今日は、Stream APIについてお話しし、まだ知られていない世界で秘密のベールを開こうとします。 Java 8はかなり前に登場したという事実にもかかわらず、誰もがプロジェクトでその機能のすべてを使用するわけではありません。 このPandoraの箱を開けて、そのような神秘的な現象の中に実際に隠れているものを見つけるために、私たちはJetBrains-Tagir lany Valeevの開発者に助けられます。 、誤ったストリームの書き方)、独自のStreamExライブラリを作成しました。これにより、Javaストリームの作業が改善されます。 誰が面白くなったのか、カットをお願いします!
この資料は、2016年10月にサンクトペテルブルクで開催されたJoker会議でのTagir Valeevのレポートに基づいています。
講演の数ヶ月前に、私はツイッターで小さなアンケートを行いました。
したがって、 Parallel Streamについてはあまり説明しません。 とにかくそれらについて話しましょう。
このレポートでは、いくつかの癖について説明します。

Streamインターフェースに加えて、Javaにはいくつかのインターフェースがあることは誰もが知っています。
- イントストリーム
- ロングストリーム
- ダブルストリーム
そして、「なぜそれらを使用するのか、何がポイントなのか」という論理的な疑問が生じるようです。

重要なのは、速度を上げることです。 プリミティブは常に高速です。 したがって、少なくとも、Streamのドキュメントに示されています。
プリミティブストリームが実際に高速かどうかを確認します。 まず、同じStream APIを使用してランダムに生成するテストデータが必要です。
int[ ] ints; Integer[ ] integers; @Setup public void setup() { ints = new Random(1).ints(1000000, 0, 1000) .toArray(); integers = new Random(1).ints(1000000, 0, 1000) .boxed().toArray(Integer[]::new); }
ここでは、0〜1000の範囲で100万個の数値を生成します(含まない)。 次に、それらをintのプリミティブ配列に収集し、その後整数オブジェクト配列にパックします。 この場合、ジェネレータを同じ番号で初期化するため、取得する番号はまったく同じです。
数字に対していくつかの操作を実行しましょう-両方の配列にある一意の数字の数を計算します。
@Benchmark public long stream() { return Stream.of(integers).distinct().count(); } @Benchmark public long intStream() { return IntStream.of(ints).distinct().count(); }
もちろん、結果は同じになりますが、問題はどのStreamがどのくらい速くなるかです。 プリミティブストリームはより高速になると考えています。 しかし、推測しないように、テストを実施し、得られたものを確認します。

うーん、プリミティブStream、奇妙なことに、失われました。 ただし、Java 1.9でテストを実行すると、プリミティブは高速になりますが、それでも半分未満です。 「プリミティブストリームがより高速であるとまだ約束しているのに、なぜそうなのか」という疑問が生じます。 これを理解するには、ソースコードを見る必要があります。 たとえば、distinct()メソッドと、プリミティブStreamでの動作方法を検討してください。 はい、これですべてがはっきりしているように見えますが、Streamはインターフェイスであるため、当然、実装はありません。 実装全体はjava.util.streamパッケージにあり、パブリックパッケージに加えて、実際には実装である多くのプライベートパッケージがあります。 Streamが実装するメインクラスはReferencePipelineで 、これはAbstractPipelineを継承します 。 それに応じて、プリミティブストリームの実装が実行されます。

したがって、IntPipelineに移動して、distinct()の実装を確認します。
// java.util.stream.IntPipeline
@Override public final IntStream distinct() { // While functional and quick to implement, // this approach is not very efficient. // An efficient version requires an // int-specific map/set implementation. return boxed().distinct().mapToInt(i -> i); }
プリミティブ型のパッキングがあり、その上で異なるStream呼び出しが形成されていることがわかります。その後、プリミティブStreamが形成されます。
したがって、これを置き換えると、2番目のケースで同じ仕事があり、さらに多くの仕事があります。 プリミティブ数のストリームを取得してパックし、 distinct()およびmapToInt()を呼び出します。 MapToInt自体はほとんど何も食べませんが、パッケージにはメモリが必要です。 最初のケースでは、オブジェクトがすでにあるため、メモリが事前に割り当てられていますが、2番目のケースでは、メモリを割り当てる必要があり、そこでGCが動作し始めます。 表示されるもの:
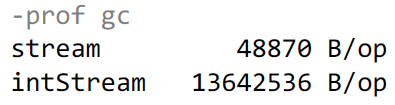
最初のケースでは、テストでは48 kBのメモリを使用します。これは主にHashSetサポートに使用され、 distinct内で使用されて、既に存在する数値を確認します。 2番目のケースでは、かなり多くのメモリ、約13メガバイトを割り当てます。
しかし、一般的に、私はあなたを安心させたいです、これは規則の唯一の例外です。 一般に、プリミティブストリームの動作ははるかに高速です。 これがJDKで行われる理由-Javaにはプリミティブ用の特別なコレクションがないためです。 プリミティブintに distinct()を実装するには、プリミティブ型のコレクションが必要です。 同様の機能を提供するライブラリがあります。
- https://habrahabr.ru/post/187234/
- https://github.com/leventov/Koloboke
- https://github.com/vigna/fastutil
しかし、これはJDKには当てはまらず、 intにプリミティブHashSetを実装する場合、 longとdoubleの両方にHashSetを作成する必要があります。 パラレルストリームもあり、パラレルストリームは順序付きおよび順序なしです。 順序付きにはLinkedHashSetがあり、順序なしではConcurrentが必要です。 したがって、大量のコードを実装する必要がありますが、誰もそれを書いていません。 10番目のJavaでリリースされる可能性のあるGenericの専門化を誰もが期待しています。
別の癖を見てみましょう。

