
少し前に 、マイクロベンチマーク用のC ++ライブラリについて書きました 。 Nonius、Haiai、Celeroの3つのライブラリについて話しました。 しかし、実際には、4番目について話したいと思いました。 その場合、私のWindowsはGoogle Benchmarkライブラリをサポートしていなかったため、テストできませんでした。 さいわい、前回の投稿のコメントから、ライブラリがVisual Studioで利用できるようになったことがわかりました。
使用方法を見てみましょう。
図書館
→ メインgithubリポジトリ
→ ディスカッション
KindDragon: appveyor commitでMSVCをサポートするおかげで、Visual Studioでライブラリを構築できます。 リポジトリから最新のコードを簡単にダウンロードし、CMakeを使用してソリューションファイルを生成し、必要なバージョンをコンパイルしました。 プロジェクトでライブラリを使用するには、ライブラリ自体と1つのヘッダーファイルを接続するだけです。
簡単な例
元の記事では、2つの実験を実施しました。
-
IntToStringConversionTest(count)
-1の範囲の整数を文字列に変換し、これらの文字列のベクトルを返します。 -
DoubleToStringConversionTest(count)
-0.12345 ... count-1 + 0.12345を文字列に変換し、文字列のベクトルを返します。
全体のベンチマークの例:
#include "benchmark/benchmark_api.h" #include "../commonTest.h" void IntToString(benchmark::State& state) { while (state.KeepRunning()) { benchmark::DoNotOptimize( IntToStringConversionTest(state.range_x()) ); } } BENCHMARK(IntToString)->Arg(TEST_NUM_COUNT1000); void DoubleToString(benchmark::State& state) { while (state.KeepRunning()) { benchmark::DoNotOptimize( DoubleToStringConversionTest(state.range_x()) ); } } BENCHMARK(DoubleToString)->Arg(TEST_NUM_COUNT1000); BENCHMARK_MAIN()
美しくシンプル!
BENCHMARK
マクロを使用してベンチマークを決定し、呼び出しパラメーターを追加できます。 上記の例では、
Arg
メソッドを使用しました。 このメソッドのパラメーターは状態オブジェクトに渡され、ベンチマーク関数で使用できます。 この例では、
state.range_x()
を使用してこの値を取得します。 次に、出力行ベクトルのサイズとして使用されます。
ベンチマーク関数内では、メインコードがwhileループで実行されます。 ライブラリは反復回数を自動的に選択します。
通常、アプリケーションはコンソールで実行され、次の結果が表示されます。

結論は非常に簡単です。ベンチマークの名前、ナノ秒単位の時間(
Unit()
メソッドを使用して変更可能)、CPU時間、完了した反復回数。
このライブラリはなぜこんなに優れているのですか?
- パラメーターを簡単に変更できます:Arg、ArgPair、Range、RangePair、Apply。
-
state.get_x()
、state.get_y()
を使用して値を取得できます - そのため、1次元および2次元空間でタスクのベンチマークを作成できます。
-
- 備品
- 複数の流量測定
- 手動時間管理:標準CPU時間を適用できないGPUまたはその他のデバイスでコードを実行する場合に役立ちます。
- 出力形式:テーブル、CSV、Json
-
state.SetLabel()
を使用してカスタムタグを追加する機能 -
state.SetItemsProcessed()
およびstate.SetBytesProcessed()
おかげで、処理されたオブジェクトと処理されたバイトのラベル
これは、1秒あたりのバイト数、1秒あたりのオブジェクト数、ラベル、および変更された時間単位でのベンチマーク出力の様子です。

複雑な例
ライブラリのマイクロベンチマークに関する別の投稿では、少し複雑な例を使用してライブラリをテストしました。 これは私の通常のベンチマークです-ポインターのベクトル対オブジェクトのベクトル。 Google Benchmarkを使用してこの例を実装できるかどうか見てみましょう。
カスタマイズ
テストするものは次のとおりです。
- パーティクルクラス-フロートタイプの18の属性が含まれます:動き(pos)を示す4、速度(vel)を示す4、加速(加速)を4、色(color)を4、時間(時間)を1回転のため。 また、可変数の要素を含むfloat型のバッファも用意します。
- 標準粒子は76バイトです
- 拡大粒子-160バイト
- パーティクルベクトルのUpdateメソッドの速度を測定します。
- 5種類のコンテナを使用します。
-
vector<Particle>
-
vector<shared_ptr<Particle>>
-メモリ内の配置のランダム化 -
vector<shared_ptr<Particle>>
-メモリ内の配置のランダム化なし -
vector<unique_ptr<Particle>>
-メモリ内の配置のランダム化 -
vector<unique_ptr<Particle>>
-メモリ内の配置のランダム化なし
-
いくつかのコード
vector<Particle>
サンプルコード:
template <class Part> class ParticlesObjVectorFixture : public ::benchmark::Fixture { public: void SetUp(const ::benchmark::State& st) { particles = std::vector<Part>(st.range_x()); for (auto &p : particles) p.generate(); } void TearDown(const ::benchmark::State&) { particles.clear(); } std::vector<Part> particles; };
そして、これがベンチマークです。
using P76Fix = ParticlesObjVectorFixture<Particle>; BENCHMARK_DEFINE_F(P76Fix, Obj)(benchmark::State& state) { while (state.KeepRunning()) { UpdateParticlesObj(particles); } } BENCHMARK_REGISTER_F(P76Fix, Obj)->Apply(CustomArguments); using P160Fix = ParticlesObjVectorFixture<Particle160>; BENCHMARK_DEFINE_F(P160Fix, Obj)(benchmark::State& state) { while (state.KeepRunning()) { UpdateParticlesObj(particles); } } BENCHMARK_REGISTER_F(P160Fix, Obj)->Apply(CustomArguments);
このコードを使用して、2つのタイプのパーティクルをテストします:小-76バイトおよび大-160バイト。 CustomArgumentsメソッドは、ベンチマークの各反復に対してパーティクルの数を生成します:1k、3k、5k、7k、9k、11k。
結果
この投稿では、ライブラリ自体に焦点を当てましたが、以前に尋ねられた質問-異なる粒子サイズの質問に答えたいと思います。 これまでのところ、76バイトと160バイトの2つのタイプのみを使用しました。
76バイトの結果:

ランダム化されたポインターは、オブジェクトベクトルよりもほぼ76%遅くなります。
160バイトの結果:
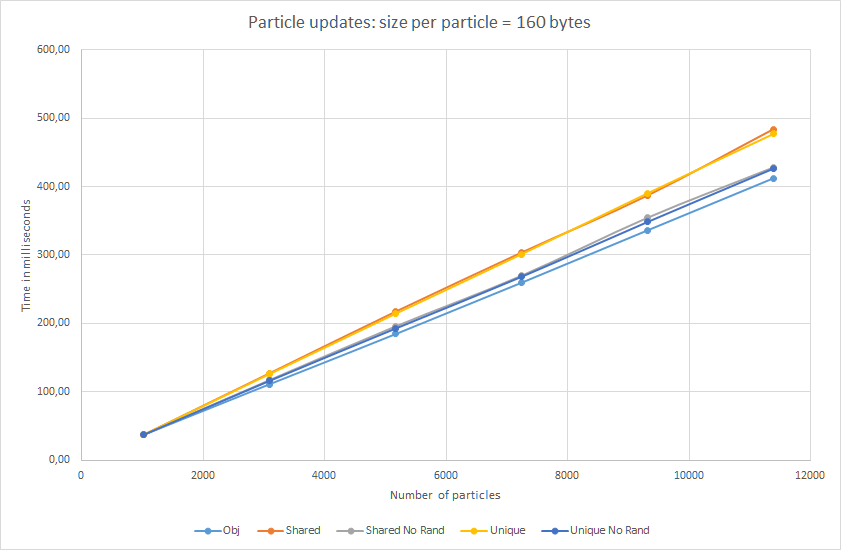
大きな粒子の場合、ほぼ直線! ランダム化されたポインターは、17%だけ遅くなります.... まあ、完全に直接ではありませんが:)
さらに、
unique_ptr
テストし
unique_ptr
。 ご覧のとおり、更新(データアクセス)に関しては、速度は
shared_ptr
とほぼ同じです。 したがって、間接的なアピールは、避けられないオーバーヘッドではなく、スマートポインターの問題です。
まとめ
コード例のあるリポジトリ
Google Benchmarkライブラリを使用するのに問題はありませんでした。 ベンチマークを書くための基本原則を数分で学ぶことができます。 マルチスレッドベンチマーク、フィクスチャ、反復回数の自動選択、CSVまたはJson形式での出力-これらはすべて基本的な機能です。 個人的には、ベンチマークコードにパラメーターを渡す柔軟性が最も気に入っています。 私がチェックした残りのライブラリには、問題領域のパラメーターをベンチマークに渡す際に問題がありました。 この観点から最も単純なものはCeleroでした。
おそらく、結果の拡張表示だけが欠けています。 ライブラリには、反復の平均実行時間のみが表示されます。 ほとんどの場合、これで十分です。
実験の観点から、さまざまなサイズの粒子について興味深い結果が得られました。 これは、将来の最終テストの基礎になる可能性があります。 さまざまなオブジェクトサイズでサンプルを書き直そうとします。 小さなオブジェクトの結果には大きな違いがあり、大きなオブジェクトの結果にはわずかな違いがあると予想しています。
ああ、仕事に来てくれませんか? :)wunderfund.ioは、 高頻度アルゴリズム取引を扱う若い財団です。 高頻度取引は、世界中の最高のプログラマーと数学者による継続的な競争です。 私たちに参加することで、あなたはこの魅力的な戦いの一部になります。
熱心な研究者やプログラマー向けに、興味深く複雑なデータ分析と低遅延の開発タスクを提供しています。 柔軟なスケジュールと官僚主義がないため、意思決定が迅速に行われ、実施されます。
チームに参加: wunderfund.io