PROTEQという名前は、障害発生後にデータを回復するための同様のアイデアが表明された以前のプロジェクトから継承されました。
したがって、ソースデータ:
•機器-FMC106Pモジュール、2つのFPGA Virtex 6 LX130T-2およびLX240T-1
•転送レート-5 Gb / s
•行数-8
•データソース-ADC、送信を一時停止する方法はありません
•双方向のデータ交換
•障害後の高速データ復旧を実装する必要がある
•エンコーディング-64/67
主なアイデアは、受信したパケットの確認が到着するまでデータの継続的な再送信を実装することです。 これはプロトコルの主な機能であり、これによりデータ回復を高速化できます。
1行の実装を検討してください。
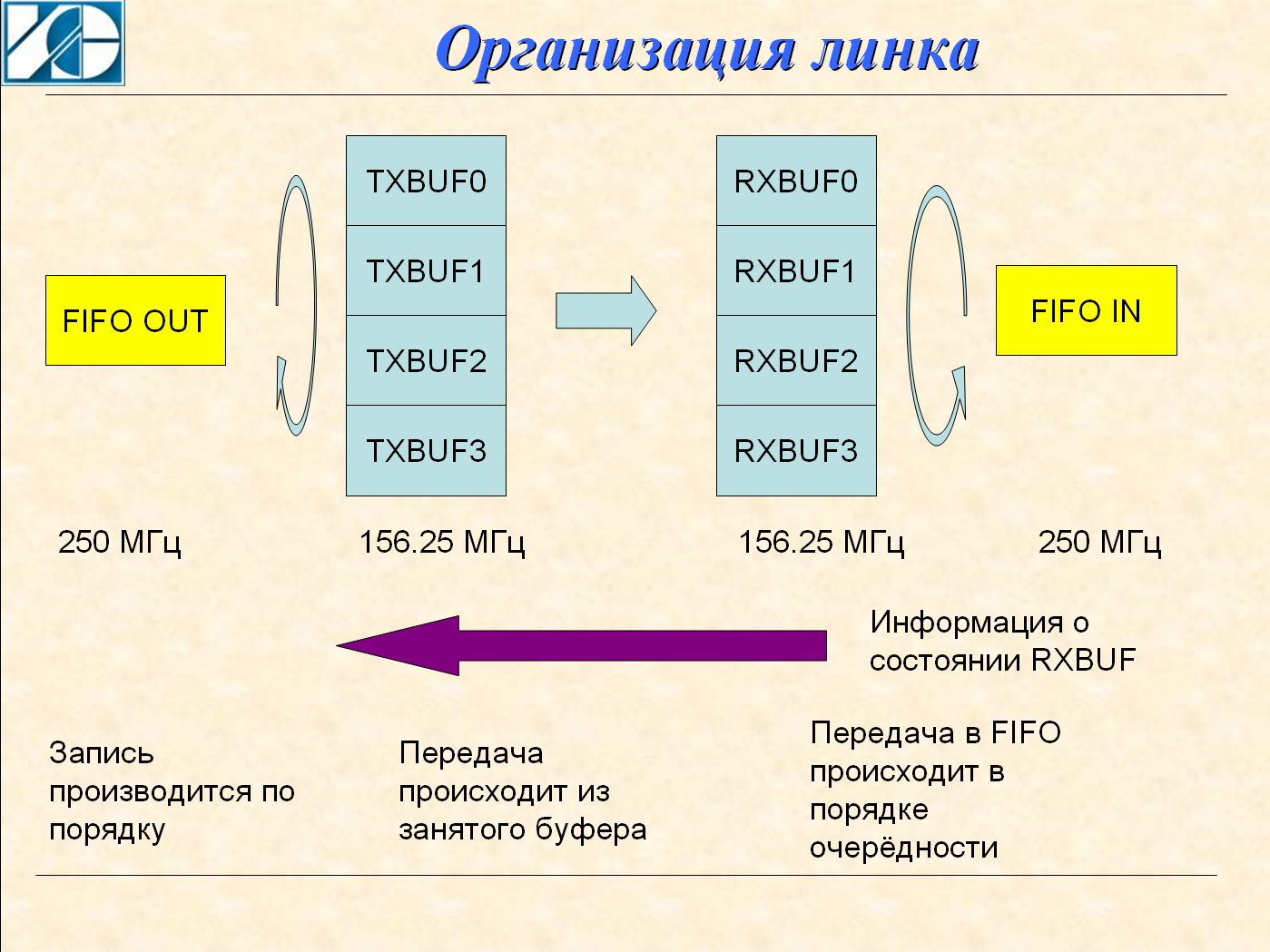
トランスミッタには4つのバッファがあります。 データソースは空きバッファを検出し、そこにデータを書き込みます。 記録は厳密な順序0、1、2、3です。 送信ノードは、円で囲まれたバッファフィルフラグもポーリングし、フィルされたバッファからデータの送信を開始します。 受信者から受信の確認が到着すると、バッファは空きとしてマークされます。 データフローが大きい場合、4つのバッファすべてが送信される前に確認が到着する時間があり、送信は最大速度で進行します。 ストリームが小さい場合、送信ノードは繰り返しパケットを送信する時間がありますが、受信側では破棄されます。
このソリューションは、データ回復を大幅に加速します。 従来の方式では、受信者はパケットを受信して分析し、再送信の要求を作成する必要があります。 これは長い時間です。
レシーバーは4つのバッファーも実装します。 パケットヘッダーにはバッファ番号があり、パケットはすぐに宛先バッファに送信されます。 そのような決定には非常に大きな危険があります。 バッファ番号が破損している場合、現在のパケットとすでに受信したパケットの両方の2つのパケットが破損する可能性があります。 これを回避するために、パッケージは2つのチェックサムを使用します。1つはヘッダーの直後、2つ目はパッケージの最後にあります。
5 Gb / sの速度の場合、周波数が156.25 MHzの32ビットバスがGTXノードで使用されます。 FIFOと内部バッファ間の交換は、250 MHzの周波数で行われます。 これにより、回復の速度が確保されます。 たとえば、バッファ1への転送中にエラーが発生し、エラーなしでバッファ2および3への転送が行われた場合、出力FIFOへの書き込みは、パケットがバッファ1に再び到着するまで遅延します。しかし、その後、バッファ2および3からのパケットは、すぐにFIFOに書き込まれます。
プロトコルは固定パケット長-32ビットの256ワードを使用します。 パッケージには2つのタイプがあります。
- データパケット
- サービスパック
データパケット形式:
- CMD1
- CRC1
- データ-256ワード
- CMD2
- CRC2
サービスパックの形式:
- CMD1
- CRC1
- CMD2
- CRC2
オーバーヘッドはかなり低く、32ビットワードは4つだけです。 合計データパケット長は260ワードです。
サービスパケットは、データがない場合に送信されます。
速度を上げるために、複数の回線での伝送が実装されています。 1〜8の行数で機能するノードがあります。各行のデータバス幅は32ビットです。 8本のラインを使用する場合、データバスの合計幅は256ビットです。
5 GHzの周波数での8回線の推定為替レート:
5,000,000,000 * 64/67 * 256/260 * 8/8/1024/1024 = 4484.7 MB / s
実験の結果として達成されたのはこの速度です。 エラーは定期的に発生しますが、プロトコルによって修正されます。 高速リカバリにより、小さなFIFOサイズを使用してADCを接続できます。
PROTEQの有効性と同じFPGAに実装されたPCI Express v2.0を比較するのは興味深いことです。 両方のプロトコルは、5 Gb / sで8つのリンクを使用します。 最大為替レートは次のとおりです。
5000000000/8/1024/1024 * 8 = 4768 MB / s
PROTEQ効率:
4484/4768 = 0.94; つまり 最大回線速度の94%。
PCI Expressは3200 MB /秒を提供します
3200/4768 = 0.67; つまり 最大回線速度の67%。
もちろん、PCI Express v2.0の効率が低い主な理由は、8/10エンコードの使用です。
プロトコル実装の占有FPGAリソースを比較することも興味深いです。 この図は、同等の機能を備えたPCI ExpressおよびPROTEQが占める領域を示しています。 PCI ExpressもHARDユニットを使用することに注意してください。

主なコンポーネントはprq_transceiver_gtx_m1です
prq_transceiver_gtx_m1
