過去1年間、Yandexは、関連ドキュメントの可用性を必要とするクエリの検索として大きな進歩を遂げました。 現在、人気のあるドキュメントのほとんどは、公開後ほとんどすぐに関連クエリの検索結果に分類されます。

作成したばかりのドキュメントを検索結果に追加することは、原則として、関連性、権限などの他の重要なユーザーメトリックと矛盾するため、これを実現するのは容易ではありません。 今日、私たちは初めて、最新のドキュメントを検索に便利にミックスできる基本テクノロジーについて話すことにしました。
1.なぜ新鮮か?
数日以内に、もちろん、このイベントがそれ以上の開発を受けない限り、どんなイベントへの関心もほとんどゼロにフェードします。 この声明が生まれた調査を実施しました。平均73%のユーザーが、イベントが発生した日に直接イベントに関心を示しており、発行後3日以上でリソースにアクセスするのは3%の読者のみです。 この研究の瞬間から何年も経ちましたが、全体として状況は変わっていません。 また、habrahabr.ruの記事でさえ、最初の数日間で検索コンバージョンの数が最も多くなります。
タイムリーに実証された鮮度は、ウェブ検索だけでなく重要な特性です。 写真やビデオの検索、検索のヒントにも新鮮さが必要です。 もちろん、ニュースアグリゲーターやメディアでは。 しかし、そこには何がありますか:映画館でさえ、ほとんどの場合、長編映画ではなく、新しい映画に行きます!
検索エンジンの検索結果を更新することの重要性を過大評価することは困難です。 新鮮さを保つには、多くの問題を解決する必要があります:新しいドキュメントをリアルタイムで検索してインデックスに追加するコンテンツシステムを構築し、どのユーザーがどのクエリで新しいドキュメントを必要とするかを予測し、これらのドキュメントのベストを決定します もちろん、これらのタスクはすべて機械学習法を使用して解決されます。
この記事では、これらの問題を解決するためのいくつかのアプローチについて説明します。 また、6月8日に、当社のオフィスは内部からYandexミーティングを開催します。これには、鮮度に関するレポートも含まれます。 新たに発生した問題の中で最も困難なもの、つまりイベントへの反応を加速するタスクを検討します。 このリンクで予約できます。
1.1。 鮮度が必要であることを理解する方法
何らかの方法で、ユーザーがYandexで要求する要求の10〜20%で鮮度が必要です。
まず、これらは「イベント」リクエストです。 世界で何かが起こると、ユーザーは検索にアクセスしてイベントの詳細を調べます。 さまざまなイベントは、ユーザーの関心の観点と必要な開発の観点の両方で互いに非常に異なります。
たとえば、2016年9月の選挙期間中の新しいドキュメントのクリック数のグラフを考えてみましょう。
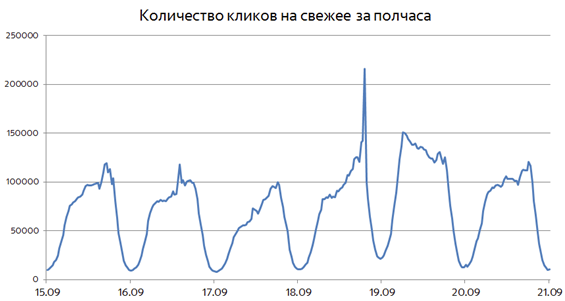
