はじめに
過去数年にわたって、コンピュータービジョン(CV)の分野では、2番目の誕生ではないにしても、それから大きな自己利益が生じています。 多くの点で、この人気の増加は、ニューラルネットワークテクノロジーの進化に関連しています。 たとえば、畳み込みニューラルネットワーク(CNN)は、従来のCVメソッド(HOG、SIFT、RANSACなど)によって以前に解決された機能を生成するためのタスクの大きなチャンクを選択しました。
マッピング、画像分類、ドローンと無人車両のルートの構築-特徴の生成、分類、画像セグメンテーションに関連する多くのタスクは、畳み込みニューラルネットワークを使用して効果的に解決できます。

ニューラルネットワーク(3 in 1)の例としてのMultiNet。次の投稿のいずれかで使用します。 出所
読者はニューラルネットワークの動作について一般的な理解を持っていることが前提となります。 ネットワークには、このトピックに関する膨大な数の投稿、コース、書籍があります。 例:
- 第6章:Deep Feedforward Networksは、I。Goodfellow、Y.Bengio、およびA.CourvilleによるDeep Learning本の章です。 強くお勧めします。
- 視覚認識のためのCS231n畳み込みニューラルネットワークは、スタンフォード大学のFei-Fei LiとAndrej Karpathyの人気のあるコースです。 このコースには、実践とデザインに焦点を当てた優れた資料が含まれています。
- ディープラーニング -オックスフォードのナンドデフレイタスのコース。
- 機械学習入門-初心者向けの無料のUdacityコースで、教材に簡単にアクセスできるプレゼンテーションは、機械学習の多くのトピックをカバーしています。
ヒント:ニューラルネットワークの基本を確実に理解するには 、ネットワークを最初から記述して、それを試してください!
このシリーズの記事では、基本を繰り返す代わりに、STN(空間変換ネットワーク)、IDSIA(交通標識を分類するたたみ込みニューラルネットワーク)、自動操縦のエンドツーエンド開発用のNVIDIAのニューラルネットワーク、および認識用のMultiNetに焦点を当てています。道路標示および標識の分類。 さあ始めましょう!
この記事のトピックは、画像の前処理のためのいくつかのツールを示すことです。 通常、一般的なパイプラインは特定のタスクに依存しますが、ツールについて詳しく説明します。 ニューラルネットワークは、メディアで提示するのが好きな魔法のブラックボックスではありません。データをグリッドに取り込んで「ドロップ」し、魔法の結果を待つことはできません。 たわごとのルールによって-せいぜい、たわごとは、あなたが数ポイント悪いスコアを取得します。 そして、ほとんどの場合、ネットワークをトレーニングすることができず、バッチの正規化やドロップアウトなどの流行のテクニックは役に立ちません。 したがって、作業はデータから開始する必要があります:データのクリーニング、正規化、正規化。 さらに、回転、シフト、ズームなどのアフィン変換を使用した元の画像データセットの拡張(データ拡張)を検討する価値があります:オーバーフィットの可能性を減らし、変換に対するより良い分類器不変性を提供します。
ツール1:データの視覚化と調査
これと次の投稿の一部として、ドイツの交通標識認識データセットであるGTSRBを使用します。 私たちのタスクは、GTSRBのタグ付きデータを使用して道路標識の分類器をトレーニングすることです。 一般に、利用可能なデータのアイデアを得る最良の方法は、列車、検証および/またはテストデータセットの分布のヒストグラムを構築することです:
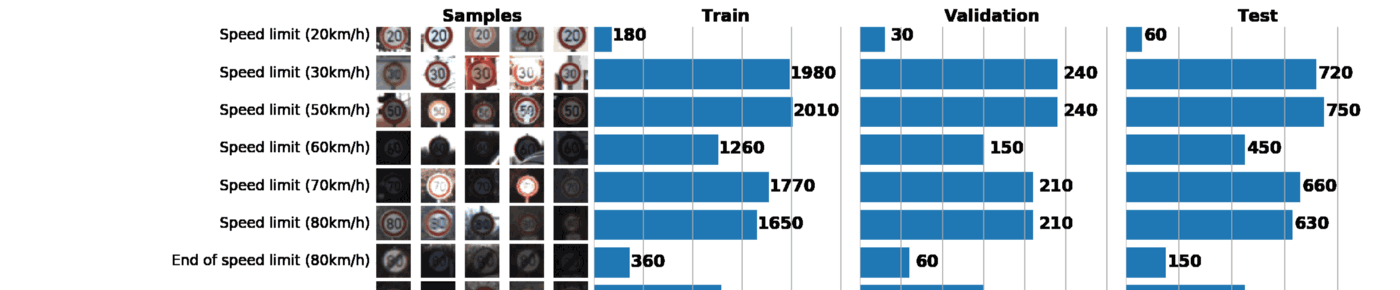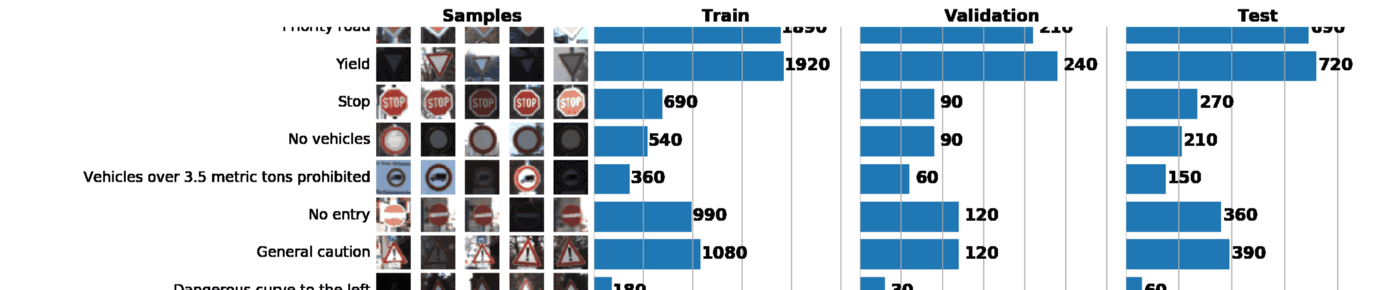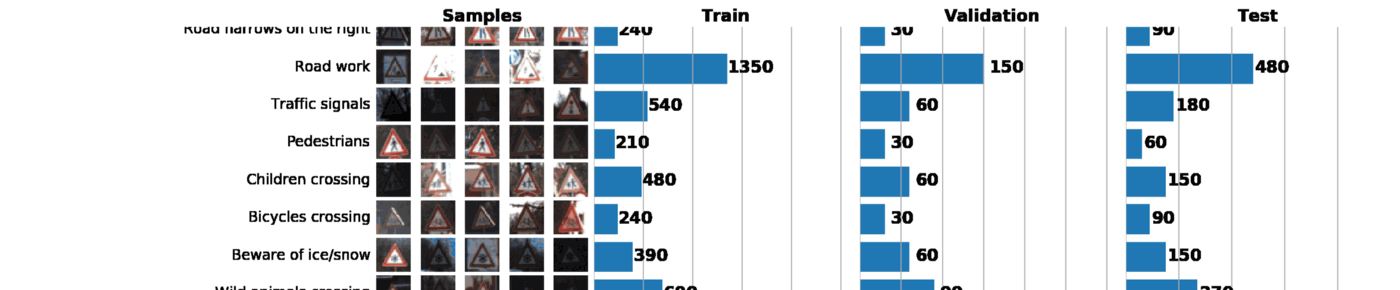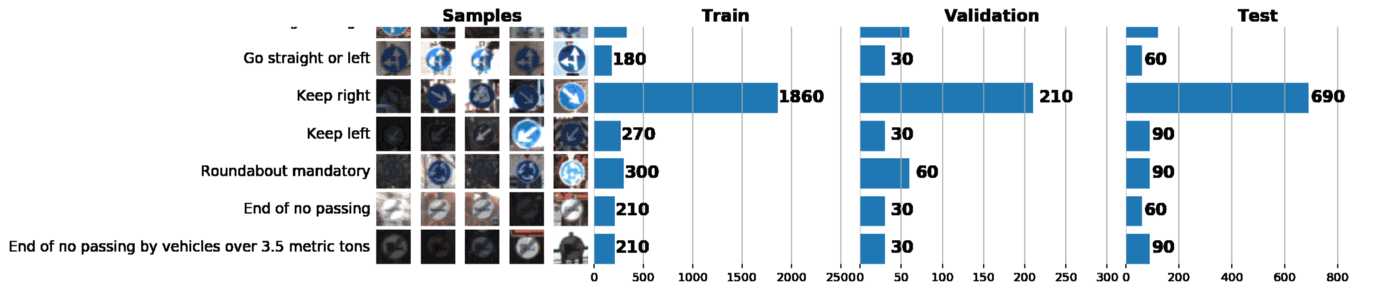
データセットに関する基本情報:
Number of training examples = 34799 Number of validation examples = 4410 Number of testing examples = 12630 Image data shape = (32, 32, 3) Number of classes = 43
この段階では、
matplotlib
はあなたの親友です。
pyplot
のみを使用するとデータを完全に視覚化できるという事実にもかかわらず、
matplotlib.gridspec
では3つのグラフをマージでき
matplotlib.gridspec
。
gs = gridspec.GridSpec(1, 3, wspace=0.25, hspace=0.1) fig = plt.figure(figsize=(12,2)) ax1, ax2, ax3 = [plt.subplot(gs[:, i]) for i in range(3)]
Gridspec
非常に柔軟です。 たとえば、前述のように、ヒストグラムごとに幅を設定できます。
Gridspec
は、各ヒストグラムの軸を他のヒストグラムとは独立して考慮します。これにより、洗練されたグラフを作成できます。

その結果、1つのグラフだけでデータセットについて多くのことがわかります。 以下は、適切に構成されたスケジュールで解決できる3つのタスクです。
- 画像の視覚化。 グラフには、暗すぎたり明るすぎたりする多くの画像がすぐに表示されるため、明るさの変動をなくすために何らかのデータ正規化を実行する必要があります。
- サンプルの不均衡を確認します。 サンプルでクラスのインスタンスが優先される場合、 アンダーサンプリングまたはオーバーサンプリングメソッドを使用する必要があります。
- サンプルの訓練、検証、およびテスト分布が類似していることを確認します。 これは、上のヒストグラムを見るか、 スピアマンの順位相関係数を使用して確認できます。 (
scipy
経由)
ツール2:scikit-image用のIPython Parallel
ニューラルネットワークの収束を改善するには、色域をグレースケールに変換することで( LeCunの道路標識の認識に関する記事で推奨されているように)すべての画像を単一の照明にする必要があります。 これは、OpenCVを使用するか、pipを使用して簡単にインストールできる優れたPythonライブラリ
scikit-image
を使用して実行できます(OpenCVでは、多数の依存関係を使用した自己コンパイルが必要です)。 画像のコントラストは、 適応ヒストグラム均等化(CLAHE)を使用して正規化されます。
skimage.exposure.equalize_adapthist
skimage
は1つのプロセッサコアのみを使用して画像を
skimage
処理することに注意してください。これは明らかに非効率的です。 画像の前処理を並列化するには、IPython Parallel(
ipyparallel
)
ipyparallel
を使用し
ipyparallel
。 このライブラリの利点の1つは、その単純さです。わずか数行のコードで並列化されたCLAHEを実装できます。 最初に、コンソールで(
ipyparallel