component prq_transceiver_gtx_m1 is generic( is_simulation : in integer:=0; -- 1 - LINES : in integer; -- MGT RECLK_EN : in integer:=0; -- 1 - recclk -- 0 - txoutclk USE_REFCLK_IN : boolean:=FALSE; -- FALSE - MGTCLK -- TRUE - REFCLK_IN is_tx_dpram_use : in integer:=1; -- 1 - is_rx_dpram_use : in integer:=1 -- 1 - ); port( clk : in std_logic; -- - 266 clk_tx_out : out std_logic; -- - 156.25 clk_rx_out : out std_logic; -- - 156.25 --- SYNC --- reset : in std_logic; -- 0 - sync_done : out std_logic; -- 1 - tx_enable : in std_logic; -- 1 - rx_enable : in std_logic; -- 1 - rst_buf : in std_logic:='0'; -- 1 - transmitter_dis : in std_logic:='0'; -- 1 - ---- DATA ---- tx_ready : out std_logic; -- 1 - rx_ready : out std_logic; -- 1 - tx_data : in std_logic_vector( 31+(LINES-1)*32 downto 0 ); -- tx_data_we : in std_logic; -- 1 - tx_data_title : in std_logic_vector( 3 downto 0 ); -- tx_data_eof : in std_logic; -- 1 - tx_user_flag : in std_logic_vector( 7+(LINES-1)*8 downto 0 ); -- tx_inject_error : in std_logic_vector( LINES-1 downto 0 ):=(others=>'0'); -- 1 - rx_data : out std_logic_vector( 31+(LINES-1)*32 downto 0 ); -- rx_data_rd : in std_logic; -- 1 - rx_data_title : out std_logic_vector( 3 downto 0 ); -- rx_data_eof : in std_logic; -- 1 - rx_user_flag : out std_logic_vector( 7+(LINES-1)*8 downto 0 ); -- rx_user_flag_we : out std_logic_vector( (LINES-1) downto 0 ); -- 1 - rx_crc_error_adr: in std_logic_vector( 2 downto 0 ):="000"; -- rx_crc_error : out std_logic_vector( 7 downto 0 ); -- --- MGT --- rxp : in std_logic_vector( LINES-1 downto 0 ); rxn : in std_logic_vector( LINES-1 downto 0 ); txp : out std_logic_vector( LINES-1 downto 0 ); txn : out std_logic_vector( LINES-1 downto 0 ); refclk_in : in std_logic:='0'; mgtclk_p : in std_logic; mgtclk_n : in std_logic ); end component;
tx_ *信号のグループは、伝送チャネルを編成します。 協定移転アルゴリズム:
- tx_ready = 1が表示されるのを待ちます
- ストロボtx_data_we = 1を使用して、tx_dataバスにパケットを書き込みます。
- サイクルごとにtx_data_eof = 1を生成-パケットが送信されます
1から256ワードまで記録できますが、いずれの場合も256ワードのパケットが送信されます。
同様に、rx_ *信号グループは受信チャンネルを編成します。 パケット受信アルゴリズム:
- rx_ready = 1が表示されるのを待ちます
- rx_data_rdストローブを使用してrx_dataバスでパケットを読み取ります
- rx_data_eof = 1を生成
記録中と同様に、パッケージ全体ではなく読み取りが許可されます。 4ビットのヘッダーがパケットとともに送信されます。 送信時に、入力tx_data_titleの値がパケットとともに送信されます。 受信すると、準備tx_ready = 1とともに、rx_data_titleの値が表示されます。 これにより、1つの伝送チャネルでデータの複数のソースとレシーバーを使用できます。
さらに、フラグはチャネルで送信されます。 tx_user_flag送信機の入力のデータは、rx_user_flag受信機の出力に送信されます。 これを使用して、FIFOステータスフラグを送信できます。
prq_transceiver_gtx_m1コンポーネントは、複数のラインでデータを送信できます。 行数は、LINESパラメーターで構成されます。 バス幅tx_data、rx_dataは行数に依存します。
入力tx_inject_errorを使用すると、転送中にエラーを追加できます。 これにより、データ回復メカニズムを確認できます。
次のレベルはprq_connect_m1コンポーネントです
prq_connect_m1
