
トップギアからのショット:アメリカ(シリーズ2)
最も負荷の高いサービスでは、BadooでCを使用し、C ++を使用することもあります。 多くの場合、これらのサービスはメモリに数百ギガバイトのデータを保存し、毎秒数十万のリクエストを処理します。 そして、適切なアルゴリズムとデータ構造だけでなく、生産的な実装も使用することが重要です。
ほぼ最初から、 Judyを連想配列の実装として使用しました。 Cインターフェイスと多くの利点があります。 7.0より前のバージョンのPHPでは、Judyは組み込みマップに比べて消費されるメモリ量を大幅に上回るため、PHPのラッパーも使用します。
しかし、時間が経ち、Judyが最後にリリースされてから何年も経ちました-代替案を検討する時が来ました。
私の名前はマルコです。プラットフォームチームのBadooシステムプログラマです。 私の同僚と私は、ジュディに代わるものを探して少し調査を行い、結論を出し、それらをあなたと共有することにしました。
連想配列
連想配列 、ツリー、およびハッシュテーブルが何であるかを知っている場合は、このセクションを安全にスキップできます。 残りの部分-トピックの簡単な紹介。
連想配列は、キーが値を受信または格納できるようにする抽象データ型です。 このデータ型をどのように実装するかについて何も述べていないため、抽象的です。 確かに、少しでも夢を見れば、さまざまなレベルの適切さのさまざまな実装を思いつくことができます。
たとえば、通常のリンクリストを使用できます。 要するに、そのような要素がまだないことを確認するために、最初から最後まですべてを回し、そうでない場合は、リストの最後に追加します。 取得時-目的のアイテムを検索してリストを最初から最後まで移動します。 このような連想配列に要素を見つけて追加するアルゴリズムの複雑さはO(n)であり、あまり良くありません。
単純ではあるが少し適切な実装から、単純な配列を検討できます。この配列の要素は常にキーでソートされます。 バイナリ検索でこのような配列を検索してO(log(n))を取得できますが、厳密に定義された位置にある要素の領域を解放する必要があるため、それに要素を追加するには大きなメモリをコピーする必要があります。
連想配列が実際にどのように実装されているかを見ると、おそらく何らかの種類のツリーまたはハッシュテーブルが表示されます 。
ハッシュテーブル
ハッシュテーブルは、連想配列を実装するデータ構造であり、そのデバイスは2段階のプロセスです。
