
Tarantool DBMSのパフォーマンス、その機能と機能について多くの人がすでに聞いています。 たとえば、彼はクールなディスクストレージを持っています-Vinylに加えて、彼はJSONドキュメントの操作方法を知っています。 しかし、多数の出版物が1つの重要な機能をバイパスしています。 通常、データベースは単なるストレージと見なされますが、Tarantoolの特徴的な機能は、内部にコードを記述し、このデータを非常に効率的に使用できることです。 猫の下には、Igor igorcoding Latkinと共同で作成されたTarantool内に1つのシステムをほぼ完全に構築した方法の物語があります。
皆さんはMail.Ru Mailに出会ったことがありますが、おそらく他のメールボックスからの手紙のコレクションを構成することが可能であることをご存知でしょう。 これを行うために、OAuthプロトコルがサポートされている場合、サードパーティのサービスからユーザー名とパスワードをユーザーに求める必要はありません。 この場合、OAuthトークンがアクセスに使用されます。 さらに、Mail.Ru Groupには、サードパーティサービスによる承認も必要とする他の多くのプロジェクトがあり、ユーザーがこのアプリケーションまたはそのアプリケーションで作業するにはOAuthトークンを発行する必要があります。 トークンを保存および更新するためのこのようなサービスの開発に従事していました。
おそらく誰もがOAuthトークンが何であるかを知っています。 ほとんどの場合、これは3つまたは4つのフィールドの構造です。
{ "token_type" : "bearer", "access_token" : "XXXXXX", "refresh_token" : "YYYYYY", "expires_in" : 3600 }
- access_tokenを使用すると 、アクションを実行したり、ユーザーに関する情報を取得したり、友人のリストをダウンロードしたりできます。
- refresh_token 、新しいaccess_token 、および任意の番号を取得できます。
- expires_in-トークンの有効期限、または別の事前定義された時間のタイムスタンプ。 有効期限が切れたアクセストークンをお持ちの場合は、リソースにアクセスできません。
次に、サービスのおおよそのアーキテクチャを検討します。 単にトークンをサービスに挿入して読み取るフロントエンドがいくつかあり、refreshersと呼ばれる別のエンティティがあると想像してください。 リフレッシャーのタスクは、有効期限が切れる頃に新しいaccess_token
OAuthプロバイダーに移動することです。

基本構造も非常に単純です。 2つのデータベースノード(マスターレプリカとスレーブレプリカ)があります。 垂直バーは、データセンターの条件付き分離を表します。 1つのデータセンターには、フロントエンドと冷蔵庫を備えたマスターがあり、もう1つのデータセンターには、マスターに行くフロントエンドと冷蔵庫を備えたスレーブがあります。
困難は何ですか?
主な問題は、トークンが存続する時間(1時間)です。 プロジェクトを見ると、考えが浮かび上がってきます。「それは高負荷スケールですか?1時間以内に更新する必要がある1,000万件のレコードですか? 分割すると、3000程度のRPSが得られます。」 問題は、何かの更新が止まった瞬間に始まります。たとえば、ベースのメンテナンス、クラッシュ、車のクラッシュなど、何でも起こります。 事実、何らかの理由でサービス(マスターベース)が15分間機能しない場合、25%の停止が発生します。 データの4分の1が無効であり、更新されていないため、使用できません。 サービスが30分である場合、更新なしでデータの半分は既にあります。 時間-有効なトークンは1つではありません。 ベースが1時間置かれたと仮定すると、それを引き上げたため、1,000万個すべてのトークンを非常に迅速に更新する必要があります。 これは3000 RPSではなく、非常に負荷の高いサービスです。
最初はすべてが正常に処理されたと言わなければなりませんが、発売後2年で、別のロジックとインデックスを追加し、セカンダリロジックを追加し始めました。一般に、Tarantoolはプロセッサを使い果たしました。 予想外でしたが、どのリソースも使い果たすことができます。