引き続きランダムな数字で遊んで、100万の数字を取りましょう。 範囲はより大きくなります-0から50,000(含まない)になるので、数字が繰り返される頻度は少なくなります。 事前にそれらをソートし、プリミティブ配列に入れます。
private int[] data; @Setup public void setup() { data = new Random(1).ints(1_000_000, 0, 50_000) .sorted().toArray(); }
次に、distinctを使用して、一意の数値の合計を計算します。
@Benchmark public int distinct() { return IntStream.of(data).distinct().sum(); }
これは最も単純な実装であり、動作し、結果を正しく計算します。 しかし、私たちはもっと速く何かを考え出したいです。 さらにいくつかのオプションを提供します:
@Benchmark public int distinct() { return IntStream.of(data).distinct().sum(); } @Benchmark public int sortedDistinct() { return IntStream.of(data).sorted().distinct().sum(); } @Benchmark public int boxedSortedDistinct() { return IntStream.of(data).boxed().sorted().distinct() .mapToInt(x -> x).sum(); }
第2の実施形態では、 distinct()の前に再度ソートし、第3のバージョンでは、引き続きpack、sort、 distinct()を実行し、プリミティブ配列にキャストしてから集計します。
疑問が生じます:「なぜソートするのですか? しかし、私たちと一緒にすべてが整理されました。 その場合、合計の結果はソートに依存しません。」
次に、常識に基づいて、最初のオプションが最も速く、2番目が遅く、3番目が最も長いと想定できます。
ただし、 distinct()はパッケージ化を行い、プリミティブ型につながることを思い出すことができます。したがって、上記の例は次のように表すことができます。
@Benchmark public int distinct() { return IntStream.of(data).boxed().distinct() .mapToInt(x -> x).sum(); } @Benchmark public int sortedDistinct() { return IntStream.of(data).sorted().boxed().distinct() .mapToInt(x -> x).sum(); } @Benchmark public int boxedSortedDistinct() { return IntStream.of(data).boxed().sorted().distinct() .mapToInt(x -> x).sum(); }
これらの例は互いにより類似していますが、いずれにしても、パッケージングは追加作業として行います。 結果を見てみましょう:

予想どおり、2番目のオプションは動作が遅くなりますが、最後のオプションは、奇妙なことに、最も速く動作します。 神秘的な行動ではありませんか?
一般に、いくつかの要因を一度に区別できます。 まず、データが既にソートされている場合、Javaでのソートは高速です。 つまり、数字が正しい順序になっていることがわかると、すぐに退出します。 したがって、ソートのソートは十分に安価です。 ただし、Stream'eのsort ()操作は、既にソートされているという特性を追加します。 最初に配列をすでに並べていましたが、Streamはそれについて知りません。 私たちだけがこれについて知っています。 したがって、 distinct()がソートされたStreamを検出すると、より効率的なアルゴリズムが含まれます。 彼はもはやHashSetを収集して重複する番号を探すのではなく、次の各番号を前の番号と単に比較します。 つまり、理論的には、入力データが既にソートされている場合、ソートが役立ちます。 その後、2番目のテストが3番目のテストよりも遅い理由は明らかではありません。 これを理解するには、 boxed()メソッドの実装を見る必要があります:
// java.util.stream.IntPipeline @Override public final Stream<Integer> boxed() { return mapToObj(Integer::<i>valueOf</i>); }
そして、コードでそれを置き換えると:
@Benchmark public int distinct() { return IntStream.of(data).mapToObj(Integer::valueOf) .distinct().mapToInt(x -> x).sum(); } @Benchmark public int sortedDistinct() { return IntStream.of(data).sorted().mapToObj(Integer::valueOf) .distinct().mapToInt(x -> x).sum(); } @Benchmark public int boxedSortedDistinct() { return IntStream.of(data).mapToObj(Integer::valueOf).sorted() .distinct().mapToInt(x -> x).sum(); }
また、 mapToObj()は、Streamがソートされている特性を削除します。 3番目のケースでは、オブジェクトをソートし、 distinct()を支援します。これにより、動作が速くなります。 また、 mapToObj()がそれらの間にある場合、このソートは無意味になります。
私には奇妙に思えた。 boxed()をもう少し長く記述し、Streamソート仕様を保持できます。 そこで、Java 1.9にパッチを導入しました。