選挙当日、22:00にピークに達するまで、新鮮さの必要性が徐々に増加していることがはっきりとわかります。 翌日、フレッシュへの関心の高まりが残ったが、1日後にはほぼ正常な値に戻った。 言い換えれば、イベントへの関心は時間とともに変化します。 したがって、フレッシュの必要性を判断するのに役立つ最初のアイデアは、「一部のクエリが突然頻繁に尋ねられるようになった場合、何かが発生したはずであり、ユーザーはフレッシュドキュメントを表示する必要がある」です。 考慮される状況は、もう1つの理由で興味深いものです。 選挙の日付は開催されるずっと前に知られていた。
イベントが時間内に非常に延長されることがあります。 そのようなイベントの例としては、2016年のオリンピックがあります。すべての大会で、ユーザーは通常の2倍の頻度で新しいドキュメントを消費します。
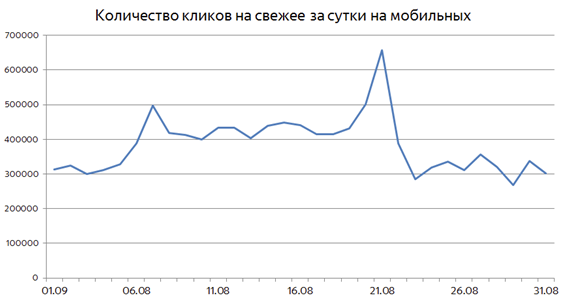
このような状況では、特定のトピックに対するリクエストの頻度の急増に基づいて、鮮度への関心を検出することはできなくなりました。 ここで別の方法が助けになります。ユーザーが何らかの種類の要求のために新鮮さを本当に必要とするなら、おそらく彼らは近い将来それを必要とするでしょう。
予期しないことが発生した場合、状況はまったく異なります。 通常、予期しない共振イベントは良いものに関連付けられていないため、日付や特定のインシデントを参照せずにグラフを見てください。
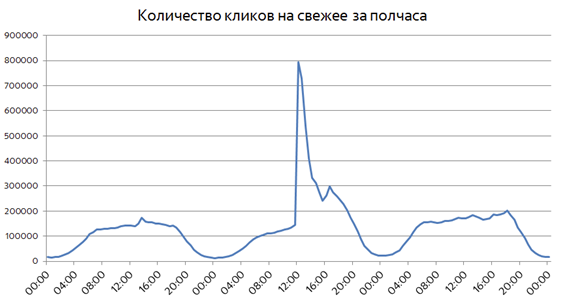
事件後の最初の30分ですでに、新鮮さに対するユーザーの関心はほぼ一桁大きくなっています。 そのような時点での検索のすべてのクエリに占める新鮮なクエリの割合は、最大25%増加する可能性があります。 予期しないイベントは、ユーザーの関心の急激なバーストによって適切に検出されますが、そのようなバーストは発生後数分以内に決定する必要があります。 Yandexが検索ログを処理し、計算結果をリアルタイム検索に配信できるようにするリアルタイムMapReduceテクノロジについては既に説明しました。
1.2。 Yandex Searchでの鮮度の表示方法
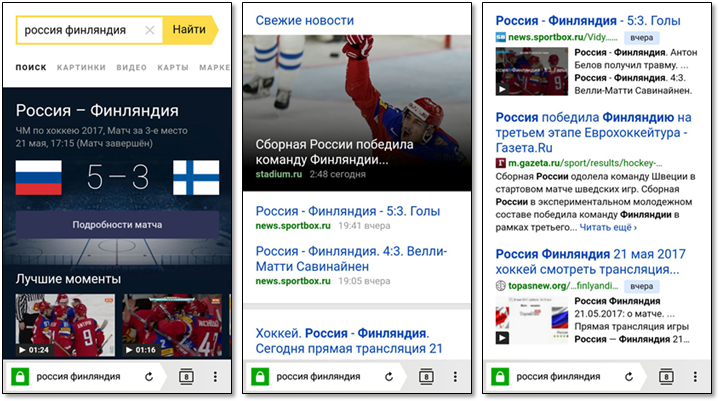
次に、検索結果に新しい結果がどのように表示されるかについて説明します。 2017年5月22日に行われた「ロシアフィンランド」のリクエストを検討してください。 この要求は、それに応答するときに、検索が新しい要求の処理に関連するほぼすべての機能要素を表示するためです。
スポーツクエリは最近のクエリのかなりの部分を占めるため、スポーツの試合に関する情報を特別な方法で提供します。 ユーザーは試合の開始日時、スコアを見つけることができます。 時々、ライブブロードキャストまたは興味深い瞬間のビデオへのリンクを知っています。
私たちはニュースソースからの結果をグループ化することを専門としており、より大きな魅力を実現しています。