初めて管理者が助けてくれました。 私たちが見つけた最も強力なプロセッサをインストールしました。これにより、さらに6か月間成長できましたが、この間に問題を何らかの形で解決する必要がありました。 私たちは新しいTarantoolに出会いました(システムは古いTarantool 1.5で書かれており、Mail.Ruグループ以外ではほとんど見られません)。 Tarantool 1.6には、その時点で既にマスターとマスターのレプリケーションがありました。 そして最初に思いついたのは、3つのデータセンターにデータベースのコピーを配置し、それらの間でマスターマスタレプリケーションを開始すると、すべてがうまくいくことです。
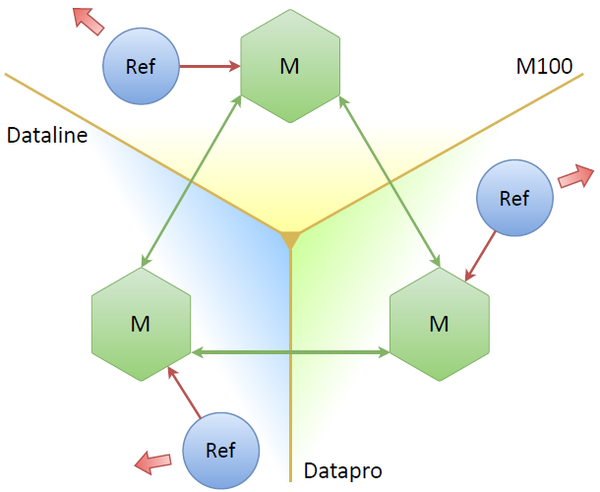
3人のマスター、3つのデータセンター、3つのリフレッシャー。それぞれが自分のマスターと連携しています。 1つまたは2つドロップできますが、すべてが機能しているようです。 しかし、ここでの潜在的な問題は何ですか? 主な問題は、OAuthプロバイダーへのリクエスト数が3倍に増えていることです。 実質的に同じトークンを、そしてレプリカがある限り何度も控えます。 これはまったく当てはまりません。 明らかな解決策:ノード自体が、現時点でどのノードをリーダーにするかを何らかの方法で決定する必要があります(つまり、1つのレプリカのみからトークンを更新する)。
リーダーズチョイス
コンセンサスアルゴリズムはいくつかあります。 これらの最初のものはPaxosです。 かなり複雑なこと。 私たちは、それを基礎にして何かを簡単にする方法を適切に理解することができませんでした。 最後に、我々はいかだに落ち着きました。 これは非常に単純なコンセンサスアルゴリズムであり、切断時またはその他の理由で新しいリーダーが選択されるまで、リーダーを選択できます。 これが私たちのやり方です:

Tarantoolには、そのままRaftもPaxosもありません。 ただし、配信に含まれる既製のモジュール、net.boxを使用します。 このモジュールを使用すると、フルメッシュスキームに従ってノードを相互に接続できます。各ノードは他のすべてのノードに接続されます。 そして、すべてが簡単です。これらの接続の上に、Raftで説明されているリーダーを選択します。 その後、各ノードはプロパティを所有し始めます。それはリーダーまたはフォロワーのいずれかであるか、リーダーまたはフォロワーのいずれも表示されません。
Raftの実装が難しいと思われる場合は、サンプルのLuaコードを次に示します。
local r = self.pool.call(self.FUNC.request_vote, self.term, self.uuid) self._vote_count = self:count_votes(r) if self._vote_count > self._nodes_count / 2 then log.info("[raft-srv] node %d won elections", self.id) self:_set_state(self.S.LEADER) self:_set_leader({ id=self.id, uuid=self.uuid }) self._vote_count = 0 self:stop_election_timer() self:start_heartbeater() else log.info("[raft-srv] node %d lost elections", self.id) self:_set_state(self.S.IDLE) self:_set_leader(msgpack.NULL) self._vote_count = 0 self:start_election_timer() end
ここでは、リモートサーバー、他のTarantoolレプリカ、ノードから受け取った投票数をリクエストします。 定足数がある場合、彼らは私たちに投票し、私たちはリーダーになり、ハートビートを開始します-私たちは他のノードに私たちが生きていることを知らせます。 選挙に敗れた場合、再度選挙を開始します。 しばらくすると、投票または選出できるようになります。
クォーラムを受け取ってリーダーを決定したら、すべてのノードにリフレッシャーを送信できますが、同時に、リーダーとのみ連携するように指示します。
