
こんにちは、Habr! 今日は、ゼロから集まった人々との会話に基づいて履歴書を作成できるチャットボットの頭脳について話します。 それは、このケースのために書かれた自転車がどのように発展したのか、途中でどのような困難に直面し、これらの困難を克服するためにどのように変化したのかについてです。 説明されているすべてのイベントは、2017年のHeadHunter School of Programmersでのトレーニング中に行われました。 誰が気に - あなたがカットの下で歓迎されています。
背景
HeadHunterでの(おそらく最も重要な)トレーニングの一部は、チームプロジェクトの開発です。 私たちのチームは、ユーザーに質問し、ユーザーの回答に基づいて概要をまとめ、hh.ruで公開するTelegramのボットを作成しました。 1人が主に電報APIのラッピングとそのクールな機能の使用に従事し、もう1人がCI / CD、データベースなどに従事し、ボットの頭脳を手に入れるように、タスクを私たちの間で分割しました。 この記事では、時間の不足、スキル、チームワークの質の問題を残します。それらは、かなり重要でしたが、それについてではありません。 また、/ start、/ skipなどの処理サービスコマンドの説明もスキップします。これらはストーリーを複雑にするだけだからです。 ユーザーに対して次の質問を生成するコンポーネントについて説明します。
ステージ1:Hello World!
この段階では、私たちの注意は他のものに集中していたので、もっとも簡単なことはもっともらしい質問を生成するために書かれました。 起こったことは次のとおりです。
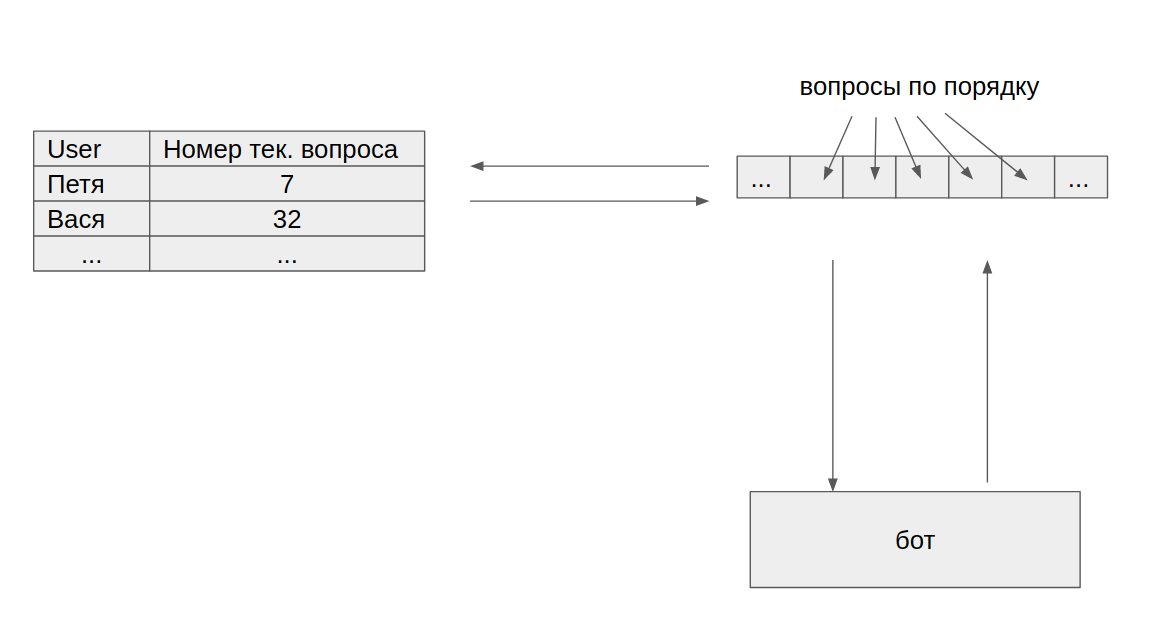
- 質問は配列に保存されます。 配列は静的ブロックに配置されます。
- 現在の質問の番号はプレートに保存されています。
- アクセスすると、現在の質問の番号がプレートでインクリメントされ、そのようなインデックスを持つ配列要素が返されます
すぐに、質問リストのハードコードはあまり良くないことが明らかになり、少なくともファイルからこのリストをロードする必要があるでしょう。 さらに、「質問」の本質にはすでに質問のテキストとその回答が含まれており、この本質の構造が幅と深さの両方で拡大することは非常に明白でした。 完全にフィット XML形式を使用することにしました。 このフォームでは、作業開始の1か月後に、このコンポーネントは最初のデモに合格しました。
最初のバージョンの合計:
- 長所:
- 非常に簡単かつ迅速に実装できます。
- 短所:
- インデックスを使用して余分な操作を行わないと、機能が少なすぎます(ブランチとループのサポートはありません)。
- さらにインデックスを想起させると、まったく安全ではないことがわかります。 このような操作のエラーと不正確さが、ボットの非常に奇妙な動作を引き起こしました。
ステージ2:分岐、順次アクセス
前の段落の解決策を見て、その欠点について考えた後、会話のブロック図に移行することが決定されました。 このモデルを理解するのはもう少し困難でしたが、まず、任意の複雑さの会話アルゴリズムを実装できました。次に、1つのパブリックメソッドのみが突き出ています-次の質問を取得します。