インストールされている)、ローカルipyparallelクラスターを開始します。
$ ipcluster start

並列化のアプローチは非常に簡単です。サンプルをバッチに分割し、各バッチを他のバッチとは無関係に処理します。 すべてのバッチが処理されるとすぐに、それらを1つのデータセットにマージします。 私のCLAHEの実装は次のとおりです。
from skimage import exposure def grayscale_exposure_equalize(batch_x_y): """Processes a batch with images by grayscaling, normalization and histogram equalization. Args: batch_x_y: a single batch of data containing a numpy array of images and a list of corresponding labels. Returns: Numpy array of processed images and a list of labels (unchanged). """ x_sub, y_sub = batch_x_y[0], batch_x_y[1] x_processed_sub = numpy.zeros(x_sub.shape[:-1]) for x in range(len(x_sub)): # Grayscale img_gray = numpy.dot(x_sub[x][...,:3], [0.299, 0.587, 0.114]) # Normalization img_gray_norm = img_gray / (img_gray.max() + 1) # CLAHE. num_bins will be initialized in ipyparallel client img_gray_norm = exposure.equalize_adapthist(img_gray_norm, nbins=num_bins) x_processed_sub[x,...] = img_gray_norm return (x_processed_sub, y_sub)
変換自体の準備ができたので、トレーニングセットの各バッチに適用するコードを記述します。
import multiprocessing import ipyparallel as ipp import numpy as np def preprocess_equalize(X, y, bins=256, cpu=multiprocessing.cpu_count()): """ A simplified version of a function which manages multiprocessing logic. This function always grayscales input images, though it can be generalized to apply any arbitrary function to batches. Args: X: numpy array of all images in dataset. y: a list of corresponding labels. bins: the amount of bins to be used in histogram equalization. cpu: the number of cpu cores to use. Default: use all. Returns: Numpy array of processed