ご覧のように、パッチを適用した後、結果は非常に興味深いものになります。 2番目のオプションは、プリミティブでソートされるため、優先されます。 オブジェクトをソートするため、3番目のオプションは2番目に少し失われますが、同時に最初のオプションよりも優れています。
ちなみに、バージョン9でテストを実行する場合、-XX:+ UseParallelGCオプションを使用しました。バージョン8ではデフォルトであり、バージョン9ではデフォルトでG1であるためです。 このオプションを削除すると、結果は大きく異なります。

したがって、バージョン9に切り替えると、動作が遅くなる可能性があることに注意してください。
次の癖に移りましょう。

次のタスクを実行します。 その実装には、20面体を使用します。 二十面体は、20個の面を持つこのような正多面体です。

Stream APIを使用してこれを行います。
// IntStream ints(long streamSize, int origin, int bound) new Random().ints(5, 1, 20+1).sum();
パラメータを設定し、取得した値を要約します。 このアプローチでは、結果が完全に正しいとは限りません。 5つの擬似乱数の合計が必要です。 そして、繰り返しになることがあります:

distinct()を追加すると 、繰り返しもスローされるため、これも役に立ちません。合計で4桁以下になります。

バージョンをもう少し本格的にすることは私たちに残っています:

int()を取り、必要な数字の数を設定せず、特定の方法で生成された数字が必要であることを示します。 無限のストリームを取得します。この場合、 distinct()は繰り返しの数をチェックし、 limit()は 5つの数を受け取った後、数の生成を停止します。
次に、このタスクを並列化してみましょう。 これを行うのは簡単ではありませんが、非常に簡単です。

parallel()を追加するのに十分で、並列Streamがあります。 上記の例はすべてコンパイルされます。 上記の例の違いは何だと思いますか? 違いがあると想定できます。 もしそうだとすれば、これはあなたのせいではありません。ドキュメントにはそれについてほとんど何も書かれておらず、実際、多くの人が同じように考えているからです。 ただし、実際には違いはありません。 すべてのストリームには、パラレルまたはレギュラーとして記述するブール変数があるデータ構造があります。 また、Streamを実行する前にparallel()を記述する場合は常に、この特別な変数をtrueに設定し、その後、端末操作はこの変数があった値でそれを使用します。
特に、次のように書く場合:
new Random().ints(1, 20+1).parallel().distinct().limit(5) .sequential().sum();
別個の()と制限()のみが並行して実行され、合計()が順番に実行されると考えるかもしれません。 実はそうではありません。sequential()はチェックボックスをクリアし、Stream全体が順次実行されるためです。
9番目のバージョンでは、人を誤解させないようにドキュメントが改善されました。 このために別のチケットが作成されました。

順次ストリームの実行にかかる時間を見てみましょう。

ご覧のとおり、実行は非常に高速です-286ナノ秒。
正直に言うと、並列化がより高速になるとは思いません。 大きなコスト-タスクを作成し、プロセッサに分散します。 200ナノ秒より長くする必要があります-オーバーヘッドが大きすぎます。
並列Streamの実行時間は何倍ですか? 10回、20回、または無限に非常に長い時間ですか? テストは約6,000年間実行されるため、実用的な観点からは後者が適切です。

