
どんな人間の感情にも馴染みのないライブラリnumpy
私は自由意志の機械学習コースを受講しました。 最初のレッスンでは、通常のコース開発にはPythonの基本的な理解だけでなく、1年間のマタンコースでも十分であると言われました。 それは素晴らしいですね! 異なる大学でのプログラムが異なることに気付くまでは。 「年次マタンコース」というフレーズには、誤って線形代数、離散数学、漸近解析などが含まれていました。
「Pythonの基本的な理解」とは何かについても、私は非常に間違っていました。 「これは最も単純な言語の1つです!」-あらゆるところで主張しています。 良いコードはフィクションとして読むことができます。 そして、私は友人を信じていました。なぜなら、Pythonで以前に何も書いたことがないので、私自身は異なるアルゴリズムの実装を読むことを好んだからです。 結局のところ、彼はとても簡潔で、本質を完璧に伝えています。
唯一の問題は、コードの読み取りと自分自身の書き込みが異なるタスクであることです。 すぐに適切なPythonコードを書き始めることは大きな問題です(キャプテンはごめんなさい)。
私の人生で最初に動的に解釈された言語を多くの苦しみと学習を試みた後、私は幸せと誇りの瞬間がありました。 ご想像のとおり、この瞬間は短命でした。 すぐに、これでは十分ではないという認識に至りました。 少なくとも何らかの方法でpythonで書くことを学んだので、機械学習ライブラリを正しく使用するために再トレーニングする必要があります。 