最初に、次の2つのメインブロックが実装されました。
しかし、ブロックはより複雑な構造に組み合わせることができるということは既に理解されていました。 そのような構造は、同じインターフェース(1つの方法で次の質問を取得すること)を実装し、同時にいくつかの基本ブロックを組み合わせることができます。 そのような構成の例は、3つの結果の条件とループです。
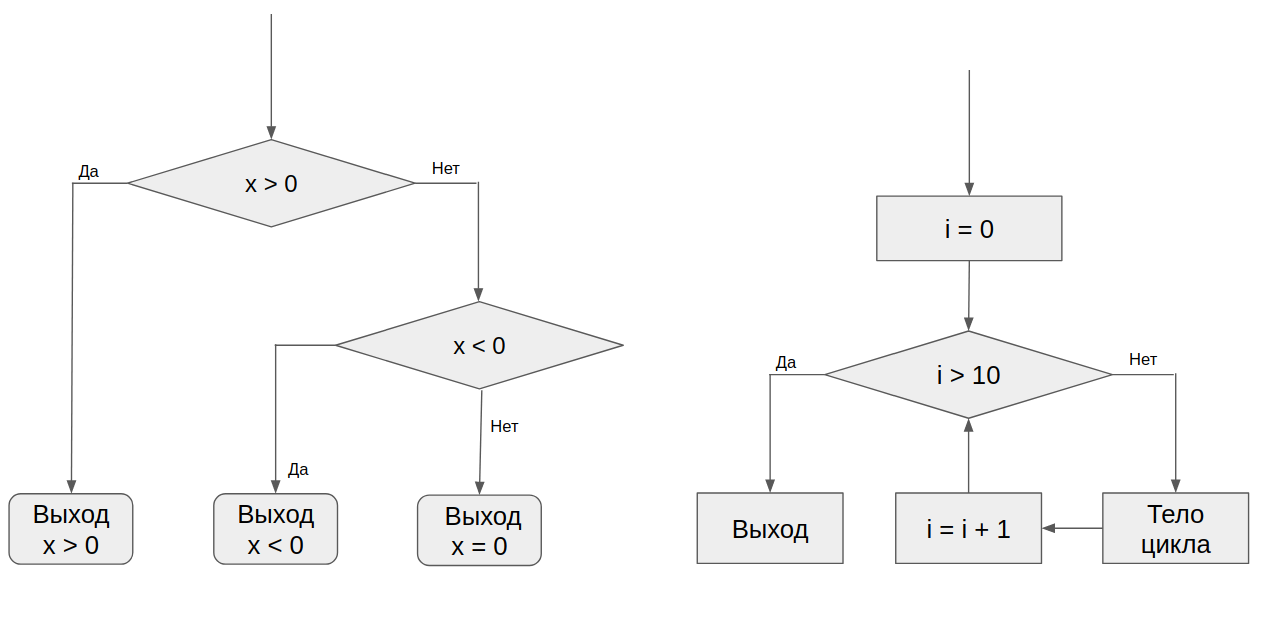
ボットにはそのような構造の特に大きな動物園はありませんでしたが、コードを記述する際のこの可能性は考慮されていました。
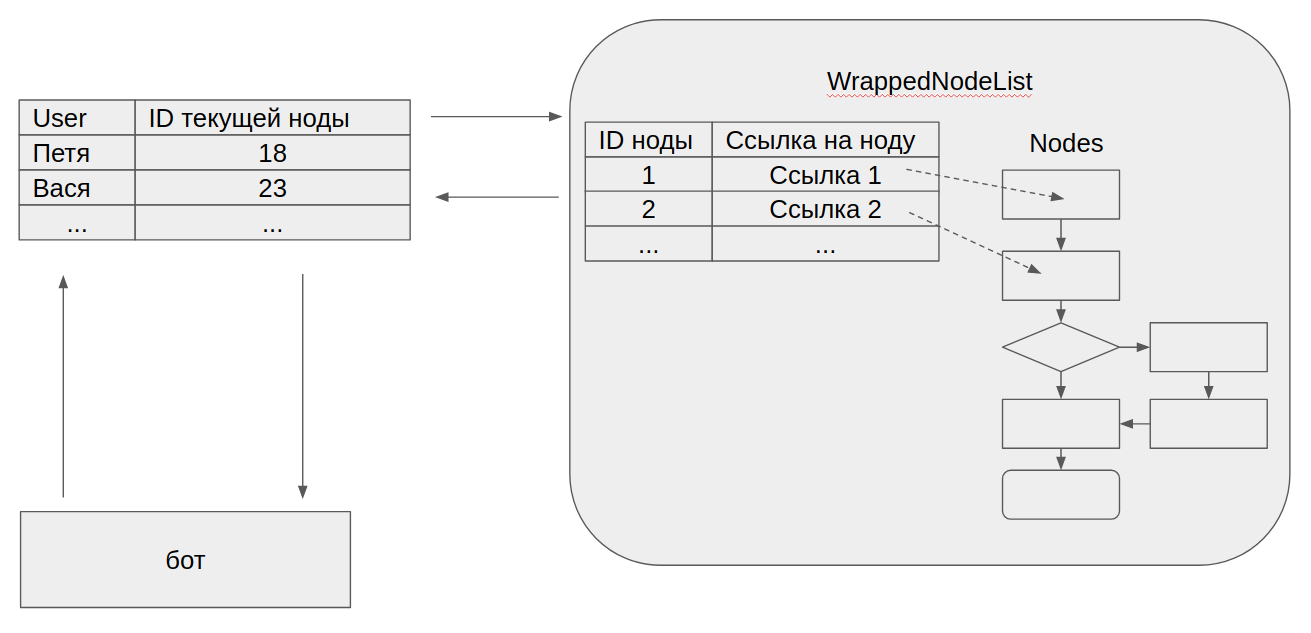
しかし、これは2番目のデモで示したコンポーネントの一般的なスキームであることが判明しました。
- 各質問はノードの一部です。 ノードインターフェイスは、1つのメソッドgetNext()で構成されています。
- ユーザーのコンテキストでは、現在のノードへのリンクが保存されます。
- 現在のノードにアクセスすると、getNext()が呼び出され、結果が返されてユーザーのコンテキストに保存されます

このようなアンケートのあるボットが2番目のデモで示されました。 2番目のバージョンの合計:
- 長所:
- 分岐、ループなどをサポートします。
- よくカプセル化されています。
- 短所:
- ユーザーコンテキストはシリアル化されません。 アプリケーションがクラッシュした場合、ユーザーコンテキストは間接的な標識によってのみ復元できますが、これは難しく、常に可能ではありません。
- 地獄の門はXMLパーサーコードで開き始めます。
ステージ3:より多くのXMLが必要
XML解析が3つのブロック(フォロー、ブランチ、ループ)について書かれたとき、パーサーで何かを行う必要があることが明らかになりました。 コードはスパゲッティに変わり、新しいブロックの追加には非常に時間がかかりました。 Googleで最初に出てきたオプションであるjaxbは、簡単な検査で、ほとんどタスクを引き出せませんでした。 タスクはこれでした。ノードのリストを解析し、各ノードはそのクラス(属性で示されます)で表され、以前は不明なフィールドのリストを含みます。 フィールドのタイプはインターフェイスにすることもできます。その場合、正確なフィールドクラスもXMLファイルで示されます。 ブラックジャックとリフレクションを使用して独自のパーサーを作成することにしました。 結果のパーサーのコアは次のようになりました。
Object getInstance(XMLTag xmlTag) { if (xmlTag.getName() in simpleClassInstantiators.keySet()) { return simpleClassInstantiators.get(xmlTag.getName()) .instantiate(); } String fullClassName = classpaths.get(xmlTag.getName()) + xmlTag.getAttr(“class”); Object