多くの場合、エンタープライズデータ処理タスクは、タイムスタンプが後に続くデータに影響します。 Rでは、このようなラベルは通常POSIXct
クラスとして保存されます。 類推の原理によってこのタイプのデータを扱う方法を選択すると、Rが非常に失望し、極端に遅くなるという確信が生まれる可能性があります。
以下では、今月会ったいくつかのケースと可能な解決策に触れます。 非常に興味深い質問を解決する過程で。 同時に、このような問題を解決するのに非常に役立つツールについても言及します。 実践では、自分の存在を知っている人はほとんどいないことが示されています。
ケース番号1。 ITシステムイベントデータの処理
ビジネスの観点からは、タスクは「あたかも」些細なことです。 一定期間の分散システムのイベントフローを明確に表示する必要があります。 そして、さまざまな基準「カット」を提供します。 データソースとして、サブシステムはITシステムのコンポーネントのロギングに使用されます。
読みやすさの観点から、このようなデータの高レベルの概要については、「ヒートマップ」の形式での表現が最適です。 生成されたチャートの例を次に示します。

自転車を発明することには意味がありません。記事「ボブ・ルディス、ggplot2でファセット付きヒートマップを作成する」で説明されているアプローチが使用されました 。 実際のところ、データは本質的に同一であり、適切な一連のメトリックを持つタイムスタンプを表しているため、個人情報を開示しないように、この記事と公開データにさらにアピールします。
ニュアンスNo.1
イベントのソースがいくつかあり、それらが異なるタイムゾーンにあるという事実にあります。 ソースデータの時間はUTCで測定され、アナリストはローカルタイムゾーンの時間に従って作業サイクルに関連付けられている必要があります。 ソースデータは次のとおりです。
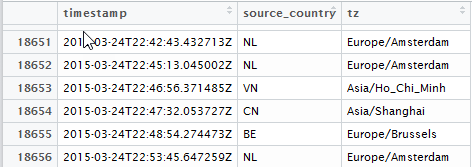
ここで、 timestamp
はテキスト形式のISO8601形式のイベントのUTC時間であり、tzはこのイベントが発生したタイムゾーンのマーカーです。
ニュアンス№2
この記事で使用されているdplyr::do()
アプローチは、 purrr
パッケージがpurrr
れてから非推奨になりました。 写真家のコメント: dplyr :: do()は、purrrアプローチを支持して、基本的に非推奨になりました 。 そしてこれは、コードが最新のアプローチに適応されるべきであることを意味します。
すぐにpurrr
、forループとVectorize Vectorize
関連するアプローチを無効としてスキップします。 残念ながら、タイムゾーンが異なるPOSIXct
値ベクトルに「額に」ベクトル化を適用する試みは不可能です。 答えは、 dput
関数によるPOSIXct
値のベクトルの詳細な調査の結果です。 タイムゾーンはベクトルの属性ですが、単一の要素ではありません!
このため、 POSIXct
処理によってPOSIXct
変数に機能map
アプローチを適用すると、憂鬱な結果が得られますPOSIXct