多くの人にとって、これはさほど難しいことではないと聞いた。 この段階に気付かない人もいます。 しかし、最初は標準コレクションをすぐにマスターして心から愛し、MLライブラリがこの問題について独自の意見を持っていることを知ることは最初は非常に困難でした。 彼らは、かわいいペットリストと辞書がどれほど便利で使いやすいかについて全く興味がありません。 numpyライブラリは、人間の感情とは無関係です。
すでに理解しているように、このコースは私にとって悲惨なほど困難でした。 私はコースの最初の部分をほとんど通過できず、「満足」の評価を得ました。 コースは2つの部分で構成され、1年間設計されましたが、私はそれ以上傷つけないことにしました。 一般的に、すべての機械学習について非常に憂鬱な意見があります。 真剣に、私はそれが私だけのものではないと決めました。
しかし、他のすべての傷のように、この傷は時間の経過とともに引きずり込まれました。 最近、機械学習のさまざまな方法を使用して人々が新しい高みを征服する方法に関するさまざまな記事を読むようになりました。 銀河の美しい謎や医学の重要な問題-コンピューターに正しい方向で考えることを教えるだけで、それらの解決に近づくチャンスがあります。 この考えは私を悩ませるので、私はもう一度モチベーションであなたを満たして、もう一度試してみることにしました。
どこから始めるか