おそらくあなたのコンピューター上で、テストは数千年多かれ少なかれ実行されます。 この動作の理由を理解するには、少し掘り下げる必要があります。 それはすべて、いくつかの実装を備えたファンシー制限()操作に関するものです。 シーケンスや並列処理、およびその他のフラグによって動作が異なるためです。 この場合、 java.util.stream.StreamSpliterators.UnorderedSliceSpliterators <T、T_SPLIT>が機能します。 コードは表示しませんが、できるだけ簡単に説明しようとします。
順不同の理由 乱数のソースは、このストリームが順序付けられていないことを示しているためです。 したがって、並列化中に順序を変更しても、誰も気付かないでしょう。 そして、順不同の制限を実装するのは簡単に思えました-アトミック変数を追加し、インクリメントします。 それを増やしましたが、まだ限界に達していません- 別の()に別の番号を与えて加算器に渡すように依頼します。 アトミック変数が5に等しくなるとすぐに、計算を停止します。
この実装は、JDK開発者向けでなければ機能します。 彼らは、そのような実装では、すべてのスレッドが同じアトミック変数を使用するという事実のために、競合が多すぎると判断しました。 したがって、彼らは1つの番号ではなく、各128を取得することにしました。つまり、各スレッドはアトミック変数を128増やし、より高いソースから128の番号を取得しますが、カウンターは更新されなくなり、128の後のみ更新が行われます。 たとえば10,000に制限がある場合、これは賢明な決定ですが、そのような小さな制限がある場合は信じられないほど愚かです。 結局、5つ以上は必要ないことが事前にわかっています。 このソースから128個の数字を取得することはできません。 通常、最初の20個の数字を使用し、21で別の()を使用してもう1つ数字を指定します。 彼は「キューブ」からそれを取得しようとします、彼はそれを与えます。 たとえば、 distinct()は番号10を取得します。「しかし、それはすでにあった」とdistinct()が言い、さらに要求します。 彼は3番を取得しますが、彼はすでにそれを持っていました。 また、 distinct()がキューブのすべての面をすでに見ており、彼はキューブが終わったことを知らないため、誰もこのプロセスを停止しません。 これは無限に発生するはずですが、 int ()のドキュメントを見ると、Streamは無限ではなく、事実上無制限です。 特にLong.MAX_VALUE要素が含まれており、ある時点で終了します。

私には奇妙に思えましたが、バージョン9でこの問題を修正しました。

したがって、パフォーマンス障害が発生します。これは非常に適切で、約20〜25回です。 ただし、特定の例でこの問題を修正したとしても、これがまったく修正されたことを意味するものではないことを警告します。 これはパフォーマンスの問題であり、Streamが正しく実装されているという問題ではありません。
ドキュメントでは、 limit(5)を指定した場合、ソースから正確に5つの数値を読み取るとは書かれていません。 findFirstがある場合、これは1つの数字を読むことを意味するものではありません。好きなだけ読むことができます。 したがって、無限のストリームには注意する必要があります。 なぜなら、5個ではなく18個の数字を制限として使用すると、同じ問題に再び直面する可能性があるからです。 18の数値がすでに読み取られているため、他の3つの並列スレッドももう1つを要求し、21になります。したがって、このような操作は並列化しないでください。 パラレルストリームを使用すると、明らかです-短絡操作がある場合は、予想よりもはるかに多くの減算が行われます。