最初の段階では、キーはハッシュ関数を介して実行されます 。 これは、入力でバイトのセット(キー)を受け取る関数であり、通常、出力で何らかの出力を提供します。 この番号を2番目の段階で使用して、値を検索します。
どうやって? 多くのオプションがあります。 最初に頭に浮かぶのは、この番号を通常の配列のインデックスとして使用することです。 値が含まれる配列。 ただし、このオプションは少なくとも2つの理由で機能しません。
ハッシュ関数の値の範囲は、メモリに割り当てられたままにしておく配列のサイズよりも大きい可能性があります。
- ハッシュ関数には衝突があります:2つの異なるキーが応答で同じ数を与えることができます。
通常、これらの問題は両方とも、各要素が別の配列(バケット)へのポインターである、サイズが制限された配列を割り当てることで解決されます。 次に、ハッシュ関数の値の範囲を最初の配列のサイズにマッピングします。
どうやって? 再び多くのオプションがあります。 たとえば、配列のサイズで除算の残りを取得するか、配列のサイズが2の累乗である場合、単純に数値の最下位ビットの目的の数を取得します(除算の残りは、シフトに比べてプロセッサの処理がはるかに遅いため、サイズは2のべき乗です)。
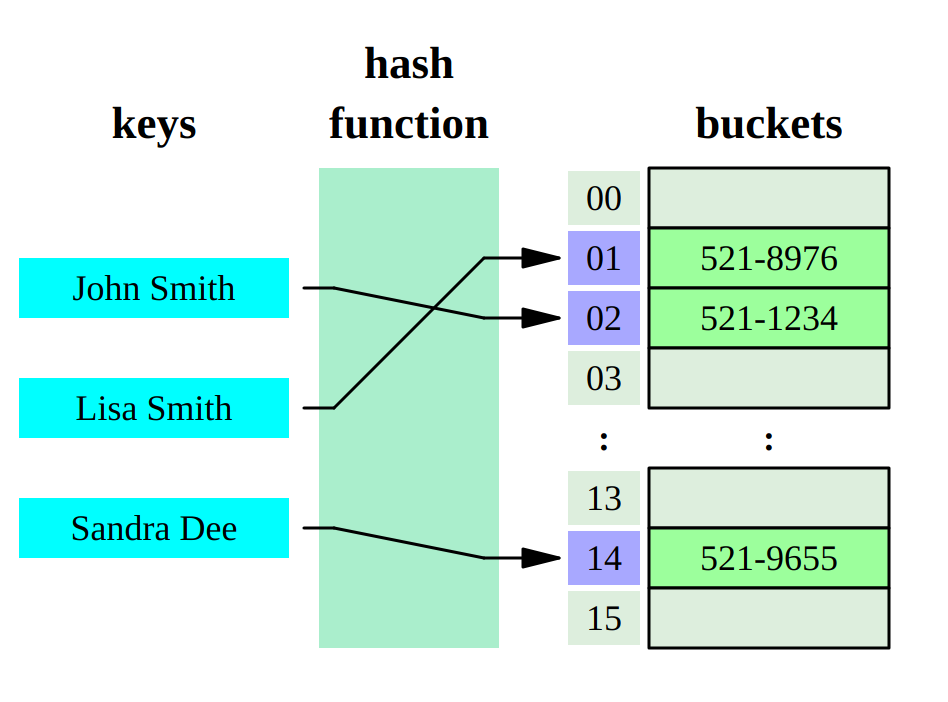
例として、ハッシュテーブルを実装する最も一般的な方法の1つを挙げましたが、一般的には非常に多くの方法があります。 また、選択した衝突処理方法に応じて、異なるパフォーマンスが得られます。 ハッシュテーブルのアルゴリズムの複雑さについて話すと、平均してO(1)になり、縮退した場合(最悪の場合)、O(n)も判明します。
木々
木があれば、すべてが非常に簡単です。 連想配列を実装するには、たとえばred-black treeなど、さまざまなバイナリツリーが使用されます 。 ツリーのバランスが取れている場合、操作ごとにO(log n)が得られます。
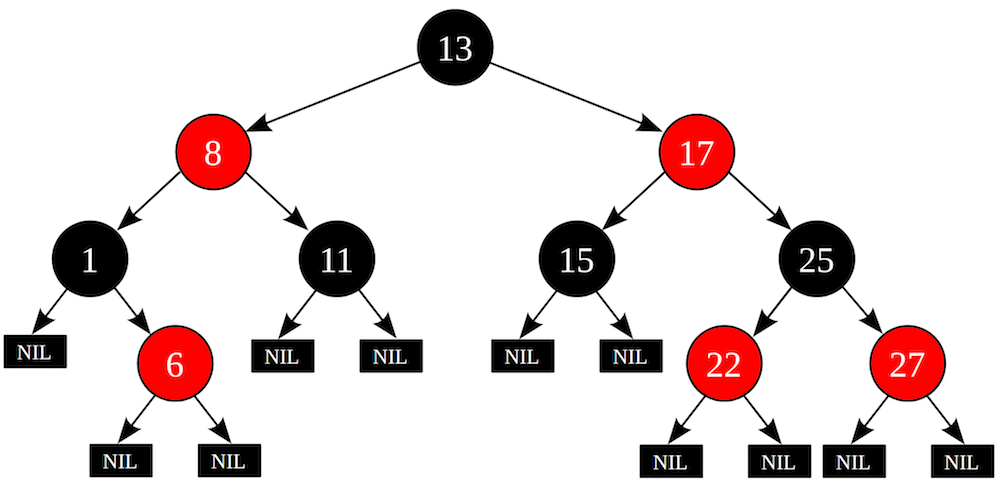
google btreeなどの一部のツリー実装では、最新のメモリ階層を考慮し、プロセッサキャッシュをより効率的に使用するためにキーをバッチで格納します。
ツリーを使用すると、キーの昇順または降順で要素をバイパスできます。これは、実装を選択するときに非常に重要な条件です。 ハッシュテーブルは方法がわかりません。
私たちは何を見ていますか?