あなたが私の旅の始まりにいるなら、簡単な旅から始めてください。 最初の試みでは、数学の深い知識は必要ありません。 マイクロソフトに着いたとき、驚いたことに、今日ではMLを学習するためのコードを書くことさえできないかもしれません。 一般的な道を歩きながら、簡単なタスクの基本的な解決策を見つけましょう。
Azure ML Studioでアカウントを作成する:銀行カードをリンクせずに、数回の試行に対して無料のクォータがあります。 すべてのアルゴリズムと必要な手順が実装されており、さらにクールです-弱いラップトップでもすべてがすぐに動作します。 すべての計算はクラウドで行われます。
データを入力することもできますが、最初は提案されたサンプルが最適です。 フライト遅延に関するデータセットを選択しました。 訓練されたモデルを持っていると、例えば、彼らのフライトが遅れる可能性があることを友人に伝えることが可能になります...
利用可能なデータセットを表示するには、 データセット→サンプルをクリックします。
選択したデータセットはFlight Delays Dataと呼ばれます。
実験を作成しましょう。 これを行うには、[ 実験 ] → [ 新規 ] (ページの下部)→[空の実験 ]をクリックします。 ちなみに、実験には「サンプル」タブもあり、既製のモデルを調べることができます。 しかし、今ではすべてを自分でやることが私たちにとってより興味深いです。
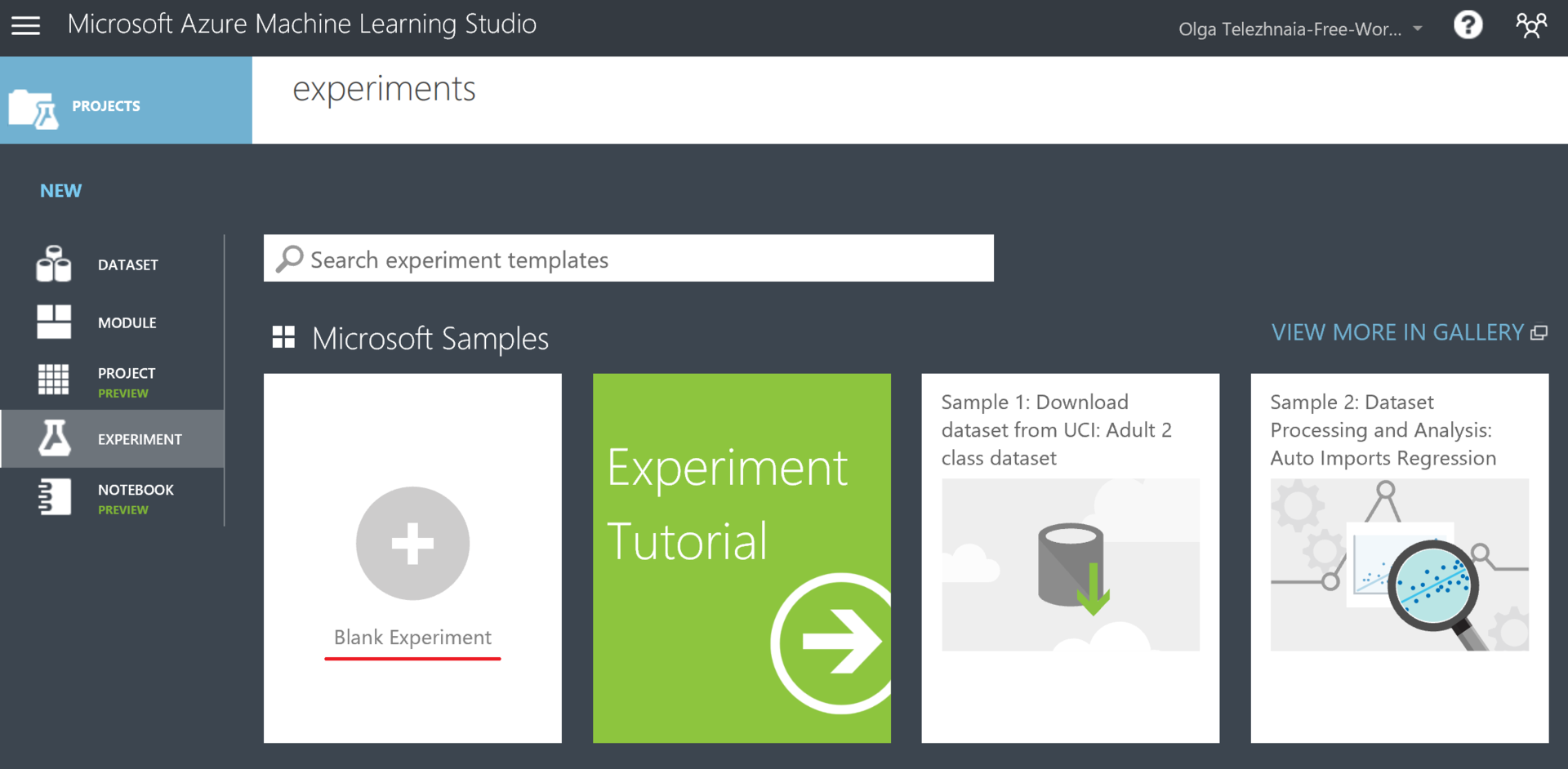
