patch( color='green', label='class 2') c3 = mpatches.Patch(color='orange', label='class 3') c4 = mpatches.Patch( color='red',label='class 4') plt.legend(handles=[c1,c2,c3,c4]) plt.xlabel(' (polar angle)') plt.ylabel(' (luminous intensity)') plt.title(' ()')
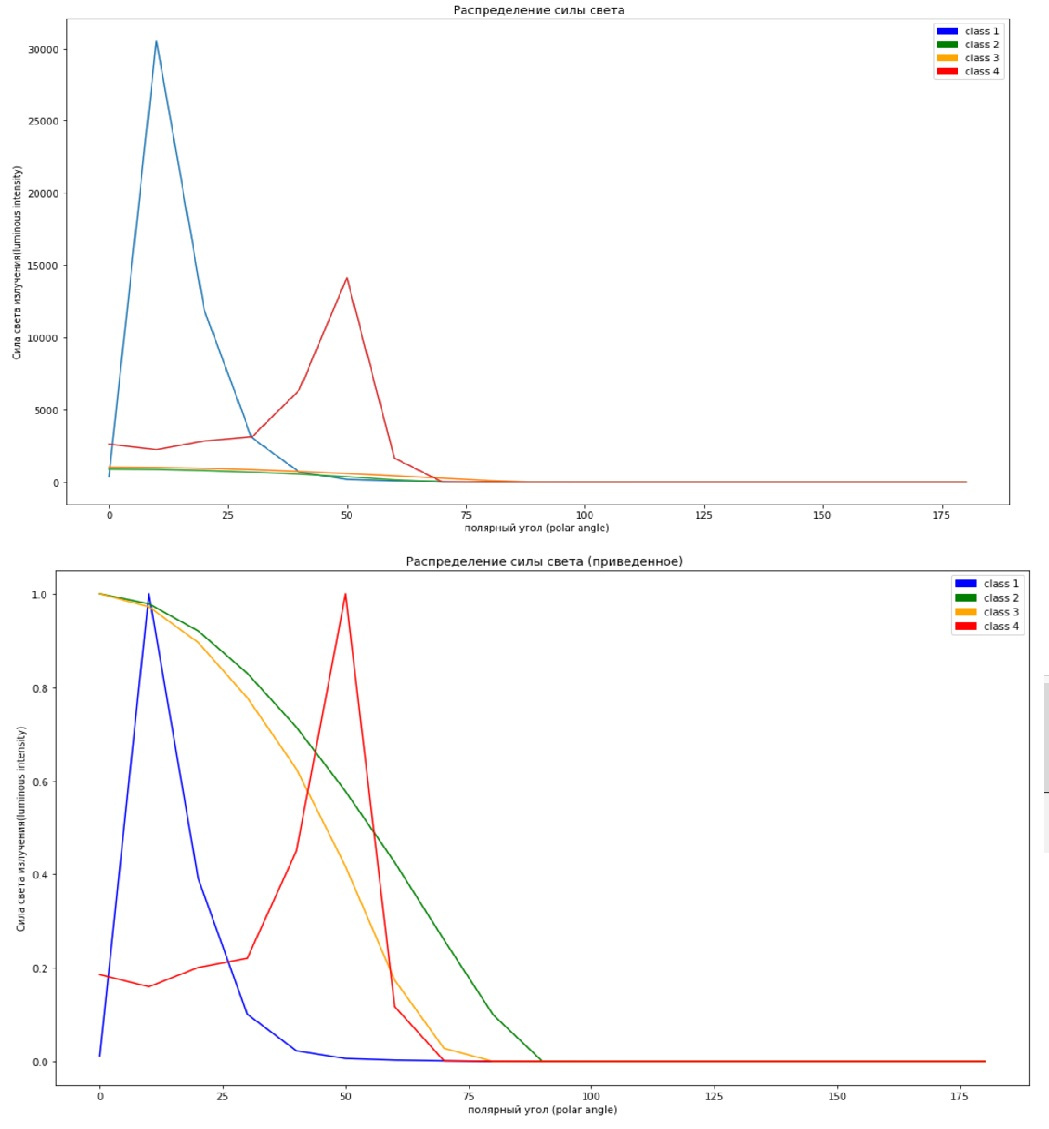
グラフには各クラスから1つのサンプルが表示されますが、スケールグラフの一部は、スケールの違いにより単純にゼロにマージされるため、私たちとコンピューターはスケールグラフから何かを理解しやすくなります。
最終的に正しいことを確認するために、フィーチャの次元を2次元に減らし、2次元グラフにデータを表示して、データが分離可能かどうかを確認してみましょう(これにはt-SNEを使用します)
スケーリングなしで左スケーリングありで右
#T-SNE colors = ["#190aff", "#0fff0f", "#ff641e" , "#ff3232"] tsne = TSNE(random_state=42) d_tsne = tsne.fit_transform(X_train) plt.figure(figsize=(10, 10)) plt.xlim(d_tsne[:, 0].min(), d_tsne[:, 0].max() + 10) plt.ylim(d_tsne[:, 1].min(), d_tsne[:, 1].max() + 10) for i in range(len(X_train)): # , plt.text(d_tsne[i, 0], d_tsne[i, 1], str(y_train[i]), color = colors[y_train[i]-1], fontdict={'weight': 'bold', 'size': 10}) plt.xlabel("t-SNE feature 0") plt.ylabel("t-SNE feature 1")
それを異なるセルに「ハンマー」で打ち込む(まあ、またはサブプロットを作成する)
#T-SNE for scaled data d_tsne = tsne.fit_transform(X_train_scl) plt.figure(figsize=(10, 10)) plt.xlim(d_tsne[:, 0].min(), d_tsne[:, 0].max() + 10) plt.ylim(d_tsne[:, 1].min(), d_tsne[:, 1].max() + 10) for i in range(len(X_train_scl)): # , plt.text(d_tsne[i, 0], d_tsne[i, 1], str(y_train[i]), color = colors[y_train[i]-1], fontdict={'weight': 'bold', 'size': 10}) plt.xlabel("t-SNE feature 0") plt.ylabel("t-SNE feature 1")
ゼロからマークをカウントし始めたので、1を引きます。

図は、スケーリングされたデータでは、クラス1、3、4が多かれ少なかれ明確に区別可能であり、クラス2はクラス1と3の間で塗りつぶされていることを示しています(ダウンロードしてKCCフィクスチャを見ると、そうであるべきことが理解できます)
エピソード VI:ジェダイの復活、または以前に誰かがあなたのために書いたモデルの力を感じます!
さて、今すぐ直接分類を開始する時間です
まず、「切り捨てられたデータ」でSVCをトレーニングします
#predict part of full data (test labels the part of X_train) #not scaled svm = SVC(kernel= 'rbf', random_state=42 , gamma=2, C=1.1) svm.fit (X_train_part, y_train_part) pred=svm.predict(X_test_part) print("\n not scaled: \n results (pred, real): \n",list(zip(pred,y_test_part))) print('not scaled: accuracy = {}, f1-score= {}'.format( accuracy_score(y_test_part,pred), f1_score(y_test_part,pred, average='macro'))) #scaled svm = SVC(kernel= 'rbf', random_state=42 , gamma=2, C=1.1) svm.fit (X_train_part_scl, y_train_part) pred=svm.predict(X_test_part_scl) print("\n scaled: \n results (pred, real): \n",list(zip(pred,y_test_part))) print('scaled: accuracy = {}, f1-score= {}'.format( accuracy_score(y_test_part,pred), f1_score(y_test_part,pred, average='macro')))
次の結論が得られます
スケーリングされない
not scaled:
results (pred, real):
[(2, 3), (2, 3), (2, 2), (3, 3), (2, 1), (2, 3), (2, 3), (2, 2), (2, 1), (2, 2), (1, 1), (3, 3), (2, 2), (2, 1), (2, 4), (3, 3), (2, 2), (2, 4), (2, 1), (2, 2), (4, 4), (2, 2), (4, 4), (2, 4), (2, 3), (2, 1), (2, 1), (2, 1), (2, 2)]
not scaled: accuracy = 0.4827586206896552, f1-score= 0.46380859284085096
スケーリング済み
scaled:
results (pred, real):
[(3, 3), (3, 3), (2, 2), (3, 3), (1, 1), (3, 3), (3, 3), (2, 2), (1, 1), (2, 2), (1, 1), (3, 3), (2, 2), (1, 1), (4, 4), (3, 3), (2, 2), (4, 4), (1, 1), (2, 2), (4, 4), (2, 2), (4, 4), (4, 4), (3, 3), (1, 1), (1, 1), (1, 1), (2, 2)]
scaled: accuracy = 1.0, f1-score= 1.0
ご覧のとおり、最初のケースで何とか達成できた場合、その差は非常に大きくなります。
結果はランダムな予測よりもわずかに優れているだけで、2番目のケースでは100%ヒットしました。
完全なデータセットでモデルをトレーニングし、100%の結果が得られることを確認します
#final predict full data svm.fit (X_train_scl, y_train) pred=svm.predict(X_test_scl) print("\n results (pred, real): \n",list(zip(pred,y_test))) print('scaled: accuracy = {}, f1-score= {}'.format( accuracy_score(y_test,pred), f1_score(y_test,pred, average='macro')))
結論を見てみましょう
results (pred, real):
[(1, 1), (1, 1), (1, 1), (1, 1), (1, 1), (1, 1), (1, 1), (1, 1), (1, 1), (1, 1), (1, 1), (1, 1), (1, 1), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (3, 3), (3, 3), (3, 3), (3, 3), (3, 3), (3, 3), (3, 3), (3, 3), (3, 3), (3, 3), (3, 3), (3, 3), (3, 3), (4, 4), (4, 4), (4, 4), (4, 4), (4, 4), (4, 4), (4, 4), (4, 4), (4, 4)]
scaled: accuracy = 1.0, f1-score= 1.0
パーフェクト! 精度のメトリックとともに、f1-scoreを使用することにしました。これは、クラスの不均衡が大幅に大きい場合に役立ちますが、この場合、メトリック間にほとんど違いはありません(ただし、明確にしました)。
さて、最後に確認するのは、すでにわかっているRandomForest分類器です
本や他の資料では、RandomForestの記号のスケーリングは重要ではないことを読みましたが、そうであるかどうかを見てみましょう。
