シニアプロダクトマネージャーのFedor Ivanov mthmtcnは、さまざまなメトリックを使用してキークエリをクラスター化することについて書きました。
はじめに
これまで、コンテンツ広告のコンバージョン最適化ツールは、直接広告主と代理店の両方で広く使用されています。 1年以上にわたり、Calltouchでは、コンテンツ広告の入札単価を最適化するツールを開発してきました。 オプティマイザーの主な目標は、キーワードのこのような入札単価を計算し、それらを設定することで、それらの望ましい主要指標を達成できるようにすることです ( K P I ) 最適化の目標として設定されています。 このような問題のステートメントの典型的な例は、次による最適化です。 C P A :\ :(コスト \:P E R \:アブックマークション) 。 この場合、オプティマイザーの主な目標は、できるだけ多くのコンバージョン(ターゲットアクション)を取得して、このアクションの平均コストが設定されたターゲット制限を超えないようにすることです C P A 。 最大化などの最適化戦略もあります R O I \:\: ( リターン \:O F :\ 投げ資) 、広告キャンペーンなどの所定の予算でコンバージョンを最大化する
今日、市場には、入札管理に従事している非常に多くのシステムがあります。 各ツールには、初期構成、機能、追加オプションなどの点で独自の特性があります。特に、Calltouchオプティマイザーは、呼び出しトピックでのコンテキスト広告の最適化を専門としています(ただし、機能は呼び出しのみの最適化に限定されません)。 コンテキスト最適化システムは、全体として、広告主が設定したタスクにうまく対処します。 ただし、最適化の大きな効果は、主に広告予算が大きい顧客によって達成されます。 この依存関係を理解するのは非常に簡単です。 何らかの形でのすべてのコンバージョンオプティマイザーは、何らかの基準期間にわたって収集されたデータからはじかれます。 広告アカウントの予算が大きいほど、最適な入札単価の計算に必要な統計を収集できます。 さらに、コンテキストの予算のサイズはデータ収集の速度に直接影響するため、オプティマイザーが「加速」する速度に影響します。 上記は、キャンペーンの自動入札戦略に関するYandex.Directのヘルプによって明確に示されています。
28日間のターゲット訪問+ 0.01 x 28日間のクリック≥40-これは、自動CPA戦略の最適化のしきい値です(1つのキャンペーン)。