それ以外の場合は、標準の検索スニペットに限定し、ドキュメントの年齢に合わせてカラープレートを追加します。 ドキュメントにビデオが含まれていることがわかっている場合は、スニペットにプレビューを追加します。
2.検索結果での鮮度の低下
2.1。 幅広いモデル
幅広いpFoundモデルに従って、新しい文書が発行のために混在しています。 このモデルは、検索結果の多様性のタスクのために一時提案されました。これに対応するYaC'2011の対応するyafinderレポートを見ることができます: https ://events.yandex.ru/lib/talks/12/。 このモデルは、特に新鮮な結果を混合するなど、より広範なタスクに適していることが判明しました。
このモデルでは、特定の検索クエリを設定するユーザーが意図(関心、トピックなど)の1つを意味すると想定しています。 たとえば、「ジャガー」と尋ねると、ユーザーは車、飲み物、または動物を意味します。 クエリ「シール」は、適切な写真、ビデオ、または単なる記事の必要性を示唆する場合があります。 ある時点での「Eurovision」のリクエストには、おそらく競技のコースまたはその準備に関する最も関連性の高い(新鮮な!)ニュースが必要です。 意図の中では、指定する特別な意図を強調する必要があります -これは「その他すべて」の意図であり、通常のオーガニックアウトプットに対応しています。
検索システムのタスクは、各ユーザーとその要求に対して適切なインテントのセットを選択し、これらのインテントに関連するドキュメントの発行を正しくコンパイルすることです。 幅広いpFoundモデルでは、各インテントは特定の重みに対応し、この特定のインテントへのユーザーの関心の可能性を示していると考えています。また、発行されている各ドキュメントについて、検討中のすべてのインテントに対する関連性のベクトルがわかっています。 次に、各インテントについて、pFoundメトリック-ユーザーがこのインテントを意味する場合、出力がユーザーのリクエストに応答する確率を計算できます。 Wide pFound-各インテントの重みで重み付けされたpFound intの合計に等しいメトリック:
どこで -ユーザーが念頭に置いていた場合、発行で関連する文書を見つける可能性 意図。
たとえば、一部のクエリで鮮度インテントの重みが0.9であり、ドキュメントの関連性が次の表に対応しているとします。
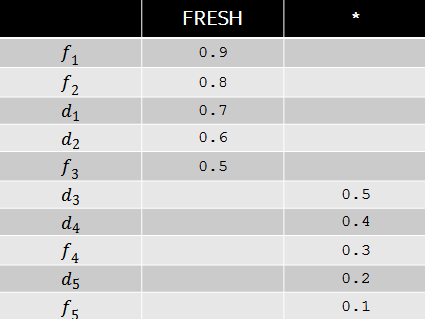
次に、広いpFoundの観点から、以下の表に示すドキュメントの順列が最適になります。 この場合の新鮮な文書の関連性は大きいという事実にもかかわらず、多様性の観点から、普通の文書を3番目と4番目の位置に置くことが有利です。 Fresh Intentは、最初の2つの結果にすでに非常に満足しています。 ご覧のとおり、ワイドpFoundモデルは、異種ソースからの検索結果の形成に対する特定のアプローチを表しており、タスクの目的は、インテントの重みとこれらのインテントへのドキュメントの関連性の決定に限定されます。