万件のレコードのサンプルでは、処理時間はほぼ20秒です。 この場合、 ymd_hms()
関数のベクトル化プロパティがymd_hms()
。そうでない場合、結果はさらに悪化します。
attacks_raw <- read_csv("./data/eventlog.csv", col_types="ccc", progress=interactive()) %>% slice(1:20000) attacks <- attacks_raw %>% # mutate(rt=map(.$timestamp, ~ ymd_hms(.x, quiet=FALSE))) %>% # ~ 8 mutate(rt=ymd_hms(timestamp, quiet=FALSE)) %>% mutate(hour=as.numeric(map2(.$rt, .$tz, ~ format(.x, "%H", tz=.y)))) %>% mutate(wkday_text=map2(.$rt, .$tz, ~ weekdays(as.Date(.x, tz=.y)))) %>% unnest(rt, hour, wkday_text)
この動作の理由を見つけようとしています。 これを行うには、コードプロファイリングツールを使用します。 利害関係者は、はじめに、Proviss Webサイトで詳細を見ることができます: Profvis-Rコードのプロファイリングのためのインタラクティブな視覚化、およびビデオを見る:
- 2016 Shiny Developer Conferenceビデオ:プロファイリングとパフォーマンス-ウィンストン・チャン 。
- rconf2017:プロファイラーでコードのパフォーマンスを理解する-Winston Chang
プロファイリングの結果は次のとおりです。
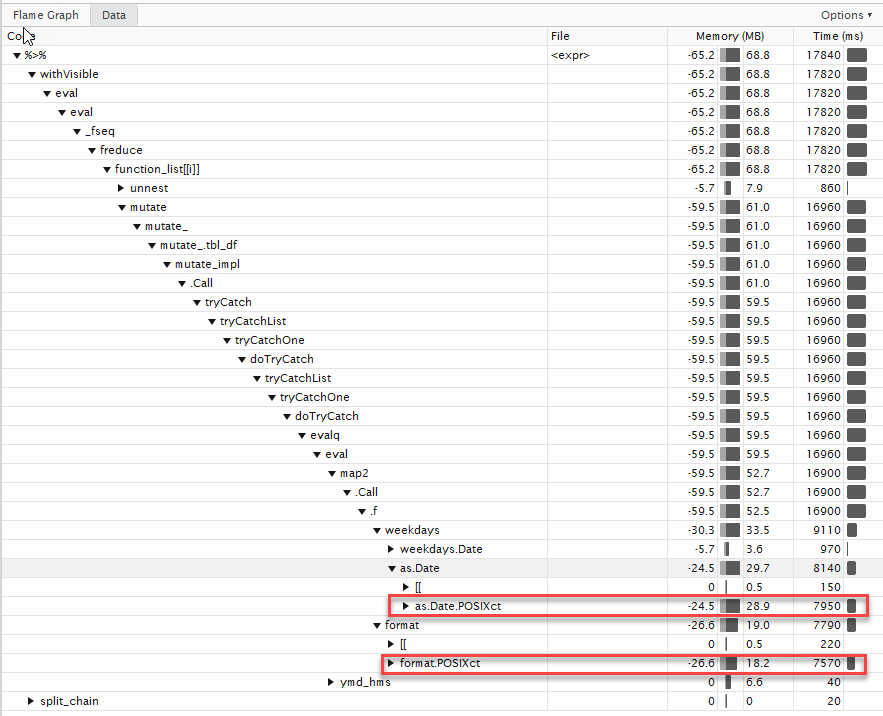
ほとんどの時間は、 POSIXct
、 POSIXlt
複数の変換に費やされていることがPOSIXlt
ます。 これには特定の説明がありますが、個々の位置については、 「as.POSIXctと比較して潤滑機能が非常に遅いのはなぜですか」を参照してください 。
しかし、私たちにはいくつかの主要な結論があります。
- 日付のあるすべてのピースアクションを機能制限から可能な限り引き出します。
- 同じtzを持つ
POSIXct
値に対してベクトル化を使用します(つまり、タイムゾーンをパラメーターとして渡すことを強制されません)。 - 特定のテキスト形式
chr->POSIXct
、chr->POSIXct
変換が基本的なR関数によって実行されず、繰り返し最適化される場合に、lubridate
パッケージの機能を使用します(fasttime
パッケージを参照)。 -
dplyr::do
代わりにdplyr::do
purrr::map2
使用してpurrr::map2
。
コードをわずかに変更することで、約25倍の加速が得られます。 (より大きなデータ配列で実行すると、ゲインはほぼ100倍になります )。

