カタログは順序を意味します-階層は、情報を直接保存することを意味し、もちろん検索、おそらくアナリスト...他の何か? 他に何も思い浮かぶことはありません。
次に、ポイントごとに。
階層
確かに、情報のグループ化は、抽象的な「カタログ」からより具体的なもの、より具体的なもの(「ハンマー」など)まで、ツリーのようになります。 詳細のレベルは任意です。「セクション」、「サブセクション」、「カテゴリー」、「サブカテゴリー」のフレームワーク内に自分自身を保持することはせず、分岐の深さを無限にします。
情報は何らかのDBMSに格納され、階層で動作します。このDBMSは階層クエリを実行できる必要があります。そのようなDBMSは少なくありません。これらの中で最も一般的なのはPostgreSQLです。
DDLプレートツリー要素:
CREATE TABLE element_tree ( id SERIAL PRIMARY KEY NOT NULL, element_tree_id INTEGER, is_hidden INTEGER DEFAULT 0, insert_date TIMESTAMP WITH TIME ZONE DEFAULT now(), CONSTRAINT fk_element_tree FOREIGN KEY (element_tree_id) REFERENCES element_tree (id) ); CREATE INDEX ix_element_tree_element_tree_id_id ON element_tree (element_tree_id, id);
テーブル構造の説明
id-テーブル行識別子。
element_tree_id-ツリーの親要素への参照。
is_hidden-削除されたレコードのフラグ(0-有効なレコード、1-削除済み)、レコードを削除するのではなく、レコードのフラグが上がるのはなぜですか? ログで識別子に会ってそれが何であるかを知りたい場合、バックアップでこの選択を行うのではなく、現在のデータベースで選択を行うのが非常に便利です(このエントリがこのバックアップに存在するという事実ではありません)。
insert_date-レコードが追加された日付。これが100年前のレコードであるか、挿入が失敗した結果として5分前に挿入されたことがわかっている場合に便利です。
もちろん、システムに精通している人はこのすべて(is_hidden、insert_date)を実際に必要としませんが、システムを新しいゲートのラムとして見る人にとって、これらのフィールドは非常に有用であり、私は通常私の練習でラムの役割を果たします:)
CONSTRAINT fk_element_tree-それ自体への外部キー-親要素へのポインタ。
INDEX ix_element_tree_element_tree_id_id-子ブランチ(子孫ノード)を検索するためのインデックス。主キーで親を見つけた場合、子孫の高速検索のために別のインデックスが必要です。
経験豊富で上級者が気付くように、テーブルには要素名の列はありません。 なんで? また、階層は階層であり、ツリーのノードではなく、階層に結合されているテーブル、したがってテーブル内の名前、および階層内の要素のグループ化のみが順序付けられているためです。
情報の直接保存
最終的に、カタログは個々のカテゴリのリストです。 見出しは、固有の特性セットを持つエンティティの特定のグループです。 つまり、適切なエッセンスとグループ化されたエンティティ-ルブリックの関係があり、さらに、ルブリックはこれらのエンティティの固有の特性のグループ化でもあります。
つまり、情報は、エッセンス、特性、ルーブリックの3つの部分に分かれています。ルーブリックは、複数のエンティティと特性の接続ポイントです。
DBMS言語では、次のように聞こえます。
表の見出し
CREATE TABLE rubric ( id SERIAL PRIMARY KEY NOT NULL, code CHAR(100), title VARCHAR(4000), description VARCHAR(4000), is_hidden INTEGER DEFAULT 0, insert_date TIMESTAMP WITH TIME ZONE DEFAULT now() ); CREATE UNIQUE INDEX ux_rubric_code ON rubric (code);
エンティティテーブル(特定のピース。製品またはサービス、会社、または一般的なレポートなど)。
CREATE TABLE item ( id SERIAL PRIMARY KEY NOT NULL, code CHAR(100), title VARCHAR(4000), description VARCHAR(4000), is_hidden INTEGER DEFAULT 0, insert_date TIMESTAMP WITH TIME ZONE DEFAULT now() ); CREATE UNIQUE INDEX ux_item_code ON item (code);
テーブルの特性(プロパティ):
CREATE TABLE property ( id SERIAL PRIMARY KEY NOT NULL, code CHAR(100), title VARCHAR(4000), description VARCHAR(4000), is_hidden INTEGER DEFAULT 0, insert_date TIMESTAMP WITH TIME ZONE DEFAULT now() ); CREATE UNIQUE INDEX ux_property_code ON property (code);