この戦略は、1週間に200回を超えるクリックと1週間に10回を超えるターゲット訪問を行うキャンペーンに効果的です。-これは最適化の有効性を保証する基準です。
明らかに、上記の「フィルター」に適合する広告キャンペーンはごく少数です。 予算が少ない広告主や新たに作成された広告キャンペーンの場合、この種のオプティマイザーの起動は不可能です。 もちろん、「サードパーティ」のオプティマイザーはトラフィック量をそれほど要求しません(特に、「フォルダ」に1回のターゲット訪問と1日あたり10クリックの最小しきい値を設定します-単一の最適化されたキャンペーンのパッケージ K p i と最適化戦略)、しかし、彼らは何らかの形で蓄積された統計の著しい不足の状態で存在することを余儀なくされています。 データ不足の問題をより詳細に検討してください。
キーワード統計
パレートの原理は広く知られており、「努力の20%が結果の80%を生み出す」と定式化できます。
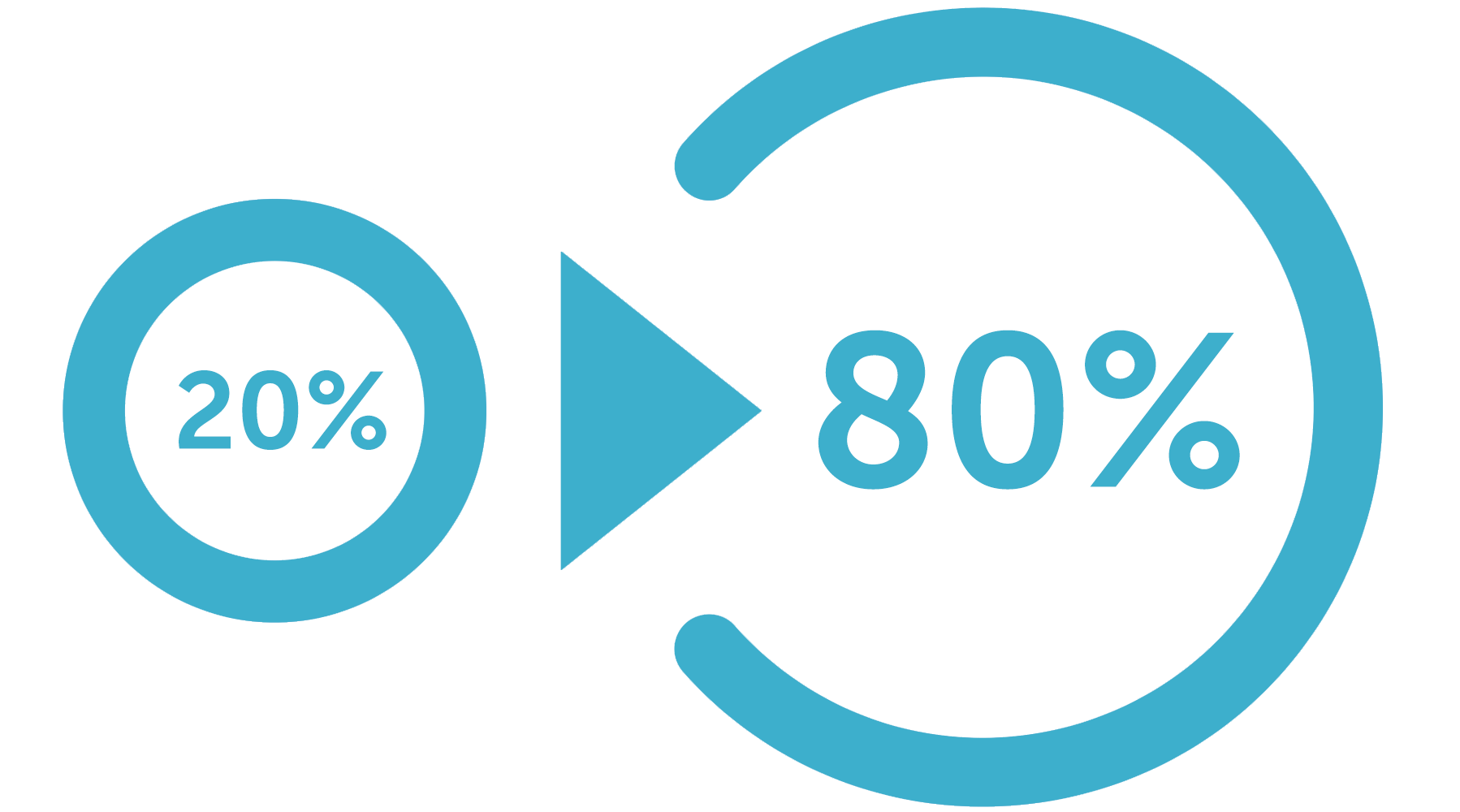
私たちの観察に基づいて、コンテキスト広告にもこの原則がありますが、割合はわずかに異なります:「キーフレーズの5%がトラフィック(統計)の95%を占める」:

コンバージョンオプティマイザーは各キーワードフレーズの最適な入札単価を個別に決定するため、情報に基づいた決定はフレーズの約5%に対してのみ行うことができます。 この図をさらに詳しく調べると、すべてのキーフレーズは、統計の量に応じて3つのグループに分類できます(一定期間、コレクションとも呼ばれます)。

もちろん、統計の妥当性の問題は、データ量を評価するための何らかの基準と一致している必要があります。 この基準の計算は、特定の分布のサンプルサイズの妥当性の評価に関連する確率理論と数学統計の方法に基づいています。
したがって、フレーズのすべてのキーフレーズは、3つの主要なグループに分けることができます。
- 参照期間の十分な統計情報を持つフレーズ
- 決定を下すのに十分ではない統計を含むフレーズ
- 参照期間の統計のないフレーズ
データが不十分な状況で入札単価を計算するためのさまざまなアプローチを検討する前に、このデータが最適な入札単価に変換される方法を理解する必要があります。 この変換は、2つのメインブロックに分割できます。
- 予測係数の計算 C r キーワードのコンバージョン
- 計算された最適な入札の計算 C r そして確立された K p i