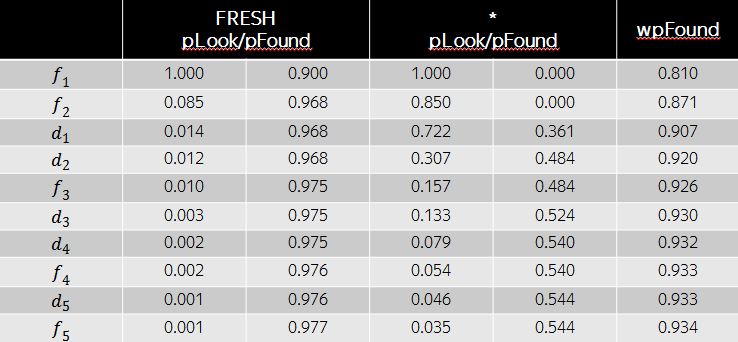
歴史的に、フレッシュネスでは、フレッシュインテントの重みを決定するタスクをフレッシュを検出するタスクと呼びます。 2番目のタスクは、ドキュメントのランク付けの標準タスクであり、この場合は新しいドキュメントです。
2.2。 トレーニングをクリック
新鮮なランキングを目的とした多くのドキュメントが毎分変更されます。新しいドキュメントが表示され、古いドキュメントが表示されなくなります。 このため、過去に取得した推定値を使用すると、次のような困難が生じます。 文書の要因と評価の両方が時間とともに変化します。 たとえば、12:00にどこかで火災が発生したというニュースが関連する場合がありますが、14:00には、その時点までに火災がすでに局所化されていたため、もはや関係ありません。 したがって、14:00に新規発行の関連性を評価するためには、新しいドキュメントを評価するだけではできません。完全にすべての新規発行ドキュメントの関連性を確認する必要があります。
このため、ラベル付けされたリクエストとドキュメントのペアの大規模で関連性の高い推定セットを新しいランキングで作成することは困難であることがわかりました。 トレーニングに追加の情報源を使用することを学んだときに、新しいランキングとしてのブレークスルーが達成されました。 主なものはユーザー信号で、検索結果をクリックします。
2.2.1。 ランキングのクリックスルートレーニング
ほとんどの場合、新しいドキュメントは発行の最初の位置に表示されないため、最初の位置の新しいドキュメントのクリック可能性を予測する最も単純な分類子を学習することもそれほど簡単ではありません。 また、隣接する新しいドキュメントを比較することもできません。他のソースからの任意の数のドキュメントを、新しいドキュメントから最初と2番目のドキュメントの間に配置できます。 したがって、従来のランキングでクリックスルートレーニングに使用される多くのアプローチは、鮮度のためにまったく機能しません。 他の方法を使用します。

最初の新鮮な文書と最後の普通の文書をクリックして、4つの普通の文書と3つの新しい文書を含む問題を想像してください。
文書と仮定することができます ドキュメントよりも優先 そして しかし比較する そして 互いの間ですでに非常に困難です。 しかし、例えば、我々はそれを仮定することができます まだ良い、なぜなら 現在のランキング式はそれを好みます。
したがって、いくつかの異なる方法で選択を作成できます。
- ペアワイズ分類のタスクの場合:文書を優先するように式をトレーニングします 文書 そして 。
- 点ごとの分類または回帰のタスクの場合:正のクラスに割り当てます 、そしてマイナスに- そして 。
- ランキングタスクの場合:順序を復元するには式が必要です 。
もちろん、トレーニングサンプルを作成する他の方法を考えることができます。 これは創造的で非常に刺激的なプロセスです。