images and a list of labels. """ rc = ipp.Client() # Use a DirectView object to broadcast imports to all engines with rc[:].sync_imports(): import numpy from skimage import exposure, transform, color # Use a DirectView object to set up the amount of bins on all engines rc[:]['num_bins'] = bins X_processed = np.zeros(X.shape[:-1]) y_processed = np.zeros(y.shape) # Number of batches is equal to cpu count batches_x = np.array_split(X, cpu) batches_y = np.array_split(y, cpu) batches_x_y = zip(batches_x, batches_y) # Applying our function of choice to each batch with a DirectView method preprocessed_subs = rc[:].map(grayscale_exposure_equalize, batches_x_y).get_dict() # Combining the output batches into a single dataset cnt = 0 for _,v in preprocessed_subs.items(): x_, y_ = v[0], v[1] X_processed[cnt:cnt+len(x_)] = x_ y_processed[cnt:cnt+len(y_)] = y_ cnt += len(x_) return X_processed.reshape(X_processed.shape + (1,)), y_processed
最後に、書かれた関数をトレーニングセットに適用します。
# X_train: numpy array of (34799, 32, 32, 3) shape # y_train: a list of (34799,) shape X_tr, y_tr = preprocess_equalize(X_train, y_train, bins=128)
その結果、1つではなく、すべてのプロセッサコア(私の場合は32)を使用し、パフォーマンスが大幅に向上しています。 受信した画像の例:

画像の正規化とグレースケールでの配色の転送の結果

RGB画像の分布の正規化(rc [:]に別の関数を使用しました。マップ)
これで、データの前処理プロセス全体に数十秒かかるため、間隔の数
num_bins
さまざまな値をテストして視覚化し、最適なものを選択できます。

num_bins:8、32、128、256、512
より多くの
num_bins
選択すると、画像のコントラストが増加すると同時に、背景が強く強調されるため、データがノイズの多いものになります。
num_bins
異なる値を使用して、データセットのコントラストをコントラストで補強し、画像の背景によりニューラルネットワークが再トレーニングされないようにすることもできます。
最後に、ipython magic
%store
を使用して、結果を将来の参照用に保存します。