最初に、2番目のブロックを検討します。 コンバージョン率を予測したと仮定します C r フレーズで。 クライアントがターゲットを設定した場合 K p i フレーズについていくつかの統計が蓄積されました S t 必要な主要指標に応じて、最適な入札単価 入札 上記のパラメーターの関数として計算:
入札=f(CR、KPI、ST)
。コンバージョン率自体も累積統計に依存しますが、依存しないことは明らかです Kpi :
CR=CR(ST)
したがって、最適なレートを計算するための最終的な式は次のとおりです。
入札=f(CR(ST)、KPI、ST)
特定のタイプの機能 f 使用されるメトリックに依存します。 ST 最適化戦略と Kpi 。 たとえば、次の最適化戦略の場合 CPA レートを計算するための最も簡単な式は次のとおりです。
入札=CPA∗CR
他の戦略では、ベットを計算するためのより複雑な式が使用されます。
入札単価を計算する際の重要なポイントは、コンバージョン率をできるだけ正確に予測することです。これは、入札単価の計算前に行われます。 定義では、キーワードのコンバージョン率は、そのフレーズをクリックするとコンバージョンが発生する可能性です。 十分なクリックで CL およびコンバージョン CV 、この係数は次のように計算できます。
CR= fracCVCL
ただし、少量の統計でこの式を「正面から」適用すると、変換率の予測が意図的に不正確になる可能性があります。
たとえば、フレーズを考えます X 2回のクリックと1回のコンバージョンの期間にわたって。 この場合、式は値を与えます CR=0.5 。 最適化戦略を「最大コンバージョン数 CPA=2000 こする。」 入札=200∗0.5=1000 こする フレーズが X YANキャンペーンには適用されません...
反対の場合。 フレーズを聞かせて Y 2回のクリックと0回のコンバージョンがありました。 この場合、式は値を与えます CR=0 。 最適化戦略を「最大コンバージョン数 CPA=2000 こする 入札=2000∗0=0 こする この場合、このアカウントの通貨の最小入札価格が送信されます。 フレーズの印象は実質的に停止し、将来的にはコンバージョンをもたらすことはありません。
フレーズのクリック数が0、コンバージョン数が0の場合、計算は CR 「直接」は、表現「0/0」の不確実性のため、原則として不可能です。
したがって、「単純な」計算式 CR 十分な量の統計情報を持つキーフレーズにのみ使用できます(覚えているように、そのようなフレーズの約5%)。残りの95%のフレーズについては「加重」決定を行うことはできません。