ここに新しい列があります:
code-異なるマシンの識別子は異なる場合があり、同じようにわずかに退屈であることができるため、書き込みおよび要求および構成に識別子を書き込むための一意のコード(ニーモニック)はCamilleではありません。書き込みコードを使用する方がはるかに便利です。一連の識別子の数字よりも覚えやすく、マジックナンバーではなく単語を見るコードでは、何が起こっているかの本質がもう少し明確になります。
title-名前(nameはPostgreSqlのキーワードであるため、nameはtitleに置き換える必要がありました)。
description-説明(名前はリストから選択するために使用され、説明はレコードの目的の実際の説明用です)。
次に、これらすべての接続方法について説明します。
カタログ内の情報の構成
見出しは要素ツリーにドッキングされ、ドッキングは別のテーブルで行われます。
CREATE TABLE rubric_element_tree ( id SERIAL PRIMARY KEY NOT NULL, rubric_id INTEGER NOT NULL, element_tree_id INTEGER NOT NULL, insert_date TIMESTAMP WITH TIME ZONE DEFAULT now(), CONSTRAINT fk_rubric_element_tree_rubric_id FOREIGN KEY (rubric_id) REFERENCES rubric (id), CONSTRAINT fk_rubric_element_tree_element_tree_id FOREIGN KEY (element_tree_id) REFERENCES element_tree (id) ); CREATE UNIQUE INDEX ux_rubric_element_tree_rubric_id ON rubric_element_tree (rubric_id); CREATE UNIQUE INDEX ux_rubric_element_tree_element_tree_id ON rubric_element_tree (element_tree_id);
テーブルは1対1の関係として機能し、テーブルには2つの外部キーがあり、各キー列には独自のインデックスがあります。
見出しとツリー要素は両方とも一度しかドッキングできないため、一意性のあるインデックスが各列に作成されます。
各セクションには、独自の特性(プロパティ)のセットがあります。
CREATE TABLE rubric_property ( id SERIAL PRIMARY KEY NOT NULL, rubric_id INTEGER NOT NULL, property_id INTEGER NOT NULL, insert_date TIMESTAMP WITH TIME ZONE DEFAULT now(), CONSTRAINT fk_rubric_property_rubric_id FOREIGN KEY (rubric_id) REFERENCES rubric (id), CONSTRAINT fk_rubric_property_property_id FOREIGN KEY (property_id) REFERENCES property (id) ); CREATE UNIQUE INDEX ux_rubric_property_rubric_id ON rubric_property (rubric_id, property_id); CREATE INDEX ix_rubric_property_property_id ON rubric_property (property_id);
テーブルには2つの外部キー、1対多の関係があります。
1つのカテゴリには1つの特性が1つあります-インデックスによって提供され、異なるルーブリックは同じ特性を持つことができます-値の一意性のない特性によるインデックス。
各セクションには、独自のエンティティ(ピース)のセットがあります。
CREATE TABLE rubric_item ( id SERIAL PRIMARY KEY NOT NULL, rubric_id INTEGER NOT NULL, item_id INTEGER NOT NULL, insert_date TIMESTAMP WITH TIME ZONE DEFAULT now(), CONSTRAINT fk_rubric_item_rubric_id FOREIGN KEY (rubric_id) REFERENCES rubric (id), CONSTRAINT fk_rubric_item_item_id FOREIGN KEY (item_id) REFERENCES item (id) ); CREATE UNIQUE INDEX ux_rubric_item_rubric_id_item_id ON rubric_item (rubric_id, item_id); CREATE UNIQUE INDEX ux_rubric_item_item_id ON rubric_item (item_id);
テーブルには2つの外部キー、1対多の関係があります。 1つのRubricには複数のエンティティがあり、各エンティティは1つのRubricにのみ属することができます。
それは情報保管構造でしたが、情報自体はどこにありますか?