このようにして、通常のトラフィックを取得します。 タスクは1つのノードによって割り当てられるため、約3分の1が各リフレッシャーに移動します。ここでのみ、マスターを安全に失うことができます-再選が発生し、リフレッシャーは別のノードに切り替わります。 しかし、他の分散システムと同様に、クォーラムに問題が発生します。
「放棄された」ノード
データセンター間の接続が失われた場合、システムを引き続き稼働させるメカニズムと、システムの整合性を復元するメカニズムが必要です。 Raftはこの問題を解決します。
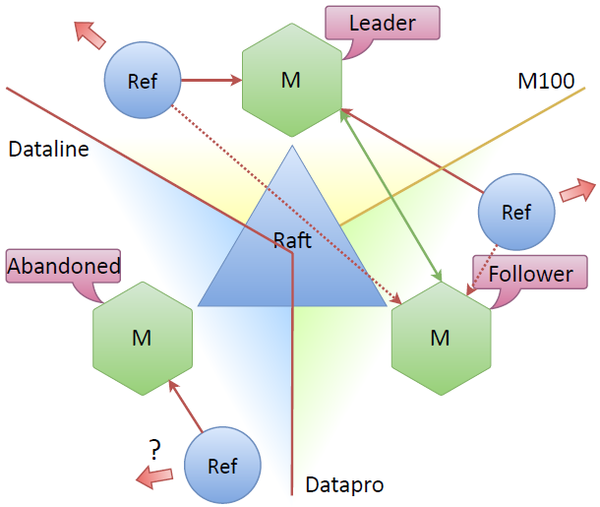
Datalineデータセンターがなくなったとしましょう。 そこに立っているノードは「放棄」になり、他のノードは見えません。 クラスターの残りの部分は、ノードが失われ、再選が行われていることを認識します。リーダーは、クラスター内の新しいノード、たとえば最上位ノードです。 ノード間のコンセンサスがまだ残っているため、システムは引き続き機能します。 半分以上のノードがお互いを認識します。
主な質問は、接続が失われた過去のデータセンターにあるリフレッシャーはどうなりますか? Raft仕様には、このようなノードの個別の名前はありません。 通常、クォーラムまたはリーダーとの通信を持たないノードは非アクティブです。 しかし、結局のところ、彼はまだネットワークに行き、トークンを個別に更新できます。 通常、トークンは接続モードで更新されますが、「放棄された」ノードに接続されているリフレッシャーでトークンを更新することは可能ですか? 最初は、トークンを更新することが理にかなっているかどうかは明らかではありませんでしたか? 不要な更新操作はありますか?
システムの実装プロセスでこの問題に対処しました。 最初の考えは、コンセンサス、クォーラムがあり、クォーラムから誰かを失った場合、更新を実行しないことです。 しかし、その後、別のアイデアが浮上しました。 Tarantoolマスターマスター実装を見てみましょう。 ある時点で、両方がマスターである2つのノードがあるとします。 値が1である変数キーXがあります。同時に、レプリケーションがこのノードに到達するまで、このキーを同時に2つの異なる値に変更するとします:1つのノードに2つ、もう1つのノードに3つ。レプリケーションログ、つまり値を交換します。 一貫性という点では、このようなマスター/マスター実装はある種の恐怖です。Tarantool開発者は私を許します。
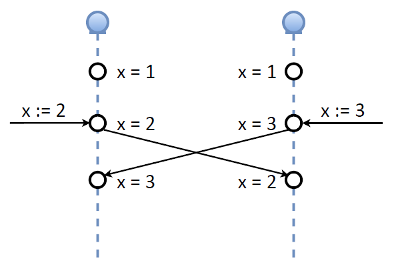
厳密な一貫性が必要な場合、これは機能しません。 ただし、2つの重要な部分で構成されるOAuthトークンを思い出してください。
- 条件付きで無期限に生きるリフレッシュトークン
- およびアクセストークン-1時間有効です。
ただし、同時に、リフレッシャーにはリフレッシュ機能があり、リフレッシュトークンからいつでも任意の数のアクセストークンを取得できます。 そして、彼らはすべて発行日から1時間以内に行動します。
スキームを考えてみましょう。2つのノードがリーダーと正常に動作し、トークンを更新し、最初のアクセストークンを受け取りました。 彼は複製し、今では誰もがこのアクセストークンを持っています。 ギャップがあり、フォロワーは「放棄された」ノードになり、クォーラムを持たず、リーダーも他のフォロワーも見えません。 同時に、リファラーが「放棄された」ノードに存在するトークンを更新できるようにします。 ネットワークがない場合、回線は機能しません。 しかし、単純な分割(ネットワークが破れている)であれば、この部分は自律的に機能します。
切断が終了してノードが参加すると、再選挙が行われるか、データが交換されます。 同時に、2番目と3番目のトークンは等しく「良好」です。
クラスターが再結合された後、次の更新手順は1つのノードでのみ実行され、複製されます。 つまり、しばらくの間、クラスターが分割され、それぞれが独自の方法で更新され、再結合後、通常の一貫したデータに戻ります。 これにより、次のことがわかります。通常、クラスターにはN / 2 + 1個のアクティブノードが必要です(3つのノードの場合、これらは2つです)。 私たちの場合、システムが機能するには少なくとも1つのアクティブノードで十分です。 必要なだけ正確にリクエストが送信されます。