この状況から抜け出すために、さまざまな手法を使用できます。たとえば、次のとおりです。
- キャンペーンレベルで単一入札を設定する
- と相関するメトリックの分析 CR (例:直帰率)
- フレーズが統計の収集を開始するまで入札単価を引き上げる
- 参照期間の延長
- 「プーリング」の使用(スマート継承および平均統計)
方法2と5はツールで積極的に使用されていますが、近い将来、参照期間を柔軟に構成する機能も追加する予定です。 これを行う方法については、別の記事を書きます。 また、このホワイトペーパーでは、「プーリング」方式を検討します。これは、最大の効率を示し、コンテキスト広告最適化システムで広く使用されています。
プーリング方法
プーリングは、基本的に、他のフレーズの統計を借用することにより、キーワードの統計の「合理的な」増加です。 クラシックプーリングの原理を理解するために、広告アカウントの構造(Yandex Directなど)に注目します。
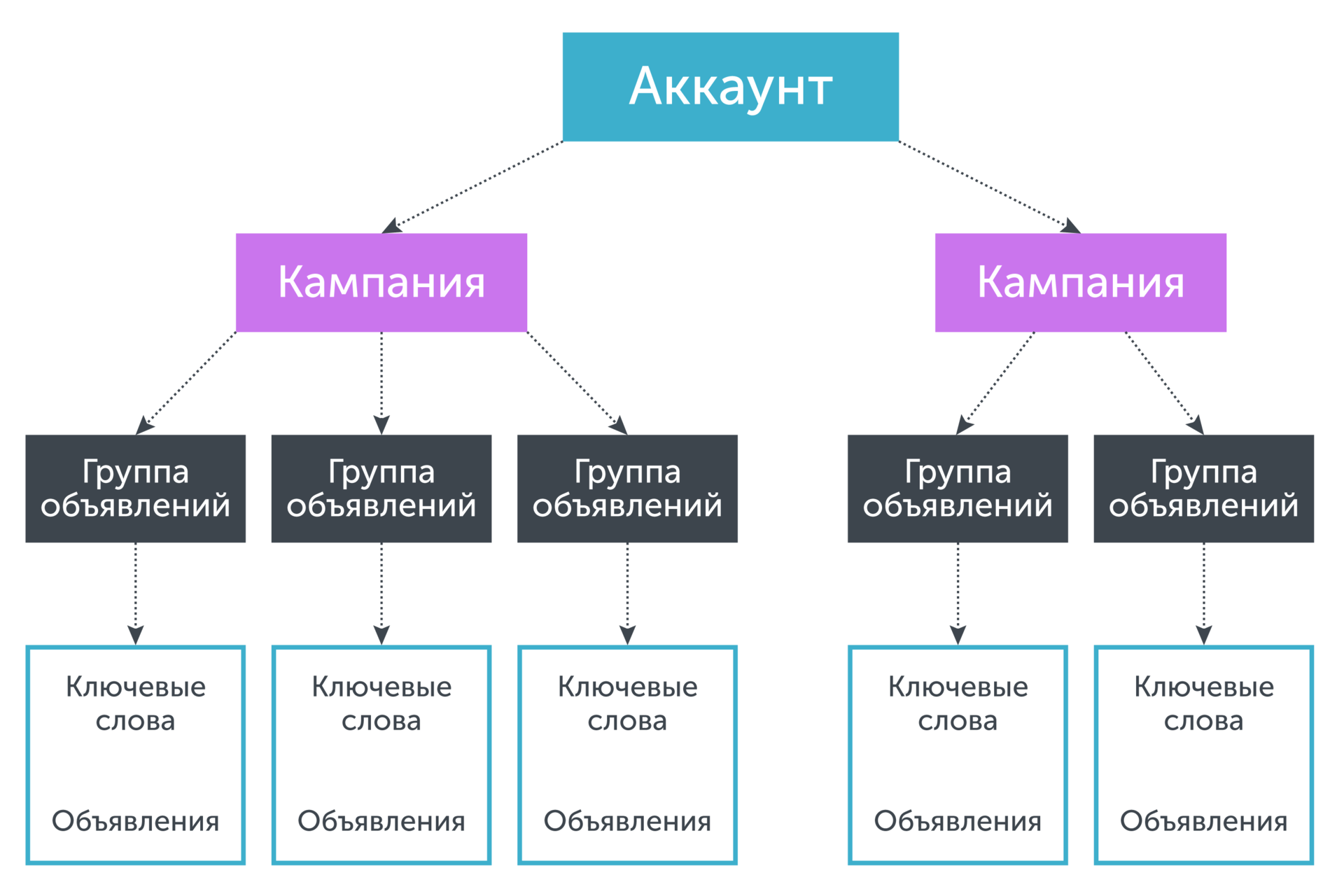
アカウントにはツリー構造があり、「ルート」はアカウント自体であり、「葉」はキーフレーズです。 キーフレーズは、トリガーされる広告に特定の方法で関連付けられます。 広告は広告グループに収集され、広告キャンペーンの一部として順番に結合されます。 独自の統計情報では不十分なキーワードのコンバージョン率を予測する必要がある場合、キーワードと広告、このフレーズが属する広告グループ、この広告グループが属するキャンペーンなどの統計情報を、したがって、予測されたパラメータの値を決定するには統計だけでは不十分です。 グラフィカルに、これはツリーを「葉」から「ルート」に「下に移動」することと同等です。
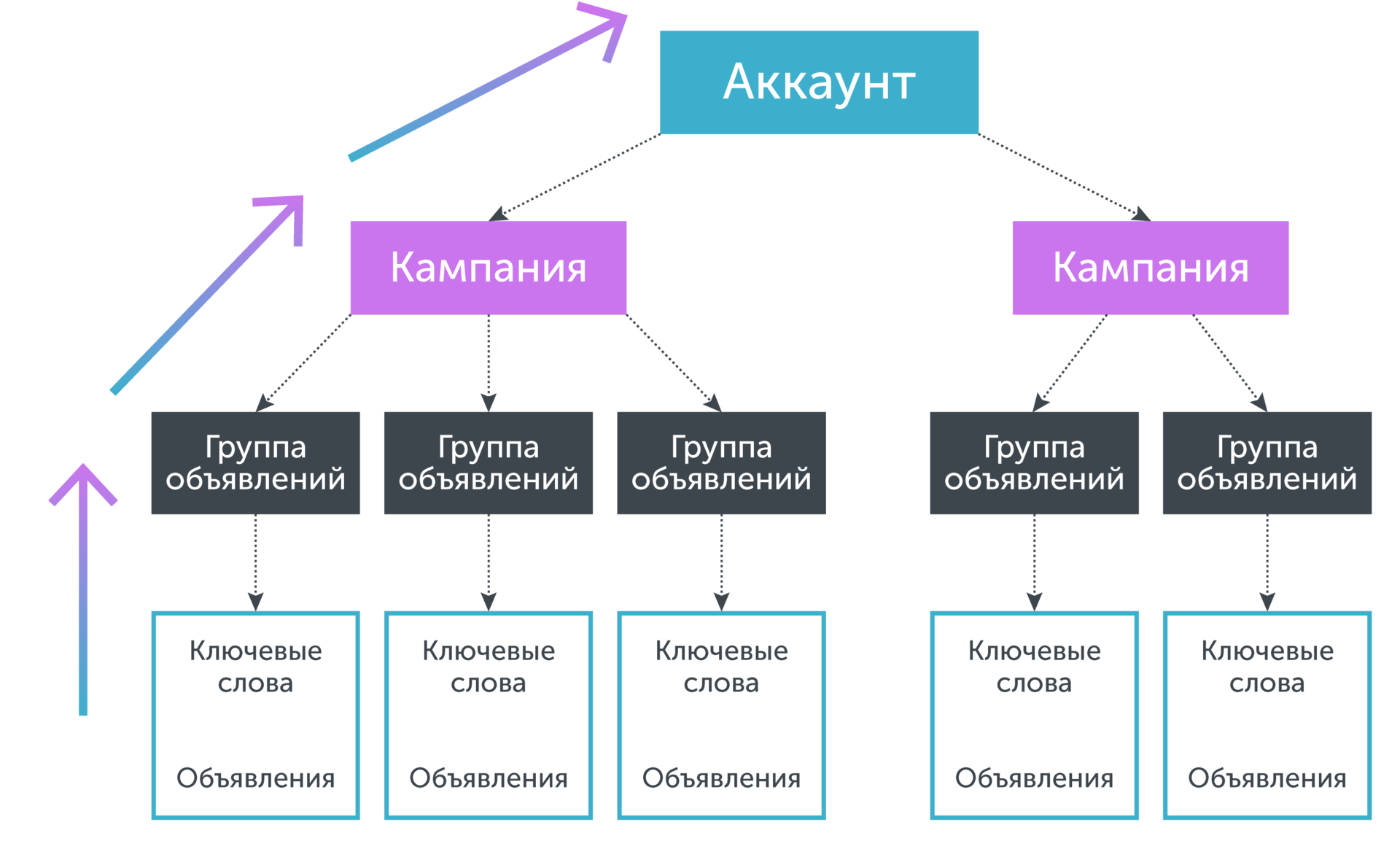
最も単純なプーリング式は次のとおりです。
CRpool= fracCV+1CL+ frac1CRup、
どこで CRプール -投影 CR キーフレーズ CV -キーワードのコンバージョン数、 CL -キーワードフレーズのクリック数、 CRup -次のプーリングレベルのコンバージョン率の値(たとえば、キャンペーンのコンバージョン率の値)。 したがって、このモデルでは、平均してすべてのフレーズが持つと仮定して、別のコンバージョンを獲得するために追加のクリックが必要なフレーズの数を予測します CR に近い CRup 。 次に、このレベルで十分な統計データがあれば、直接計算できます。そうでなければ、より高いレベルのプーリングを使用して計算できます。 この場合、複雑なネストされたモデルが取得されます。