情報自体は個別に保存されます。
情報の保存
値テーブル(情報特性値):
CREATE TABLE content ( id SERIAL PRIMARY KEY NOT NULL, raw VARCHAR(4000), redactor_id INTEGER NOT NULL, property_id INTEGER NOT NULL, insert_date TIMESTAMP WITH TIME ZONE DEFAULT now(), CONSTRAINT fk_content_redactor_id FOREIGN KEY (redactor_id) REFERENCES redactor (id), CONSTRAINT fk_content_property_id FOREIGN KEY (property_id) REFERENCES property (id) ); CREATE INDEX ix_content_redactor_id ON content (redactor_id); CREATE INDEX ix_content_property_id ON content (property_id);
このプレートはあまり一般的ではありません。実際、値(未加工)を保存するのは単なる「メモリ」セルです。 特定の特性の値(property_id)。 特定のエディターによって指定された値(redactor_id)。 タブレットからは、この特性の価値がハンマーモデルまたはビデオカードモデルのどちらを指しているのか明確ではありません。Essenceとのドッキングは別のテーブルのタスクですが、編集者に伝えるには時期尚早です。
CREATE TABLE redactor ( id SERIAL PRIMARY KEY NOT NULL, code CHAR(100), title VARCHAR(4000), description VARCHAR(4000), is_hidden INTEGER DEFAULT 0, insert_date TIMESTAMP WITH TIME ZONE DEFAULT now() ); CREATE UNIQUE INDEX ux_redactor_code ON redactor (code);
なぜエディターが必要なのですか? 情報カタログは、各編集者が各エンティティの特性値の独自のバージョンを設定できるウィキペディアのようなものであると想定されていました。 そして実際には、システムは同じエンティティを表すためにエディターのバリエーションと連携する必要がありました。これらのバリエーションの分析を検討してください。
値テーブルには、特性情報の文字列表現のみが格納されます。 これは実際にはユーザー入力です。 システムは、データタイプに応じた表現を使用して、この情報の異なる表現で動作します。 各データ型には独自のテーブルがあります。
行
CREATE TABLE string_matter ( content_id INTEGER NOT NULL, id SERIAL PRIMARY KEY NOT NULL, string VARCHAR(4000), insert_date TIMESTAMP WITH TIME ZONE DEFAULT now(), CONSTRAINT fk_string_matter_content_id FOREIGN KEY (content_id) REFERENCES content (id) ); CREATE UNIQUE INDEX ux_string_matter_content_id ON string_matter (content_id);
* TEXTは、PostgreSqlに文字列を保存するために使用する必要があります
数字
CREATE TABLE digital_matter ( content_id INTEGER NOT NULL, id SERIAL PRIMARY KEY NOT NULL, digital DOUBLE PRECISION, insert_date TIMESTAMP WITH TIME ZONE DEFAULT now(), CONSTRAINT fk_digital_matter_content_id FOREIGN KEY (content_id) REFERENCES content (id) ); CREATE UNIQUE INDEX ux_digital_matter_content_id ON digital_matter (content_id);