リクエストの数を増やす問題について話しました。 スプリットまたはダウンタイムの時間については、少なくとも1つのノードを存続させることができます。 更新し、データを追加します。 これが最終的な分割である場合、つまり、すべてのノードが分割され、全員がネットワークを持っている場合、OAuthプロバイダーへのリクエスト数が3倍になります。 しかし、イベントの期間が短いため、これは恐ろしいことではなく、常にスプリットモードで作業するつもりはありません。 通常、システムはクォーラム、接続状態にあり、通常はすべてのノードが機能します。
シャーディング
1つの問題がありました-CPUの天井にぶつかりました。 明らかな解決策:シャーディング。

データベースが2つあり、それぞれが複製されているとしましょう。 いくつかのキーが入力に来る特定の機能があり、このキーによって、データがどのシャードにあるかを判別できます。 電子メールでシャードする場合、アドレスの一部は1つのシャードに保存され、別のシャードにはいくつかのアドレスが保存され、データの場所が常にわかります。
シャーディングを実装するには、2つのアプローチがあります。 最初はクライアントです。 CRC32キー、Guava、Sumburなどの数字、シャードを返す一貫したハッシュ関数を選択します。 この機能は、すべてのクライアントに等しく実装されています。 このアプローチには明確な利点があります。データベースはシャーディングについて何も知りません。 ベースを上げて標準として機能し、シャーディングは側面のどこかにあります。
しかし、重大な欠点があります。 まず、顧客はかなり太っている。 新しいものを作成する場合は、シャーディングロジックを追加する必要があります。 しかし、最悪の問題は、あるスキームに従って動作するクライアントもあれば、別のスキームに従って動作するクライアントもあるということです。 同時に、基地自体はあなたがさまざまな方法で恥ずかしがり屋であるという事実について何も知りません。
別のアプローチを選択しました-データベース内でのシャーディング。 この場合、コードはより複雑になりますが、単純なクライアントを使用できます。 このデータベースに接続するクライアントはすべてのノードに移動し、そこで接続するノードと転送するコントロールを計算する関数がそこで実行されます。 クライアントは単純です-データベースはより複雑ですが、同時にそのデータに対して完全に責任があります。 さらに、最も難しいのはリシャーディングです。 データベースがそのデータに責任を負う場合、リシャーディングは、まだ更新できないクライアントがある場合よりもはるかに簡単です。
これをどうやってやったの?
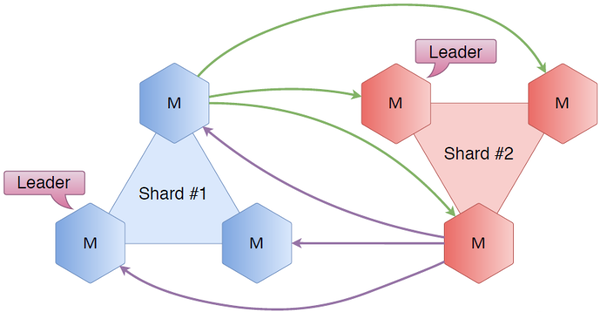
六角形はタランツールです。 3つのノードを取り、シャード番号1を呼び出します。 まったく同じクラスターを配置し、シャード番号2を呼び出します。 すべてのノードを互いに接続します。 それは何を与えますか? まず、Raftがあります。トリプルのサーバー内で、誰がリーダー、誰がフォロワー、クラスターの状態を把握しています。 新しいシャーディング接続のおかげで、エイリアンのシャードの状態がわかりました。 誰がセカンドシャードのリーダーであり、誰がフォロワーであるかなどを完全に知っています。 一般的なケースでは、最初のシャード以上のものが必要な場合、最初のシャードに来たユーザーをどこにリダイレクトするかを常に知っています。
簡単な例を考えてみましょう。
ユーザーが最初のシャードにあるキーを要求するとします。 彼は最初の破片から結び目に入ります。 なぜなら 彼はリーダーが誰であるかを知っており、リクエストはリーダーにリダイレクトされ、キーを受け取ったり書き込んだりして、応答がユーザーに返されます。
ここで、ユーザーが同じノードに来て、実際に2番目のシャードにあるキーが必要だとします。 同じこと:最初のシャードは、2番目のシャードが誰であるかを知っており、このノードに行き、データを受信または書き込み、ユーザーに戻ります。
非常に単純なスキームですが、それには困難があります。 主な問題:接続が多すぎますか? スキームでは、各ノードがそれぞれに接続されると、6 * 5-30の接続が取得されます。 シャードをもう1つ入れます-クラスターで既に72の接続を取得しています。 多すぎる。