もちろん、連想配列の世界は白黒ではありません。各実装には長所と短所があります。
実装が異なると、パフォーマンスだけでなく、提供される機能セットも異なる場合があります。 たとえば、一部の実装では、キーの昇順または降順で要素をバイパスできますが、そうでないものもあります。 そして、この制限は、著者の気まぐれではなく、内部アーキテクチャに関連しています。
はい。通常のパフォーマンスは、連想配列の使用方法によって大きく異なります。基本的には、書き込みまたは読み取り、キーをランダムな順序で、または順番に読み取ります。
KnutのO表記で2つのアルゴリズムを比較するのに十分だった時代は終わりました。 現実の世界はもっと複雑です。 プログラムが実行される最新のハードウェアにはマルチレベルメモリがあり 、異なるレベルへのアクセスは非常に異なっており、これを考慮すると、アルゴリズムを数倍高速化したり、同じ量だけ遅くしたりできます。
重要な基準は、メモリ消費の問題です。選択した実装のオーバーヘッドは、理論上の最小値(キーサイズ+値のサイズに要素数を掛けた値)と比較してどのくらいですか。
一時停止、最大遅延、応答性も重要な役割を果たします。 連想配列の一部の実装では、不運な要素を追加するときに内部構造の1回限りの高価な再構築が必要になりますが、他の実装ではこれらの遅延を「スミア」します。
研究参加者
ジュディ
Judy(またはJudy Array)は、順序付けられた連想配列を実装するDouglas Baskinsによって発明された構造です。 実装は Cで書かれており、非常に複雑です。 著者は、最新のアーキテクチャを考慮し、プロセッサキャッシュを最大限に使用しようとしました。
Judyはツリーであり、ハッシュテーブルではありません。 そして、単なるツリーではなく、いわゆるプレフィクスツリー 。 私たちの消費者にとって、これは、Judyを使用すると、キーの圧縮と、キーの昇順または降順で要素を実行できることを意味します。
Judyは、いくつかのキー/値のバリエーションを提供します。
| バリエーション | キー | 価値 |
|---|---|---|
| Judy1 | uint64_t | 少し |
| JudyL | uint64_t | uint64_t |
| ジュディスル | ヌル終了文字列 | uint64_t |
| ジュディス | バイトの配列 | uint64_t |
Judy1は、大きなスパースビットマップに便利です。 JudyLは、Badoo Cサービスで最もよく使用される基本タイプです。 ご覧のとおり、JudySLは文字列に使用すると便利で、JudyHLは一部のバイトセットにのみ使用できます。
std :: unordered_map
unordered_mapはテンプレートとしてC ++で実装されているため、何でもすべてをキーおよび値として使用できます。 非標準タイプを使用する場合、これらのタイプをハッシュする関数を定義する必要があります。
これはハッシュテーブルであるため、昇順または降順のキーバイパスは使用できません。
google :: sparse_hash_map