component prq_connect_m1 is generic( is_simulation : in integer:=0; -- 1 - RECLK_EN : in integer:=0; -- 1 - recclk -- 0 - txoutclk is_tx_dpram_use : in integer:=1; -- 1 - is_rx_dpram_use : in integer:=1; -- 1 - FIFO0_WITH : in integer:=1; -- FIFO0: 1 - , 32,64,128,256 FIFO0_PAF : in integer:=16; -- PAF FIFO0_DEPTH : in integer:=1024; -- FIFO0 FIFO1_WITH : in integer:=1; -- FIFO1: 1 - , 32,64,128,256 FIFO1_PAF : in integer:=16; -- PAF FIFO1_DEPTH : in integer:=1024 -- FIFO0 ); port( --- MGT --- rxp : in std_logic_vector( 7 downto 0 ); rxn : in std_logic_vector( 7 downto 0 ); txp : out std_logic_vector( 7 downto 0 ); txn : out std_logic_vector( 7 downto 0 ); mgtclk_p : in std_logic; mgtclk_n : in std_logic; ---- Tranceiver ---- clk : in std_logic; -- - 266 clk_tx_out : out std_logic; -- - 156.25 clk_rx_out : out std_logic; -- - 156.25 --- SYNC --- reset : in std_logic; -- 0 - sync_done : out std_logic; -- 1 - tx_enable : in std_logic; -- 1 - rx_enable : in std_logic; -- 1 - ---- FIFO0 ---- fi0_clk : in std_logic:='0'; -- FIFO fi0_data : in std_logic_vector( FIFO0_WITH-1 downto 0 ):=(others=>'0'); -- FIFO fi0_data_en : in std_logic:='0'; -- 1 - FIFO fi0_paf : out std_logic; -- 1 - FIFO fi0_id : in std_logic_vector( 3 downto 0 ):=(others=>'0'); -- FIFO fi0_rstp : in std_logic:='0'; -- 1 - FIFO fi0_enable : in std_logic:='0'; -- 1 - fi0_prs_en : in std_logic:='0'; -- 1 - fi0_ovr : out std_logic; -- 1 - FIFO fi0_rd_full_speed: in std_logic:='0'; -- 1 - ---- FIFO1 ---- fi1_clk : in std_logic:='0'; -- FIFO fi1_data : in std_logic_vector( FIFO1_WITH-1 downto 0 ):=(others=>'0'); -- FIFO fi1_data_en : in std_logic:='0'; -- 1 - FIFO fi1_paf : out std_logic; -- 1 - FIFO fi1_id : in std_logic_vector( 3 downto 0 ):=(others=>'0'); -- FIFO fi1_rstp : in std_logic:='0'; -- 1 - FIFO fi1_enable : in std_logic:='0'; -- 1 - fi1_prs_en : in std_logic:='0'; -- 1 - fi1_ovr : out std_logic; -- 1 - FIFO fi1_rd_full_speed: in std_logic:='0'; -- 1 - tx_inject_error : in std_logic_vector( 7 downto 0 ):=(others=>'0'); -- 1 - tx_user_flag : in std_logic_vector( 63 downto 0 ):=(others=>'0'); -- ---- ---- fifo_data : out std_logic_vector( 255 downto 0 ); -- FIFO fifo_we : out std_logic; -- 1 - fifo_id : out std_logic_vector( 3 downto 0 ); -- FIFO fifo_rdy : in std_logic_vector( 15 downto 0 ); -- rx_crc_error_adr: in std_logic_vector( 2 downto 0 ):="000"; -- rx_crc_error : out std_logic_vector( 7 downto 0 ); -- rx_user_flag : out std_logic_vector( 63 downto 0 ); -- rx_user_flag_we : out std_logic_vector( 7 downto 0 ) -- 1 - ); end component;
FIFOを介して8行でデータを送信するメカニズムを既に実装しています。 ブロック図:

2つのFIFO、prq_transceiver、受信および送信マシンで構成されています。
各FIFOの入力バスの幅は、FIFOx_WITHパラメーターを介して設定され、ワード数とほぼ満杯のFIFOのフラグの応答レベルも調整されます。 各FIFOへの記録は、独自のクロック周波数で実行されます。 各FIFOには、識別子fi0_id、fi1_idが付属しています。 これにより、受信時にデータストリームを分割できます。 FIFOの後に、擬似ランダムシーケンスジェネレーターがインストールされます。 図では、PSDとして指定されています。
ジェネレーターには3つのモードが実装されています。
- データストリームを変更せずにスキップ
