
はじめに
近年、ユビキタスニューラルネットワークはさまざまな知識分野でますます多くのアプリケーションを発見し、長年使用されてきた古典的なアルゴリズムに取って代わりました。 コンピュータービジョンの分野も例外ではありません。そこでは、現代のニューラルネットワークの助けを借りて、年々、より多くのタスクが解決されています。 戦争で倒れた別の戦闘機、伝統的なビジョン対ディープラーニングについて書く時です。 1999年に提案されたSIFT(Scale-invariant Feature Transform)アルゴリズムは、長年にわたり、画像の局所的な特徴(いわゆるキーポイント)を検索するタスクで最高位に君臨し、多くの人が頭を折り返してそれを超えようとしましたが、成功したのは深層学習のみでした。 それでは、新しいローカルフィーチャ検索アルゴリズム-LIFT(Learned Invariant Feature Transform)に会ってください。
データの必要性

ディープラーニングが機能するためには、大量のデータが必要です。そうしないと、魔法が機能しません。 そして、すべての種類のデータは必要ありませんが、解決したい問題の代表的な表現となるデータです。 それでは、特異点の人工検出器/記述子ができることを見てみましょう:
- 画像内の位置に対する不変性。
- 回転角に対する不変性。
- スケールに対する不変性。
さて、ポイントの集合を含むデータセットが必要です。特定のポイントごとに、さまざまな角度から受信したサンプルがたくさんあります。 もちろん、任意の写真を撮り、そこからドットを切り取り、合成的に生成されたアフィン変換を使用して、任意の大きなサイズのデータセットを取得できます。 しかし、モデリングの精度には常にいくつかの制限があるため、合成は悪いです
実際のケース。 コンピュータビジョンのいくつかの適用された問題を解決するときに、要件を満たす実際のデータセットが発生します。 たとえば、いくつかの角度から撮影されたシーンの3D再構築の場合、次のようなことを行います。
- シーンの各画像について、特別なポイントを見つけます。
- 異なる画像からの特異点間の対応を見つけます。
- ただし、この情報に基づいて、各フレームの空間位置を計算します( [R、t] つまり 原点に対する回転と平行移動)。
- 三角形分割手順を使用して、すべての特異点の3D位置を見つけます。
- 分岐最適化aki バンドル調整 (ほとんどの場合、Levenberg-Marquardt法から派生したアルゴリズム)を使用して、空間内のポイントの位置に関するより正確な情報を取得します。
- さまざまな後処理。 たとえば、ポリゴンモデルをポイントクラウドにプルして、滑らかなサーフェスを取得できます。
このようなアルゴリズムの操作の副産物として、各クラウドのポイントが取得されます。各クラウドの3Dポイントは、シーンフレーム上の2D位置(投影)のいくつかに対応しています。 このクラウドは、必要なデータセットにすぎません。 特にStructure From Motionの複雑さに煩わされることなく、著者は3D再構築のために公開されているいくつかのデータセットを取得し、公開されている点群構築ツール(VisualSFM)を介して実行し、取得したデータセットを実験で使用しました。 伝えられるところでは、そのようなセットでトレーニングされたグリッドは、他のタイプのシーンにも一般化されています。