名前が示すように、スパースハッシュはGoogleによって開発され、値ごとに2ビットのみの最小オーバーヘッドを主張しています。 また、C ++で実装され、テンプレートとして作成されます(これは、私の意見では、C ++実装の明らかな利点です)。
とりわけ、スパースハッシュはその状態をディスクに保存し、そこから起動できます。
google :: dense_hash_map
スパースハッシュに加えて、Googleはデンスハッシュと呼ばれるオプションを作成しました。 その速度(特にget'aの速度)ははるかに高速ですが、これには多くのメモリを支払う必要があります。 また、dense_hash_mapの内部にはフラットな配列があるため、定期的に高価な再構築が必要です。 ところで、 Konstantin Osipovは、HighLoad ++に関する彼のレポートで、ハッシュテーブルのこのような問題とニュアンスについて話しました。 勉強することをお勧めします。
連想配列に保存するデータの量が少なく、そのサイズがあまり変わらない場合は、高密度ハッシュが最適です。
同様に、スパースハッシュデンスハッシュは、ハッシュテーブルとテンプレートです。 つまり、キーを昇順で通過せずに、キーと値として任意のタイプを使用する機能を繰り返します。
また、対応するものと同様に、sparse_hash_map dense_hash_mapはその状態をディスクに保存できます。
spp :: sparse_hash_map
そして最後に、開発者の1人からの最後の申請者は、Googleのスパースハッシュです。 著者は、スパースハッシュを基礎として再考し、レコードあたり1ビットの最小オーバーヘッドを達成しました。
すべて同じ:ハッシュテーブルとテンプレート。 C ++実装。
申請者が提出した-それは彼らが何ができるかを確認する時間です。
さらに2つの要因
しかし、最初に、さらに2つのことがパフォーマンスとメモリ消費に影響することに注意してください。
ハッシュ関数
ハッシュテーブルである調査のすべての参加者は、ハッシュ関数を使用します。
ハッシュ関数にはかなりの数のプロパティがあり、それぞれが地域によって多少重要な場合があります。 たとえば、暗号化では、入力データの最小限の変更が結果の可能な限り大きな変更につながることが重要です。
しかし、速度に最も関心があります。 ハッシュ関数のパフォーマンスは大きく異なる可能性があり、速度はしばしば「フィード」するデータの量に依存します。 長いバイト文字列がハッシュ関数に提供される場合、SIMD命令を使用して最新のプロセッサの機能をより効率的に使用することをお勧めします。
C ++の標準ハッシュ関数に加えて、 xxhashとt1haがそれをどのように行うかを見ていきます 。
メモリ割り当て
結果に間違いなく影響する2番目の要因は、メモリアロケーターです。 作業の速度と消費されるメモリの量は、それに直接依存します。 標準のlibcアロケーターは、すべての取引のジャックです 。 それはすべてに適していますが、何にも完璧ではありません。
別の方法として、 jemallocを検討します。 テストでは、その主な利点の1つ(マルチスレッドでの作業)を利用しないという事実にもかかわらず、このアロケーターでの作業が高速になることを期待しています。
結果