- データフローレートを維持しながらテストシーケンスを置き換える
- テストシーケンスを置き換え、データを全速で送信
このジェネレーターは、実際のプロジェクトの一部としてのテストに基づいています。 このジェネレーターは、FPGAのスペースをあまり消費せず、すべてのプロジェクトにあり、いつでも交換チャネルを確認できます。
コンポーネントprq_connect_m1およびprq_transceiver_gtx_m1は基本です。 Virtex 6 FPGA用に設計されています。 その後、コンポーネントprq_transceiver_gtx_m4およびprq_transceiver_gtx_m6が開発されました。
- prq_transceiver_gtx_m4-コマンド転送用に割り当てられたバッファ0
- prq_transceiver_gtx_m6-Kintex 7 FPGAの場合
プロジェクトは完全にシミュレートされ、tclファイルを介したテストの順次起動が実装されています。
そして、ここでイゴール・カジノフに感謝したい。 彼はこのプロジェクトのモデリングの組織に多大な貢献をしました。
全体的なシミュレーション結果は次のようになります。
Global_tc_summary.logファイル
Global PROTEQ TC log: tc_00_0 PASSED tc_00_1 PASSED tc_00_2 PASSED tc_00_3 PASSED tc_02_0 PASSED tc_02_1 PASSED tc_02_2 PASSED tc_02_3 PASSED tc_02_4 PASSED tc_02_5 PASSED tc_03_0 PASSED tc_05_0 PASSED tc_05_1 PASSED
ファイルの各行は、単一のテストの結果です。 tcはテストケース-テストケースです。 例として、tc_00_1コンポーネントを指定します-パケットの送信を確認し、送信プロセスに単一のエラーを導入します。
tc_00_1
------------------------------------------------------------------------------- -- -- Title : tc_00_1 -- Author : Dmitry Smekhov -- Company : Instrumental Systems -- E-mail : dsmv@insys.ru -- -- Version : 1.0 -- ------------------------------------------------------------------------------- -- -- Description : prq_transceiver_tb -- -- 32- . -- -- ------------------------------------------------------------------------------- -- -- Rev0.1 - debug test #1 -- ------------------------------------------------------------------------------- library ieee; use ieee.std_logic_1164.all; use ieee.std_logic_arith.all; use ieee.std_logic_unsigned.all; library std; use std.textio.all; library work; use work.prq_transceiver_tb_pkg.all; -- to bind testbench and its procedures use work.utils_pkg.all; -- for "stop_simulation" use work.pck_fio.all; entity tc_00_1 is end tc_00_1; architecture bhv of tc_00_1 is signal tx_err : std_logic; signal rx_err : std_logic; begin ---------------------------------------------------------------------------------- -- Instantiate TB TB : prq_transceiver_tb generic map( max_pkg => 32, -- , max_time => 100 us, -- tx_pause => 1 ns, -- rx_pause => 1 ns -- ) port map( tx_err => tx_err, -- m1->m2 rx_err => rx_err -- m2->m1 ); ---------------------------------------------------------------------------------- -- -- Define ERR at TIME# -- tx_err <= '0', '1' after 27 us, '0' after 27.001 us; rx_err <= '0'; ---------------------------------------------------------------------------------- end bhv;
コンポーネントは非常にシンプルです。 prq_transceiver_tbを呼び出します(ただし複雑です)。パラメータを設定し、伝送ラインにエラーを導入する信号tx_errを生成します。
tc_00_1からtc_00_5までの残りのコンポーネントはほぼ同じであり、構成されたパラメーターが異なるため、さまざまな条件下でデータ転送を確認できます。