コードは次のとおりです。
attacks_raw <- read_csv("./data/eventlog.csv", col_types="ccc", progress=interactive()) %>% slice(1:20000) parseDFDayParts <- function(df, tz) { real_times <- ymd_hms(df$timestamp, tz=tz, quiet=TRUE) tibble(wkday=weekdays(as.Date(real_times, tz=tz)), hour=as.numeric(format(real_times, "%H", tz=tz))) } attacks <- attacks_raw %>% group_by(tz) %>% nest() %>% mutate(res=map2(data, tz, parseDFDayParts)) %>% unnest()
重要な「チップ」の1つは、時間帯によるグループ化と、それに続く処理のベクトル化です。
ケース番号2。 一時データのスライディングウィンドウ
ビジネスケースも簡単です。 ユーザーアクションへの応答時間を特徴付ける一時データの配列があります。

アプリケーションに対するユーザーの満足度を測定するには、 APDEXインデックスを計算する必要があります。

# , 3 : # N – # NS - , [0 – ] # NF – , ( – 4] # (. 4) # APDEX = (NS + NF/2)/N.
出発点として、ベースRを使用してスライディングウィンドウのメトリックを計算した恐ろしい結果を使用します。2000レコードのサンプルの場合、計算時間はほぼ2分です。
apdexf <- function(respw, T_agreed = 1.2) { which(0 < respw$response_time & respw$response_time < T_agreed) apdex_N <- length(respw$response_time) #APDEX_total apdex_NS <- length(which(respw$response_time < T_agreed)) # APDEX_satisfied apdex_NF <- length(which(T_agreed < respw$response_time & respw$response_time < 4*T_agreed)) # APDEX_tolerated F=4T apdex <- (apdex_NS + apdex_NF/2)/apdex_N return(apdex) } dt = dminutes(15) df.apdex = data.frame(timestamp=numeric(0), apdex=numeric(0)) for(t in seq(from = start_time, by = dt, length.out = floor(as.duration(end_time - start_time)/dt))){ respw <- subset(mydata, t <= timestamp & timestamp < t+dt) df.apdex <- rbind(df.apdex, data.frame(timestamp = t, apdex = apdexf(respw))) }
すべての中間ステップをスキップし、すぐに最適化の場所をマークします。
- 機能処理への移行。
- ループで呼び出される関数以外のすべての定数計算の削除。 特に、
satisfied\tolerated\frustrated
た状態satisfied\tolerated\frustrated
は、応答時間の関数であり、測定時間や計算ウィンドウではありません。 - 非常に重要な点は、オブジェクトの非生産的なコピーです!!!
data.frame
は参照によって関数に渡されるという事実にもかかわらず、関数内でdata.frame
を使用する操作はオブジェクトの複製の作成につながる可能性があり、これは大きなオーバーヘッドです。dplyr
メソッドの機能を使用した操作の最適化により、関数内のデータコピーの量を最小限に抑えることができ、生産性が大幅に向上します。dplyr
メソッドの機能、dplyr
オブジェクトを制御する手段、特にdplyr::changes()
関数については、記事「データフレームパフォーマンス」を参照してください。 これが、応答時間ステータスを持つ個々の列のモデルが、応答時間ステータスタイプを持つ1つの列よりもはるかに望ましい理由です。 - ベクトル化プロパティを使用して、計算の開始時に時間ウィンドウの範囲を一度計算します。
POSIXct
+タイムシフトの計算は、サイクル内で実行するには非常に高価な手順です。 - 外部パラメーター化で最適化された
dplyr
関数を使用します。 このようなトリックは、コンピューティングと使用メモリのコストを削減できますが、NSE [非標準評価]からSE [標準評価]に戻ることで構文が多少複雑になります。 (filter_
>filter_
)。 SE \ NSEの紹介情報については、ここをクリックしてください: 非標準評価 。
apdexf2 <- function(df, window_start, cur_time) { t_df <- df %>% filter_(lazyeval::interp(~ timestamp>var, var=as.name("window_start"))) %>% filter_(lazyeval::interp(~ timestamp<=var, var=as.name("cur_time"))) # , summarise s <- sum(t_df$satisfied) t <- sum(t_df$tolerated) f <- sum(t_df$frustrated) (s + t/2)/(s + t + f) } t_agreed <- 0.7 mydata %<>% mutate(satisfied=if_else(t_resp <= t_agreed, 1, 0)) %>% mutate(frustrated=if_else(t_resp > 4*t_agreed, 1, 0)) %>% mutate(tolerated=1-satisfied-frustrated) %>% mutate(window_start=timestamp-minutes(15)) time_df <- mydata %>% select(window_start, timestamp) mydata %<>% select(timestamp, satisfied, tolerated, frustrated) mydata$apdex <- map2(time_df$window_start, time_df$timestamp, ~ apdexf2(mydata, .x, .y)) %>% unlist()
このような最適化の後、約3.5秒の処理時間が得られます。 加速はほぼ35倍であり、コードをわずかに書き換えるだけで達成できます。

しかし、これは制限ではありません。 指定された実装は、個々のメトリックごとにスライディングウィンドウを使用して計算します。 測定は、任意の時点で行うことができます。 しかし、実際には、そのような精度は過剰であり、計算を1〜5分のグループ間隔に失格にするのに十分です。 そしてこれは、計算時間を比例的に削減しながら、計算量が再び10減ることを意味します。
結論として、現在存在するパッケージとツールのセットにより、Rをコンパクトかつ迅速に記述できるようになりました。 これでは十分でない場合でも、 Rcpp
の形式で予備が残っています-C ++で個別の関数を記述します。
前の投稿: 「エンタープライズタスクのR。 トリックとトリック