順次ストリームでは、この例には奇妙な点があります。
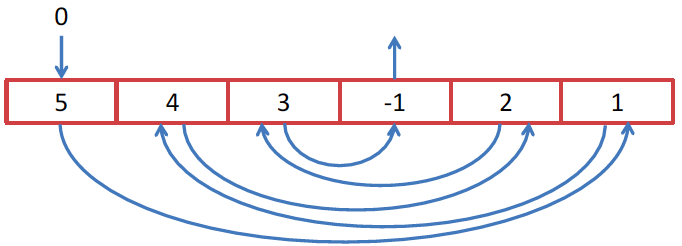
例は少し人工的かもしれませんが、それはいくつかのアルゴリズムに現れるかもしれません。 整数の配列を回避したいが、トリッキーな方法で回避したい。 0要素から始めましょう。この要素の値は、取得する次の要素のインデックスです。 Stream APIを使用して回避したいので、Stream.iterate()メソッドを見つけます。これは、タスク用に作成されたようです。
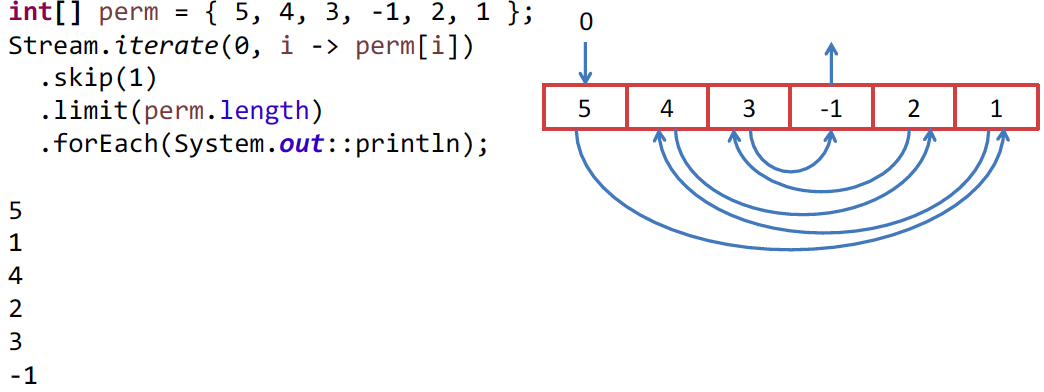
最初のStream要素は配列内のインデックスであり、2番目は成長関数です。 前の要素から次の要素を実行する関数。 この例では、要素をインデックスとして使用します。 ただし、最初の要素0はインデックスであり、必要ないため、 skip(1)でスキップします。 次に、Streamを配列の長さに制限して表示するか、別のアルゴリズムを実行します。たとえば、別のアルゴリズムが使用されます。
すべてが正しく動作し、キャッチはありません。 しかし、ここには整数があるので、なぜIntStreamを使用しないのですか? このインターフェイスには、反復処理とその他のすべての操作があります。 IntStreamを作成すると 、次の情報を受け取ります。
Exception in thread "main" java.lang.ArrayIndexOutOfBoundsException at test.Iterate.lambda$0(Iterate.java:9) at test.Iterate$$Lambda$1/424058530.applyAsInt(Unknown Source) at java.util.stream.IntStream$1.nextInt(IntStream.java:754) … at test.Iterate.main(Iterate.java:12)
問題は、これはIntStream.iterate()の実装の詳細であるが、 Stream.iterate()にはこの詳細がないことです。 番号が与えられるたびに、すぐに以下が要求されます。 これは変数に保存され、以前の番号が返されます。 したがって、-1を取得しようとすると、ソースからインデックス-1を持つ配列の値を取得しようとしますが、これはエラーにつながります。 私には奇妙に思えたので、修正しました。

しかし、これは単なる奇妙な実装であり、動作が仕様に準拠しているため、これをバグと呼ぶことはできません。

ストリームは本当にこれが大好きです:
Map<String, String> userPasswords = Files.lines(Paths.get("/etc/passwd")) .map(str -> str.split(":")) .collect(toMap(arr -> arr[0], arr -> arr[1]));
ファイルを取得して、ソースとして使用できます。 文字列のストリームに変えたり、配列に変えたり、見逃したりします。 すべてが美しく、すべてが一行でこのようになっています-私たちは皆流です:

しかし、このコードには何かが欠けていると思いませんか? たぶんトライキャッチ ? ほとんど、しかし完全ではありません。 try-with-resourcesが不十分です 。 ファイルを閉じる必要があります。そうしないと、ファイル記述子が不足する可能性がありますが、Windowsではさらに悪いことに、後で何もしません。
実際、コードはすでに次のようになっているはずです。