ネット、ネット、ネット
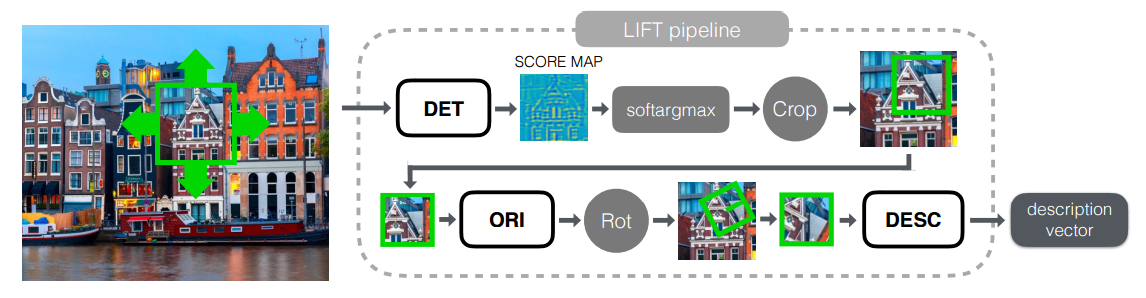
データセットを理解したので、最も興味深いもの、つまりグリッドの研究に移りましょう。 グリッド全体を3つの論理ブロックに分割できます。
- 検出器-画像全体の特別なポイントを検索します。
- Rotation Estimator-ポイントの方向を決定し、回転角度がゼロになるようにパッチをその周りに回転させます。
- 記述子-パッチを入力として受け入れ、このパッチを記述する一意の(動作方法)ベクトルを構築します。 これらのベクトルは、たとえば、一対のポイント間のユークリッド距離を計算し、それらが類似しているかどうかを理解するために既に使用できます。
まず、このモデル全体の推論を検討し、次にすべてのブロックを個別に検討し、どのように正確にトレーニングするかを検討します。
推論
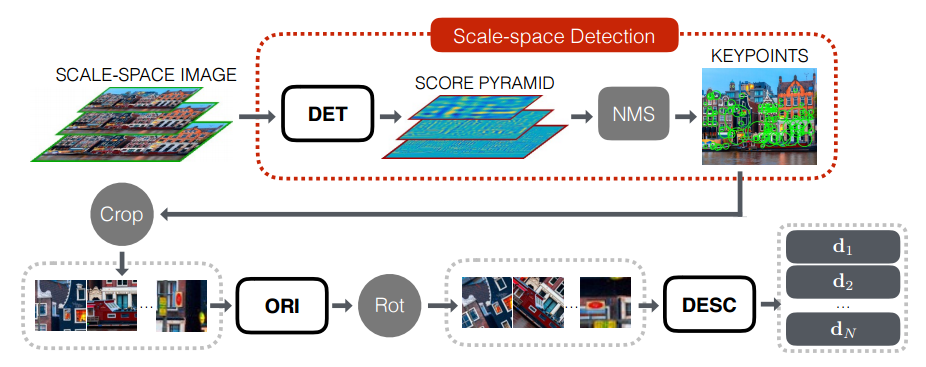
特異点の検索とその記述子の計算は、いくつかの段階で行われます。
- 最初に、元の画像の画像ピラミッドを構築します(つまり、元の画像をいくつかの縮尺に縮小して、縮尺特徴に不変の特徴を取得します)。
- ピラミッドの各レイヤーを検出器ネットワークで実行し、スコアマップピラミッドを計算します。
- 非最大抑制手順を使用して、特定のポイントの最強の候補を見つけます。
- 特異点ごとに、特異点とその近傍を含むパッチを切り取ります。
- 各パッチの向きをOrientation Estimatorに合わせます。
- アラインされたパッチごとに記述子を計算します。
- 受信した記述子を、標準機能のマッチング手順に使用します。
記述子
SIFTの機能以来、真にユニークなポイントを見つけるのが特に得意ではないが、それらのそれぞれに対してクールな記述子を構築できる場合でも、問題を解決できる可能性が高いことが知られています。 したがって、レビューは最後から、つまり、すでに見つかった特異点の記述子の構築から始めます。 一般的に、画像(パッチ)を入力としてとる畳み込みグリッドは、この画像の特定の記述を出力します。これは既に記述子として使用できます。 しかし、実践が示すように、たとえばVGG16、ResNet-152、Inceptionなどの巨大なネットワークを使用する必要はありません。小さなネットワークで十分です:双曲線正接の形でアクティブ化される2〜3の畳み込み層
正規化バッチなどのその他の小さなもの
明確にするために、ネットワーク記述子を示します d=hp(p theta) どこで h(...) -記述子畳み込みネットワーク、 p -そのパラメーター、 p theta -角度がゼロのパッチ(回転推定器から取得)。
特異点ごとに、2つのペアを作成します。
- (p1 theta、p2 theta) -同じ特異点の投影に対応するパッチのペア。
- (p1 theta、p3 theta) -パッチのペア。最初のパッチは特異点に属し、2番目のパッチは特異点に属します。 同時に、「ネガティブ」パッチは、ポジティブからそれほど離れていない特定の近傍から選択されます。 トレーニングのプロセスでは、近傍が減少するため、負のサンプルはより困難になります。