Azure MLプラットフォームは、その柔軟性と目立たないことに驚きました。 この記事では、すべての人が機械学習にアクセスできることを示したいと思いました。 私たちとの仕事の全体的なプロセスは、「必要なブロックを選択し、それらを作業面に投げ、論理的に接続し、開始し、喜ぶ」ように見えます。
自信がある場合は、独自のブロックを作成できます。そのためには、PythonまたはRでプログラムコードを記述する必要があります。既に訓練されたモデルの軍隊を背中に置いている場合は、おそらくJupyter Notebookに精通していて、Azure MLで作業できます彼を通して。
Webインターフェイスに対する深刻なアレルギーを抱えていても、クラウドの利点を味わいたい場合でも、開発者はこの状況を考慮して、コンソールからAzureに接続できるようにしました。 詳細はこちら 。
モデルに戻ります。 左側のメニューで必要なすべてのブロックを取得します。 それらは便利なグループに分けられます。 最初の試行では、途中で隣接するセクションを調べながら、正しいものを検索することをお勧めします。 ただし、目的のブロックのおおよその名前がわかっている場合は、検索を使用できます。
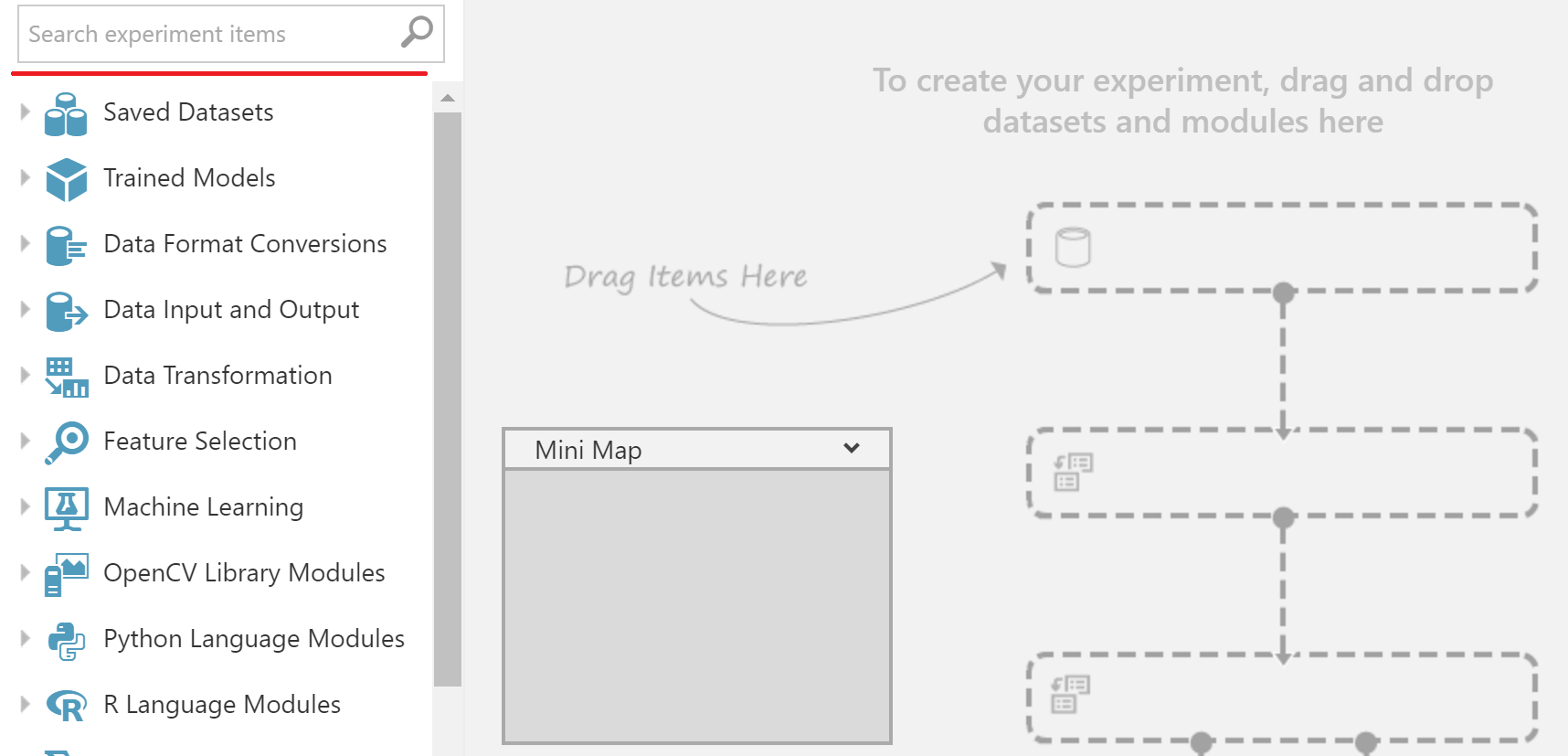
フライト遅延を予測する
機械学習アルゴリズムを適用する古典的なシナリオは次のとおりです。
- 良いデータを見つけて、さらに改善します。 ごみをきれいにし、有用な情報を追加します。
フライトデータセットを選択しました。