日付(タイムスタンプ)
CREATE TABLE date_matter ( content_id INTEGER NOT NULL, id SERIAL PRIMARY KEY NOT NULL, date_time TIMESTAMP WITH TIME ZONE insert_date TIMESTAMP WITH TIME ZONE DEFAULT now(), CONSTRAINT fk_date_matter_content_id FOREIGN KEY (content_id) REFERENCES content (id) ); CREATE UNIQUE INDEX ux_date_matter_content_id ON date_matter (content_id);
時間間隔
CREATE TABLE duration_matter ( content_id INTEGER NOT NULL, id SERIAL PRIMARY KEY NOT NULL, duration INTERVAL, insert_date TIMESTAMP WITH TIME ZONE DEFAULT now(), CONSTRAINT fk_duration_matter_content_id FOREIGN KEY (content_id) REFERENCES content (id) ); CREATE UNIQUE INDEX ux_duration_matter_content_id ON duration_matter (content_id);
データ型は特別に「国際的」に選択されるため、データベース構造を任意のプラットフォーム、任意のDBMSに転送できます。
「問題」という名前は、「問題」および「本質」という言葉との調和のために選ばれました。
そして、私はもう一つのことについては言わなかった、これらはオプションです:
CREATE TABLE option ( id SERIAL PRIMARY KEY NOT NULL, code CHAR(100), title VARCHAR(4000), description VARCHAR(4000), is_hidden INTEGER DEFAULT 0, insert_date TIMESTAMP WITH TIME ZONE DEFAULT now() ); CREATE UNIQUE INDEX ux_option_code ON option (code);
オプションは、特性の処理方法、特性の分析方法、使用する検索エンジン、保持するデータのタイプ、アクセスに必要な権限(許可)を決定するタグとして必要であり、そのようなすべてのビジネスロジックはオプションに関連付けられています。
機能を備えたオプションドック:
CREATE TABLE property_option ( id SERIAL PRIMARY KEY NOT NULL, property_id INTEGER NOT NULL, option_id INTEGER NOT NULL, insert_date TIMESTAMP WITH TIME ZONE DEFAULT now(), CONSTRAINT fk_property_option_property_id FOREIGN KEY (property_id) REFERENCES property (id), CONSTRAINT fk_property_option_option_id FOREIGN KEY (option_id) REFERENCES option (id) ); CREATE UNIQUE INDEX ux_property_option_property_id_option_id ON property_option (property_id, option_id); CREATE INDEX ix_property_option_option_id ON property_option (option_id);