prq_transceiver_tbコンポーネントははるかに複雑です。 実際には、テストシーケンスを形成し、2つのprq_transceiver_gtx_m1間でストリームを転送し、受信したデータストリームをチェックします。 必要に応じて-送信プロセスにエラーを導入します。
コンポーネント自体は次のとおりです。
prq_transceiver_tb
library ieee; use ieee.std_logic_1164.all; use ieee.std_logic_arith.all; use ieee.std_logic_unsigned.all; use work.prq_transceiver_gtx_m1_pkg.all; library std; use std.textio.all; use work.pck_fio.all; use work.utils_pkg.all; entity prq_transceiver_tb is generic( max_pkg : integer:=0; -- , max_time : time:=100 us; -- tx_pause : time:=100 ns; -- rx_pause : time:=100 ns -- ); port( tx_err : in std_logic:='0'; -- m1->m2 rx_err : in std_logic:='0' -- m2->m1 ); end prq_transceiver_tb; architecture TB_ARCHITECTURE of prq_transceiver_tb is signal clk : std_logic:='0'; signal reset : STD_LOGIC; signal tx_data : STD_LOGIC_VECTOR(31 downto 0); signal tx_data_we : STD_LOGIC; signal tx_data_title : STD_LOGIC_VECTOR(3 downto 0); signal rx_data_rd : STD_LOGIC; signal rxp : STD_LOGIC_VECTOR(0 downto 0); signal rxn : STD_LOGIC_VECTOR(0 downto 0); signal mgtclk_p : STD_LOGIC; signal mgtclk_n : STD_LOGIC; signal mgtclk : std_logic:='0'; -- Observed signals - signals mapped to the output ports of tested entity signal clk_tx_out : STD_LOGIC; signal clk_rx_out : STD_LOGIC; signal sync_done : STD_LOGIC; signal tx_enable : STD_LOGIC; signal rx_enable : STD_LOGIC; signal tx_ready : STD_LOGIC; signal rx_ready : STD_LOGIC; signal rx_data : STD_LOGIC_VECTOR(31 downto 0); signal rx_data_title : STD_LOGIC_VECTOR(3 downto 0); signal txp : STD_LOGIC_VECTOR(0 downto 0); signal txn : STD_LOGIC_VECTOR(0 downto 0); signal m2_txp : STD_LOGIC_VECTOR(0 downto 0); signal m2_txn : STD_LOGIC_VECTOR(0 downto 0); signal m2_rxp : STD_LOGIC_VECTOR(0 downto 0); signal m2_rxn : STD_LOGIC_VECTOR(0 downto 0); signal tx_err_i : std_logic_vector( 0 downto 0 ); signal rx_err_i : std_logic_vector( 0 downto 0 ); signal tx_data_eof : std_logic; signal rx_data_eof : std_logic; signal m2_clk : std_logic:='0'; signal m2_tx_data : STD_LOGIC_VECTOR(31 downto 0); signal m2_tx_data_we : STD_LOGIC; signal m2_tx_data_title : STD_LOGIC_VECTOR(3 downto 0); signal m2_rx_data_rd : STD_LOGIC; signal m2_tx_data_eof : std_logic; signal m2_rx_data_eof : std_logic; -- Observed signals - signals mapped to the output ports of tested entity signal m2_clk_tx_out : STD_LOGIC; signal m2_clk_rx_out : STD_LOGIC; signal m2_sync_done : STD_LOGIC; signal m2_tx_enable : STD_LOGIC; signal m2_rx_enable : STD_LOGIC; signal m2_tx_ready : STD_LOGIC; signal m2_rx_ready : STD_LOGIC; signal m2_rx_data : STD_LOGIC_VECTOR(31 downto 0); signal m2_rx_data_title : STD_LOGIC_VECTOR(3 