この問題を次のように解決します。Tarantoolsをいくつか配置し、シャードまたはベースではなく、シャーディングのみを扱うプロキシを呼び出します。キーを計算し、このシャードまたはそのシャードのリーダーを見つけ、Raftがクラスター化します。内向的であり、破片自体の内部でのみ機能します。 クライアントがプロキシに来ると、クライアントは必要なシャードを計算し、リーダーが必要な場合はリーダーにリダイレクトします。 誰でもかまわない場合は、このシャードから任意のノードにリダイレクトします。

ノードの数に応じて、複雑さは直線的です。 各ノードに3つのノードを持つ3つのシャードがある場合、接続は何倍も少なくなります。
プロキシスキームは、3つ以上のシャードがある場合にさらにスケーリングするように設計されています。 シャードが2つある場合、接続の数は同じですが、シャードの数が増えると、接続が大幅に節約されます。 シャードのリストはLua configに保存されます。新しいリストを取得するには、コードをリロードするだけですべてが機能します。
そこで、私たちはmaster-masterから始め、Raftを実装し、それにシャーディングをねじ込み、その後プロキシですべてを書き直しました。 それはレンガ、クラスターになりました。 回路は非常にシンプルになりました。
私たちのフロントエンドは残っており、トークンを入れたり受け取ったりするだけです。 トークンを更新し、リフレッシュトークンを取得し、OAuthプロバイダーに渡し、新しいアクセストークンを配置するリフレッシャーがあります。
プロセッサリソースが不足したため、まだセカンダリロジックがあると言いました。 別のクラスターに転送してみましょう。
このような2次ロジックには、主にアドレス帳が含まれます。 ユーザートークンがある場合、このユーザーのアドレス帳はそれに対応します。 そして、量に関するデータはトークンと同じくらい多くあります。 1台のマシンでプロセッサリソースが不足しないようにするには、明らかに同じクラスターが必要で、再度複製する必要があります。 アドレス帳を既に更新するために、他のリフレッシャーを多数配置します(これはまれなタスクなので、アドレス帳をトークンで更新しません)。
その結果、このような2つのクラスターを組み合わせて、システム全体の非常に単純なアーキテクチャを取得しました。
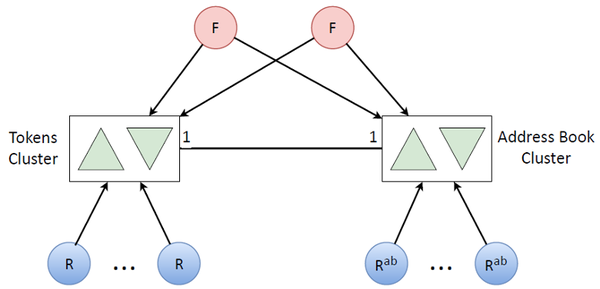
トークン更新キュー
なぜ私たちはターンをしたのですか? 標準的なものをとることは可能でした。 ポイントは、トークン更新モデルにあります。 トークンを受け取った後、それは1時間生きます。 アクションの終了時が来たら、更新する必要があります。 これが期限待ち行列です。トークンは一定時間前に更新する必要があります。

短期的であろうとなかろうと、停止が発生したと仮定しますが、一定量の期限切れトークンがあります。 それらを更新すると、さらにいくつかは廃止されます。 もちろん、すべてに追いつきますが、最初に(60秒後に)死にそうなものを更新し、次に残りのリソースで既に死んだものを更新する方が良いでしょう。 最後に、遠い地平線(死まで5分)を更新します。
サードパーティにこのロジックを実装するには、汗をかかなければなりません。 Tarantoolの場合、これは非常に簡単です。 単純なスキームを考えてみましょう。Tarantoolデータが配置されているタプルがあり、ある種の識別子IDがあり、それによって主キーがあります。 そして、必要なキューを作成するには、ステータスと時間の2つのフィールドを追加するだけです。 ステータスは、キュー内のトークンの状態を示します。時間は同じ有効期限です。
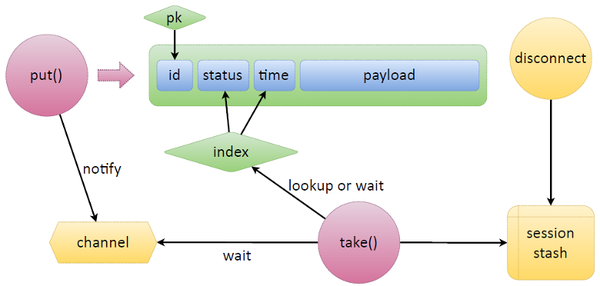
キューから2つの主要な関数、 put
とtake
ましょう。 put
のタスクは、データを持ってくることです。 何らかのペイロードを提供し、 put
自体がステータス、時間を設定し、データを配置します。 新しいtuple
が表示されます。
take
に来take
、インデックスを見てください。 イテレータを作成し、調べ始めます。 待機中のタスク(準備完了)を選択し、それらを取得する時間が来たかどうか、または期限切れかどうかを確認します。 タスクがない場合、 take
はスタンバイモードになります。 Tarantoolの組み込みLuaに加えて、ファイバー間の同期のプリミティブ(チャネル)もあります。 どんなファイバーでもチャネルを作成して、「私はここで待っています」と言うことができます。 他のファイバーは、このチャネルをウェイクアップして、メッセージを送信できます。
