
Habréで機械学習コースを受講している皆さん、こんにちは!
最初の2つの部分( 1、2 )では、パンダからのデータの初期分析と、データから結論を引き出すことができる写真の構築を実践しました。 今日、最後に、機械学習に移りましょう。 機械学習の問題について話し、2つの簡単なアプローチ-決定木と最近傍の方法を考えてみましょう。 また、相互検証を使用して特定のデータのモデルを選択する方法についても説明します。
UPD:現在、コースは英語で、 mlcourse.aiというブランド名で、Medium に関する記事 、Kaggle( Dataset )およびGitHubに関する資料があります 。
オープンコースの2回目の立ち上げ(2017年9月から11月)の一環として、この記事に基づいた講義のビデオ 。
この記事の概要:
はじめに
おそらく、すぐに戦いに突入したいと思いますが、まず、どのような問題を解決するのか、そして機械学習の分野でのその場所について話します。
機械学習の古典的で一般的な(痛みを伴う厳密ではない)定義は次のように聞こえます(T. Mitchell "Machine learning"、1997):
彼らは、クラスPから問題を解決するときにコンピュータープログラムが学習すると言う。そのパフォーマンスがメトリックPに従って、経験Eの蓄積とともに向上する場合。
さらに、異なるシナリオでは、 T、P 、およびEはまったく異なることを意味します。 機械学習で最も人気のあるTタスクの中で :
- 分類-オブジェクトの特性に基づくカテゴリの1つへの割り当て
- 回帰-他の属性に基づいてオブジェクトの量的属性を予測する
- クラスタリング-これらのオブジェクトの特性に基づいてオブジェクトのセットをグループに分割し、グループ内ではオブジェクトが互いに類似し、同じグループの外ではオブジェクトが類似しないようにする
- 異常検出-サンプル内の他のすべてまたはオブジェクトのグループと「非常に異なる」オブジェクトを検索します
- その他、より具体的に。 ディープラーニングの機械学習の基本の章で優れたレビューが提供されています(Ian Goodfellow、Yoshua Bengio、Aaron Courville、2016)
経験Eはデータ(それらなし、どこもなし)を意味し、これに応じて、機械学習アルゴリズムは教師ありと教師なし( 教師あり &教師なし学習)で教えるものに分割できます。 教師なしで教える問題には、 属性のセットで記述されたオブジェクトで構成されるサンプルがあります 。 これに加えて、教師による指導のタスクでは、 trainingと呼ばれる特定のサンプルの各オブジェクトについて、 ターゲット属性が既知です。実際、これはトレーニングサンプルからではなく、他のオブジェクトについて予測したいものです。
例
分類と回帰のタスクは、教師に教えるタスクです。 例として、クレジットスコアリングのタスクを紹介します。顧客についてクレジット組織が蓄積したデータに基づいて、ローンのデフォルトを予測したいと思います。 ここで、アルゴリズムの場合、エクスペリエンスEは利用可能なトレーニングセットです。 オブジェクト (人々)のセットは、それぞれが特性のセット(年齢、給与、ローンの種類、過去の非返済など)とターゲット属性によって特徴付けられます 。 このターゲット属性が単純にローンの未返済の事実(1または0、つまり銀行がローンを返済した顧客と返済しなかった顧客を知っている)である場合、これは(バイナリ)分類タスクです。 クライアントがローンの返済にどれだけの時間を遅らせたかを知っていて、新しい顧客に対して同じことを予測したい場合、これは回帰タスクになります。
最後に、機械学習の定義における3番目の抽象化は、 アルゴリズムPのパフォーマンスを評価するためのメトリックです。 このようなメトリックは、タスクやアルゴリズムごとに異なります。アルゴリズムを学習するときに、それらについて説明します。 今のところ、分類問題を解決するアルゴリズムの最も単純な品質メトリックは、正解の割合( 正確さ 、 正確さではなく、この翻訳は別のメトリック、 精度のために予約されています)、つまり、単にテストサンプル上のアルゴリズムの正しい予測の割合であるとしましょう
次に、教師に教える2つのタスク、分類と回帰について説明します。
決定木
最も一般的なものの1つである決定木を使用して、分類方法と回帰方法のレビューを開始します。 決定木は、人間の活動のさまざまな分野の日常生活で使用されますが、機械学習からはほど遠いこともあります。 決定木は、どのような状況で何をすべきかについての視覚的な指示と呼ぶことができます。 研究所の科学者のカウンセリングの分野から例を挙げましょう。 Higher School of Economicsは、従業員の生活を楽にする情報スキームを作成します。 以下は、研究所のポータルで科学論文を公開するための指示の断片です。