そして今、すべてがそれほどバラ色に見えません。 tryを挿入する必要があり、このために別の変数を取得しました。 これは、コードを記述するための推奨される方法です。つまり、私はこれを思いつきませんでした。 Streamドキュメントは、この方法でそれを行うと言っています。
当然、一部の人々はこれを好まず、それを修正しようとしています。 たとえば、ルーカス・エダーはこれを試みました。 彼は素晴らしい人で、そのようなアイデアを提供します。 彼はStackOverfowに関する議論に疑問を投げかけました 。 これはすべて奇妙ですが、Streamがいつ動作を終了するかはわかっています。端末操作があり、呼び出した後は、絶対に必要ありません。 閉じてみましょう。
ストリームはインターフェースです。それを利用して実装できます。 JDKから提供されるStreamへのデリゲートを作成し、すべての端末操作を再定義しましょう。元の端末操作を呼び出してStreamを閉じます。
このアプローチは機能し、すべてのファイルを正しく閉じますか? すべての端末操作のリストを検討してください-それらは2つのグループに分かれています。1つは「通常の」操作(内部バイパス)、もう1つは(奇妙なため)「Bizarre」(外部バイパス)と呼ばれます。
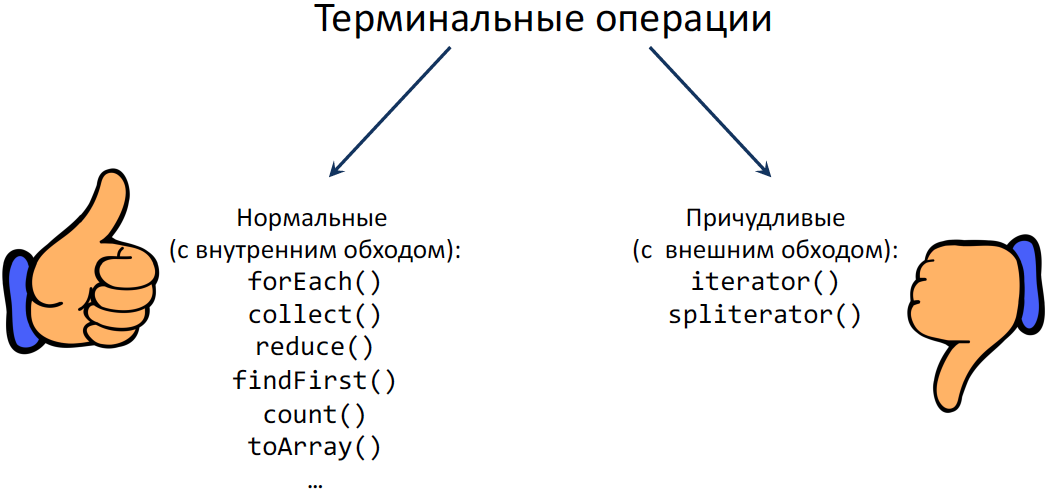
「奇妙な」操作は全体像を台無しにします。 ファイルのStream行を作成し、古いAPIに転送したい場合を想像してください。古いAPIはStreamでは何も知らないが、イテレーターについては知っています。 当然、このStreamからイテレータを取得しますが、ファイル全体をメモリにロードする必要はありません。 Streamsは遅延しているため、これが「遅延」するようにします。 つまり、実際には、端末操作はすでに呼び出されていますが、開いているファイルはまだ必要です。 その後、イテレータコントラクトは、このイテレータを閉じる必要があることや、その後イテレータが不要であることを意味しません。
iterator.next()を 1回呼び出してからドロップできます。 , , . , . Spliterator — , . tryAdvance() , hasNext() next() , . – , . , , , . , :

, , – Stream . – .
, , Stream . flatMap :

, , . , Stream. , Stream , Stream. flatMap() , Stream . , try-with-resources . :
Map<String, String> userPasswords = Stream.of(Files.lines(Paths.get("/etc/passwd"))) .flatMap(s -> s) .map(str -> str.split(":")) .collect(toMap(arr -> arr[0], arr -> arr[1]));
Stream.of(Files.lines(…)) – Stream'a, Stream. flatMap() Stream. flatMap() , Stream . . try .
, ? , . , . - «:» arr[1] ArrayIndexOutOfBoundsException , , flatMap() . , .
JPoint , Stream flatMap() , Stream .
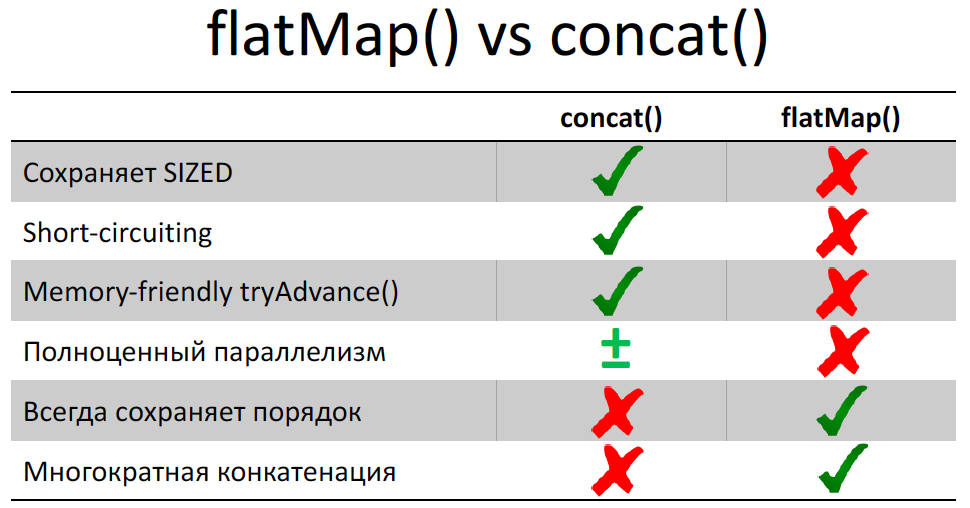
, Stream, Stream , limit() findFirst() – Stream . Stream, . Stream ( ). flatMap() , , Stream, flatMap() , . . , tryAdvance() :