rfc=RandomForestClassifier(random_state=42,n_jobs=-1, n_estimators=100) rfc=rfc.fit(X_train, y_train) rpred=rfc.predict(X_test) print("\n not scaled: \n results (pred, real): \n",list(zip(rpred,y_test))) print('not scaled: accuracy = {}, f1-score= {}'.format( accuracy_score(y_test,rpred), f1_score(y_test,rpred, average='macro'))) rfc=rfc.fit(X_train_scl, y_train) rpred=rfc.predict(X_test_scl) print("\n scaled: \n results (pred, real): \n",list(zip(rpred,y_test))) print('scaled: accuracy = {}, f1-score= {}'.format( accuracy_score(y_test,rpred), f1_score(y_test,rpred, average='macro')))
次の結論が得られます。
not scaled:
results (pred, real):
[(1, 1), (1, 1), (2, 1), (1, 1), (1, 1), (2, 1), (1, 1), (1, 1), (1, 1), (1, 1), (1, 1), (1, 1), (1, 1), (2, 2), (2, 2), (2, 2), (1, 2), (2, 2), (2, 2), (2, 2), (2, 2), (3, 2), (2, 2), (3, 2), (2, 2), (4, 2), (3, 3), (3, 3), (3, 3), (3, 3), (3, 3), (3, 3), (3, 3), (3, 3), (3, 3), (3, 3), (4, 3), (3, 3), (3, 3), (4, 4), (4, 4), (4, 4), (4, 4), (4, 4), (4, 4), (4, 4), (4, 4), (4, 4)]
not scaled: accuracy = 0.8541666666666666, f1-score= 0.8547222222222222
scaled:
results (pred, real):
[(1, 1), (1, 1), (2, 1), (1, 1), (1, 1), (1, 1), (1, 1), (1, 1), (1, 1), (1, 1), (1, 1), (1, 1), (1, 1), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (3, 3), (3, 3), (3, 3), (3, 3), (3, 3), (3, 3), (3, 3), (3, 3), (3, 3), (3, 3), (3, 3), (3, 3), (3, 3), (4, 4), (4, 4), (4, 4), (4, 4), (4, 4), (4, 4), (4, 4), (4, 4), (4, 4)]
scaled: accuracy = 0.9791666666666666, f1-score= 0.9807407407407408
したがって、2つの結論を導き出すことができます。
1.決定的なツリーの場合でも、属性をスケーリングすると便利な場合があります。
2. SVCの精度が向上しました。
今回はパラメーターを手動で選択し、2回目の試行でscvの2番目のオプションを獲得した場合、10回目からでもランダムフォレストでそれを選択せず、スパッツしてデフォルトで残しました(ツリーの数を除く)。 おそらく、100%の精度をもたらすパラメーターがあり、それを拾い上げてコメントで伝えるようにしてください。
さて、それですべてですが、スターウォーズのファンは、サガの7番目の映画に言及しないことを私に許さないと思います...
エピソード VII:力の覚醒-結論の代わりに。
機械学習はとてつもなく魅力的なものであることが判明しましたが、私は今でも皆さんの近くで問題を見つけて解決しようとすることをみんなに勧めています。
すぐにうまくいかない場合は、下の写真のように鼻を垂らさないでください。
はい、はい! あなたがこれが「あなたの鼻をハングアップしないでください」と他の隠された考えがないとは思わないように;)
そして、力があなたと共に来ますように!