
エントリー
それでは、Tシャツから始めましょう。 9月1日までに決定を書かなければならず、6番目だけを終えました。
9月1日に結果がまとめられ、場所が割り当てられ、Tシャツが1000秒に会ったすべての人に約束されました。 その後、主催者は決定を改善するために別の週を許可しましたが、賞品はありませんでした。 今回は、決定を書き直すために使用しました(実際、数晩しかありませんでした)。 実際、Tシャツを着るつもりはありませんが、すみません:(
前の記事で、 phpのライブラリを比較してWebソケットサーバーを作成しました。次に、swooleライブラリを推奨しました。C++で記述され、peclからインストールされます。 ところで、これらのライブラリはすべて、Webソケットサーバーを作成するために使用できるだけでなく、単にHTTPサーバーにも適しています。 これを使うことにしました。
swooleライブラリを取得し、メモリ内にsqliteデータベースを作成し、159秒という結果ですぐに上位20に上がった後、シフトし、キャッシュを追加して時間を79秒に短縮し、20に戻り、sqliteからswoole_tableに書き直し、時間を47秒に短縮しました。 もちろん、私は最初の場所からは程遠いものでしたが、Goのソリューションで何人かの友人のテーブルをうまく回りました。
これは、古い評価テーブルの外観です。

Mail.Ruを少し称賛すると、さらに先へ進むことができます。
この素晴らしいチャンピオンシップのおかげで、私はシューラー、労働者のライブラリに精通し、高負荷のためにPHPをより最適化する方法を学び、yandex tankの使い方などを学びました。 このようなチャンピオンシップの手配を続けてください。競争は新しい情報を学び、スキルをアップグレードすることを奨励します。
php vs node.js vs go
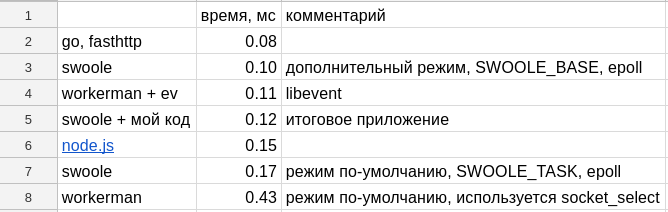
始めるには、C ++で書かれており、phpで書かれているworkermanよりも確実に速く動作するはずなので、私はswoolを使いました。
私はこんにちは世界のコードを書きました:
$server = new Swoole\Http\Server('0.0.0.0', 1080); $server->set(['worker_num' => 1,]); $server->on('Request', function($req, $res) {$res->end('hello world');}); $server->start();
Apache Benchmark Linuxコンソールユーティリティを起動し、10個のスレッドで10,000のリクエストを行います。
ab -c 10 -n 10000 http://127.0.0.1:1080/
応答時間は0.17 msでした
その後、私は労働者の例を書きました:
require_once DIR . '/vendor/autoload.php'; use Workerman\Worker; $http_worker = new Worker("http://0.0.0.0:1080"); $http_worker->count = 1; $http_worker->onMessage = function($conn, $data) {$conn->send("hello world");}; Worker::runAll();
0.43ミリ秒 、つまり 結果は3倍悪くなります。
しかし、私はあきらめず、イベントライブラリをインストールしました。
コードに追加:pecl install event
Worker::$eventLoopClass = '\Workerman\Events\Ev';
最終コード
require_once DIR . '/vendor/autoload.php'; use Workerman\Worker; Worker::$eventLoopClass = '\Workerman\Events\Ev'; $http_worker = new Worker("http://0.0.0.0:1080"); $http_worker->count = 1; $http_worker->onMessage = function($conn, $data) {$conn->send("hello world");}; Worker::runAll();
測定値は0.11 msを示しました。 PHPで記述され、libeventを使用するworkermanは、C ++で記述されたswooleよりも高速です。 Google翻訳の助けを借りて、中国語のドキュメントを大量に読みました。 しかし、何も見つかりませんでした。 ちなみに、両方のライブラリは中国語で書かれており、それらのライブラリコードには中国語でコメントが書かれています-...