. Stream flatMap() Stream 1 000 000 000 . Stream'a spliterator() tryAdvance() – Stream. – OutOfMemoryError . tryAdvance() , flatMap() — Stream – . JPoint, .
, :
Files.lines(Paths.get<("/etc/passwd")) .spliterator().tryAdvance(...); // , Stream.of(Files.lines(Paths.get("/etc/passwd"))) .flatMap(s -> s) .spliterator().tryAdvance(...); // ,
, spliterator().tryAdvance(), Stream . , BufferedReader . , . , tryAdvance() . flatMap() , , , spliterator . . . – flatMap() , , . , , flatMap . ( flatMap ). JDK, . , Stream , spliterator().tryAdvance(), . . JDK ? , Stream . , flatMap() Stream.

. ? , . , Stream, , . , ? .

0 1 000 000. 1 000 000 , 1 000 000. Stream :

@Benchmark public long count() { return IntStream.rangeClosed(0, 1_000_000).boxed() .filter(x -> x == 1_000_000).count(); } @Benchmark public Optional<Integer> findAny() { return IntStream.rangeClosed(0, 1_000_000).boxed() .filter(x -> x == 1_000_000).findAny(); }
rangeClosed() , . Boxed() , , . . Stream . , , — count() , findAny() . , . , ?
0 1 000 000, - , . . , branch predictor .., .
. - ( ), - ( ). . , :

FindAny() , — 25%. , . , , IntStream.rangeClosed() . — ArrayList . , :
List<Integer> list; @Setup public void setup() { list = IntStream.rangeClosed(0, 1_000_000).boxed() .collect(Collectors.toCollection(ArrayList::new)); } @Benchmark public long count() { return list.stream().filter(x -> x == 1_000_000).count(); } @Benchmark public Optional<Integer> findAny() { return list.stream().filter(x -> x == 1_000_000).findAny(); }
, , ( ):
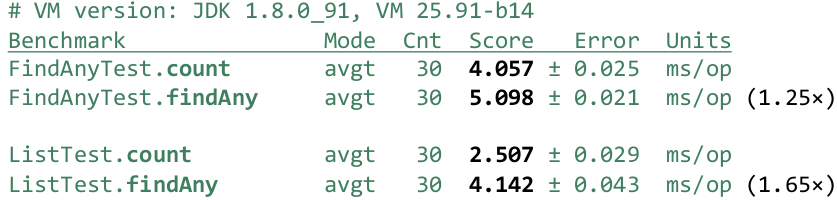
. 65%. . , , Stream, forEachRemaining, , . tryAdvance() — tryAdvance() , , tryAdvance() .
, forEachRemaining spliterator . , ( ), tryAdvance() , , . , , spliterator JIT- , . , modCount() , - , ConcurrentModificationExceptions . forEachRemaining modCount() . tryAdvance() . , tryAdvance() . . Stream , .
, , Stream:
@Benchmark public Optional<Integer> findAny1() { return IntStream.range(0, 1_000_000) .boxed().filter(x -> x == 0).findAny(); } @Benchmark public Optional<Integer> findAny1Flat() { return IntStream.of(1_000_000).flatMap(x -> IntStream.range(0, x)) .boxed().filter(x -> x == 0).findAny(); }
1 000 000, :

83 , . , Stream'a, Stream , , . 54 000 , , .
:

, - . , , forEachRemaining, - «» — , , - , . - forEach , . , , — Consumer , . , . - forEachRemaining ? Exception ?

Exception Control Flow, ( http://c2.com/cgi/wiki?DontUseExceptionsForFlowControl ):

… - ?