機械学習の観点から言えば、これはいくつかの基準に従ってポータルの出版形態(本、記事、本の章、プレプリント、高等経済学およびマスメディアでの出版)を決定する基本分類子であると言えます:出版の種類(モノグラフ、パンフレット、記事、など)、記事が公開される出版物の種類(科学雑誌、作品集など)およびその他。
多くの場合、決定木は、専門家の経験の一般化、将来の従業員に知識を移転する手段、または会社のビジネスプロセスのモデルとして機能します。 たとえば、銀行セクターにスケーラブルな機械学習アルゴリズムを導入する前に、クレジットスコアリングのタスクは専門家によって解決されました。 借り手にローンを付与する決定は、いくつかの直観的に(または経験から)派生したルールに基づいて行われ、ルールは決定ツリーの形式で表すことができます。
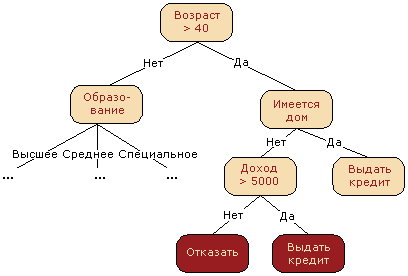
この場合、「年齢」、「家にいる」、「収入」、「教育」の記号に従って、バイナリ分類問題が解決されていると言えます(ターゲットクラスには「貸し出し」と「拒否」の2つの意味があります)。
機械学習アルゴリズムとしての決定木は基本的に同じです。「有意性」という形式の論理規則の結合です。 a 少ない x そして意義 b 少ない y ... =>クラス1の「ツリー」データ構造。決定ツリーの大きな利点は、簡単に解釈でき、人々が理解できることです。たとえば、上の図の図によれば、借り手にローンを拒否された理由を説明できます。したがって、後で説明しますが、他の多くのモデルはより正確ですが、このプロパティを持たず、データを読み込んで回答を受け取った「ブラックボックス」のように考えることができます。決定木の「理解可能性」とモデルとの類似性 人のソリューション(モデルを上司に簡単に説明できます)、決定木は非常に人気があり、この分類方法のグループの代表の1つであるC4.5は、10のベストデータマイニングアルゴリズム(「データマイニングのトップ10アルゴリズム」)のリストの最初と見なされます、知識および情報システム、2008年。PDF )。
決定木を構築する方法
クレジットスコアリングの例では、ローンを付与する決定は、年齢、不動産の入手可能性、収入などに基づいて行われたことがわかりました。 しかし、選択する最初の兆候は何ですか? これを行うには、すべての符号がバイナリである、より単純な例を考えてください。
ここでは、「20の質問」というゲームを思い出すことができます。これは、決定ツリーの概要でよく言及されています。 きっと誰もがそれをプレイしました。 1人は有名人を作り、2人目は「はい」または「いいえ」で答えられる質問のみを尋ねて推測しようとします(「わからない」および「言えない」オプションは省略します)。 どの推測の質問が最初に尋ねられますか? もちろん、残りのオプションの数を減らす可能性が最も高いものです。 たとえば、「アンジェリーナ・ジョリーですか?」という質問 否定的な答えの場合、さらに検索するための選択肢が70億を超えます(もちろん、すべての人が有名人というわけではありませんが、それでも多くの人がいます)が、「これは女性ですか?」 すでに約半分の有名人をカットしました。 つまり、「これはアンジェリーナジョリーです」、「スペイン国籍」、「サッカーが大好き」という記号よりも、「性別」という記号の方が人々のサンプルを共有するのにはるかに優れています。 これは、エントロピーに基づく情報の増加という概念に直感的に対応しています。
エントロピー
シャノンのエントロピーは、 N 次のような可能性のある条件:
LargeS=− sumNi=1pi log2pi、
どこで pi -システムを見つける確率 i 状態。 これは、物理学、情報理論、その他の分野で使用される非常に重要な概念です。 この概念の導入(組み合わせ理論および情報理論)の前提条件を省略すると、直感的に、エントロピーはシステムのカオスの程度に対応することに注意してください。 エントロピーが高いほど、システムの順序は小さくなり、逆の場合も同様です。 これは、「20の質問」ゲームのコンテキストで話した「サンプルの効果的な分離」を形式化するのに役立ちます。
例
エントロピーがツリーを構築するための良い兆候を識別するのにどのように役立つかを説明するために、ここにエントロピーとデシジョンツリーの同じおもちゃの例を示します。 座標によってボールの色を予測します。 もちろん、これは人生とは関係ありませんが、決定木を構築するためにエントロピーがどのように使用されるかを示すことができます。

9個の青いボールと11個の黄色のボールがあります。 ランダムにボールを引いた場合、 p1= frac920 青色で確率があります p2= frac1120 -黄色。 したがって、状態のエントロピー S0=− frac920 log2 frac920− frac1120 log2 frac1120\約1 。 この値自体はまだ何もわかりません。 次に、ボールを2つのグループに分けた場合のエントロピーの変化を見てみましょう。座標は12以下で、12より大きいです。
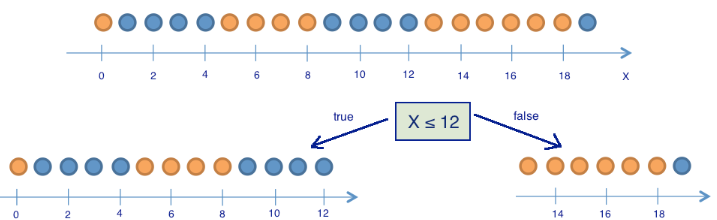
左のグループには13個のボールがあり、そのうち8個は青、5個は黄色でした。 このグループのエントロピーは等しい S1=− frac513 log2 frac513− frac813 log2 frac813\約0.96 。 右側のグループには7個のボールがあり、そのうち1個は青、6個は黄色です。 正しいグループのエントロピーは S2=− frac17 log2 frac17− frac67 log2 frac67\約0.6 。 ご覧のとおり、両方のグループでエントロピーは初期状態と比較して減少しましたが、左側ではそれほどではありません。 エントロピーは本質的にシステムのカオス(または不確実性)の程度であるため、エントロピーの減少は情報の増加と呼ばれます。 形式的に、属性でサンプルを分割するときの情報のゲイン(情報ゲイン、IG) Q (この例では、これは「 x leq12 ")は次のように定義されます
LargeIG(Q)=SO− sumqi=1 fracNiNSi、
どこで q -パーティションの後のグループの数、 Ni -属性の対象となるサンプル要素の数 Q 持っている i 番目の値。 私たちの場合、分離後、2つのグループが取得されました( q=2 )-13要素の1つ( N1=13 )、7から2番目( N2=7 ) 情報の獲得が判明
\ラージIG(x leq12)=S0− frac1320S1− frac720S2\約0.16
「座標が12以下である」ことに基づいてボールを2つのグループに分割すると、最初よりも多くの順序付けられたシステムをすでに受け取りました。 各グループのボールが同じ色になるまで、ボールをグループに分け続けます。