downto 0); signal tx_user_flag : std_logic_vector( 7 downto 0 ):=x"A0"; signal rx_user_flag : std_logic_vector( 7 downto 0 ); signal rx_user_flag_we : std_logic_vector( 0 downto 0 ); signal m2_tx_user_flag : std_logic_vector( 7 downto 0 ):=x"C0"; signal m2_rx_user_flag : std_logic_vector( 7 downto 0 ); signal m2_rx_user_flag_we : std_logic_vector( 0 downto 0 ); signal m2_reset : std_logic; begin clk <= not clk after 1.9 ns; mgtclk <= not mgtclk after 3.2 ns; m2_clk <= not m2_clk after 1.8 ns; mgtclk_p <= mgtclk; mgtclk_n <= not mgtclk; -- Unit Under Test port map UUT : prq_transceiver_gtx_m1 generic map ( is_simulation => 1, -- 1 - LINES => 1, is_tx_dpram_use => 1, -- 1 - is_rx_dpram_use => 0 -- 1 - ) port map ( clk => clk, clk_tx_out => clk_tx_out, clk_rx_out => clk_rx_out, --- SYNC --- --- SYNC --- reset => reset, sync_done => sync_done, tx_enable => tx_enable, rx_enable => rx_enable, ---- DATA ---- ---- DATA ---- tx_ready => tx_ready, rx_ready => rx_ready, tx_data => tx_data, tx_data_we => tx_data_we, tx_data_title => tx_data_title, tx_data_eof => tx_data_eof, tx_user_flag => tx_user_flag, rx_data => rx_data, rx_data_rd => rx_data_rd, rx_data_title => rx_data_title, rx_data_eof => rx_data_eof, rx_user_flag => rx_user_flag, rx_user_flag_we => rx_user_flag_we, --- MGT --- --- MGT --- rxp => rxp, rxn => rxn, txp => txp, txn => txn, mgtclk_p => mgtclk_p, mgtclk_n => mgtclk_n ); UUT2 : prq_transceiver_gtx_m1 generic map ( is_simulation => 1, -- 1 - LINES => 1, is_tx_dpram_use => 0, -- 1 - is_rx_dpram_use => 1 -- 1 - ) port map ( clk => m2_clk, clk_tx_out => m2_clk_tx_out, clk_rx_out => m2_clk_rx_out, --- SYNC --- --- SYNC --- reset => m2_reset, sync_done => m2_sync_done, tx_enable => m2_tx_enable, rx_enable => m2_rx_enable, ---- DATA ---- ---- DATA ---- tx_ready => m2_tx_ready, rx_ready => m2_rx_ready, tx_data => m2_tx_data, tx_data_we => m2_tx_data_we, tx_data_title => m2_tx_data_title, tx_data_eof => m2_tx_data_eof, tx_user_flag => m2_tx_user_flag, rx_data => m2_rx_data, rx_data_rd => m2_rx_data_rd, rx_data_title => m2_rx_data_title, rx_data_eof => m2_rx_data_eof, rx_user_flag => m2_rx_user_flag, rx_user_flag_we => m2_rx_user_flag_we, --- MGT --- --- MGT --- rxp => m2_rxp, rxn => m2_rxn, txp => m2_txp, txn => m2_txn, mgtclk_p => mgtclk_p, mgtclk_n => mgtclk_n ); rx_err_i <= (others=>rx_err); tx_err_i <= (others=>tx_err); rxp <= m2_txp or rx_err_i; rxn <= m2_txn or rx_err_i; m2_rxp <= txp or tx_err_i; m2_rxn <= txn or tx_err_i; reset <= '0', '1' after 1 us; m2_reset <= '0', '1' after 2 us; tx_enable <= '0', '1' after 22 us; rx_enable <= '0', '1' after 22 us; m2_tx_enable <= '0', '1' after 24 us; m2_rx_enable <= '0', '1' after 24 us; m2_tx_data_we <= '0'; m2_tx_data <= (others=>'0'); m2_tx_data_title <= "0000"; m2_tx_data_eof <= '0'; pr_tx_data: process begin tx_data_we <= '0'; tx_data_eof <= '0'; tx_data <= x"AB000000"; tx_data_title <= "0010"; loop wait until rising_edge( clk ) and tx_ready='1'; tx_data_we <= '1' after 1 ns; for ii in 0 to 255 loop wait until rising_edge( clk ); tx_data <= tx_data + 1 after 1 ns; end loop; tx_data_we <= '0' after 1 ns; wait until rising_edge( clk ); tx_data_eof <= '1' after 1 ns; wait until rising_edge( clk ); tx_data_eof <= '0' after 1 ns; wait until rising_edge( clk ); wait for tx_pause; end loop; end process; pr_rx_data: process variable expect_data : std_logic_vector( 31 downto 0 ):= x"AB000000"; variable error_cnt : integer:=0; variable pkg_cnt : integer:=0; variable pkg_ok : integer:=0; variable pkg_error : integer:=0; variable index : integer; variable flag_error : integer; variable tm_start : time; variable tm_stop : time; variable byte_send : real; variable tm : real; variable velocity : real; variable tm_pkg : time:=0 ns; variable tm_pkg_delta : time:=0 ns; variable L : line; begin m2_rx_data_rd <= '0'; m2_rx_data_eof <= '0'; --fprint( output, L, " \n" ); loop loop wait until rising_edge( m2_clk ); if( m2_rx_ready='1' or now>max_time ) then exit; end if; end loop; if( now>max_time ) then exit; end if; if( pkg_cnt=0 ) then tm_start:=now; tm_pkg:=now; end if; tm_pkg_delta := now - tm_pkg; fprint( output, L, "PKG=%3d %10r ns %10r ns\n", fo(pkg_cnt), fo(now), fo(tm_pkg_delta) ); tm_pkg:=now; index:=0; flag_error:=0; m2_rx_data_rd <= '1' after 1 ns; wait until rising_edge( m2_clk ); loop wait until rising_edge( m2_clk ); if( expect_data /= m2_rx_data ) then if( error_cnt<32 ) then fprint( output, L, "ERROR: pkg=%d index=%d expect=%r read=%r \n", fo(pkg_cnt), fo(index), fo(expect_data), fo(m2_rx_data) ); end if; error_cnt:=error_cnt+1; flag_error:=1; end if; index:=index+1; expect_data:=expect_data+1; if( index=255 ) then m2_rx_data_rd <= '0' after 1 ns; end if; if( index=256 ) then exit; end if; end loop; if( flag_error=0 ) then pkg_ok:=pkg_ok+1; else pkg_error:=pkg_error+1; end if; wait until rising_edge( m2_clk ); m2_rx_data_eof <= '1' after 1 ns; wait until rising_edge( m2_clk ); m2_rx_data_eof <= '0' after 1 ns; wait until rising_edge( m2_clk ); --wait until rising_edge( m2_clk ); wait for rx_pause; pkg_cnt:=pkg_cnt+1; if( pkg_cnt=max_pkg ) then exit; end if; end loop; tm_stop:=now; fprint( output, L, " : %r