目的のブロックを作業面にドラッグします。
データをよりよく研究して準備します。 これを行うには、右クリックしてブロックを終了し、視覚化を選択します。
美しいテーブルが見えます。
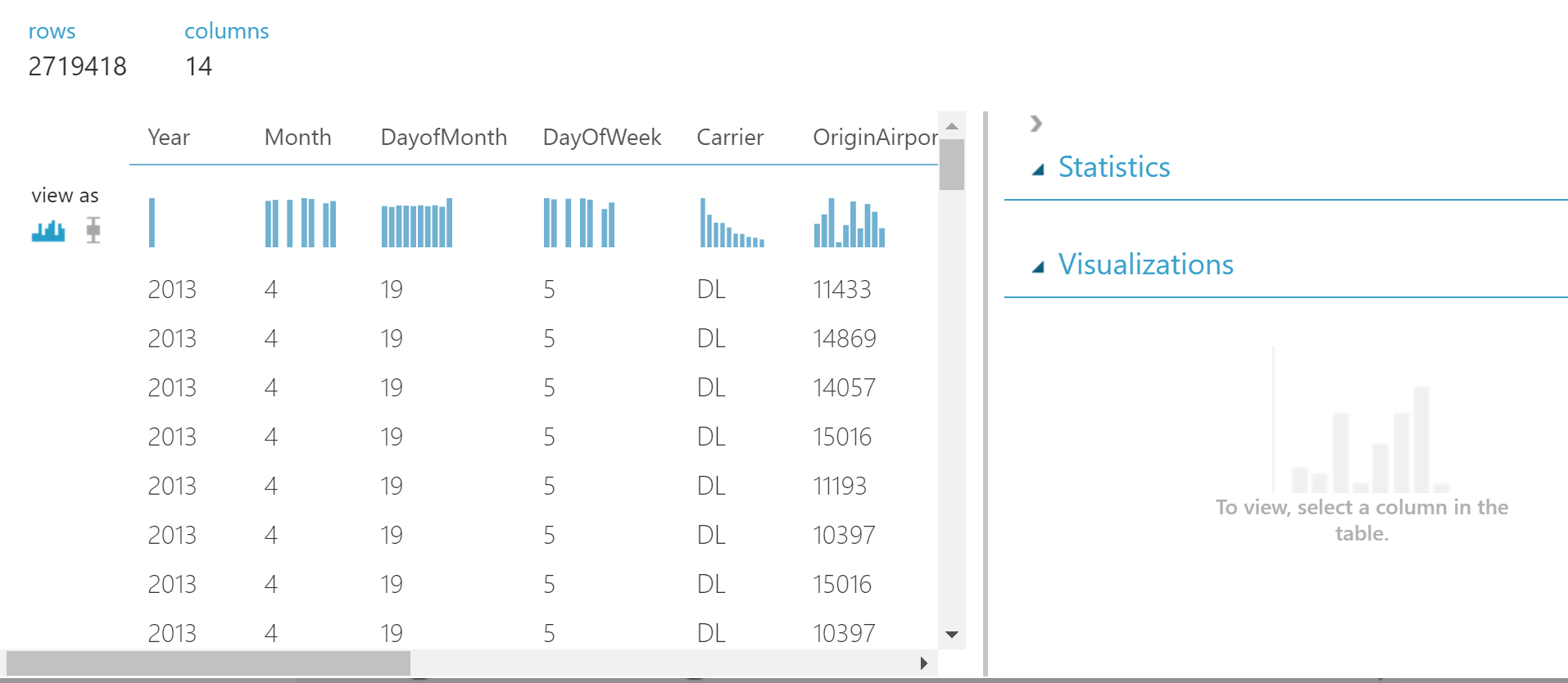
任意の列をクリックして、統計を確認できます。
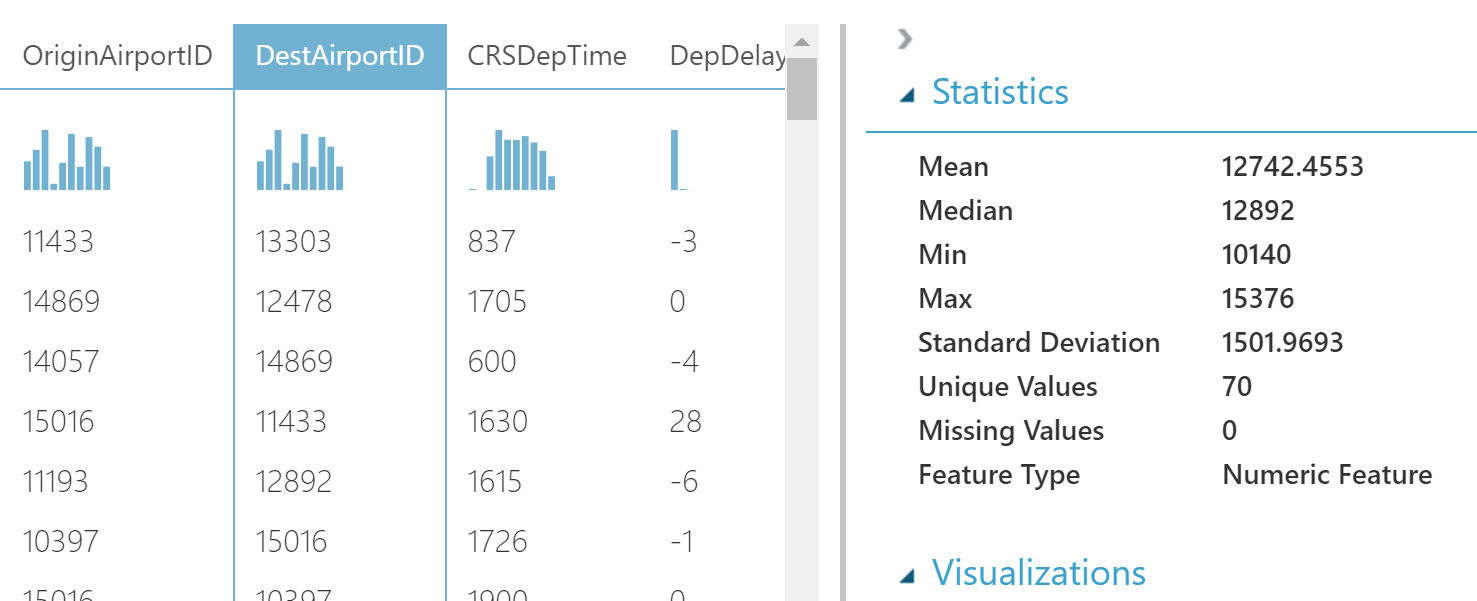
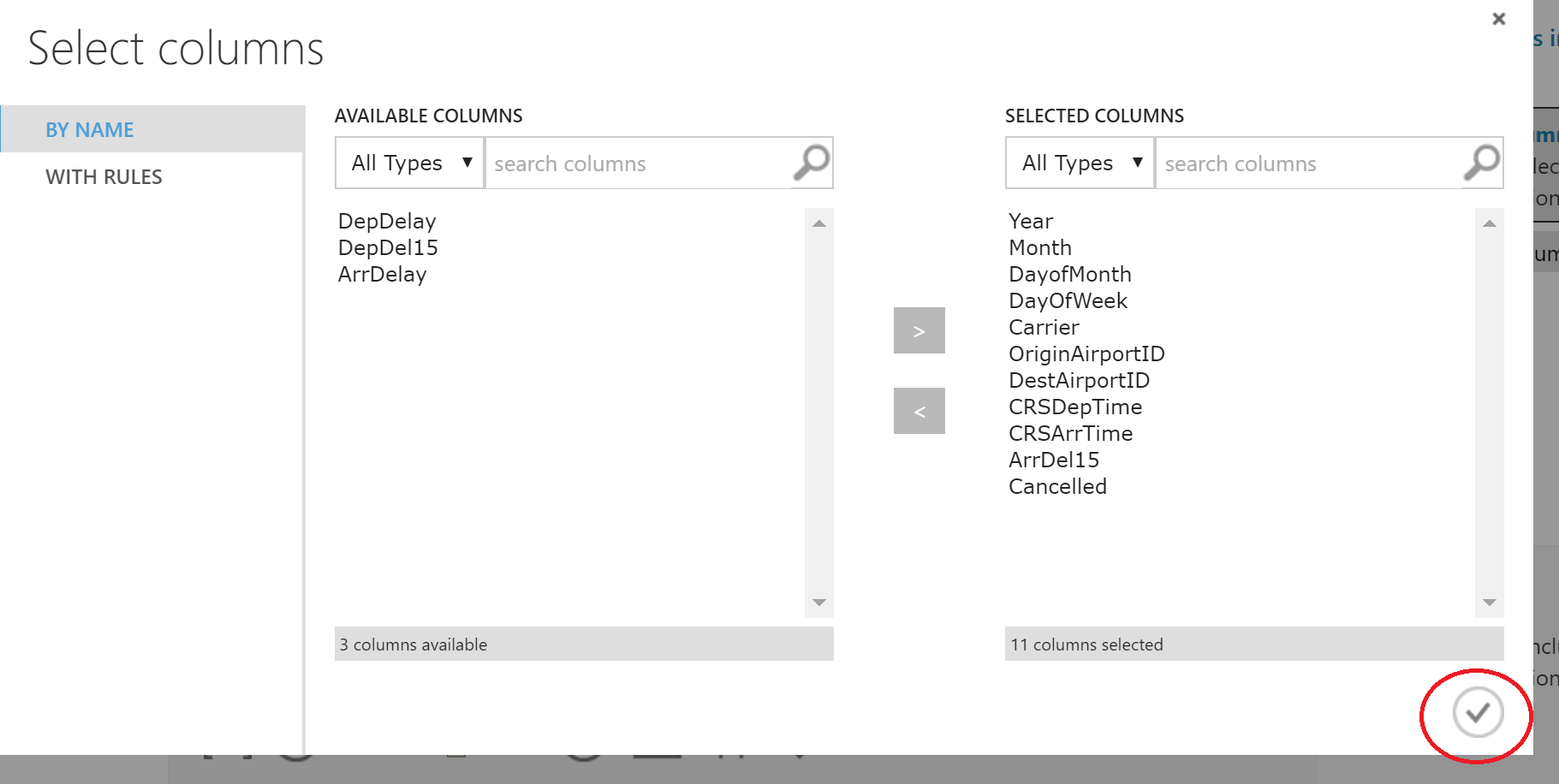
データを調べると、DepDelay列とDepDel15列が見つかりました。 これらにはギャップが含まれているため、これらの列を削除することにしました。
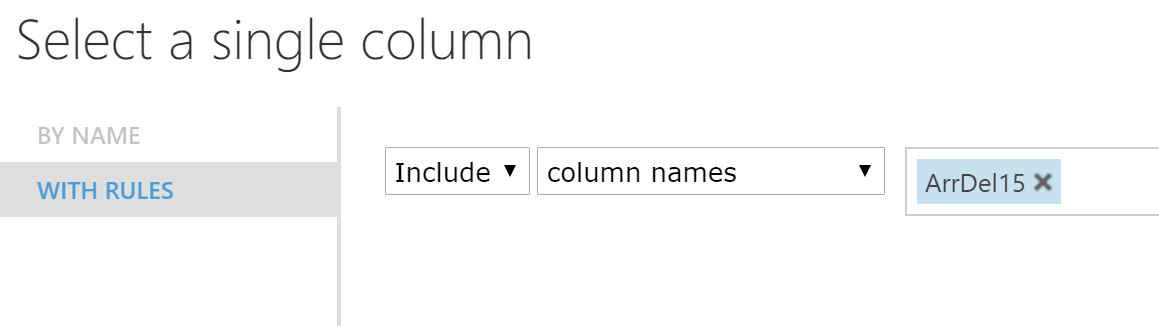
バイナリ記号を予測する予定です-飛行機が15分以上遅れることは本当ですか? ArrDel15列がそれを担当します。 彼女に加えて、遅延を数分で保存するArrDelay列もあります。 残念ながら、削除する必要があります。そうしないと、実験は完全に正直ではないことが判明します)
列を削除するには、Datasetブロックの列の選択を選択し、前のブロックに接続してから、右側のメニューで[列セレクターを起動]ボタンをクリックします。
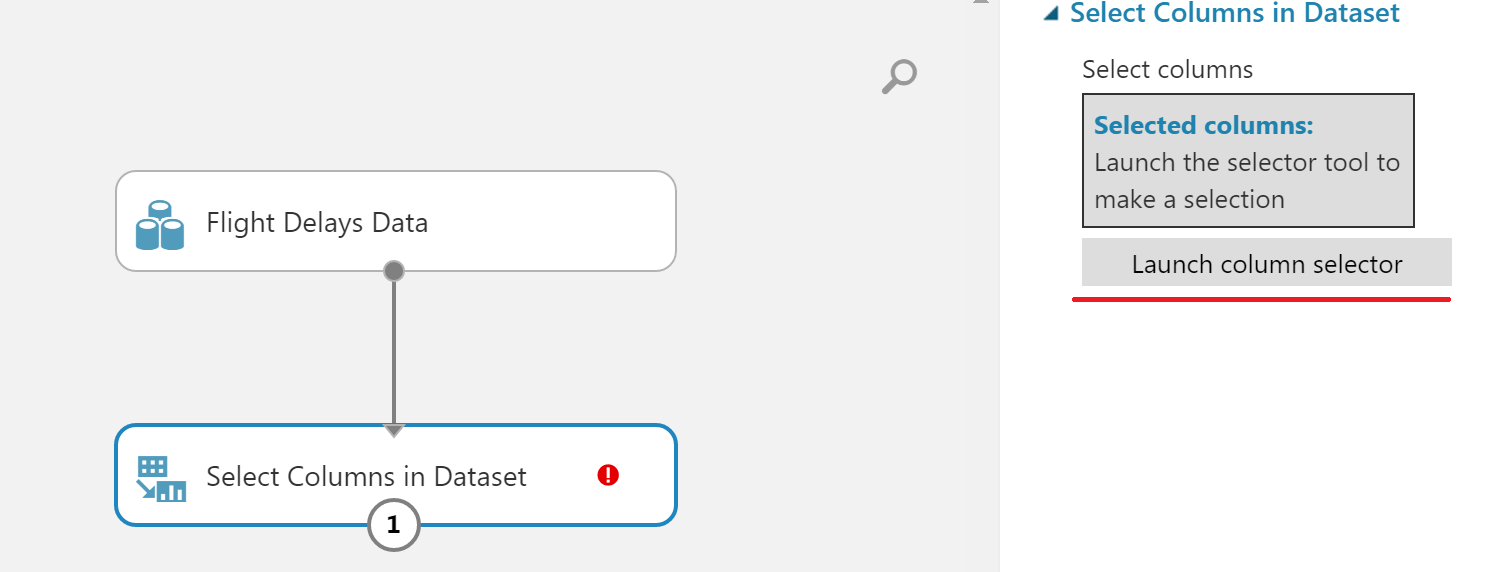
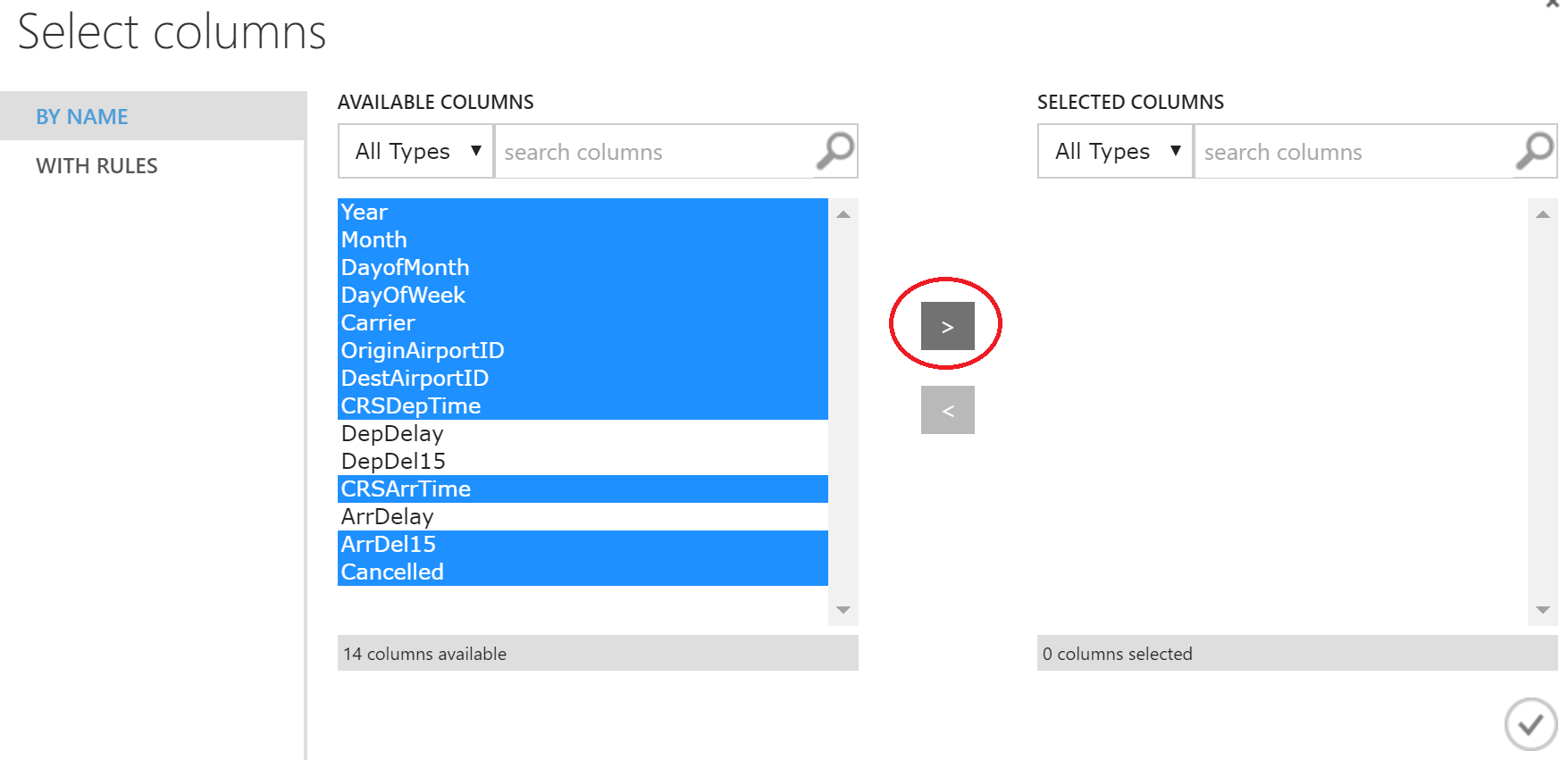