右側のグループでは、「座標が18以下」に基づいて、左側に1つだけ追加のパーティションが必要でした-さらに3つ。 明らかに、同じ色のボールを持つグループのエントロピーは0( log21=0 )、同じ色のボールのグループが注文されるという考えに対応します。
その結果、座標によってボールの色を予測する決定木を構築しました。 このような決定ツリーは、トレーニングセット(最初の20個のボール)に完全に適合するため、新しいオブジェクト(新しいボールの色を決定する)でうまく機能しない可能性があることに注意してください。 新しいボールを分類するには、トレーニングセットを色で理想的に着色していない場合でも、「質問」または区分の数が少ないツリーの方が適しています。 この問題、再訓練、さらに検討します。
ツリー構築アルゴリズム
前の例で構築されたツリーが、ある意味で最適であることを確認できます。たった5つの「質問」(属性の条件 x )決定木をトレーニングセットに「適合」させるため、つまり、ツリーがトレーニングオブジェクトを正しく分類するようにします。 サンプリング分離の他の条件下では、ツリーはより深くなります。
ID3やC4.5などの一般的な決定木構築アルゴリズムの基礎は、情報成長の貪欲な最大化の原則です。各ステップで、その属性が選択されます。 さらに、エントロピーがゼロまたは何らかの小さな値に等しくなるまで(再トレーニングを回避するためにツリーがトレーニングサンプルに完全に適合しない場合)、手順が再帰的に繰り返されます。
アルゴリズムが異なると、「早期停止」または「クリッピング」に異なるヒューリスティックが使用され、再トレーニングされたツリーの構築が回避されます。
def build(L): create node t if the stopping criterion is True: assign a predictive model to t else: Find the best binary split L = L_left + L_right t.left = build(L_left) t.right = build(L_right) return t
分類問題におけるその他の分割品質基準
エントロピーの概念により、ツリー内のパーティションの品質の概念をどのように形式化できるかを見つけました。 しかし、これは単なるヒューリスティックであり、他にもあります。
- ジニ不純物: G=1− sum limitsk(pk)2 。 この基準の最大化は、同じサブツリーにある同じクラスのオブジェクトのペアの数の最大化として解釈できます。 Evgeny Sokolovのリポジトリから、これについて(さらに多くのことを)学ぶことができます 。 Giniインデックスと混同しないでください! Alexander Dyakonovのブログ投稿でこの混乱について詳しく読んでください。
- 誤分類エラー: E=1− max limitskpk
実際には、分類エラーはほとんど使用されず、Giniの不確実性と情報の増加はほぼ同じように機能します。
バイナリ分類問題の場合( p+ -ラベル+)エントロピーとGini不確実性を持つオブジェクトの確率は、次の形式を取ります。
S=−p+ log2p+−p− log2p−=−p+ log2p+−(1−p+) log2(1−p+);
G=1−p2+−p2−=1−p2+−(1−p+)2=2p+(1−p+)
引数の2つの関数をプロットするとき p+ 、エントロピープロットはGiniの2倍の不確実性プロットに非常に近いため、実際には、これら2つの基準はほぼ同じように「機能」します。
from __future__ import division, print_function # Anaconda import warnings warnings.filterwarnings('ignore') import numpy as np import pandas as pd %matplotlib inline import seaborn as sns from matplotlib import pyplot as plt
plt.rcParams['figure.figsize'] = (6,4) xx = np.linspace(0,1,50) plt.plot(xx, [2 * x * (1-x) for x in xx], label='gini') plt.plot(xx, [4 * x * (1-x) for x in xx], label='2*gini') plt.plot(xx, [-x * np.log2(x) - (1-x) * np.log2(1 - x) for x in xx], label='entropy') plt.plot(xx, [1 - max(x, 1-x) for x in xx], label='missclass') plt.plot(xx, [2 - 2 * max(x, 1-x) for x in xx], label='2*missclass') plt.xlabel('p+') plt.ylabel('criterion') plt.title(' p+ ( )') plt.legend();

例
合成データにScikit-learnライブラリの決定木を使用する例を考えてみましょう。 2つのクラスは、平均が異なる2つの正規分布から生成されます。
# np.seed = 7 train_data = np.random.normal(size=(100, 2)) train_labels = np.zeros(100) # train_data = np.r_[train_data, np.random.normal(size=(100, 2), loc=2)] train_labels = np.r_[train_labels, np.ones(100)]
データを表示します。 非公式には、この場合の分類タスクは、2つのクラス(黄色から赤色の点)を分割する何らかの「良い」境界線を構築することです。 誇張すると、この場合の機械学習は、適切な分割境界を選択する方法に帰着します。 おそらく、直線は単純な境界線であり、各赤い点を囲む複雑な曲線は複雑すぎて、トレーニングサンプルの元と同じ分布からの新しい例で多くの間違いを犯します。 直感は、2つのクラスを分割する滑らかな境界線、または少なくとも単なる直線( n -次元の場合-超平面)。
plt.rcParams['figure.figsize'] = (10,8) plt.scatter(train_data[:, 0], train_data[:, 1], c=train_labels, s=100, cmap='autumn', edgecolors='black', linewidth=1.5); plt.plot(range(-2,5), range(4,-3,-1));
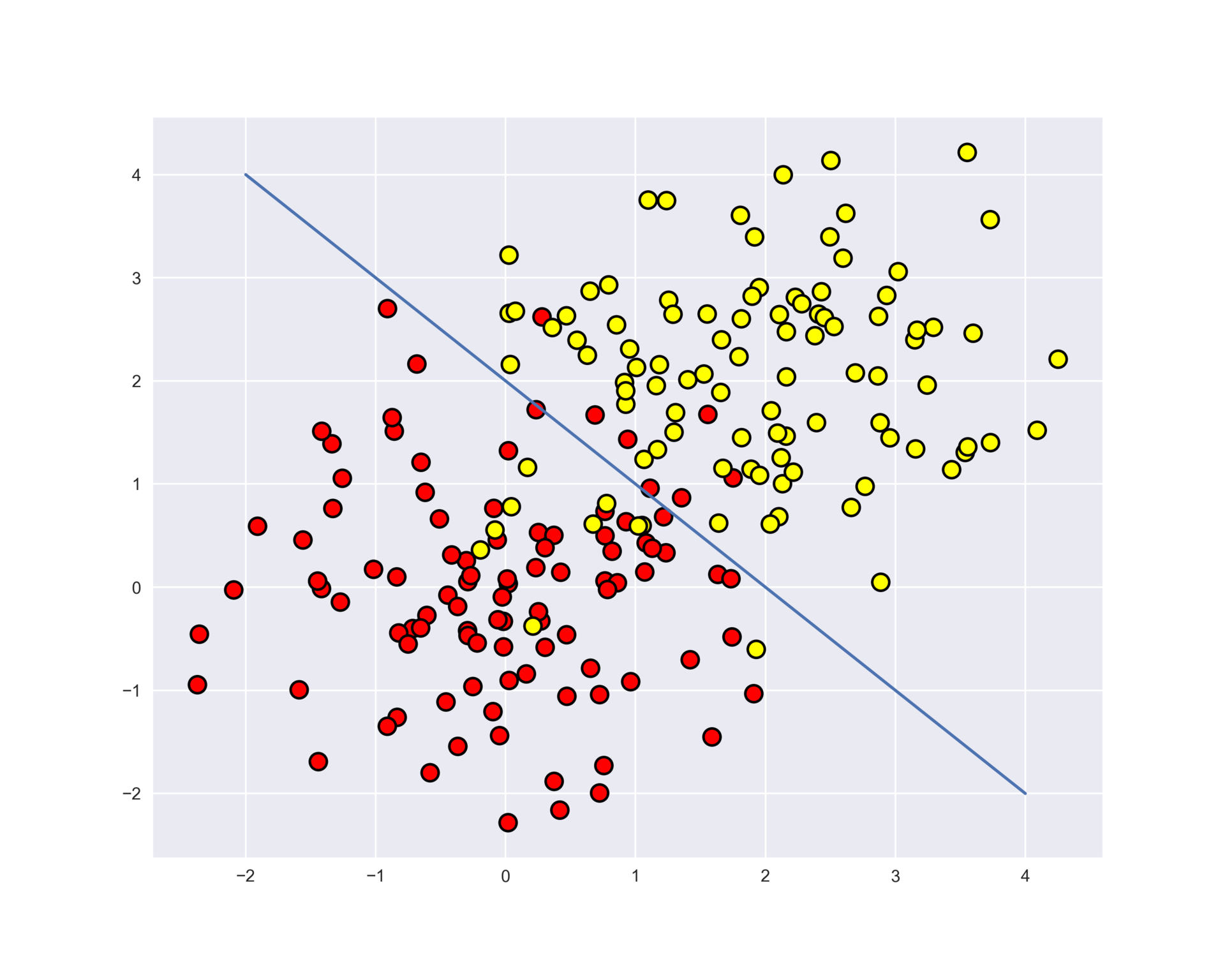
決定木を学習して、これら2つのクラスを分離してみましょう。 ツリーでは、ツリーの深さを制限するmax_depth
パラメーターを使用します。 結果のクラス分離境界を視覚化します。
from sklearn.tree import DecisionTreeClassifier # , . def get_grid(data): x_min, x_max = data[:, 0].min() - 1, data[:, 0].max() + 1 y_min, y_max = data[:, 1].min() - 1, data[:, 1].max() + 1 return np.meshgrid(np.arange(x_min, x_max, 0.01), np.arange(y_min, y_max, 0.01)) # min_samples_leaf , # clf_tree = DecisionTreeClassifier(criterion='entropy', max_depth=3, random_state=17) # clf_tree.fit(train_data, train_labels) # xx, yy = get_grid(train_data) predicted = clf_tree.predict(np.c_[xx.ravel(), yy.ravel()]).reshape(xx.shape) plt.pcolormesh(xx, yy, predicted, cmap='autumn') plt.scatter(train_data[:, 0], train_data[:, 1], c=train_labels, s=100, cmap='autumn', edgecolors='black', linewidth=1.5);