例を挙げます。 フレーズを聞かせて X 5回のクリックと1回のコンバージョン、そしてそれが存在する広告グループ X 、100回のクリックと5回のコンバージョンを獲得しました。 100回のクリックで最適な入札単価を決定できると仮定すると、次のようになります。
CRpool= frac1+15+ frac1 frac5100= frac225=0.08
プーリング方法とそのさまざまな一般化は、コンテキスト広告自動化システムで広く使用されています。 たとえば、インターネットで世界で最も人気のある広告管理プラットフォームであるマリンソフトウェアは、そのモデルの特許を取得しています(米国特許PTO 60948670)。
CR= frac widetildeFk+CVk+CL
k=(\ワイドティルデF−\ワイドティルデF2)/( sigma2F)–1、
どこで \ワイドティルドF -次のプーリングレベルのコンバージョン確率の平均値、 sigma2F -次のプーリングレベルの変換確率値の分散(広がりの測定値)。
明らかに、分散が大きいほど少ない k 、つまり、コンバージョン率の予測における次のレベルのプーリングの影響は小さくなります。 価値 sigma2F コンバージョン率が互いにどれだけ近いかによって決まります。 クラシックプーリングモデルを使用 sigma2F 広告アカウントの開発状況に直接依存します。つまり、予測の質は人的要因に直接依存します。
さらに、階層プーリングではフレーズの統計のみが考慮され、その構造は無視されます。
上記に関連して、Calltouchチームは、コンバージョン率を予測するための異なるアプローチを開発しました。
アプローチの重要なアイデア
私たちのアプローチの主なアイデアは、プルするときに階層構造を放棄することです。 代わりに、特別なメトリックが導入されています。 d (距離の尺度)。キーフレーズのテキスト間の類似性を評価できます。
特定のキーワードフレーズに対して X 十分な統計情報を持つさまざまなフレーズからそのような要素を選択します S (クラスタリングコアと呼びます)、テキスト間の距離が X 選択された要素は、事前に定義された数を超えていません \デルタ :
クラスター(X、\ delta)= \ {p∈S:d(X、p)\ leq \ delta \}