result = InstantiateWithReflection(fullClassName); for (XMLTag child : xmlTag.getChildren()) { Object childObject = getInstance(child); setFieldWithReflection(result, child.getAttr(“fieldName”), childObject); } return result; } List<Node> getNodeList(XMLTag xmlRootTag) { return xmlRootTag.getChildren().stream() .map(x -> getInstance(x)) .map(x -> (Node)x) .collect(Collectors.toList()); }
このようなXMLパーサーは、次の規則に従って機能しました。
- 各XMLタグは、「単純な」クラスのリスト、または「複雑な」リストのいずれかになければなりません。 これらのリストにタグがない場合、エラーが発生します。
- インスタンスは、「単純な」リストから各タグ名ごとに記述する必要があります。
- クラス構造の「複雑な」リストの各タグ名には、1つのインターフェースを実装するクラスを含むパッケージが必要です。 この場合、これらのクラスのいずれかの名前はクラス属性と一致する必要があります。
- [オプション]「複雑な」方法で作成されたクラスごとに、必須フィールドのリストを指定できます。
両方のリストは静的ブロックで初期化されました。 その結果、次のアルゴリズムに従って、新しいタイプのノードの追加または既存のノードの構造の変更が行われました。
- メインコードを変更します(XMLからの読み取りを除く)。
- ソースXMLファイルに変更を加えます。
- 新しいインターフェイスが追加され、それを実装するクラスが新しい(または変更された)ノードのフィールドで使用される場合、「複雑な」リストにエントリを追加します。
- 新しい比較的プリミティブなタイプが追加された場合、そのインストーラーを作成し、それを「シンプル」リストに追加します。
同時に、最後の2つのポイントはテストされましたが、ボットの作成時には使用されませんでした。 「複雑な」型のインターフェースのリストは変更されず、プリミティブ型のインスタンス生成子はすぐに記述されました。 すなわち 必要なクラスとXMLファイルの構造を変更しただけで、ステージ2と比較して大幅に改善されました。
第2段階で残った問題は、XMLからの読み取りの難しさだけではありませんでした。 きしむ音でボットにデータベースをねじ込んだとき、各ユーザーの現在のノードへのリンクを保存できないことがわかりました。 再起動後にボットがユーザーの現在の状態を復元できない場合に限ります。 コンポーネントの現在の構造は変更せず、ノードのIDを正しく操作する方法を知っているクラスに単純にラップしました。 これには劇的な構造変更は必要ありませんでした。
その結果、3番目の(最後の)コンポーネントのデモ構造は次のようになりました。
3番目のバージョンの合計:
- 長所:
- 複雑な会話アルゴリズムをサポートします。
- ユーザーコンテキストはシリアル化されます=>クラッシュトレランスが表示されます。
- 新しいタイプのノードを追加し、既存のノードの構造を変更します。 簡単になり、XMLパーサーの根底を掘る必要がありません。
- 短所
- XMLパーサーでは、コードをクラス構造にバインドする規則の実行が必要です。
ステージ4.永遠、マルチスレッド、スケーラビリティなどに関する考察
魚に羊毛があった場合 ボットが実稼働に入った場合、遅かれ早かれ、開発中に船外に残されたいくつかの追加の問題が発生します。 それにもかかわらず、それらについてはかなり多くのことが言われたので、ここでそれらについて書きます。
最初に、質問のリストが変更された場合の対処方法について、質問が1回または2回以上提起されました。 最後に、アンケートをその場で安全に任意の方法で変更できるメカニズムを作成するのは猫の問題であると判断しました。必要はなく、どのように不明なのか。 同時に、XMLからアンケートを再読み込みする機能は、それでも小さな変更の場合にはありましたが、この可能性は特にテストされていませんでした。 変更はすべてのユーザーにすぐに適用されました。
第二に、単一のスレッドでは明らかに不十分です。 マルチスレッドに関連する潜在的な問題を解決するために、さまざまなスキームが提案されています。
- アンケートの同期方法。
- 登録時に各ユーザーのアンケートをコピーします。
- 要件スレッドセーフノード。
- ノードを要求する場合、各ユーザーに対して、標準(または標準のプール)からノードを同期的にコピーします。
- など
しかし、これらのスキームの1つを選択する(さらに実装する)時間がありませんでした。
第三に、すでに前回のデモで、水平スケーリングの問題が提起されました。 ここでボットは私たちを失望させませんでした:すべてのノード(アンケートを含む)は、ボックスからの水平スケーリングだけでなく(必要に応じて)マイクロサービスに分割できるように設計されました。
結果は何ですか?
その結果、シンプルなチャットボットがいっぱいになりました。 履歴書へのインタビュー自体は難しい作業ではないため、シンプルです。 しかし、この形式でも、このコンポーネントには拡張性のための大きなリソースがあります。 ほぼすべての複雑なユーザーとの会話を記述することができます。 フローチャート設計のおかげで、XMLファイルの編集をビジュアルエディターで比較的簡単に置き換えることができます(実際、これは計画に含まれていましたが、時間がありませんでした)。 容易に拡張可能なXML構造のおかげで、新しい機能をすばやく追加できます(たとえば、質問テキストのいくつかのバリエーションを使用)。 また、ボットはボックスから水平方向のスケーラビリティを受け取り、マルチスレッドの作業を追加するための労力をほとんど必要としませんでした。 ボットのコンポーネントは非常によく絶縁されており、マイクロサービスに分割できます。 マイナスのうち、最も深刻なのは、オンザフライでアンケートを変更できないことでした。 この機能の追加には非常に時間がかかり、大きなアーキテクチャのレビューが必要になります。