そして、ツリー自体はどのように見えますか? ツリーは、スペースを7つの長方形に「カット」していることがわかります(ツリーには7つの葉があります)。 このような各長方形では、1つまたは別のクラスのオブジェクトの普及率に応じて、ツリー予測が一定になります。
# .dot from sklearn.tree import export_graphviz export_graphviz(clf_tree, feature_names=['x1', 'x2'], out_file='../../img/small_tree.dot', filled=True) # pydot (pip install pydot) !dot -Tpng '../../img/small_tree.dot' -o '../../img/small_tree.png'
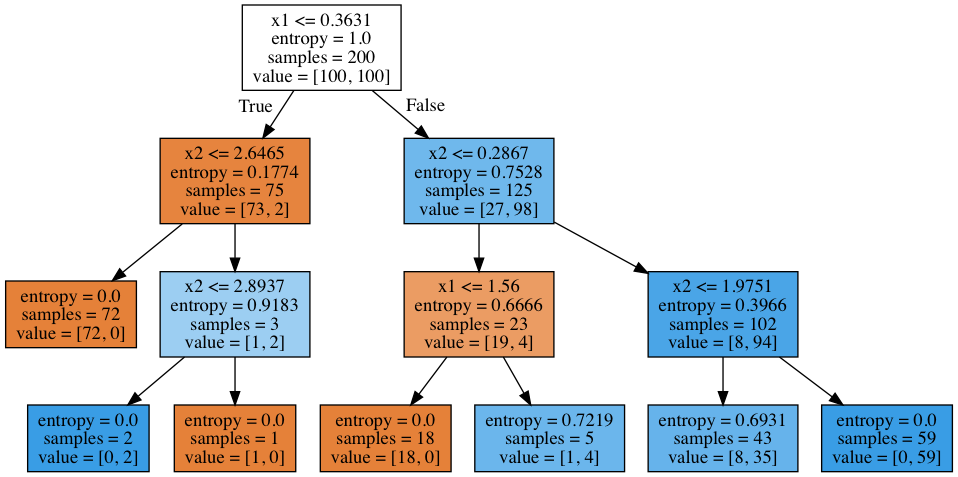
このようなツリーはどのように「読み取り可能」ですか?
最初は200のオブジェクトがあり、100は1つのクラスで、100は別のクラスでした。 初期状態のエントロピーは最大-1でした。その後、属性の比較に応じてオブジェクトを2つのグループに分けました x1 価値あり 0.3631 (上の図で、ツリーの境界線のこのセクションを見つけます)。 同時に、オブジェクトの左右両方のグループのエントロピーが減少しました。 このように、ツリーは深さ3まで構築されます。この視覚化では、1つのクラスのオブジェクトが多いほど、頂点の色は濃いオレンジに近く、逆に、2番目のクラスのオブジェクトが多いほど、色は濃い青色に近くなります。 したがって、同じクラスのオブジェクトの開始時には、ツリーのルート頂点は等しくなります。
決定木が定量的特性とどのように機能するか
サンプルに、多くの一意の値を持つ量的属性「年齢」があるとします。 決定木は、サンプルの最適な(情報ゲインのタイプの基準に従って)パーティション分割を探し、「Age <17」、「Age <22.87」などのバイナリ記号をチェックします。 しかし、そのような年齢の「カット」が多すぎるとどうなりますか? しかし、まだ「給与」の量的属性があり、給与も多くの方法で「削減」できる場合はどうでしょうか。 各ステップで最適なツリーを選択するには、バイナリ記号が多すぎます。 この問題を解決するために、ヒューリスティックを使用して、定量属性を比較するしきい値の数を制限します。
これをおもちゃの例で考えてみましょう。 次の選択肢があります。
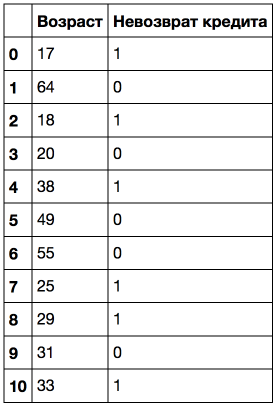
年齢の高い順に並べ替えます。

このデータについて決定ツリーをトレーニングし(深さを制限せずに)、それを調べます。
age_tree = DecisionTreeClassifier(random_state=17) age_tree.fit(data[''].values.reshape(-1, 1), data[' '].values) export_graphviz(age_tree, feature_names=[''], out_file='../../img/age_tree.dot', filled=True) !dot -Tpng '../../img/age_tree.dot' -o '../../img/age_tree.png'
次の図では、ツリーに43.5、19、22.5、30、および32年という5つの値が含まれていることがわかります。 よく見ると、これらはターゲットクラスが1から0(またはその逆)に「変化」する年齢間の正確な平均値です。 複雑なフレーズですので、例:43.5は38〜49歳の平均、38歳に返済しなかったクライアント、49歳から49歳に返還したクライアントです。 同様に、18年から20年の平均は19年です。 つまり、量的属性を「切り取る」ためのしきい値として、ツリーは、ターゲットクラスが値を変更する値を「見る」。
この場合、「年齢<17.5」という記号を考慮するのが意味をなさない理由を検討してください。