学習プロセスでは、次の形式の損失関数を最小化します。
Ldesc(pk theta、pl theta)= begincases |hp(pk theta)−hp(pl theta) |2、\正の場合max(0、C− |hp(pk theta)−hp(pl theta) |2)、\ネガの endcases
つまり 実際、類似ポイント間のユークリッド距離を小さくし、互いに類似していないポイント間の距離を遠くにしたいと考えています。
回転推定器
空間の異なるポイントからだけでなく、異なる傾斜角からも同じポイントを観察できるため、観察する角度に関係なく、同じ特異点に対して同じ記述子を構築できる必要があります。 しかし、Descriptorに同じポイントのすべての可能な傾斜角を記憶するように教える代わりに、空間内のパッチの方向を決定する中間計算ユニット(Rotation Estimator)を使用して、回転に不変な独自の状態にパッチを「回す」ことを提案します(Spatial変換)。 もちろん、SIFT特徴を構築するためのアルゴリズムから取得した空間内のパッチの方向を計算するためにユニットを使用できますが、21世紀の窓の外では、コンピュータービジョンのタスクを機械学習に減らすことが一般的です。 そこで、別の畳み込みニューラルネットワークを使用してこの問題を解決します。
したがって、ニューラルネットワークを次のように示します。 theta=g phi(p) どこで phi -ネットワークパラメータ、および p -ソースパッチ。
トレーニングサンプルとして、パッチのペアを取ります P1 、 P2 1つの特異点に属するが、異なる傾斜角と空間座標を持つ x1 、 x2 。
学習プロセスでは、次の損失関数を最小化します。
L方向(P1、x1、P2、x2)= |hp(G(P1、x1))−hp(G(P2、x2)) |2
どこで G(p、x) -向きを修正する手順の後に受け取ったパッチ、 G(P、x)=Rot(P、x、g phi(クロップ(P、x))) 。
つまり ネットワークをトレーニングするとき、記述子間のユークリッド距離が最小になるように、異なる傾斜角でパッチをラップします。
検出器
最後のステップ、つまり、元の画像の特異点の直接検出を検討する必要があります。 このネットワークの本質は、画像全体がそれを介して駆動されることであり、出力では、特定の特徴マップが期待されます。その特徴点は、元の画像の特別な点に対応します。
モデルの推論により、検出器は画像全体で一度に起動しますが、トレーニング中に個々のパッチに対してのみ実行します。
検出器の計算は2つのステップで構成されます。最初に、パッチのスコアマップを計算する必要があります。次に、特異点の位置を決定します。
S=f mu(P)= sumNn betan maxMm(Wmn∗P+bmn)
次に、特異点の位置を計算します。
x=softargmax(S)
どこで softargmax 計算の結果の重みで重み付き重心を計算する関数です softmax :
softargmax(S)= frac sumy exp( betaS(y))y sumy exp( betaS(y))