通常の練習



これで、中国人が私のコードを読んだときの気持ちがわかりました。
私はこれがどのように起こるのかという質問でswoole githubでチケットを開始しました。
そこで使用することが推奨されました:
$serv = new Swoole\Http\Server('0.0.0.0', 1080, SWOOLE_BASE);
代わりに:
$serv = new Swoole\Http\Server('0.0.0.0', 1080);
最終コード
$serv = new Swoole\Http\Server('0.0.0.0', 1080, SWOOLE_BASE); $serv->set(['worker_num' => 1,]); $serv->on('Request', function($req, $res) {$res->end('hello world');}); $serv->start();
私は彼らのアドバイスを受けて、 0.10 msを得ました。 労働者よりわずかに速い。
この時点で、私はすでにPHPで既製のアプリケーションを持っていましたが、最適化の方法がわかりませんでした。0.12ミリ秒の責任があり、アプリケーションを別のものに書き換えることに決めました。
node.jsを試しました:
const http = require('http'); const server = http.createServer(function(req, res) { res.writeHead(200); res.end('hello world'); }); server.listen(1080);
0.15 msを受信した、つまり 完成したphpアプリケーションより0.03 ms少ない
外出先でfasthttpを取得し、 0.08ミリ秒になりました :
FasthttpのHello World
package main import ( "flag" "fmt" "log" "github.com/valyala/fasthttp" ) var ( addr = flag.String("addr", ":1080", "TCP address to listen to") compress = flag.Bool("compress", false, "Whether to enable transparent response compression") ) func main() { flag.Parse() h := requestHandler if *compress { h = fasthttp.CompressHandler(h) } if err := fasthttp.ListenAndServe(*addr, h); err != nil { log.Fatalf("Error in ListenAndServe: %s", err) } } func requestHandler(ctx *fasthttp.RequestCtx) { fmt.Fprintf(ctx, "Hello, world!") }
要約表( githubで公開されている表とすべてのテスト ):
splfixedarray vs配列
コンテスト終了の1週間前に、状況は少し複雑になりました。
- データ量が10倍に増加
- 1秒あたりのリクエスト数が10倍に増加しました
格納する必要があるデータ構造は、ユーザー(1kk)、場所(1kk)、および訪問(11kk)の3つのテーブルです。
フィールドの説明
ユーザー:
id-ユーザーの一意の外部識別子。 テストシステムによってインストールされ、サーバーの応答を確認するために使用されます。 32ビット符号なし整数。
email-ユーザーのメールアドレス。 タイプは、最大100文字のUnicode文字列です。 一意のフィールド。
first_nameとlast_nameは、それぞれ名と姓です。 タイプ-最大50文字のUnicode文字列。
性別 -unicode-string mは男性を意味し、f-女性を意味します。
birth_date-生年月日。UTCで UNIX時代の初めからの秒数として記録されます(つまり、これはタイムスタンプです)。
場所:
id-アトラクションの一意の外部ID。 テストシステムによってインストールされます。 32ビット符号なし整数。
place-アトラクションの説明。 無制限の長さのテキストフィールド。
country-場所の国の名前。 最大50文字のUnicode文字列。
city-ロケーションの都市の名前。 最大50文字のUnicode文字列。
distance-キロメートル単位の直線での都市からの距離。 32ビット符号なし整数。
訪問:
idは、訪問の一意の外部IDです。 32ビット符号なし整数。
location-アトラクションのID。 32ビット符号なし整数。
user-旅行者のID。 32ビット符号なし整数。
Visited_at-訪問日、タイムスタンプ。
mark -0から5までの訪問の評価。 整数
私の決定は、割り当てられた4GBに収まるのをやめました。 オプションを探す必要がありました。
まず、jsonファイルのメモリに1,100万件のレコードを入力する必要がありました。
swoole_tableを試し、メモリ消費量を測定しました-2200 MB
データダウンロードコード
$visits = new swoole_table(11000000); $visits->column('id', swoole_table::TYPE_INT); $visits->column('user', swoole_table::TYPE_INT); $visits->column('location', swoole_table::TYPE_INT); $visits->column('mark', swoole_table::TYPE_INT); $visits->column('visited_at', swoole_table::TYPE_INT); $visits->create(); $i = 1; while ($visitsData = @file_get_contents("data/visits_$i.json")) { $visitsData = json_decode($visitsData, true); foreach ($visitsData['visits'] as $k => $row) { $visits->set($row['id'], $row); } $i++; } unset($visitsData); gc_collect_cycles(); echo 'memory: ' . intval(memory_get_usage() / 1000000) . "\n";
連想配列を試してみましたが 、メモリ消費量ははるかに大きい-6057 MB
データダウンロードコード
$visits = []; $i = 1; while ($visitsData = @file_get_contents("data/visits_$i.json")) { $visitsData = json_decode($visitsData, true); foreach ($visitsData['visits'] as $k => $row) { $visits[$row['id']] = $row; } $i++;echo "$i\n"; } unset($visitsData); gc_collect_cycles(); echo 'memory: ' . intval(memory_get_usage() / 1000000) . "\n";
SplFixedArrayを試しましたが、メモリ消費量は通常のアレイの消費量よりわずかに少ない-5696 MB
