
1.はじめに
これは、機械学習アルゴリズムを使用するための小さな実用的なガイドです。 もちろん、情報の数学的(統計)分析の機械学習アルゴリズムと方法はかなりありますが、このノートはランダムフォレストに特化したものです。 このノートでは、分類と回帰の問題にこのアルゴリズムを使用する例と、いくつかの理論的な説明を示します。
2.木に関するいくつかの言葉
まず、このアルゴリズムのいくつかの基本的な理論的原理を検討し、決定木などの概念から始めます。 私たちの主なタスクは、利用可能な情報に基づいて決定を下すことです。 最も単純なケースでは、クラス間で明確に区別可能な境界を持つ1つの属性(メトリック、予測子、リグレッサー)のみがあります(1つのクラスの最大値は明らかに別のクラスの最小値よりも小さい)。 たとえば、すべての観察結果の中に、ミツバチのような体重を持つクジラが1頭もいないことがわかっている場合、体重を知って、クジラとミツバチを区別する必要があります。 したがって、正確な答えを出すには1つのインジケータ(予測子)で十分であり、それによって正しいクラスを予測できます。
すべての場合で、1つのクラスのポイント(赤で表示)が青のポイントの上にあるとします。 人はそれらの間に直線を引き、これがクラスの境界になると言うことができます。 したがって、この境界より上にあるものはすべて1つのクラスに属し、線の下にあるものはすべて別のクラスに属します。
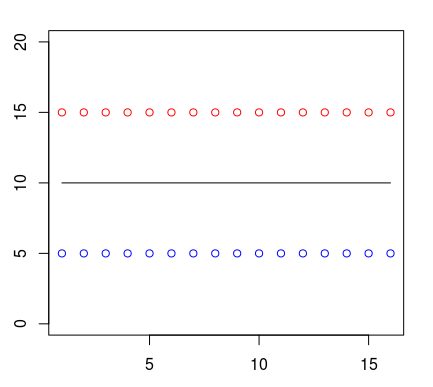
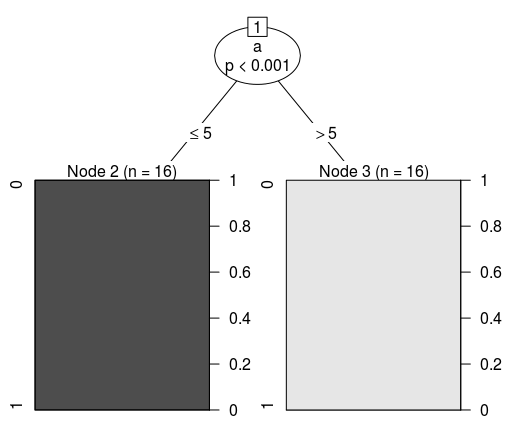
これをツリー構造の形で表します。 アルゴリズムの1つ(CART)を使用して、前述のデータに基づいて決定木を作成する場合、次の分類条件を取得します。
Conditional inference tree with 2 terminal nodes Response: class Input: a Number of observations: 32 1) a <= 5; criterion = 1, statistic = 31 2)* weights = 16 1) a > 5 3)* weights = 16
したがって、その視覚的表現は次のようになります。
もちろん、各特性の重要度は異なります。 次のデータセット(LibSVM形式)から、最初の属性(番号付けはゼロから開始されないため、インデックスは1)はすべてのクラスの代表に対して完全に同一であることがわかります。 実際、このインディケーターには分類の値がないため、冗長情報と呼ばれる場合がありますが、実用的な利点はありません。 同様の状況は、2番目の兆候(予測子)の場合です。 ただし、3番目のものは異なります。
1 1:10 2:20 3:4 0 1:10 2:20 3:5 1 1:10 2:20 3:4 0 1:10 2:20 3:5 1 1:10 2:20 3:4 0 1:10 2:20 3:5 1 1:10 2:20 3:4 0 1:10 2:20 3:5 1 1:10 2:20 3:4 0 1:10 2:20 3:5
3番目の機能(機能2)は、ベクトルからクラスを予測できる大事な区別として機能します。 問題は単一の条件(If-Else)で解決できると仮定するのは論理的です。 実際、機械学習アルゴリズムの各ツリーは、違いを正しく理解していました。 以下は、ランダムフォレストアンサンブルのいくつかのツリーのデバッグ情報です(Apache Spark 2.1.0フレームワークのランダムフォレスト分類子を使用)。
Tree 0: If (feature 2 <= 4.0) Predict: 1.0 Else (feature 2 > 4.0) Predict: 0.0 Tree 1: If (feature 2 <= 4.0) Predict: 1.0 Else (feature 2 > 4.0) Predict: 0.0 Tree 2: If (feature 2 <= 4.0) Predict: 1.0 Else (feature 2 > 4.0) Predict: 0.0
より複雑なタスクには、より複雑なツリーが必要です。 次の例では、パターンは人間にとってそれほど明白ではなくなりました。 違いに気付くには、データセットをより詳しく調べる必要があります。 追加の検証が必要なため、条件はもう少し複雑になります。