表示されるウィンドウで、目的の列を選択します。
- データを2つの部分(トレーニングとテスト)に分割します。 私たちのタスクは、しばらくの間テスト部分を忘れることです。
トレイン/テストセットの詳細については、 こちらをご覧ください 。 Split Dataブロックが役立ちます。
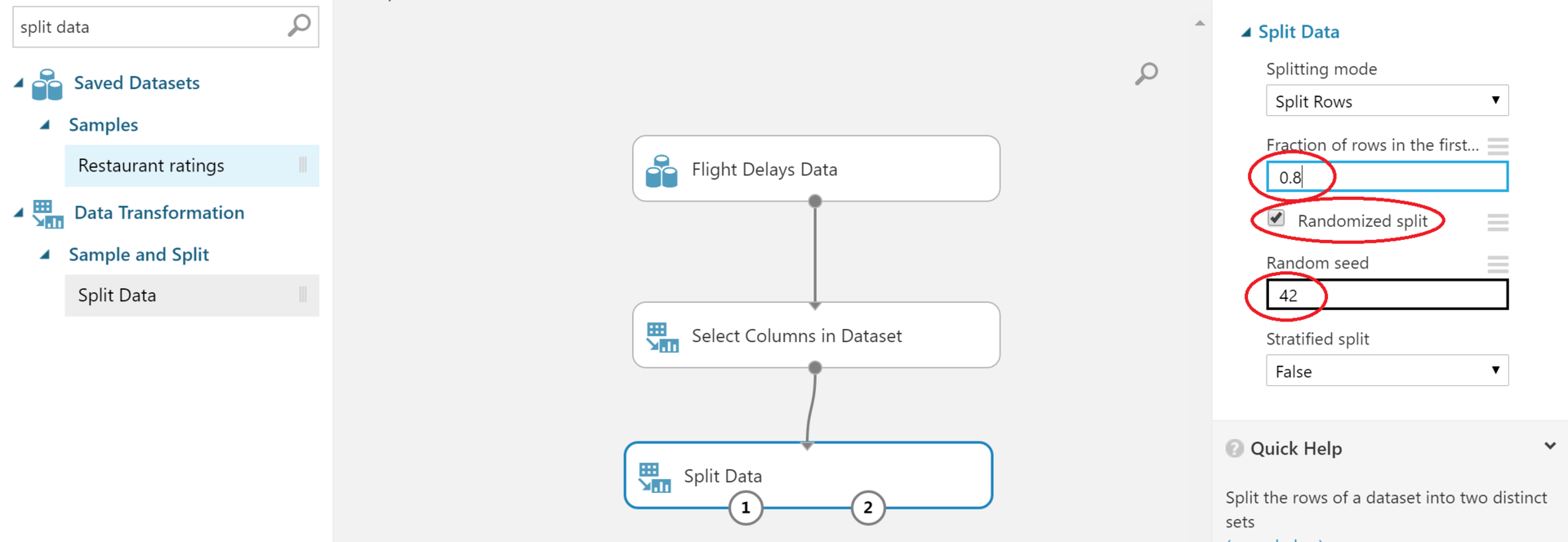
右側の丸で囲まれたフィールドに必ず入力してください。 最初の-ブレークにどのくらいの割合で-通常は0.7-0.8に設定されます。 2番目は、パーティションがランダムかどうかです。 チェックマークは既にあります。誤って削除していないことを確認してください。 また、Random Seedを設定すると便利です。詳細については、 こちらを参照してください 。
- トレイン部分を機械学習アルゴリズムに渡します。
最も難しいことは私たちのために行われます。 アルゴリズムの選択は微妙な点です。 私の記憶から、ランダムフォレスト(きちんと-ここでは決定フォレストと呼ばれていました)を取りました。 任意の2クラス分類アルゴリズムが適しています。
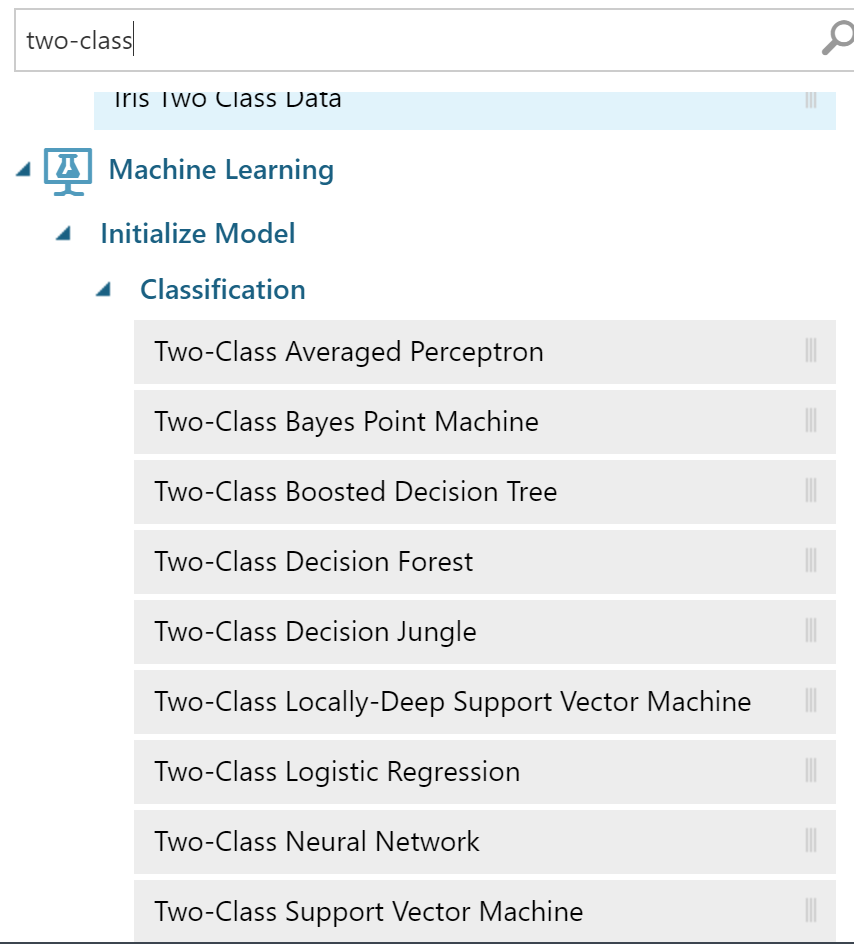
他の何かを選択して、より良い結果を得て、コメントでそれについて話すことができます)
Train Modelブロックも必要になります。 以下のスクリーンショットに示すように、ブロックを接続する必要があります。