2.2.2。 検出のクリックスルートレーニング
クリックによって新鮮な検出を教える2つのスキームを考えてみましょう。これは異なるときに使用しました。 これらの各スキームは、いわゆるコンテキストマルチアームバンディットの問題を解決します。 この場合のコンテキストは、ユーザークエリによって計算された要因です。 鮮度に関連するもののうち、いくつかを挙げると意味があります:リクエストの「コントラスト」(たとえば、過去24時間のリクエストの頻度と過去1週間の頻度の比)、このトピックについて最近書かれたニュースの量、リクエストの鮮度のCTRなど。
クリック情報はいくつかの方法で収集できます。 たとえば、すべての新しいドキュメントでユーザークリックを使用できます。新しいドキュメントをクリックした場合、検出器の予測を強化する必要があります。 トリガーは適切でした。 これは非常に魅力的な方法ですが、実際の応用では多くの困難に直面します。 サンプルは現在の式の応答に強く偏っており、場合によっては、強化の量を理解するのが非常に困難です。 たとえば、鮮度が低いことが示されており、クリックがなかった場合、これは、新鮮さに興味がないこと(この場合、意図の重みを減らす必要がある)と位置が低すぎる(この場合、意図の重みを増やす必要がある)ことの両方の証拠になります。
新鮮さを「ランダムな」位置に表示する特別な実験を使用できます。 鮮度インテントは、0から1までの数で、0.05の倍数などの小さなセットから選択できます。 次に、タスクは21の異なる値のいずれかを選択することになります。 これは多腕バンディットの問題です。 選択に対する応答は、問題に対するユーザーの何らかの行動です-たとえば、結果をクリックすると、機械学習タスクは、この応答の確率が最大になる鮮度インテントの大きさの選択に関して定式化されます。 この方法では非常に良い結果が得られますが、重大な欠点が1つあります。クリック信号の収集手順自体がユーザーの出力を大幅に低下させるためです。 新鮮な印象のほとんどは無関係です。
すでにいくつかの式がある場合 新鮮さの検出-評価の評価または上記の方法に従って選択された場合、その値は小さなランダム値によって変更でき、予測の変化の最適値は上記と同じ方法で予測できます。 より正確には、現在のリクエストで、式が意図の重みを予測すると仮定します 。 この重みに少しランダムな追加を追加します。 どこで -値の小さな離散セットの値。 例えば 。 その後、式を訓練することができます 、添加剤の最適値を予測し、2つの合計を新しい式として使用します。 。
この方法では、鮮度を検出するために現在の数式の値を変更し、常に改善することができます。 実際にはユーザーの結果を損なうことはありませんが、数ステップで式の予測を大幅に変更することができます。
3.鮮度がうまく機能するとき
最後に、いくつかのイベントの例としていくつかの指標についてお話したいと思います。その助けを借りて、フレッシュネスがうまく機能することを理解します。