1 1:10 2:25 0 1:10 2:20 1 1:15 2:20 0 1:10 2:20 1 1:10 2:25 0 1:10 2:20 1 1:15 2:20 0 1:10 2:20 1 1:10 2:25 0 1:10 2:20 1 1:15 2:20 0 1:10 2:20
これらの追加チェックには、ツリーの新しいブランチ(ノード)が必要です。 各ブランチの後、さらにチェックを行う必要があります。 新しい枝。 これは、デバッグ情報で確認できます。 スペースを節約するために、私はいくつかの木だけを持ってきます。
Tree 0: If (feature 0 <= 10.0) If (feature 1 <= 20.0) Predict: 0.0 Else (feature 1 > 20.0) Predict: 1.0 Else (feature 0 > 10.0) Predict: 1.0 Tree 1: If (feature 1 <= 20.0) If (feature 0 <= 10.0) Predict: 0.0 Else (feature 0 > 10.0) Predict: 1.0 Else (feature 1 > 20.0) Predict: 1.0 Tree 2: If (feature 1 <= 20.0) If (feature 0 <= 10.0) Predict: 0.0 Else (feature 0 > 10.0) Predict: 1.0 Else (feature 1 > 20.0) Predict: 1.0
ここで、100万行と数百(偶数)の列のデータセットを想像してください。 単純な条件では、このような問題を解決するのは難しいことに同意します。 さらに、非常に困難な条件下(深いツリー)では、特定のデータセットに対して特定すぎる(再トレーニングされる)場合があります。 1つのツリーはデータのスケーリングには耐性がありますが、ノイズには耐性がありません。 1つのコンポジションで多数のツリーを組み合わせると、非常に優れた結果を得ることができます。 その結果、非常に効果的で汎用性の高いモデルができました。
3.ランダムフォレスト
実際、ランダムフォレストは多くの決定ツリーの構成(アンサンブル)であり、これにより、再トレーニングの問題が軽減され、単一ツリーと比較して精度が向上します。 予測は、多くのツリーの応答を集約することによって取得されます。 ツリーは(異なるサブセットで)互いに独立してトレーニングされるため、同じデータセットで同じツリーを構築する問題が解決されるだけでなく、このアルゴリズムは分散コンピューティングシステムでの使用に非常に便利です。 一般に、Leo Braimanによって提案されたバギングのアイデアは、計算の分布に適しています。
バギング(分類アルゴリズムの独立したトレーニング、結果は投票によって決定される)の場合、十分な深さを持つ多数の決定木を使用するのが理にかなっています。 分類中、最終結果は、1つのツリーに1つの投票がある場合、ほとんどのツリーが投票したクラスになります。
したがって、たとえば、バイナリ分類問題で500本のツリーを持つモデルが形成され、そのうち100がゼロクラスを示し、残りの400が最初のクラスを示す場合、結果としてモデルは最初のクラスを正確に予測します。 回帰問題にランダムフォレストを使用する場合、ほとんどのツリーが投票したソリューションを選択するアプローチは不適切です。 代わりに、すべてのツリーに対して中程度のソリューションが選択されます。
ランダムフォレスト(深いツリーの独立した構築のため)は多くのリソースを必要とし、深さを制限すると精度が損なわれます(複雑な問題を解決するには、多くの深いツリーを構築する必要があります)。 木のトレーニング時間は、その数に対してほぼ線形に増加することに気付くかもしれません。
当然、木の高さ(深さ)を増やしても生産性に最高の効果はありませんが、このアルゴリズムの効率は向上します(これに伴い、再トレーニングの傾向が高まります)。 再トレーニングを恐れる必要はありません。これは木の数によって補われるからです。 しかし、夢中になってはいけません。 最適に選択されたパラメーター(ハイパーパラメーター)はどこでも重要です。
プログラミング言語Rの分類の例を考えてみましょう。回帰モデルではなく分類モデルが必要になったため、最初のパラメーターをクラスファクターとして明示的に設定する必要があります。 ツリーの数に加えて、基本モデル(ツリー)が分岐に使用する記号の数(mtry)にも注意を払います。 実際、これらは最初に設定するのが理にかなっている2つの主要なパラメーターです。