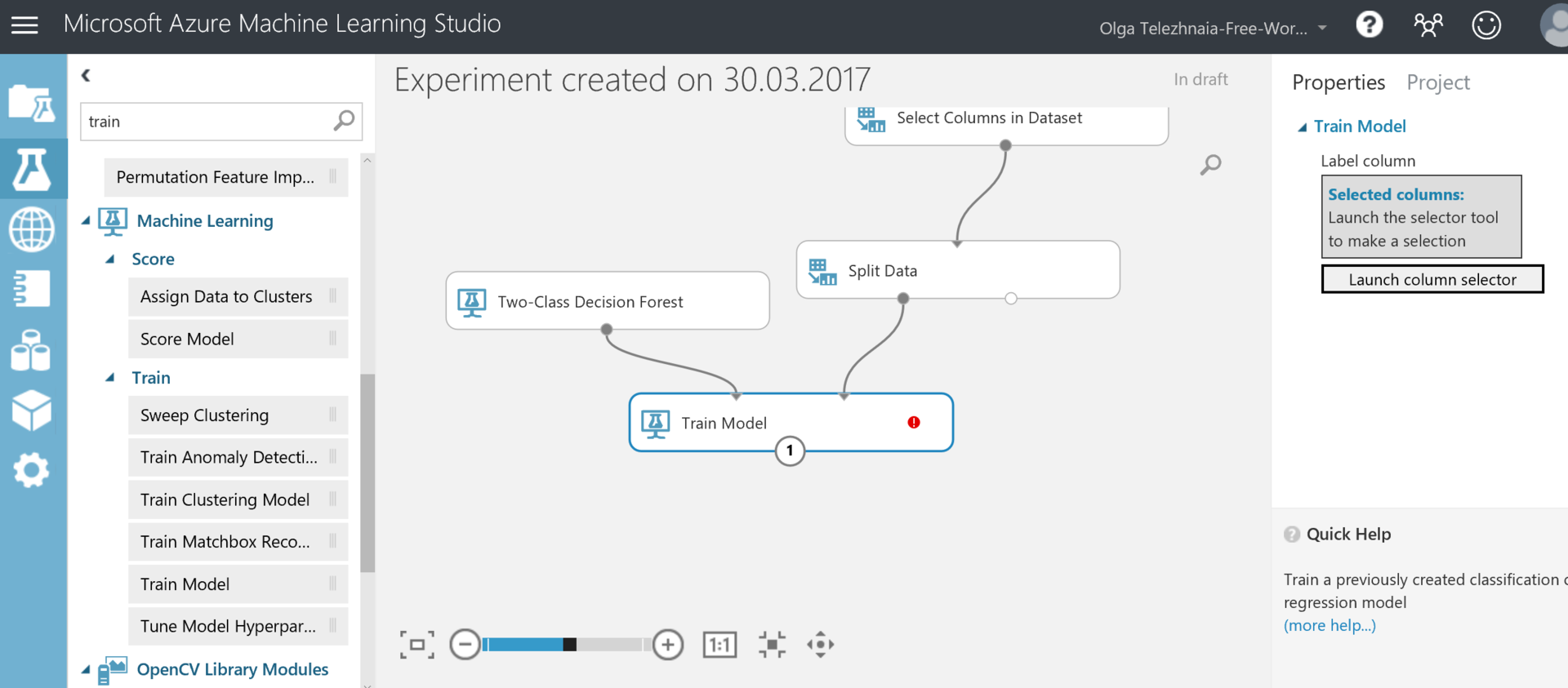
Train Modelブロックでは、Launch Column Selectorをクリックして、予測する列(この場合はArrDel15)を選択する必要もあります。
- テストパーツを使用して、結果のモデルを検証します。
Score Modelブロックは、これに対処するのに役立ちます。 分割後のデータの2番目の部分にも接続することを忘れないでください。
今日の最後のブロック-モデルの評価-は、便利な形式で結果を表示します。 結果のグラフは次のようになります。
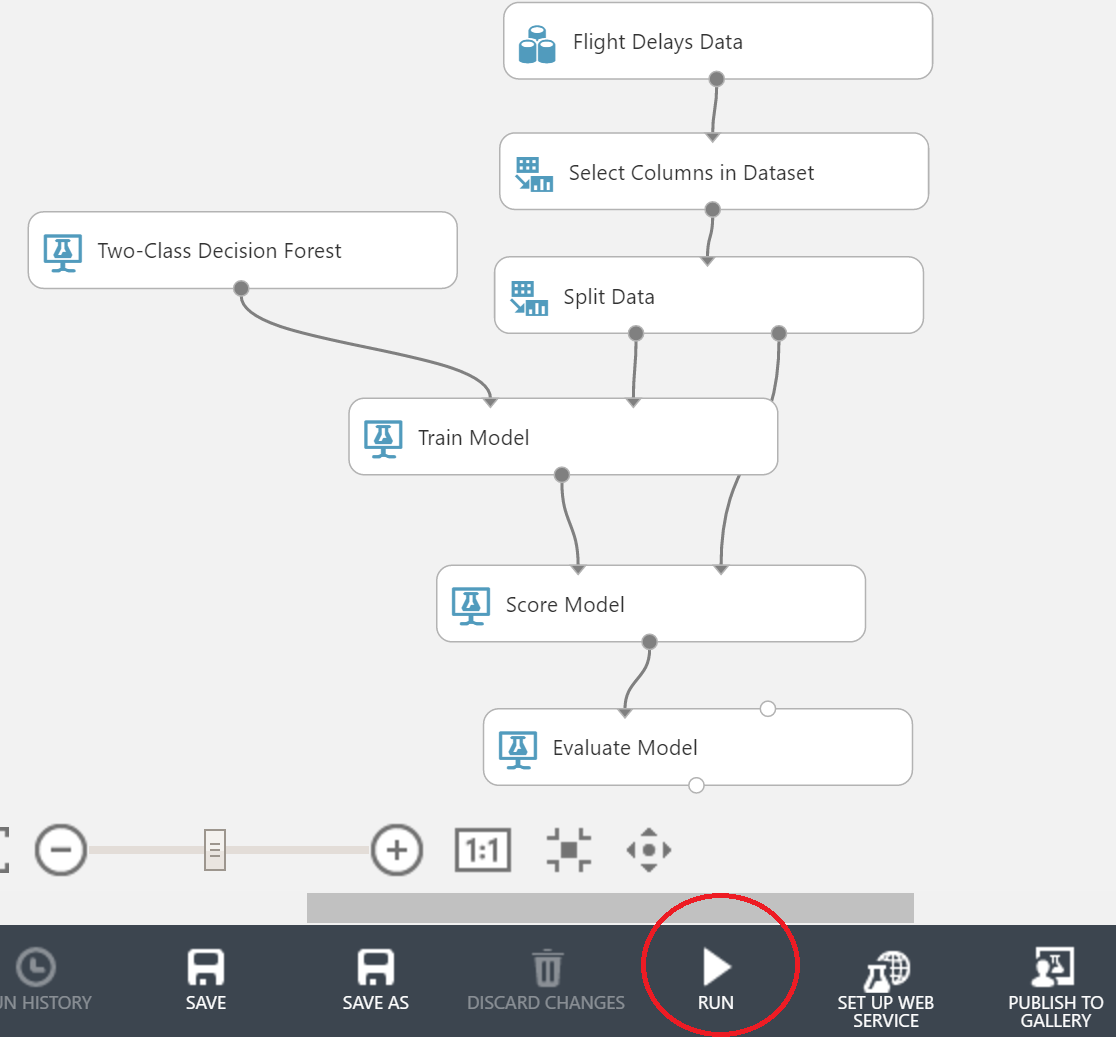
誇らしげに実行ボタンを押して、お茶を飲みに行きましょう。 クラウドであっても、学習は最速のプロセスではありません。
お茶がすでに終了しているが、プロセスが終了していない場合は、モデルの学習成果の質に関するデータを読み取るのに役立つ資料をいくつか検討することをお勧めします。
これは、線形依存のArrDelay列をデータから削除しなかった場合に確認できるものです。 モデルは完全に予測し、一度も間違えていません。 私はこれを見て、とげとげしい喜びの涙を流し、正直に言うと、再び実験を行いました)

しかし、ArrDelay列を削除すると、この結果が得られました。 さらに悪いことに、それは真実のように見えます。