— :
static class FoundException extends RuntimeException { Object payload; FoundException(Object payload) { this.payload = payload; } } public static <T> Optional<T> fastFindAny(Stream<T> stream) { try { stream.forEach(x -> { throw new FoundException(x); }); return Optional.empty(); } catch (FoundException fe) { @SuppressWarnings({ "unchecked" }) T val = (T) fe.payload; return Optional.of(val); } }
, RuntimeException , checked . — fastFindAny (). , Stream — , Stream. — , forEach . , forEachRemaining . , Exception . , , , . Exception , — Optinal .
findAny() ? — ? . , , - .
— findAny() «» fastFindAny() .
@Benchmark public Optional<Integer> findAny() { return IntStream.rangeClosed(0, 1_000_000).boxed() .filter(x -> x == 1_000_000).findAny(); } @Benchmark public Optional<Integer> fastFindAny() { return fastFindAny(IntStream.rangeClosed(0, 1_000_000) .boxed().filter(x -> x == 1_000_000)); }
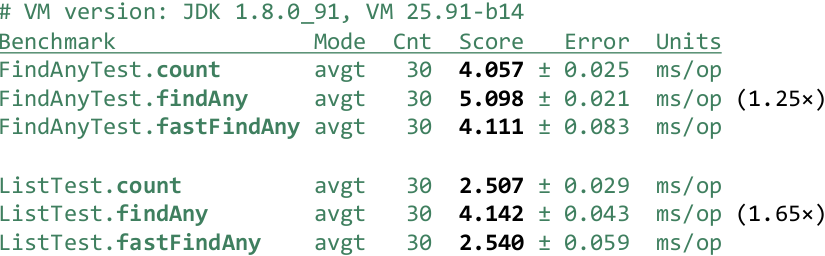
, «» count() , 25-65% . — flatMap() – Stream :

, . 4 000 , 2 . – Stream ( IntStream.rangeClosed ) . 20 . – Exception . , , : - – Exception , . , Stack Trace. Exception Stack Trace . , , – JDK . , :

protected Constructor , RuntimeException , , Stack Trace . :
static class FoundException extends RuntimeException { Object payload; FoundException(Object payload) { super("", null, false, false); // <<<< this.payload = payload; } }
FoundException . :
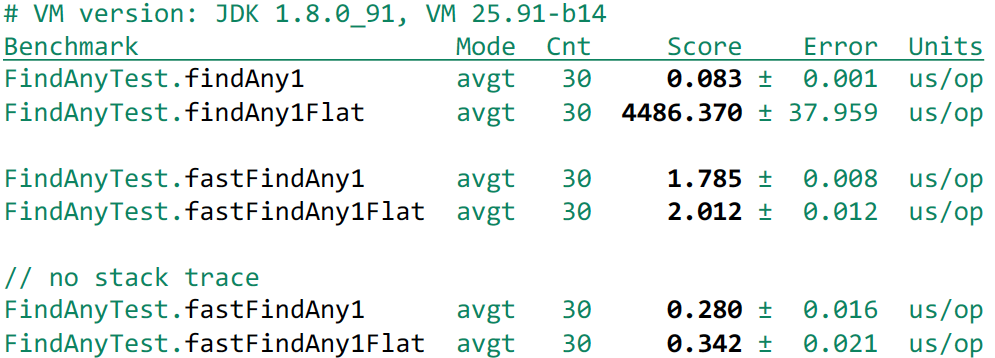
- – 200-300 . overhead , , .
Stream. , , ?
@Benchmark public Optional<Integer> findAnyPar() { return IntStream.range(0, 100_000_000).parallel().boxed() .filter(x -> x == 10_000_000).findAny(); } @Benchmark public Optional<Integer> fastFindAnyPar() { return fastFindAny(IntStream.<i>range</i>(0, 100_000_000) .parallel().boxed().filter(x -> x == 10_000_000)); }
forEach , Stream . .
Benchmark . 4- HT :

, – . その理由は何ですか? , Stream:

:

:
@Param({ "0", "20", "40" }) private int sleep; @Setup(Level.Invocation) public void setup() throws InterruptedException { Thread.sleep(sleep); }
setup – . , :

, , , , – .
, :
AtomicInteger i = new AtomicInteger(); Optional<Integer> result = fastFindAny( IntStream.range(0, 100_000_000).parallel() .boxed().peek(e -> i.incrementAndGet()) .filter(x -> x == 10_000_000)); System.out.println(i); System.out.println(result); Thread.sleep(1000); System.out.println(i);
peek() , . , , 1, , . , . , -:
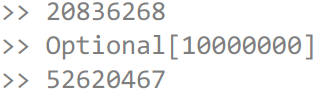
20 000 000 , 50 000 000 . Stream, , . – , . Core-Libs-Dev, – :

, , . , 9 . , Stream , .
, . , , .
, . Stream , , Stream — .
JVM Java 9 , , Joker 2017 :
- Java 9: the good parts (Cay Horstmann, San Jose State University)
- Amazon Alexa vs Google Home : Java ( , JFrog; , CA Technologies)
- Java 9. OSGi? ( , Excelsior LLC)
- ( , )