library(randomForest) dataset <- read.csv(file="/home/kalinin84/data/real.csv", head=TRUE, sep=",") model <- randomForest(factor(Class) ~ ., data=dataset, ntree=250, mtry=9)
これが分類のモデルであることを確認してください。
model$type
混同マトリックスの結果を見てみましょう。
model$confusion
予測値(out-of-bagに基づく)を見るのは興味深いです:
model$predicted
varImpPlotおよび重要度関数は、予測子(分類子の精度の値)の重要度を表示するように設計されています。
varImpPlot(model) importance(model)
もちろん、ありそうなクラスを取得する特別な関数があります。 予測と呼ばれます。 モデルには最初の引数と、2番目のデータセットが必要です。 結果は、予測されたクラスのベクトルです。 信頼性の高い検証を行うには、あるデータセットでトレーニングを実行し、別のデータセットで検証を実行する必要があります。
別の例。 今回はApache Spark 2.1.0とScalaプログラミング言語を使用します。 LibSVMファイルから情報を読み取ります。 その後、データセットを明示的に2つの部分に分割する必要があります。 そのうちの1つはトレーニングで、2つ目はテストです。 標準化または正規化を行う意味はありません。 私たちのモデルはこれに対して抵抗力があるだけでなく、さまざまな性質(体重、年齢、収入)のデータに対して十分な抵抗力があります。
トレーニングはトレーニングサンプルでのみ行う必要があることを繰り返します。 この例のクラスの数は2つです。 木の数を50とします。理論的にはエントロピーの使用はそれほど効果的な基準ではないため、Ginnyインデックスを分割の基準として残しましょう。 ツリーの深さは9に制限されています。
import org.apache.spark.mllib.tree.RandomForest import org.apache.spark.mllib.tree.model.RandomForestModel import org.apache.spark.mllib.util.MLUtils val data = MLUtils.loadLibSVMFile(sc, "/home/kalinin84/data/real.data") val splits = data.randomSplit(Array(0.7, 0.3)) val (trainingData, testData) = (splits(0), splits(1)) val model = RandomForest.trainClassifier(trainingData, 2, Map[Int, Int](), 50, "auto", "gini", 9, 32)
ここで、テストデータセットを使用して、指定されたパラメーターで分類器の動作をテストします。 精度のしきい値(モデルの適合性)は、それぞれの場合に個別に決定されることに注意してください。
import org.apache.spark.mllib.evaluation.BinaryClassificationMetrics val result = testData.map(p => (p.label, model.predict(p.features))) val metrics = new BinaryClassificationMetrics(result) // : 1.0 — .. ROC metrics.areaUnderROC // : Array((0.0,0.0), (0.0,1.0), (1.0,1.0), (1.0,1.0)) metrics.roc.collect
入力として予測子のベクトルを受信すると、システムはオブジェクトのクラスを(許容される確率で)推測する必要があります。 大きなデータセットを何度かチェックした結果、これを実行できた場合は、モデルの精度を述べることができます。 ただし、人の身長によって非常に高い精度で教育レベルを推測できる人やシステムはありません。 したがって、データを正しく収集および準備しないと、問題を解決することは困難(またはまったく不可能)になります。
4.実用化に関するいくつかの考え