より複雑な例を考えてみましょう。属性「給与」(千ルーブル/月)を追加します。
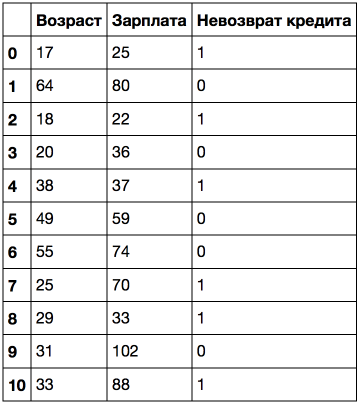
年齢で並べ替えると、ターゲットクラス(「クレジットのデフォルト」)が5回(1から0またはその逆に)変更されます。 そして、給与でソートする場合-7回。 ツリーはどのように属性を選択しますか? 見てみましょう。

age_sal_tree = DecisionTreeClassifier(random_state=17) age_sal_tree.fit(data2[['', '']].values, data2[' '].values); export_graphviz(age_sal_tree, feature_names=['', ''], out_file='../../img/age_sal_tree.dot', filled=True) !dot -Tpng '../../img/age_sal_tree.dot' -o '../../img/age_sal_tree.png'
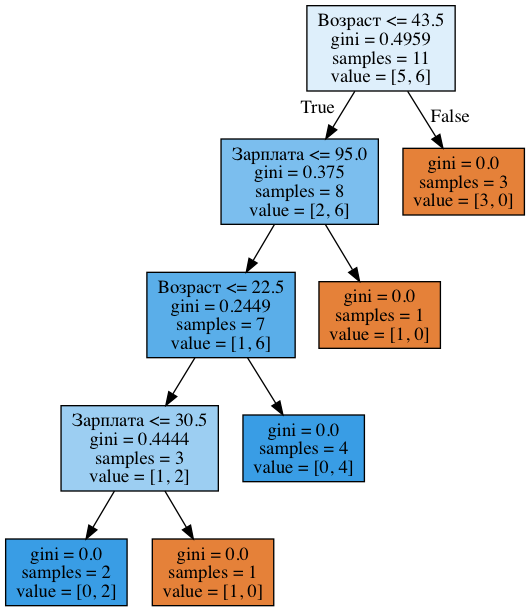
ツリーには、年齢別と給与別の両方の内訳が含まれていることがわかります。 さらに、兆候を比較するしきい値:年齢は43.5および22.5歳、給与は95および30.5ルーブル/月。 繰り返しになりますが、給与が88の人は「悪い」、そして102-「良い」と判明したのに対して、95万が88と102の間の平均であることがわかります。 つまり、給与と年齢の比較は、すべての可能な値ではなく、ごく少数の値で確認されました。 そして、なぜこれらの兆候が木に現れたのですか? その理由は、Giniの不確実性の基準によると、パーティションが優れていたためです。
結論:決定木の定量的特性を処理するための最も単純なヒューリスティック:定量的特性は昇順にソートされ、ターゲット特性が値を変更するツリーでそれらのしきい値のみがチェックされます。 それほど厳密に聞こえるわけではありませんが、おもちゃの例を使ってその意味を伝えたいと思います。
さらに、データに多くの量的特性があり、それぞれに多くの一意の値がある場合、上記のすべてのしきい値を選択できるわけではなく、上位Nのみを選択できるため、同じ基準の最大増加が得られます。 つまり、実際には、各しきい値に対して深さ1のツリーが構築され、エントロピー(またはGiniの不確実性)がどれだけ減少したかが考慮され、定量的属性を比較するために最適なしきい値のみが選択されます。
説明のために:給与によって破られたとき leq 34.5「左のサブグループはエントロピー0(すべてのクライアントは「悪い」)であり、右-0.954(3「悪い」および5「良い」)では、宿題の1つの部分がツリーの構築方法を完全に理解するためだけであることを確認できます)。情報のゲインは約0.3です。
そして「給与」で割ると leq 95 "左側のサブグループでは、エントロピーは0.97(6"悪い "と4"良い ")で、右側-0(1つのオブジェクトのみ)。情報のゲインは約0.11です。
このように各パーティションの情報の増加を計算すると、大きなツリーを構築する前に(すべての基準で)各定量的特性を比較するしきい値を選択できます。
量的形質の量子化の例は、 thisまたはthisのような投稿で見つけることができます。 このテーマに関する最も有名な科学記事の1つは、「決定木生成における連続値属性の処理について」です(UM Fayyad。KB Irani、 "Machine Learning"、1992)。
基本的なツリーパラメーター
原則として、決定ツリーは、各シートにオブジェクトが1つだけ存在するような深さまで構築できます。 しかし、実際には、そのようなツリーが再トレーニングされるという事実のために(1つのツリーのみが構築される場合)これは行われません-トレーニングセットに合わせすぎて、新しいデータの予測にはうまく機能しません。 ツリーの下のどこか、非常に深いところに、パーティションがそれほど重要でない理由で表示されます(たとえば、クライアントがサラトフから来たのか、コストロマから来たのか)。 誇張すると、緑色のズボンでローンを求めて銀行に来た4人のクライアントのうち、誰もローンを返さなかったことが判明するかもしれません。 ただし、分類モデルでこのような特定のルールを生成することは望ましくありません。
次の2つの例外があります。ツリーが最大深度まで構築される場合です。
- ランダムフォレスト(多くのツリーの構成)は、最大の深さまで構築されたツリーの応答を平均します(なぜそれを行う必要があるのか、後でわかります)
- 剪定 このアプローチでは、ツリーは最初に最大の深さまで構築され、その後、ツリーの品質をこのパーティションとパーティションなしで比較することで、下から上に徐々にツリーの一部が削除されます(比較は、以下で説明する相互検証を使用して実行されます)。 Evgeny Sokolovのリポジトリの資料で詳細を読むことができます。
以下の画像は、再訓練されたツリーによって構築された境界線の例です。