ns\n", fo(now) ); fprint( output, L, " : %d\n", fo( pkg_cnt ) ); fprint( output, L, " : %d\n", fo( pkg_ok ) ); fprint( output, L, " : %d\n", fo( pkg_error ) ); fprint( output, L, " : %d\n", fo( error_cnt ) ); byte_send:=real(pkg_cnt)*256.0*4.0; tm := real(tm_stop/ 1 ns )-real(tm_start/ 1 ns); velocity := byte_send*1000000000.0/(tm*1024.0*1024.0); fprint( output, L, " : %r /\n", fo( integer(velocity) ) ); flag_error:=0; if( max_pkg>0 and pkg_cnt/=max_pkg ) then flag_error:=1; end if; if( flag_error=0 and pkg_cnt>0 and error_cnt=0 ) then --fprint( output, L, "\n\n \n\n" ); fprint( output, L, "\n\nTEST finished successfully\n\n" ); else --fprint( output, L, "\n\n \n\n" ); fprint( output, L, "\n\nTEST finished with ERR\n\n" ); end if; utils_stop_simulation; wait; end process; pr_tx_user_flag: process begin tx_user_flag <= tx_user_flag + 1; wait for 1 us; end process; pr_m2_tx_user_flag: process begin m2_tx_user_flag <= m2_tx_user_flag + 1; wait for 1.5 us; end process; end TB_ARCHITECTURE;
試験結果:
tc_00_1.log
# KERNEL: PKG= 0 25068 ns 0 ns # KERNEL: PKG= 1 26814 ns 1746 ns # KERNEL: PKG= 2 35526 ns 8712 ns # KERNEL: PKG= 3 36480 ns 954 ns # KERNEL: PKG= 4 37434 ns 954 ns # KERNEL: PKG= 5 38388 ns 954 ns # KERNEL: PKG= 6 39342 ns 954 ns # KERNEL: PKG= 7 40858 ns 1515 ns # KERNEL: PKG= 8 42597 ns 1738 ns # KERNEL: PKG= 9 44339 ns 1742 ns # KERNEL: PKG= 10 46081 ns 1742 ns # KERNEL: PKG= 11 47827 ns 1746 ns # KERNEL: PKG= 12 49566 ns 1738 ns # KERNEL: PKG= 13 51309 ns 1742 ns # KERNEL: PKG= 14 53051 ns 1742 ns # KERNEL: PKG= 15 54790 ns 1738 ns # KERNEL: PKG= 16 56536 ns 1746 ns # KERNEL: PKG= 17 58278 ns 1742 ns # KERNEL: PKG= 18 60021 ns 1742 ns # KERNEL: PKG= 19 61759 ns 1738 ns # KERNEL: PKG= 20 63502 ns 1742 ns # KERNEL: PKG= 21 65248 ns 1746 ns # KERNEL: PKG= 22 66990 ns 1742 ns # KERNEL: PKG= 23 68729 ns 1738 ns # KERNEL: PKG= 24 70471 ns 1742 ns # KERNEL: PKG= 25 72210 ns 1738 ns # KERNEL: PKG= 26 73953 ns 1742 ns # KERNEL: PKG= 27 75699 ns 1746 ns # KERNEL: PKG= 28 77441 ns 1742 ns # KERNEL: PKG= 29 79180 ns 1738 ns # KERNEL: PKG= 30 80922 ns 1742 ns # KERNEL: PKG= 31 82661 ns 1738 ns # KERNEL: : 83598 ns # KERNEL: : 32 # KERNEL: : 32 # KERNEL: : 0 # KERNEL: : 0 # KERNEL: : 534 / # KERNEL: # KERNEL: # KERNEL: TEST finished successfully
右の列に注意してください。 これは、受信パケット間の時間です。 通常の時間は〜1740 nsですが、パケット2は8712 nsの遅延で受信されました。 これは単なるエラー信号でした。 また、次のパケットが954 nsの遅延で受信されたことにも注意してください。 これは、1つのパケットのみが誤って受信され、残りはバッファメモリで順番を待っていたためです。
テストの自動起動は、プロトコルのデバッグ時に非常に役立ちました。 これにより、すべての変更を管理できます。 また、ソースコードを少し変更しても、プロジェクトが崩壊することはありませんでした。
PROTEQプロジェクトは、OpenSourceとして入手できます。 サイトへのリンクは私のプロフィールにあります。