# Same images, multiple bins (contrast augmentation) %store X_tr_8 %store y_tr_8 # ... %store X_tr_512 %store y_tr_512
ツール3:オンラインデータ拡張
サンプルにさまざまな新しいデータを追加すると、ニューラルネットワークの再トレーニングの可能性が低くなることは周知の事実です。 この場合、回転、鏡面反射、アフィン変換を使用して既存の画像を変換することにより、人工画像を構築できます。 サンプル全体に対してこのプロセスを実行し、結果を保存して使用できるという事実にもかかわらず、よりエレガントな方法は、新しい画像をその場で(オンラインで)作成して、データ拡張パラメーターをすばやく調整できるようにすることです。
まず、
numpy
と
skimage
を使用して、計画されているすべての変換を示します。
import numpy as np from skimage import transform from skimage.transform import warp, AffineTransform def rotate_90_deg(X): X_aug = np.zeros_like(X) for i,img in enumerate(X): X_aug[i] = transform.rotate(img, 270.0) return X_aug def rotate_180_deg(X): X_aug = np.zeros_like(X) for i,img in enumerate(X): X_aug[i] = transform.rotate(img, 180.0) return X_aug def rotate_270_deg(X): X_aug = np.zeros_like(X) for i,img in enumerate(X): X_aug[i] = transform.rotate(img, 90.0) return X_aug def rotate_up_to_20_deg(X): X_aug = np.zeros_like(X) delta = 20. for i,img in enumerate(X): X_aug[i] = transform.rotate(img, random.uniform(-delta, delta), mode='edge') return X_aug def flip_vert(X): X_aug = deepcopy(X) return X_aug[:, :, ::-1, :] def flip_horiz(X): X_aug = deepcopy(X) return X_aug[:, ::-1, :, :] def affine_transform(X, shear_angle=0.0, scale_margins=[0.8, 1.5], p=1.0): """This function allows applying shear and scale transformations with the specified magnitude and probability p. Args: X: numpy array of images. shear_angle: maximum shear angle in counter-clockwise direction as radians. scale_margins: minimum and maximum margins to be used in scaling. p: a fraction of images to be augmented. """ X_aug = deepcopy(X) shear = shear_angle * np.random.rand() for