決定木の場合の再トレーニングに対処する主な方法:
- シート内のオブジェクトの深さまたはオブジェクトの最小数の人為的な制限:ツリーの構築は、ある時点で停止します。
- 木刈り
Scikit-learnのDecisionTreeClassifierクラス
sklearn.tree.DecisionTreeClassifier
クラスの主なパラメーター:
-
max_depth
最大ツリー深度 -
max_features
ツリー内の最適なパーティションが検索されるフィーチャの最大数(これは、多数のフィーチャでは、 すべての属性の中で(情報の成長のタイプの基準により)パーティションを検索するのに「高価」になるため必要です) -
min_samples_leaf
シート内のオブジェクトの最小数。 このパラメーターには明確な解釈があります。たとえば、5の場合、ツリーは少なくとも5つのオブジェクトに当てはまる分類規則のみを生成します
ツリーのパラメーターは、入力データに応じて調整する必要があります。これは通常、少し低めの交差検証を使用して行われます。
回帰問題の決定木
量的属性を予測する場合、ツリーを構築するという考え方は変わりませんが、品質基準は変わります。
- 中央付近の分散: LargeD= frac1 ell sum limits elli=1(yi− frac1 ell sum limits elli=1yi)2、
どこで ell -シート内のオブジェクトの数、 yi -ターゲット属性の値。 簡単に言えば、平均の周りの分散を最小化して、各シートのターゲットフィーチャの値がほぼ等しくなるようにサンプルを分解するフィーチャを探します。
例
関数の周りに分散されたデータを生成する f(x)=e−x2+1.5∗e−(x−2)2 ノイズがある場合は、それらの決定木を訓練し、木がどのような予測をするかを示します。
n_train = 150 n_test = 1000 noise = 0.1 def f(x): x = x.ravel() return np.exp(-x ** 2) + 1.5 * np.exp(-(x - 2) ** 2) def generate(n_samples, noise): X = np.random.rand(n_samples) * 10 - 5 X = np.sort(X).ravel() y = np.exp(-X ** 2) + 1.5 * np.exp(-(X - 2) ** 2) + \ np.random.normal(0.0, noise, n_samples) X = X.reshape((n_samples, 1)) return X, y X_train, y_train = generate(n_samples=n_train, noise=noise) X_test, y_test = generate(n_samples=n_test, noise=noise) from sklearn.tree import DecisionTreeRegressor reg_tree = DecisionTreeRegressor(max_depth=5, random_state=17) reg_tree.fit(X_train, y_train) reg_tree_pred = reg_tree.predict(X_test) plt.figure(figsize=(10, 6)) plt.plot(X_test, f(X_test), "b") plt.scatter(X_train, y_train, c="b", s=20) plt.plot(X_test, reg_tree_pred, "g", lw=2) plt.xlim([-5, 5]) plt.title("Decision tree regressor, MSE = %.2f" % np.sum((y_test - reg_tree_pred) ** 2)) plt.show()

決定木は、区分定数関数によってデータの依存性を近似することがわかります。
最近傍法
最近傍法(k最近傍、またはkNN)も非常に一般的な分類方法であり、回帰問題でも使用される場合があります。 これは、決定ツリーと共に、分類に対する最も理解しやすいアプローチの1つです。 直観のレベルでは、この方法の本質は次のとおりです。勝つ隣人を見て、あなたもそうです。 正式には、この方法の基礎はコンパクト性仮説です。例間の距離メトリックが非常にうまく導入された場合、類似した例は異なる例よりも同じクラスにある可能性がはるかに高くなります。
最近傍の方法によれば、テストケース(緑のボール)は、クラス「赤」ではなく「青」に割り当てられます。

たとえば、Bluetoothヘッドセットの発表で示す製品のタイプがわからない場合は、5つの同様のヘッドセットを見つけることができ、そのうち4つがアクセサリカテゴリに割り当てられ、1つだけがテクニクスカテゴリに割り当てられている場合、常識がわかります広告にはカテゴリ「アクセサリ」も示されます。
テストサンプルの各オブジェクトを分類するには、次の操作を順番に実行する必要があります。
- トレーニングセット内の各オブジェクトまでの距離を計算します
- 奪う k トレーニングセットのオブジェクト、最小距離
- 分類されたオブジェクトのクラスは、最も一般的に見られるクラスです k 最近傍
回帰タスクの場合、メソッドは非常に簡単に適応します-ステップ3では、ラベルは返されませんが、数値は近隣のターゲット属性の平均値(または中央値)です。
このアプローチの顕著な特徴は、その怠inessさです。 つまり、計算はテストケースの分類時にのみ開始され、事前にはトレーニング例のみでモデルは構築されません。 これは、たとえば、以前に検討された決定ツリーとの違いです。最初にトレーニングサンプルに基づいてツリーが構築され、次にテストケースの分類が比較的迅速に行われます。
最近傍の方法がよく研究されたアプローチであることは注目に値します(機械学習、計量経済学、統計学では、おそらく線形回帰についてのみ知られています)。 最近傍の方法については、「無限」サンプルではこれが最適な分類方法であると主張する多くの重要な定理があります。 古典的な本「統計的学習の要素」の著者は、kNNを理論的に理想的なアルゴリズムと考えています。その適用性は、計算能力と次元の呪いによって単純に制限されます。
実生活問題における最近傍法
- 純粋な形では、kNNは問題を解決するための良い出発点(ベースライン)として役立ちます。
- 競技会では、Kaggle kNNがメタサインを構築するためによく使用されます(kNNの予測は他のモデルに入力されます)またはスタッキング/ブレンド;
- 最も近い隣人のアイデアは他のタスクにも拡張されます。たとえば、レコメンダーシステムでは、簡単な最初の解決策は、推奨したい人の最も近い隣人の間で人気のある製品(またはサービス)を推奨することです。
- 実際には、多くの場合、最も近い近傍を見つけるための近似方法が使用されます。 これは、 Artyom Babenkoによる、高次元空間の何十億ものオブジェクトから最も近いものを見つけるための効果的なアルゴリズムについての講義です(画像検索)。 AnnoyライブラリのSpotifyのおかげで、このようなアルゴリズムを実装するオープンライブラリも知られています。
最近傍法による分類/回帰の品質は、いくつかのパラメーターに依存します。
- 隣人の数
- オブジェクト間の距離メトリック(ハミングメトリック、ユークリッド距離、コサイン距離、ミンコフスキー距離がよく使用されます)。 ほとんどのメトリックを使用する場合、特性値をスケーリングする必要があることに注意してください。 相対的に言えば、値の範囲が10万までの「給与」の記号は、値が100までの「年齢」よりも距離に大きく影響しません。
- 隣人の重み(テストケースの隣人は異なる重みで入力する場合があります。たとえば、例が遠くなるほど、スコアは低くなります)
Scikit-learnのKNeighborsClassifierクラス
sklearn.neighbors.KNeighborsClassifierクラスの主なパラメーター:
- 重み:「均一」(すべての重みが等しい)、「距離」(重みはテストケースまでの距離に反比例する)、または別のユーザー定義関数
- algorithm (): "brute", "ball_tree", "KD_tree", "auto". . — , . "auto" .
- leaf_size (): BallTree KDTree
- metric: "minkowski", "manhattan", "euclidean", "chebyshev"
-
– , . ( , ), , .
2 :
- ( held-out/hold-out set ). - ( 20% 40%), (60-80% ) (, – ) .
- - ( cross-validation , ). – K-fold -

K ( K−1 ) ( ), ( , ).
K , , / -.
- . - , .
- – ( ), , , .. , , Sebastian Raschka ()
応用例
-
DataFrame . Series, . , , .
df = pd.read_csv('../../data/telecom_churn.csv') df['International plan'] = pd.factorize(df['International plan'])[0] df['Voice mail plan'] = pd.factorize(df['Voice mail plan'])[0] df['Churn'] = df['Churn'].astype('int') states = df['State'] y = df['Churn'] df.drop(['State', 'Churn'], axis=1, inplace=True)