以下は、1000万の要素間でのランダム検索テストの結果です。 私が最も興味を持っている2つのパラメーターは、テストの実行時間と消費される最大メモリ(ピーク時のプロセスのRSS)です。
キーとして32ビット整数を使用し、値としてポインター(64ビット)を使用しました。 最も頻繁に使用するのは、これらのサイズのキーと値です。
ランダム取得とメモリ消費に最も関心があったため、リポジトリに提示されている他のテストの結果は表示しませんでした。
最速の連想配列は、Googleの高密度ハッシュでした。 次はspp、次にstd :: unordered_mapです。
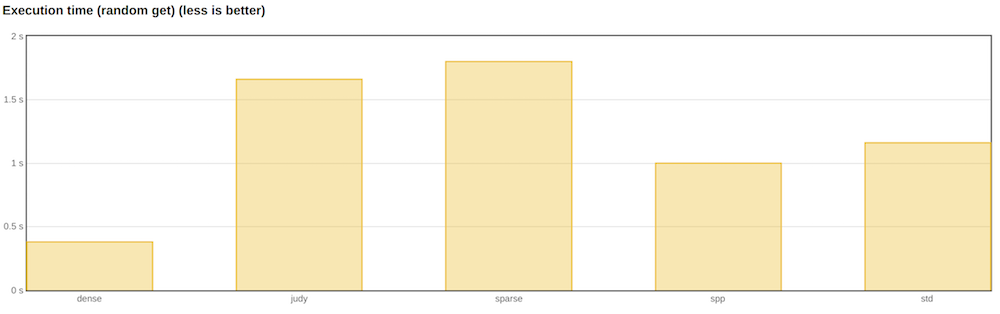
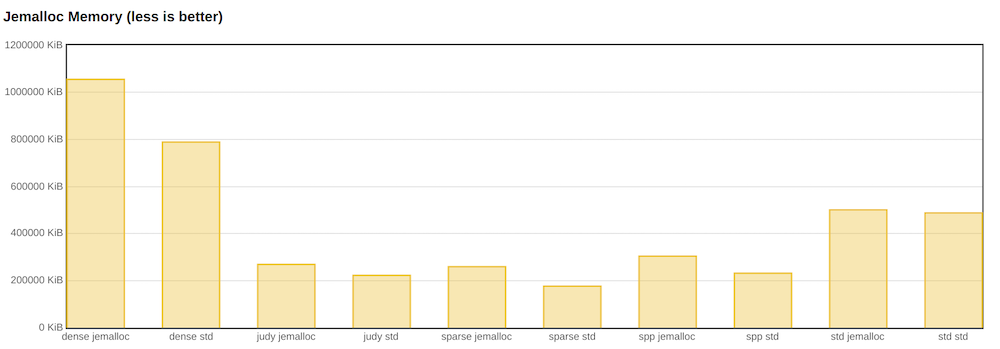
ただし、メモリを見ると、dense_hash_mapが他のすべての実装よりも多く消費していることがわかります。 実際、これはドキュメントに書かれていることです。 さらに、テストで競合する読み取りと書き込みがあった場合、ほとんどの場合、世界の再構築が発生します。 したがって、応答性と多くのエントリが重要なアプリケーションでは、密なハッシュを使用できません。
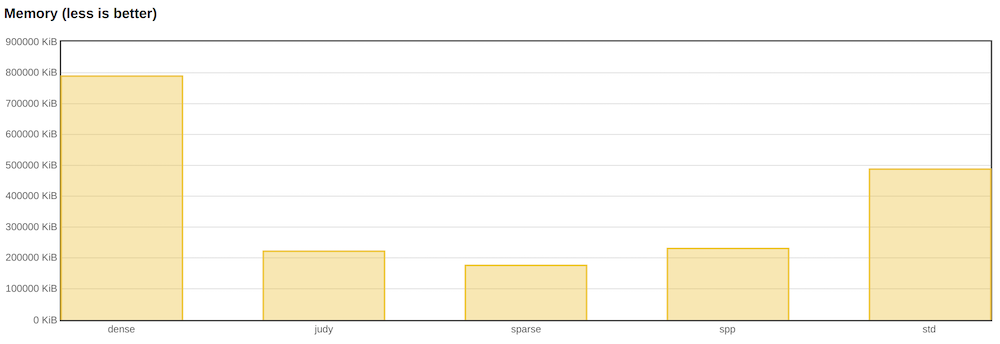
また、代替ハッシュ関数の実装も検討しました。 しかし、判明したように、標準のstd ::ハッシュはより高速です。
同僚は、32ビットまたは64ビットキーの場合、std :: hashが本質的に単なるアイデンティティであることを誤って気付きました。 つまり、入力と出力が同じ数であるか、つまり、関数は何もしません。 xhashとt1haは正直にハッシュを考慮します。
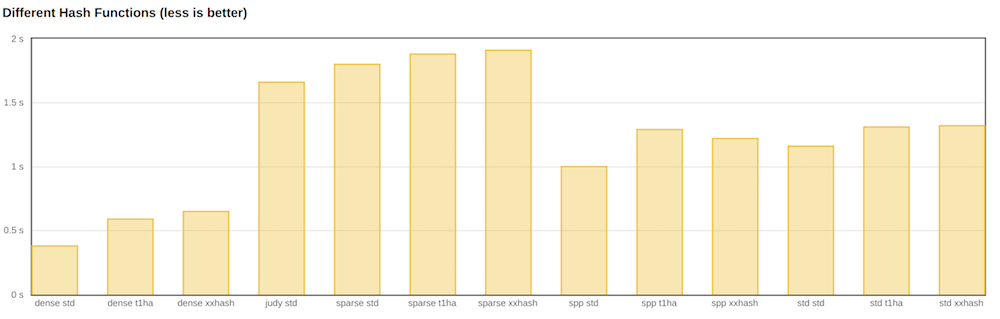
パフォーマンスの観点から、jemallocは便利です。 ほとんどすべての実装が高速になります。

ただし、jemallocのメモリ消費量はそれほど良くありません。
ソースコードとハードウェア
ベンチマークのソースコードをgithubに投稿しました 。 必要に応じて、私のテストを繰り返すか、テストを展開できます。
私は自宅のデスクトップでテストしました:
- Ubuntu 17.04
- Linux 4.10.0
- Intel®Core(TM)i7-6700K CPU @ 4.00GHz
- 32 GiB DDR4メモリ
- GCC 6.3.0
- コンパイラフラグ:-std = c ++ 11 -O3 -ffast-math
簡単な結論と最後の言葉
テストでは、Judyの代替としてsppの優れた可能性が示されました。 sppはランダムget'ahでより高速であることが判明し、そのメモリオーバーヘッドはそれほど大きくありません。
CのC ++の単純なラッパーを作成し、近い将来、負荷の高いサービスの1つでsppを試してみます。
哲学的な結論として、私たちが検討した実装にはそれぞれ長所と短所があり、手元のタスクに基づいて選択する必要があると言います。 内部構造を理解すると、タスクとソリューションを比較するのに役立ちます。この理解により、単純なエンジニアと高度なエンジニアが区別されることがよくあります。