コンテンツはエンティティと接続します:
CREATE TABLE item_content ( id SERIAL PRIMARY KEY NOT NULL, item_id INTEGER NOT NULL, content_id INTEGER NOT NULL, insert_date TIMESTAMP WITH TIME ZONE DEFAULT now(), CONSTRAINT fk_item_content_item_id FOREIGN KEY (item_id) REFERENCES item (id), CONSTRAINT fk_item_content_content_id FOREIGN KEY (content_id) REFERENCES content (id) ); CREATE UNIQUE INDEX ux_item_content_item_id_content_id ON item_content (item_id, content_id); CREATE UNIQUE INDEX ux_item_content_content_id ON item_content (content_id);
実際、これらはすべて情報カタログのコンポーネントです。
「アーキテクチャ」のチップ
ここで最も重要な質問、なぜこれほど多くの接続ラベルが、テーブルを直接結合することは本当に不可能なのでしょうか?
答えは、この「アーキテクチャ」は最大のモジュール性を目指しているということです。 各テーブルは1つの機能のためにシャープ化されており、これらの機能は柔軟に組み合わせることができます。 柔軟性は値のテーブルによってのみ侵害されます-コンテンツ、もちろんエディターとの接続は別のテーブルに移動できますが、これは遠すぎます(次の実装ではそうしますが)。 コンテンツ外のコンテンツを解釈することはできないため、コンテンツとプロパティの関係は困難です。
接続の柔軟性は、システムの他のサブジェクト間でサブジェクトをスローできるように作成されています。
つまり、同じ一連の値を持つエンティティを異なるヘディング間でスローできます。各ヘディングでは、このヘディングに対して定義された特性のみでエンティティを表示および操作します。 意味自体に影響を与えることなく、あるエンティティから別のエンティティに値を自由に転送できます。
情報の文字列表現のみを使用し、* _matterテーブルの高度に特殊化された表現を忘れることができます。
要素のツリーにルーブリックを散布することなく、ルーブリックのみを使用できます。 しかし、逆に、ユーザーがアクセスできるようにしたい見出しのみをツリーに沿って散らし、システムの見出しをツリーにドッキングせず、ユーザーからそれらを隠すことはできません。
カテゴリの特性を追加または削除できますが、値は影響を受けません。
つまり、プロジェクトごとに、必要な機能のみを使用でき、必要のない機能は2つのアカウントにカットでき、アセンブリから不要なクラスを単純に除外できます。
一般に、データベース構造を変更せずにデータをツイストおよびツイストできます。したがって、このデータを操作するクラスを変更することなく、ロジックが変更された場合、「プリミティブ」を変更せずにデータアクセスレイヤーを変更せずにビジネスロジックレイヤーのみを変更する必要がありますデータ編集インターフェースを担当するクラス。
データアクセスのオーバーヘッドの増加により、不注意なユーザーアクションに対する柔軟性と抵抗力が高まりました。バックアップを必要とせずにいくつかの実験を行うことができます。
この「美しさ」にはPHPコードもありますが、次回はそれについて、そして私の「回復モード」を検討すると、たった1週間です。
PS。 おそらくあなたのコメントの後、この「アーキテクチャ」についてもう一度書く必要があります。その後、このデータストレージおよび処理システムを操作するためのPHPクラスについて話すことができます。
ERチャート
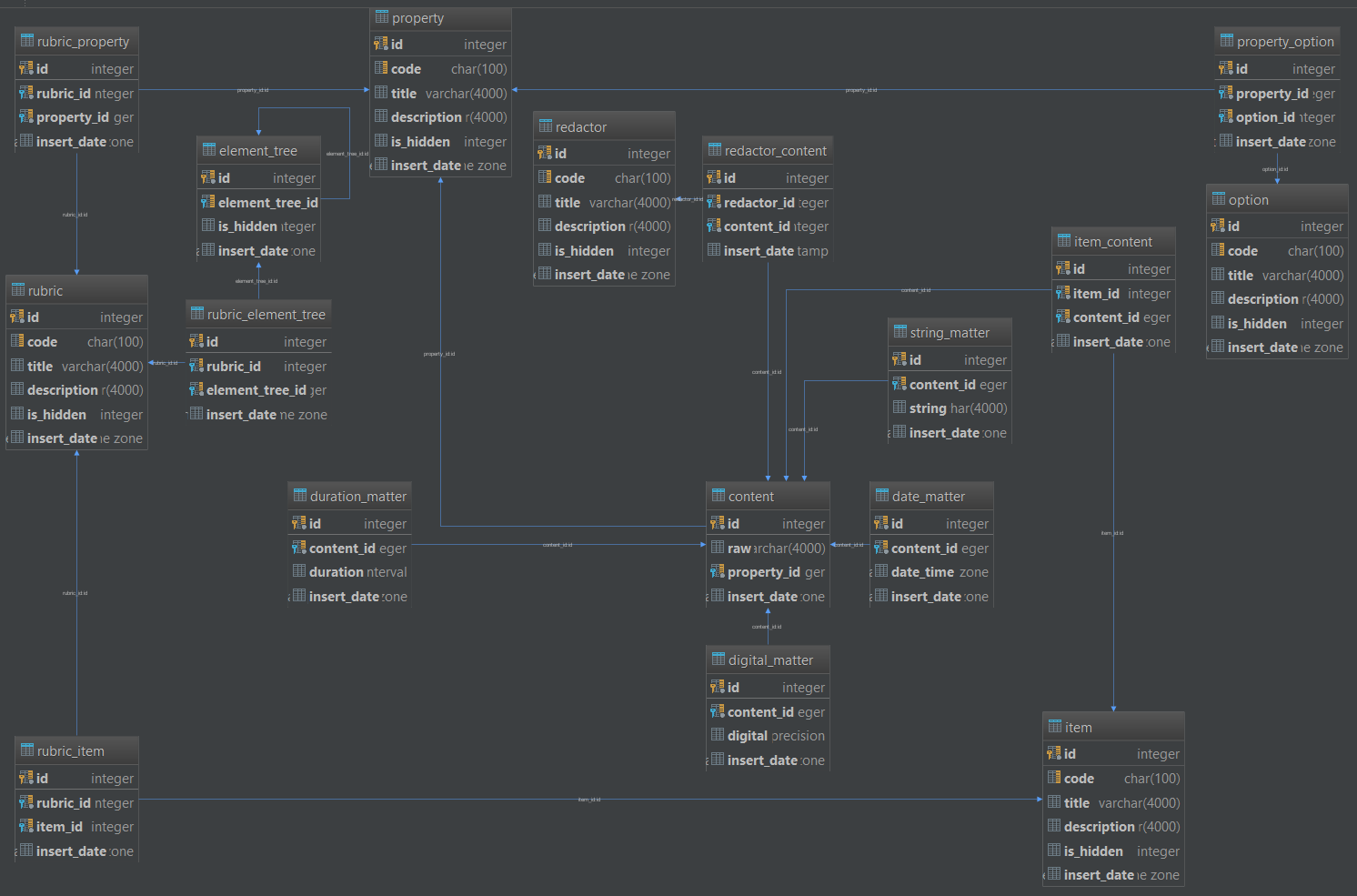
継続
完璧なカタログ、建築スケッチ