70% (X_train, y_train) 30% (X_holdout, y_holdout). , , , . 2 – kNN, , , : 5, – 10.
from sklearn.model_selection import train_test_split, StratifiedKFold from sklearn.neighbors import KNeighborsClassifier X_train, X_holdout, y_train, y_holdout = train_test_split(df.values, y, test_size=0.3, random_state=17) tree = DecisionTreeClassifier(max_depth=5, random_state=17) knn = KNeighborsClassifier(n_neighbors=10) tree.fit(X_train, y_train) knn.fit(X_train, y_train)
– . . : 94% 88% kNN. .
from sklearn.metrics import accuracy_score tree_pred = tree.predict(X_holdout) accuracy_score(y_holdout, tree_pred) # 0.94
knn_pred = knn.predict(X_holdout) accuracy_score(y_holdout, knn_pred) # 0.88
-. . , GridSearchCV: max_depth
max_features
5- - .
from sklearn.model_selection import GridSearchCV, cross_val_score
tree_params = {'max_depth': range(1,11), 'max_features': range(4,19)}
tree_grid = GridSearchCV(tree, tree_params, cv=5, n_jobs=-1, verbose=True)
tree_grid.fit(X_train, y_train)
パラメーターの最適な組み合わせと、相互検証の正解の対応する平均割合:
tree_grid.best_params_
{'max_depth':6、 'max_features':17}
tree_grid.best_score_
0.94256322331761677
accuracy_score(y_holdout, tree_grid.predict(X_holdout))
0.94599999999999995
kNN.
from sklearn.pipeline import Pipeline from sklearn.preprocessing import StandardScaler
knn_pipe = Pipeline([('scaler', StandardScaler()), ('knn', KNeighborsClassifier(n_jobs=-1))])
knn_params = {'knn__n_neighbors': range(1, 10)}
knn_grid = GridSearchCV(knn_pipe, knn_params, cv=5, n_jobs=-1, verbose=True)
knn_grid.fit(X_train, y_train)
knn_grid.best_params_, knn_grid.best_score_
({'knn__n_neighbors': 7}, 0.88598371195885128)
accuracy_score(y_holdout, knn_grid.predict(X_holdout))
0.89000000000000001
, : 94.2% - 94.6% 88.6% / 89% kNN. , , ( , - , ) (95.1% - 95.3% – ), .
from sklearn.ensemble import RandomForestClassifier forest = RandomForestClassifier(n_estimators=100, n_jobs=-1, random_state=17) print(np.mean(cross_val_score(forest, X_train, y_train, cv=5))) # 0.949
forest_params = {'max_depth': range(1,11), 'max_features': range(4,19)}
forest_grid = GridSearchCV(forest, forest_params, cv=5, n_jobs=-1, verbose=True)
forest_grid.fit(X_train, y_train)
forest_grid.best_params_, forest_grid.best_score_ # ({'max_depth': 9, 'max_features': 6}, 0.951)
accuracy_score(y_holdout, forest_grid.predict(X_holdout)) # 0.953
. - , ( – 6), , "", .
export_graphviz(tree_grid.best_estimator_, feature_names=df.columns, out_file='../../img/churn_tree.dot', filled=True) !dot -Tpng '../../img/churn_tree.dot' -o '../../img/churn_tree.png'

, , - "", . (2 ), (+1, , -1 – ). , – .
def form_linearly_separable_data(n=500, x1_min=0, x1_max=30, x2_min=0, x2_max=30): data, target = [], [] for i in range(n): x1, x2 = np.random.randint(x1_min, x1_max), np.random.randint(x2_min, x2_max) if np.abs(x1 - x2) > 0.5: data.append([x1, x2]) target.append(np.sign(x1 - x2)) return np.array(data), np.array(target) X, y = form_linearly_separable_data() plt.scatter(X[:, 0], X[:, 1], c=y, cmap='autumn', edgecolors='black');
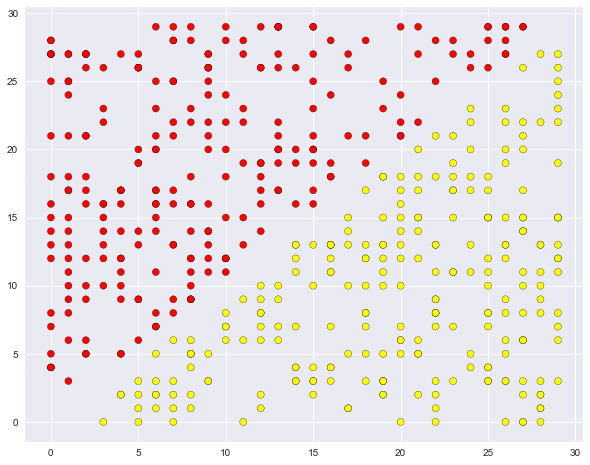
. , , 30×30 , .
tree = DecisionTreeClassifier(random_state=17).fit(X, y) xx, yy = get_grid(X, eps=.05) predicted = tree.predict(np.c_[xx.ravel(), yy.ravel()]).reshape(xx.shape) plt.pcolormesh(xx, yy, predicted, cmap='autumn') plt.scatter(X[:, 0], X[:, 1], c=y, s=100, cmap='autumn', edgecolors='black', linewidth=1.5) plt.title('Easy task. Decision tree compexifies everything');

, ( ) – x1=x2 。
export_graphviz(tree, feature_names=['x1', 'x2'], out_file='../../img/deep_toy_tree.dot', filled=True) !dot -Tpng '../../img/deep_toy_tree.dot' -o '../../img/deep_toy_tree.png'