ここで、yはスコアマップ内の位置です \ベータ -softmax関数の「ぼやけ」の係数を担当するハイパーパラメーター。
検出器をトレーニングするとき、4つのパッチを使用します (P1、P2、P3、P4) どこで P1、P2 -同じ特異点の投影、 P3 -別の特異点の投影、 P4 -特定のポイントに属さないパッチ。 このようなパッチを収集するには、次の損失関数を最小化します。
L検出器(P1、P2、P3、P4)= gammaLクラス(P1、P2、P3、P4)+Lペア(P1、P2)
どこで \ガンマ -損失関数の2つのメンバーのバランス調整パラメーター。
正負の正しい分類を担当する損失会員:
Lclass(P1、P2、P3、P4)= sum4i=1 alphaimax(0、1−softmax(f mu(Pi))yi)2
特異点の正確なローカリゼーションを担当する損失メンバー:
Lpair(P1、P2)= |hp(G(P1、softargmax(f mu(P1)))))−hp(G(P2、softargmax(f mu(P2)))) |2
トレーニング
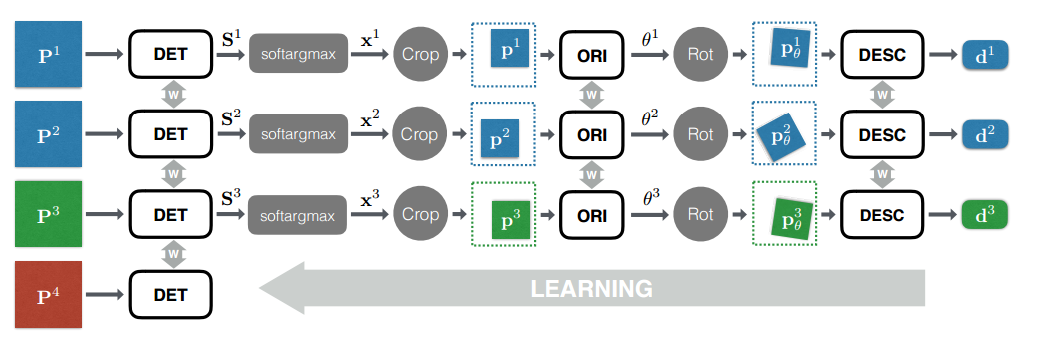
ネットワーク全体は、ファッショナブルな今日のエンドツーエンド方式でトレーニングされています。 シャムネットワークとしてネットワークのすべての部分を並行してすぐに学習します。 同時に、トレーニング中に使用される4つのパッチのそれぞれについて、重みがバランスされたネットワークの別個のブランチが作成されます。
実験
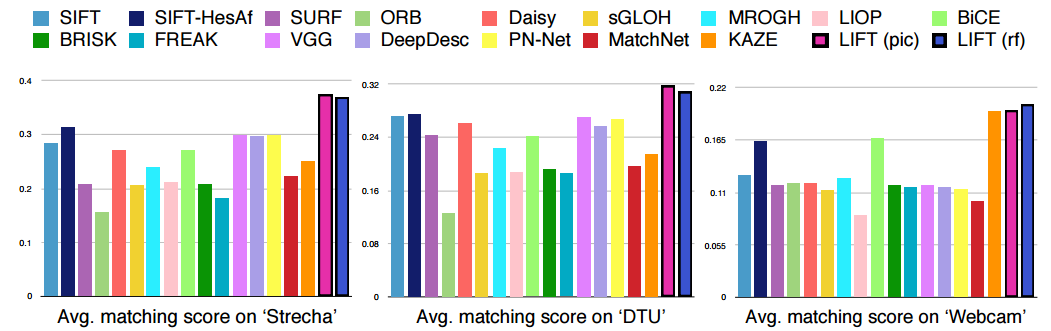
著者らは、特異点を見つけるために以前に利用可能な方法と比較して、彼らのアプローチは最先端であると結論付けました。
そして、彼らのネットワークの結果は次のビデオで見ることができます:
おわりに
提示された作品は、コンピュータービジョンの従来の方法の時代が過ぎているという事実のさらに別の確認であり、サンツの日付の時代に置き換えられています。 繰り返しになりますが、いくつかの難しい問題を解決する機知に富んだヒューリスティックを発明することを検討する必要があります。コンピューターが数百万のヒューリスティックを個別にソートし、タスクを最良の方法で解決するものを選択できるように問題を定式化することは可能ですか?
参照資料
- 元の記事はarxivで見つけることができます: LIFT:Learned Invariant Feature Transform
- Theanoの使いやすいコードはgithubにあります: https : //github.com/cvlab-epfl/LIFT
- 特異点の記述子を計算するためのシャムネットワークと同様のパイプラインのトレーニングについてですが、 ステレオマッチングのタスクに関しては、父親のJan LeCunからこちらを読むことができます: 畳み込みニューラルネットワークのトレーニングによるステレオマッチングによるイメージパッチの比較
ご清聴ありがとうございました。
PS投稿は、 サークルでの1つのディスカッションの結果であり、それに関連して著者の音節では十分な文学的ではない場合があります。