与えられた場合 \デルタ クラスターに十分な統計が含まれていない場合、 \デルタ 特定のステップで増加 h : delta:= delta+h まで クラスター(X、\デルタ) フレーズのコンバージョン率を予測するのに十分な統計情報が得られない X 。 クラスターが構成されると、クラスター内のフレーズの変換率の平均値が値として選択されます CRup 。 グラフィカルに、このプロセスは次のように表すことができます。

次に、クラスター構造をより詳細に検討します。
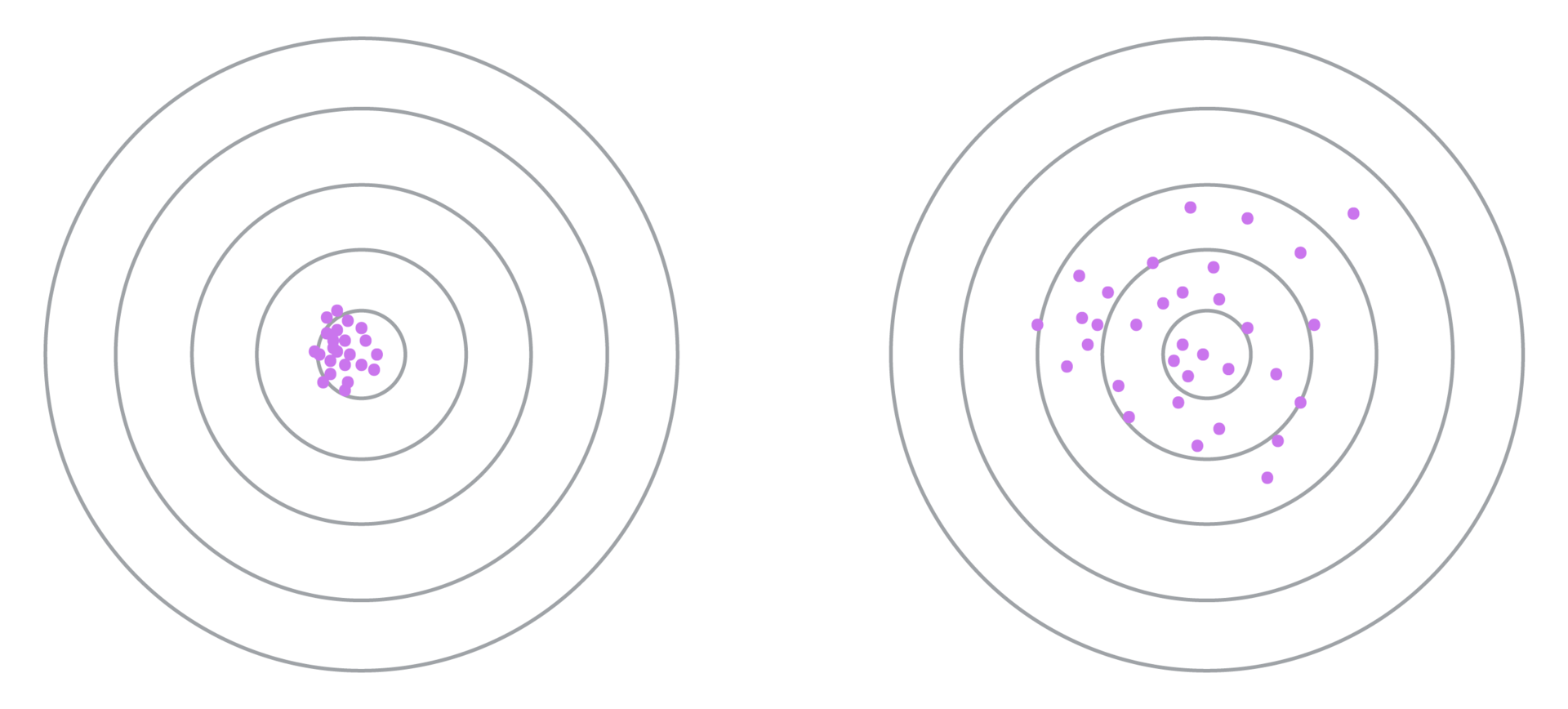
変換係数のばらつきが小さいキーフレーズを左の図で選択し、大きなものを右の図で選択しました。 大きな分散の場合、アルゴリズムの収束が遅くなることがわかります(しきい値を数回増やす必要があります) \デルタ 、予測自体の精度は低くなります。 したがって、分散を最小化するフレーズ類似性メトリックを事前に選択する必要があります。
アフィニティメトリック
2つのテキストの類似性を計算するためのさまざまなメトリックがあります(この例ではキーフレーズ)。 これらのメトリックにはそれぞれ長所と短所があり、可能なアプリケーションの範囲を狭めます。 私たちのチームが実施した調査では、次のタイプの距離が考慮されました。
- レーベンシュタイン距離
- Nグラムの距離
- コサイン距離
各メトリックをより詳細に検討します。
レーベンシュタイン距離
レーベンシュタイン距離は、1行を別の行に変換するために必要な、1文字の挿入、1文字の削除、1文字の置き換えを行う最小操作数として定義されます。 この行間隔を示します S1 そして S2 どうやって L(S1、S2) 。 明らかに L(S1、S2) 小さい線 S1 そして S2 似ている。
以下に例を示します。
させる S1=′string′ そして S2=′犬′ 次に回す S1 で S2 、「t」を「o」に、「p」を「b」に、「o」を「a」に置き換える必要があります。 L(S1、S2)=3 。
もし S1= 「これは1つのフレーズです」 S2= 「これはまったく異なるフレーズです」 L(S1、S2)=12 。
レーベンシュタイン距離の主な利点は、テキスト内の単語形式への依存度が低いことと実装の容易さであり、主な欠点は単語の順序への依存度です。
Nグラムの距離
Nグラム距離の計算の基礎となる主なアイデアは、行を長さNのサブストリングに分割し、一致するサブストリングの数をカウントすることです。