まず、検索結果の一般的な関連性のグラフから始めたいと思います。 このスケジュールはAshmanov&Partnersによって作成されているため、その客観性に疑いの余地はありません。
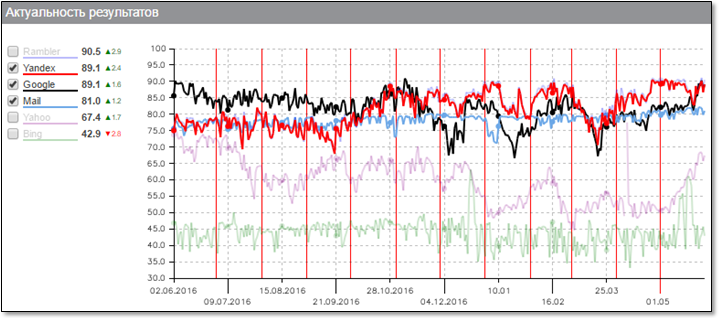
ここでは、過去1年間に達成されたドキュメントのインデックス作成速度におけるYandex(赤線)の進捗状況を明確に見ることができます。 私たちのロボットは、新しいドキュメントの出現について数分で学習し、Freshness検索インデックスに配信して、関連するクエリによってユーザーに表示できるようにします。
たとえば、 2018年ワールドカップでのブラジル代表チームの資格に関するニュースを考えてみましょう。 ドキュメントは10:56にサイト運営者のWebサイトに表示され、10:58にはすでにユーザーに最初に表示され、11:00までは関連するリクエストに対して約20回表示されました。 このスキームによれば、特定のドキュメントを調査するだけでなく、一般的なメトリックを構築することが可能です。 たとえば、かなり人気のあるすべてのドキュメント(1日に少なくとも1000回は問題で表示されていた)を取り上げ、発行から問題に関する最初のショーまでの時間の中央値を調べます。
過去1年間にこのグラフを描画すると、この値が4分から約2に減少したことがわかります。 つまり、ユーザーは新しいドキュメントをほぼ瞬時に利用できるようになります。
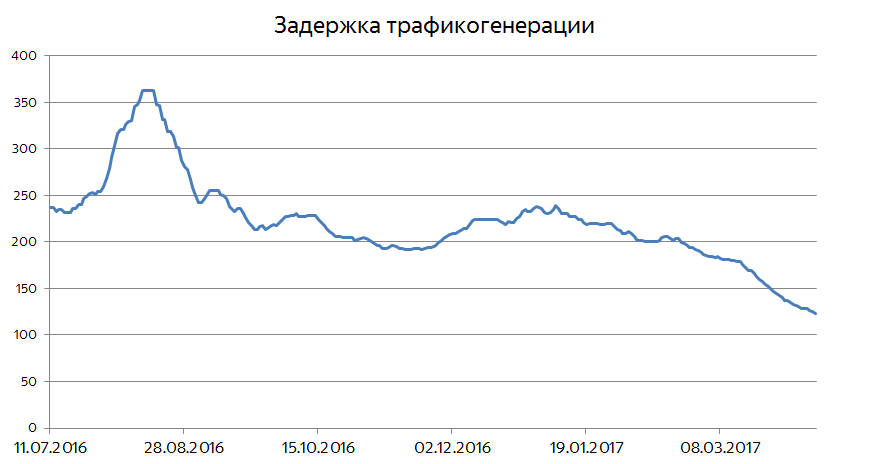
十分に大きなイベントが発生した場合、最も関連性の高いドキュメントを使用して、関連するドキュメントをユーザーにすぐに返信することが重要です。 時々、これは問題に関する最新のドキュメントの時代のグローバルグラフで見ることができます。 表示されているドキュメントのうち、10分未満、30分、1時間、2時間経過したものなどを常に監視しています。 イベントへの関心が時間の経過とともに引き延ばされているという事実により、そのようなドキュメントの割合が50%を超えることはめったにありません。 ただし、グラフが次のように動作する場合があります。
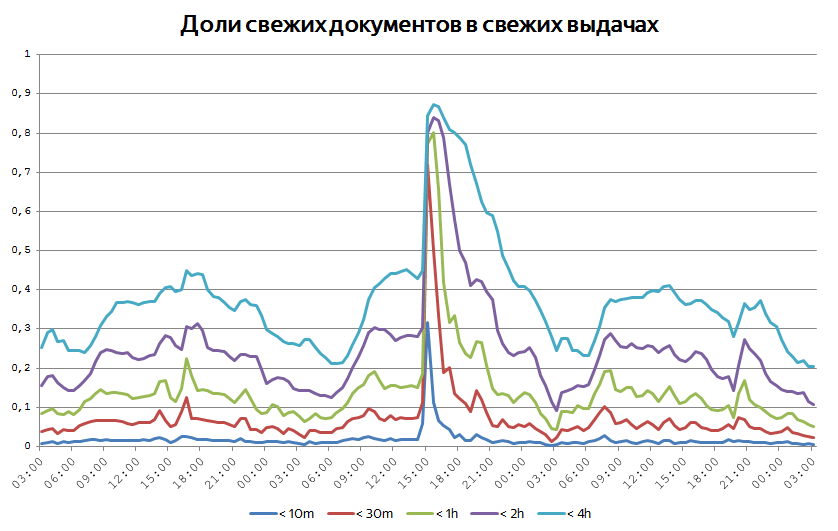
世界で重要なイベントが発生すると、出版物や検索アクティビティが急増し、非常に新しいドキュメントが普及し始めます。
4.結論
ユーザーが要求に応じて最も関連性の高い情報を必要とする状況で、検索結果を生成するいくつかの側面を検討しました。 もちろん、たとえば、迅速な回避策やロボットの品質、スパム対策、権限、設計など、多数の質問が検討の範囲を超えています。 Web検索の新鮮さのみを説明し、新鮮なサービスの必要性も感じていた他のサービス(写真、ビデオ、検索のヒント、音声検索など)の範囲は省略しました。 これらのトピックの一部は、既に発表されているYandexの会議で内部から取り上げられ、今後の記事で他のトピックについて議論することを期待しています。
お楽しみに!