データダウンロードコード
$visits = new SplFixedArray(11000000); $i = 1; while ($visitsData = @file_get_contents("data/visits_$i.json")) { $visitsData = json_decode($visitsData, true); foreach ($visitsData['visits'] as $k => $row) { $visits[$row['id']] = $row; } $i++;echo "$i\n"; } unset($visitsData); gc_collect_cycles(); echo 'memory: ' . intval(memory_get_usage() / 1000000) . "\n";
テキストキーは多くのメモリを占有する可能性があるため、ホテルアレイへの訪問の個々のプロパティを保存することにしました。 このコードを変更しました:
$visits[1] = ['user' => 153, 'location' => 17, 'mark' => 5, 'visited_at' => 1503695452];
これについて:
$visits_user[1] = 153; $visits_location[1] = 17; $visits_mark[1] = 5; $visits_visited_at[1] => 1503695452;
3次元配列を2次元に分割したときのメモリ消費量は-2147 MBでした。 3倍少ない。 T.O. 3次元配列のキー名は、それが占有するすべてのメモリの2/3を食べました。
データダウンロードコード
$user = $location = $mark = $visited_at = []; $i = 1; while ($visitsData = @file_get_contents("data/visits_$i.json")) { $visitsData = json_decode($visitsData, true); foreach ($visitsData['visits'] as $k => $row) { $user[$row['id']] = $row['user']; $location[$row['id']] = $row['location']; $mark[$row['id']] = $row['mark']; $visited_at[$row['id']] = $row['visited_at']; } $i++;echo "$i\n"; } unset($visitsData); gc_collect_cycles(); echo 'memory: ' . intval(memory_get_usage() / 1000000) . "\n";
SplFixedArrayとともに3次元配列の分割を使用することにしましたが 、メモリ消費量がさらに3倍減少し、 704 MBになりました
データダウンロードコード
$user = new SplFixedArray(11000000); $location = new SplFixedArray(11000000); $mark = new SplFixedArray(11000000); $visited_at = new SplFixedArray(11000000); $user_visits = []; $location_visits = []; $i = 1; while ($visitsData = @file_get_contents("data/visits_$i.json")) { $visitsData = json_decode($visitsData, true); foreach ($visitsData['visits'] as $k => $row) { $user[$row['id']] = $row['user']; $location[$row['id']] = $row['location']; $mark[$row['id']] = $row['mark']; $visited_at[$row['id']] = $row['visited_at']; if (isset($user_visits[$row['user']])) { $user_visits[$row['user']][] = $row['id']; } else { $user_visits[$row['user']] = [$row['id']]; } if (isset($location_visits[$row['location']])) { $location_visits[$row['location']][] = $row['id']; } else { $location_visits[$row['location']] = [$row['id']]; } } $i++;echo "$i\n"; } unset($visitsData); gc_collect_cycles(); echo 'memory: ' . intval(memory_get_usage() / 1000000) . "\n";
楽しみのために、 node.jsで同じことを試し、 780 MBを取得しました
データダウンロードコード
const fs = require('fs'); global.visits = []; global.users_visits = []; global.locations_visits = []; let i = 1; let visitsData; while (fs.existsSync(`data/visits_${i}.json`) && (visitsData = JSON.parse(fs.readFileSync(`data/visits_${i}.json`, 'utf8')))) { for (y = 0; y < visitsData.visits.length; y++) { //visits[visitsData.visits[y]['id']] = visitsData.visits[y]; visits[visitsData.visits[y]['id']] = { user:visitsData.visits[y].user, location:visitsData.visits[y].location, mark:visitsData.visits[y].mark, visited_at:visitsData.visits[y].visited_at, //id:visitsData.visits[y].id, }; } i++; } global.gc(); console.log("memory usage: " + parseInt(process.memoryUsage().heapTotal/1000000));
要約表( 表とgithubで公開されたすべてのテスト ):

apc_cacheとredisを試してみたかったのですが、キー名を保存するためにメモリを追加で使用します。 実際には使用できますが、このチャンピオンシップではまったく選択肢ではありません。
あとがき
すべての最適化の後、合計時間は404秒でした。これは、最初の場所よりもほぼ4倍遅いです。
夜に眠れなかったオーガナイザーに再び感謝し、吊り下げられたコンテナをリロードし、バグを修正し、サイトを完成させ、電報で質問に答えました。
すべてのテストの実際のサマリーテーブルと同様のコードは、githubで公開されています。
異なるWebサーバーの速度の比較
異なる構造によるメモリ消費の比較
今日のHabrに関する他の記事: クラウド内の無料サーバー