たとえば、N = 2(バイグラムへの分割)および S1= 「1回のキーワード」、しかし S2= 「2つのキーワード」 S1 次の一連のバイグラムに対応します。「ra」、「az」、「ke」、「her」、...、「rd」、および行 S2 :「dv」、「va」、「ke」、「her」、...、「rd」。
N = 3(トライグラムへの分割)の場合、同じ S1 そして S2 私達は得る:
S1 :「times」、「azk」、「zke」、「kay」、「neur」、...、「hordes」
S2 :「two」、「vak」、「ake」、「kay」、「neur」、...、「hordes」
N-gram距離自体 Ng(N、S1、S2) 次の式で計算されます。
Ng(N、S1、S2)= frac2|S1 capS2||S1|+|S2|、
どこで |S1| -のN-gramの数 S1 、 |S2| -のN-gramの数 S2 そして |S1 capS2| -合計N-gramの数 S1 そして S2 。
私たちの場合: Ng(2、S1、S2)=0.75 そして Ng(3、S1、S2)=0.83 。
キーフレーズの類似性を計算するこのアプローチの主な利点は、テキスト内の単語の形式に弱く依存することです。 主な欠点は、自由パラメータNに依存することです。自由パラメータNの選択は、クラスタ内の分散に強い影響を与える可能性があります。
コサイン距離
コサイン距離の計算の基礎となる主な考え方は、文字列を数値ベクトルに変換できるということです。 2つの比較された文字列でこの手順を実行すると、2つの数値ベクトル間の余弦を介して、それらの類似性の尺度を推定できます。 学校の数学のコースから、ベクトル間の角度が0(つまり、ベクトルが完全に一致)の場合、コサインは1であることがわかります。逆も同様です。ベクトル間の角度が90度の場合(ベクトルが直交-つまり、完全に一致しない)、 0に等しい。
コサイン距離の正式な定義を導入する前に、文字列を数値ベクトルにマッピングする方法を決定する必要があります。 このような表示として、テキスト文字列からインジケーターのベクトルへの変換を使用しました。
例を考えてみましょう。 させる
S1= 「割引価格でプラスチック窓を購入する」、
S2= 「モスクワで無料配送で安価なプラスチック窓を購入する」
テーブルを作りましょう:

表の最初の行には、テキストに表示されるさまざまな単語がすべて表示されます。 S1 そして S2 、2行目と3行目は、指定された単語が行に表示されることを示すインジケータです S1 または S2 それに応じて。 したがって、各行を置き換えると S1 そして S2 インジケーターからベクトルへ(それぞれ呼び出します) A そして B )、式を使用してライン間のコサインを計算できます:
Cos(S1、S2)= frac sum limitsni=1AiBi sqrt sum limitsni=1A2i sqrt sum limitsni=1B2i
この例では:
Cos(S1、S2)\約0.45
間の距離 S1 そして S2 次の式で検討します。
CosD(S1、S2)=1−Cos(S1、S2)
次に、この場合:
CosD(S1、S2)\約0.55
コサイン距離の主な利点は、このメトリックがスパースデータでうまく機能することです(キーフレーズの実際のテキストは非常に長く、ネガティブキーワード、ストップワードなどのオーバーヘッド情報が大量に含まれる場合があります)。彼の言葉の形への非常に強い依存です。
これを適切な事例で説明します。 させる
S1= 「プラスチック製の窓を購入する」
S2= 「プラスチック製の窓を購入する」
非常によく似た2つのテキストのすべての単語が異なる形式で使用されていることは簡単にわかります。 , CosD(S1,S2)=1 。 , S1 そして S2 , .
().
.
() – — () .
:
- — , ;
- — , , ;
- , , — .
, – , , . .
S1= « » “ ”, S2= “ ” - “ ”. :
CosD(S1,S2)≈0.33
, .
結果
, . , : , , . . Calltouch 10000 , . , .
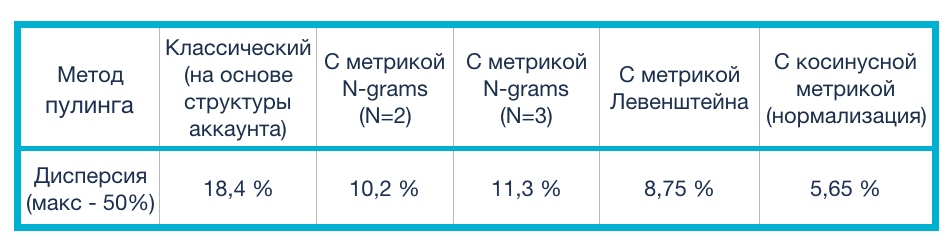
, 28 CL :
CL≥1CRcamp,
どこで CLcamp - , .
, ( CR ), . .
おわりに
この記事では、テキストの類似性に基づいてキーフレーズをクラスタリングする新しいアプローチについて説明します。この方法により、変換係数のクラスター内分散が大幅に減少し、キーワードによる変換予測の精度が大幅に向上することが示されています。この記事で説明されている方法を使用して、独自の統計情報では最適な入札単価を決定できないフレーズでも最適化できます。上記のコンバージョン率の計算方法はCalltouchコンバージョンオプティマイザーの要素であり、実際には大規模なプロジェクトと広告予算が比較的少ないアカウントの両方で高い効率を示しています。