単純な条件または記述統計の方法ではすぐに問題が解決しない場合があります。 インターネットプロジェクトの有効性を高めるタスク(顧客分析、購入の可能性の特定、最適な広告戦略、人気のあるブロックに表示する製品の選択、推奨事項と個人ランキング、カタログとディレクトリのエントリの分類)にあり、同様の複雑なデータセットがあります。
数年前、MLテクノロジーを使用する必要に直面したのは初めてです。 私の同僚(開発チーム)が、非常に大きなポータルで詳細なリファレンスブックの資料を分類する方法を考え出そうとしたときがありました。 以前は、分類は他の専門家によって手動で実行されていたため、膨大な時間がかかりました。 しかし、自動化はどのようにも機能しませんでした(ルールと統計的手法では必要な精度が得られませんでした)。 既に専門家がマークしたベクトルのセットがありました。
その後、数行のコード(一般的な機械学習ライブラリの1つを使用)で文字通りすぐに問題を解決できることに驚きました。 当然、さまざまなモデル(ニューラルネットワークを含む)を使用する可能性が研究され、合理的なハイパーパラメーターが考え出されました。 しかし、この記事はランダムフォレストに関するものなので、Pythonプログラミング言語の例を彼に捧げます。 当然、サンプルコードは既製の分類子の新しいバージョンを考慮して記述されており、その後は使用されません。
import pandas as pd from sklearn.metrics import classification_report, accuracy_score from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier # # # dataset = pd.read_csv('/home/kalinin84/data/real.csv') # # ( ) # train, test = train_test_split(dataset, test_size = 0.4) classes = train.pop('Class').values features = train testClasses = test.pop('Class').values testFeatures = test # # # model = RandomForestClassifier(n_estimators=500, max_depth=30).fit(features, classes) # # # print(classification_report(testClasses, model.predict(testFeatures))) print(accuracy_score(testClasses, model.predict(testFeatures)))
そのような例はたくさんあります。 別の話をします タスクは、巨大な広告管理システムの有効性を高めることでした。 彼女の仕事は、商品やサービスの評価を予測する精度に直接依存していました。 それぞれに64の標識のベクトルがありました。 新しい特徴ベクトルごとに、事前に評価値の比較的正確な予測を行うことが戦略的に重要でした。 これに先立ち、システムは単純なルールと記述統計によって制御されていました。 しかし、ご存知のように、そのような問題にはあまり効率と正確さはありません。 効率の向上の問題を解決するために、例に示されているものと同様の回帰モデルが使用されました。
from sklearn.datasets import load_svmlight_files from sklearn.metrics import mean_squared_error from sklearn.ensemble import RandomForestRegressor # # ( ) # X, y, Xt, yt = load_svmlight_files(("/data/001.data", "/data/001_test.data")) # # # model = RandomForestRegressor(n_estimators=500, max_features=5).fit(X,y) print(mean_squared_error(yt, model.predict(Xt))) # # # # import xgboost as xgb modelXGB = xgb.XGBRegressor().fit(X, y) print(mean_squared_error(yt, modelXGB.predict(Xt)))
その結果、他の方法では最良の結果が得られないタスクで救助できる情報を分析するためのかなり強力なツールが得られます。