- 品質に満足していますか? おめでとうございます! これで、実世界から新しいオブジェクトを取得でき、コンピューターはそれらに必要なすべてを予測します。 80%の予測精度を得ました。これは魔法ではありませんが、素晴らしいスタートです。
- 品質があなたに合わない場合は、タスクの最初に戻り、改善できるものを探します。
もちろん、プロセスを可能な限り簡素化しました。 データを準備し、それを部分に分割し、アルゴリズムを選択し、品質を測定する技術は何年も磨かれてきました。 それにもかかわらず、「わずか10分でゼロからモデルを組み立てる」という事実は、私に第二の風を与え、このトピックに対する大きな関心を蘇らせます。 しかし、ランダムフォレストではなく、SVMを使用するとどうなりますか? ところで、これらのアルゴリズムの違いを知っていますか? どちらも巨大な数学的基礎とかなり複雑な実装を備えていますが、誰もが一般的な考え方を理解できます。 願望があるでしょう;-)ところで、あなたはこのチートシートを勉強することから始めることができます。
私と同じように、私の記事があなたが苦しみを避け、MLに恋をするのに役立つことを願っています。 コメントであなたの意見や経験を共有してください、チャットするのは面白いでしょう!
より具体的なトピックに関する初心者向けの記事に興味がある場合は、コメントで報告してください。私は私の経験をより詳細に共有しようとします。 Evgeny Grigorenkoによる記事を読むこともできます。この記事では、経験豊富なユーザー向けのより実用的なシナリオを見つけることができます。