タスクを解放する、時間の到来、または他の何かを待つ関数は、チャネルを作成し、特別な方法でラベルを付け、どこかに配置してから待機します。 緊急に更新する必要のあるトークンを私たちに持ってきたら、例えばput
、そしてこのチャンネルに通知を送信します。
Tarantoolには1つの特徴があります:何らかのトークンが誤ってリリースされた場合、誰かがそれをリフレッシュに使用したり、タスクを実行したりすると、クライアント接続の切断を追跡できます。 セッションスタッシュでは、どの接続がどのタスクを発行したかを覚えています。 このようなタスクをこのセッションに関連付けます。 更新プロセスがクラッシュし、ネットワークが破壊されたと仮定します-トークンを更新するかどうか、戻すことができるかどうかはわかりません。 切断がトリガーされ、セッション内のすべてのタスクが検出され、自動的に解放されます。 put
, .
, :
function put(data) local t = box.space.queue:auto_increment({ 'r', --[[ status ]] util.time(), --[[ time ]] data --[[ any payload ]] }) return t end function take(timeout) local start_time = util.time() local q_ind = box.space.tokens.index.queue local _,t while true do local it = util.iter(q_ind, {'r'}, { iterator = box.index.GE }) _,t = it() if t and t[F.tokens.status] ~= 't' then break end local left = (start_time + timeout) - util.time() if left <= 0 then return end t = q:wait(left) if t then break end end t = q:taken(t) return t end function queue:taken(task) local sid = box.session.id() if self._consumers[sid] == nil then self._consumers[sid] = {} end local k = task[self.f_id] local t = self:set_status(k, 't') self._consumers[sid][k] = { util.time(), box.session.peer(sid), t } self._taken[k] = sid return t end function on_disconnect() local sid = box.session.id local now = util.time() if self._consumers[sid] then local consumers = self._consumers[sid] for k,rec in pairs(consumers) do time, peer, task = unpack(rec) local v = box.space[self.space].index[self.index_primary]:get({k}) if v and v[self.f_status] == 't' then v = self:release(v[self.f_id]) end end self._consumers[sid] = nil end end
Put
space
, , , FIFO-, , .
take
, : . taken
, — , . on_disconnect
, , .
?
もちろん。 . , , . , . , . ( ). . , , , , , in memory, .
, , . — 7 tuple, . , .
まとめると
outage, . .
. N 2 , -: , - . : Google, Microsoft, - OAuth-, .
, , , . Tarantool . ありがとう