i in np.random.choice(len(X_aug), int(len(X_aug) * p), replace=False): _scale = random.uniform(scale_margins[0], scale_margins[1]) X_aug[i] = warp(X_aug[i], AffineTransform(scale=(_scale, _scale), shear=shear), mode='edge') return X_aug
スケーリングとランダム回転
rotate_up_to_20_deg
は、元のクラスへの画像の帰属を維持しながら、サンプルのサイズを増加させます。 反射(フリップ)および90、180、270度の回転は、反対に、記号の意味を変える可能性があります。 そのような遷移を追跡するには、各道路標識とそれらが変換されるクラスの可能な変換のリストを作成します(以下はそのようなリストの一部の例です):
| label_class | label_name | rotate_90_deg | rotate_180_deg | rotate_270_deg | flip_horiz | flip_vert |
|---|---|---|---|---|---|---|
| 13 | 収量 | 13 | ||||
| 14 | やめて | |||||
| 15 | 車両なし | 15 | 15 | 15 | 15 | 15 |
| 16 | 乗り物
3.5トン 禁止されている | |||||
| 17 | エントリーなし | 17 | 17 | 17 |
列見出しは前に定義した変換関数の名前に対応しているため、処理中に変換を追加できます。
import pandas as pd # Generate an augmented dataset using a transform table augmentation_table = pd.read_csv('augmentation_table.csv', index_col='label_class') augmentation_table.drop('label_name', axis=1, inplace=True) augmentation_table.dropna(axis=0, how='all', inplace=True) # Collect all global functions in global namespace namespace = __import__(__name__) def apply_augmentation(X, how=None): """Apply an augmentation function specified in `how` (string) to a numpy array X. Args: X: numpy array with images. how: a string with a function name to be applied to X, should return the same-shaped numpy array as in X. Returns: Augmented X dataset. """ assert augmentation_table.get(how) is not None augmentator = getattr(namespace, how) return augmentator(X)
これで、
augmentation_table.csv
にリストされている使用可能なすべての関数(変換)をすべてのクラスに適用するパイプラインを構築できます。