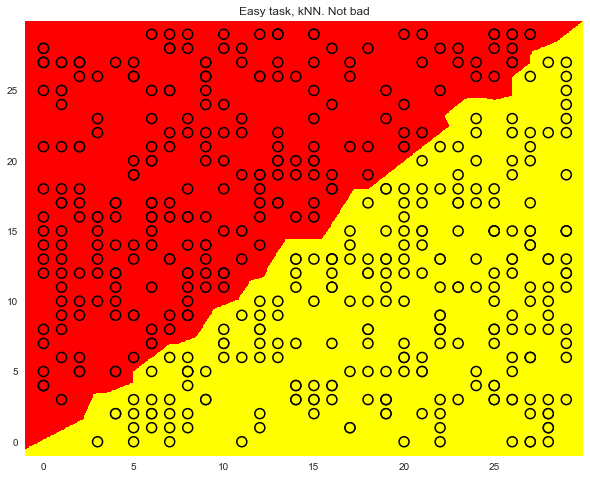
, , ( ).
knn = KNeighborsClassifier(n_neighbors=1).fit(X, y) xx, yy = get_grid(X, eps=.05) predicted = knn.predict(np.c_[xx.ravel(), yy.ravel()]).reshape(xx.shape) plt.pcolormesh(xx, yy, predicted, cmap='autumn') plt.scatter(X[:, 0], X[:, 1], c=y, s=100, cmap='autumn', edgecolors='black', linewidth=1.5); plt.title('Easy task, kNN. Not bad');
MNIST
2 . "" sklearn
. , .
8 x 8 ( ). "" 64, .
, , .
from sklearn.datasets import load_digits data = load_digits() X, y = data.data, data.target X[0,:].reshape([8,8])
array([[ 0., 0., 5., 13., 9., 1., 0., 0.],
[ 0., 0., 13., 15., 10., 15., 5., 0.],
[ 0., 3., 15., 2., 0., 11., 8., 0.],
[ 0., 4., 12., 0., 0., 8., 8., 0.],
[ 0., 5., 8., 0., 0., 9., 8., 0.],
[ 0., 4., 11., 0., 1., 12., 7., 0.],
[ 0., 2., 14., 5., 10., 12., 0., 0.],
[ 0., 0., 6., 13., 10., 0., 0., 0.]])
f, axes = plt.subplots(1, 4, sharey=True, figsize=(16,6)) for i in range(4): axes[i].imshow(X[i,:].reshape([8,8]));
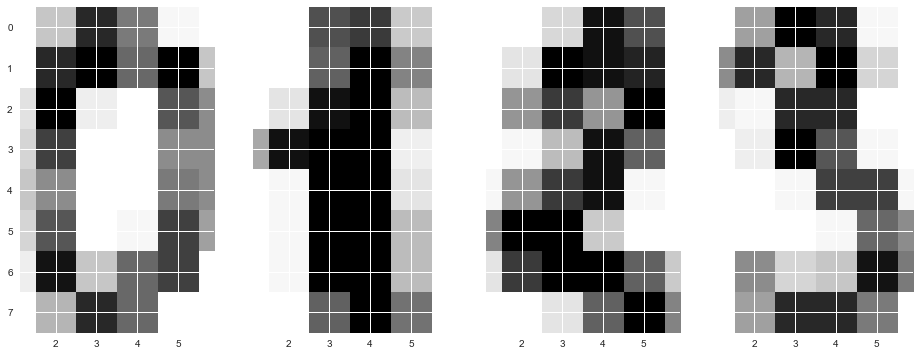
, , .
70% (X_train, y_train) 30% (X_holdout, y_holdout). , , , .
X_train, X_holdout, y_train, y_holdout = train_test_split(X, y, test_size=0.3, random_state=17)
kNN, .
tree = DecisionTreeClassifier(max_depth=5, random_state=17) knn = KNeighborsClassifier(n_neighbors=10) tree.fit(X_train, y_train) knn.fit(X_train, y_train)
. , . .
tree_pred = tree.predict(X_holdout) knn_pred = knn.predict(X_holdout) accuracy_score(y_holdout, knn_pred), accuracy_score(y_holdout, tree_pred) # (0.97, 0.666)
, -, , , — 64.
tree_params = {'max_depth': [1, 2, 3, 5, 10, 20, 25, 30, 40, 50, 64], 'max_features': [1, 2, 3, 5, 10, 20 ,30, 50, 64]} tree_grid = GridSearchCV(tree, tree_params, cv=5, n_jobs=-1, verbose=True) tree_grid.fit(X_train, y_train)
-:
tree_grid.best_params_, tree_grid.best_score_ # ({'max_depth': 20, 'max_features': 64}, 0.844)
66%, 97%. . - 99% .
np.mean(cross_val_score(KNeighborsClassifier(n_neighbors=1), X_train, y_train, cv=5)) # 0.987
, , . .
np.mean(cross_val_score(RandomForestClassifier(random_state=17), X_train, y_train, cv=5)) # 0.935
, , RandomForestClassifier, 98%, .
実験結果
(: CV Holdout– - -. DT – , kNN – , RF – )
| CV | Holdout | |
|---|---|---|
| DT | 0.844 | 0.838 |
| kNN | 0.987 | 0.983 |
| RF | 0.935 | 0.941 |
( ): – ( ), , .
. , .
def form_noisy_data(n_obj=1000, n_feat=100, random_seed=17): np.seed = random_seed y = np.random.choice([-1, 1], size=n_obj) # x1 = 0.3 * y # – x_other = np.random.random(size=[n_obj, n_feat - 1]) return np.hstack([x1.reshape([n_obj, 1]), x_other]), y X, y = form_noisy_data()
, - . , n_neighbors
. .
, , . , "" .
from sklearn.model_selection import cross_val_score cv_scores, holdout_scores = [], [] n_neighb = [1, 2, 3, 5] + list(range(50, 550, 50)) for k in n_neighb: knn = KNeighborsClassifier(n_neighbors=k) cv_scores.append(np.mean(cross_val_score(knn, X_train, y_train, cv=5))) knn.fit(X_train, y_train) holdout_scores.append(accuracy_score(y_holdout, knn.predict(X_holdout))) plt.plot(n_neighb, cv_scores, label='CV') plt.plot(n_neighb, holdout_scores, label='holdout') plt.title('Easy task. kNN fails') plt.legend();

tree = DecisionTreeClassifier(random_state=17, max_depth=1) tree_cv_score = np.mean(cross_val_score(tree, X_train, y_train, cv=5)) tree.fit(X_train, y_train) tree_holdout_score = accuracy_score(y_holdout, tree.predict(X_holdout)) print('Decision tree. CV: {}, holdout: {}'.format(tree_cv_score, tree_holdout_score))
Decision tree. CV: 1.0, holdout: 1.0
, , . , , : , .
:
- , , , " < 25 , ". ;
- , "" ( ) (), ( );
- ;
- ;
- , .
:
- : , , (, ), , ;
- , , ( , - ), ;
- (pruning) . , — ;
- . . ( );
- ( ) NP-, , ;
- . Friedman , 50% CART ( – Classification And Regression Trees,
sklearn
); - , ( ). , , . , > 19 < 0.
:
:
- , , , , , , , (100-150), , ;
- , , /;
- . . , ;
- — (, ). , ;
- , , , - " ". ML- Pedro Domingos – "A Few Useful Things to Know about Machine Learning", "the curse of dimensionality" Deep Learning "Machine Learning basics".
, , . , .
№ 3
– , , , Adult UCI. - ( ).
- Open Machine Learning Course. Topic 3. Classification, Decision Trees and k Nearest Neighbors ( )
- – rushter . , , , ;
- ( GitHub). , ;
- GitHub (.). ;
- " " ;
- " . " .