import numpy as np def flips_rotations_augmentation(X, y): """A pipeline for applying augmentation functions listed in `augmentation_table` to a numpy array with images X. """ # Initializing empty arrays to accumulate intermediate results of augmentation X_out, y_out = np.empty([0] + list(X.shape[1:]), dtype=np.float32), np.empty([0]) # Cycling through all label classes and applying all available transformations for in_label in augmentation_table.index.values: available_augmentations = dict(augmentation_table.ix[in_label].dropna(axis=0)) images = X[y==in_label] # Augment images and their labels for kind, out_label in available_augmentations.items(): X_out = np.vstack([X_out, apply_augmentation(images, how=kind)]) y_out = np.hstack([y_out, [out_label] * len(images)]) # And stack with initial dataset X_out = np.vstack([X_out, X]) y_out = np.hstack([y_out, y]) # Random rotation is explicitly included in this function's body X_out_rotated = rotate_up_to_20_deg(X) y_out_rotated = deepcopy(y) X_out = np.vstack([X_out, X_out_rotated]) y_out = np.hstack([y_out, y_out_rotated]) return X_out, y_out
いいね! これで、2つの既製のデータ拡張関数ができました。
-
affine_transform
:回転なしのカスタマイズ可能なアフィン変換(回転はアフィン変換の1つであるため、選択した名前はあまり成功していません)。 -
flips_rotations_augmentation
:画像クラスを変更するaugmentation_table.csv
基づくランダムな回転と変換。
最後の手順は、バッチジェネレーターを作成することです。
def augmented_batch_generator(X, y, batch_size, rotations=True, affine=True, shear_angle=0.0, scale_margins=[0.8, 1.5], p=0.35): """Augmented batch generator. Splits the dataset into batches and augments each batch independently. Args: X: numpy array with images. y: list of labels. batch_size: the size of the output batch. rotations: whether to apply `flips_rotations_augmentation` function to dataset. affine: whether to apply `affine_transform` function to dataset. shear_angle: `shear_angle` argument for `affine_transform` function. scale_margins: `scale_margins` argument for `affine_transform` function. p: `p` argument for `affine_transform` function. """ X_aug, y_aug = shuffle(X, y) # Batch generation for offset in range(0, X_aug.shape[0], batch_size): end = offset + batch_size batch_x, batch_y = X_aug[offset:end,...], y_aug[offset:end] # Batch augmentation if affine is True: batch_x = affine_transform(batch_x, shear_angle=shear_angle, scale_margins=scale_margins, p=p) if rotations is True: batch_x, batch_y = flips_rotations_augmentation(batch_x, batch_y) yield batch_x, batch_y
num_bins
内の異なる数の
num_bins
持つデータセットを1つの大きなトレインに結合することにより、結果のジェネレーターに送り込みます。 これで、2種類の拡張機能があります。対照的に、オンザフライでバッチに適用されるアフィン変換の助けを借りて:

Augmented_batch_generatorイメージを使用して生成
注:列車セットには増強が必要です。 テストセットを前処理しますが、拡張はしません。
元のデータセットと比較して、拡張トレインのクラスの分布に誤って違反していないことを確認しましょう。
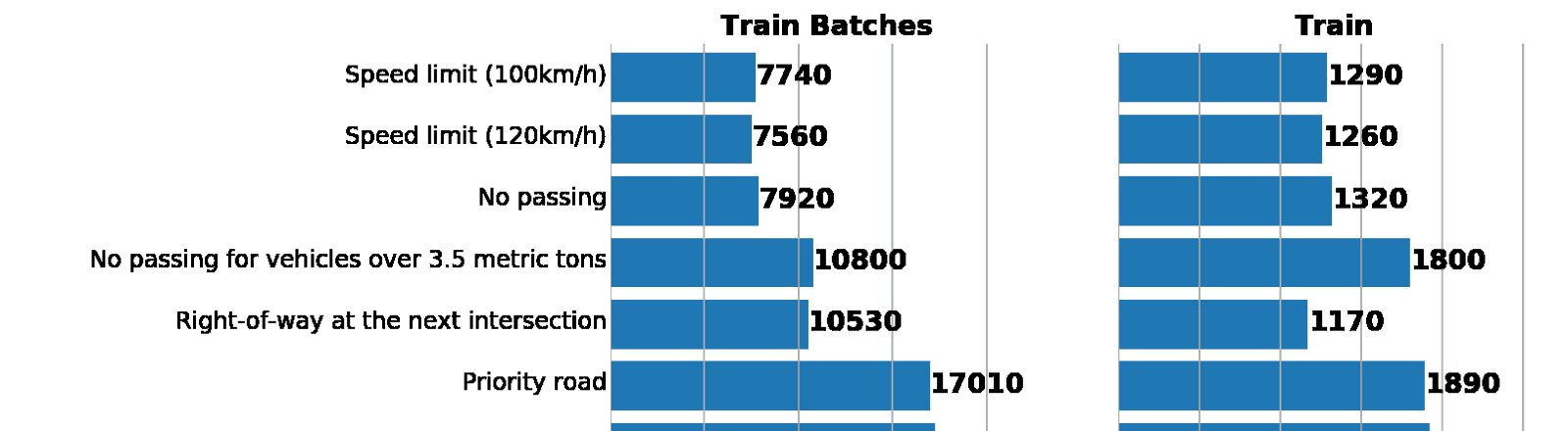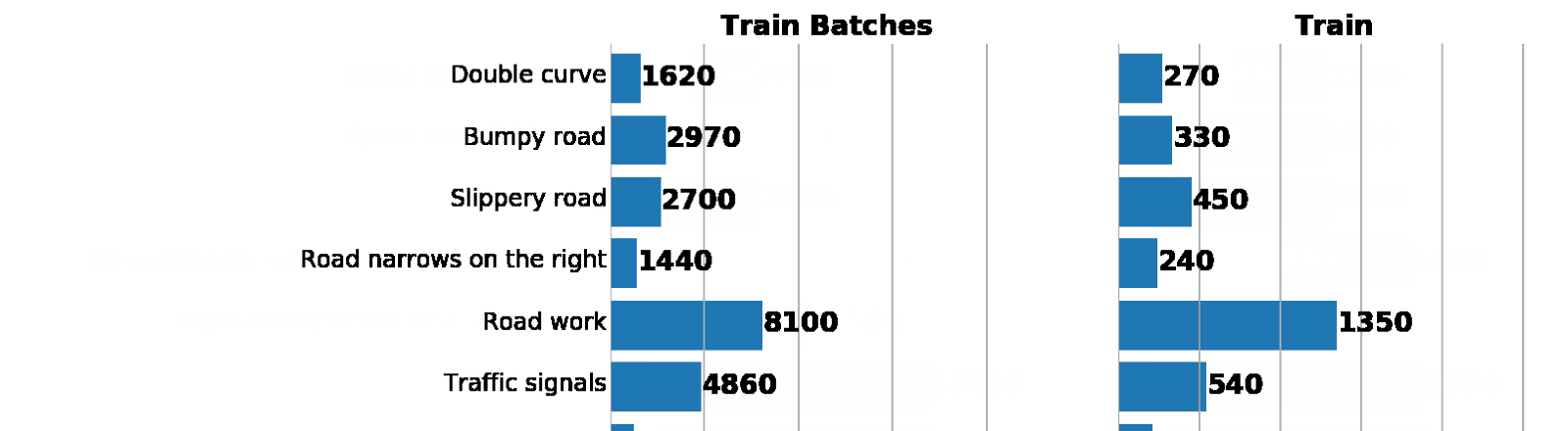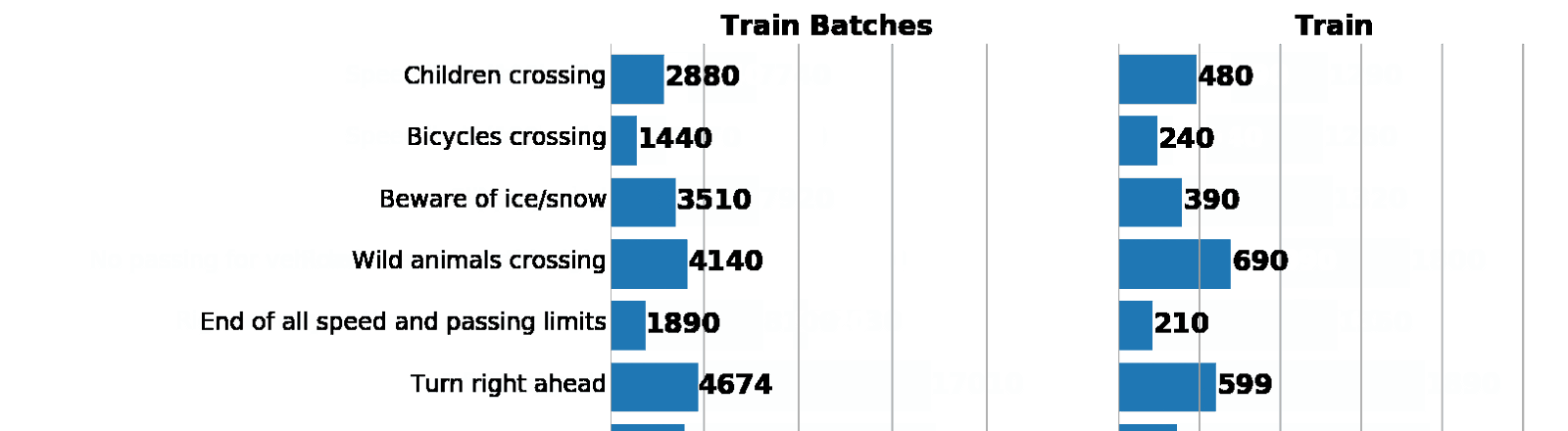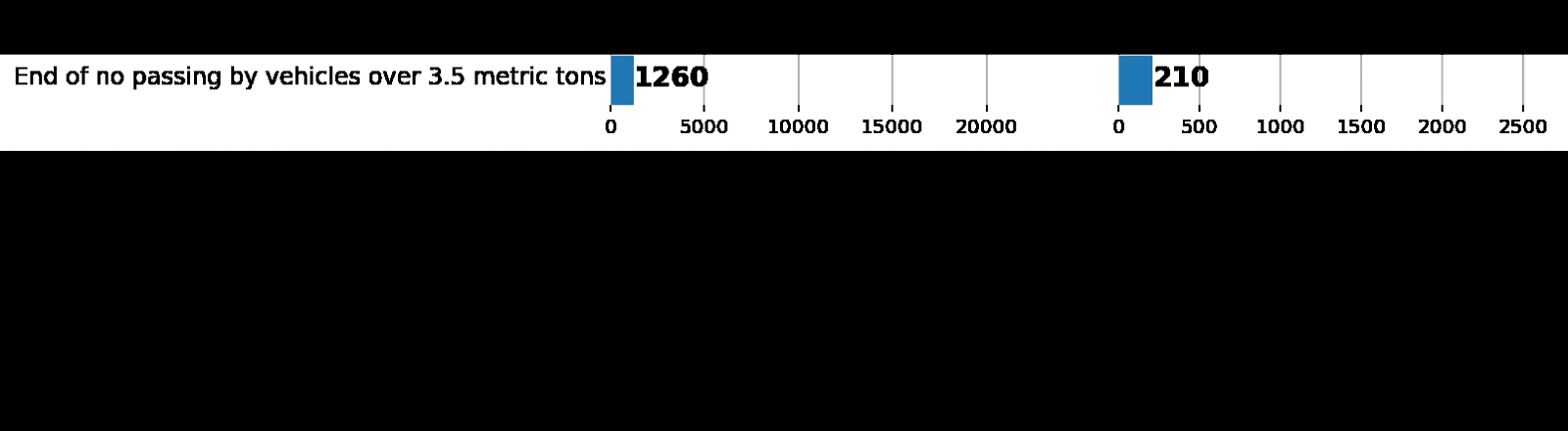
左:拡張バッチジェネレーターからのデータ分布のヒストグラム。 右:元の列車。 ご覧のとおり、値は異なりますが、分布は似ています。
ニューラルネットワークへの移行
データの前処理が完了し、すべてのジェネレーターとデータセットの分析の準備ができたら、トレーニングに進むことができます。 二重畳み込みニューラルネットワークを使用します:STN(空間変換器ネットワーク)はジェネレーターから前処理された画像バッチを受け取り、道路標識に焦点を合わせますが、IDSIAニューラルネットワークはSTNから受け取った画像上の道路標識を認識します。 次の投稿では、これらのニューラルネットワーク、トレーニング、品質分析、および作業のデモバージョンについて説明します。 新しい投稿をお楽しみに!

左:元の前処理された画像。 右:分類のためのIDSIA入力を受け取る変換されたSTNイメージ。