理論
OSSIプロトコル(Operations Support Systems Interface)は、さまざまなアドオンモジュールとメインPBXモジュール(この場合はCommunication Manager)の相互作用のためにAvaya製品で使用されます。 サーバーへの接続中に正しい端末タイプを選択するだけでアクセスできます。
ossiとossimtの 2種類の端末が大きな注目に値します。 最初のタイプは、CMの直接作業、情報の取得、およびPBX設定の変更に使用されます。 2番目のタイプは、最初のタイプで使用されるフィールドの識別子を実際の目的と一致させるために使用されます。 これが必要な理由は CMのさまざまなバージョンでは、不可能なものを見つけるために事前にさまざまな識別子が使用されます。
標準ossi端末出力:

このタイプの特徴は、端末に入力された文字が表示されず、削除されないという事実です。
ossimtターミナルからの標準出力:
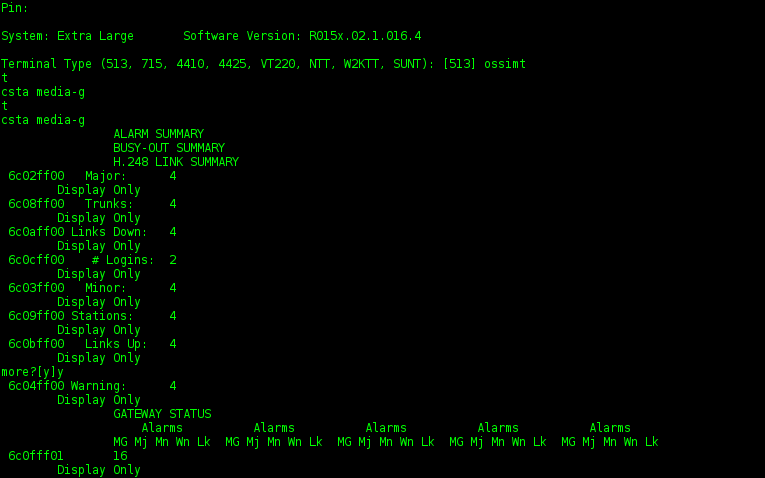
プロトコルの相互作用は、特定のタイプの文字列を送信することにより実行されます。 行のタイプは、行の先頭で置換されるポインターによって決定されます。 これらのポインターのリスト:
- c (コマンド)-実行可能なコマンドを含む文字列へのポインター。
- f (フィールド)-フィールド識別子を含む文字列へのポインタ。
- d (データ)-フィールドに従って、データを含む行へのポインター。
- e (エラー)-エラーメッセージを含む行へのポインター。
- t (終了)-情報の入力/出力の終わりへのポインター
端末での情報の入出力は、次の形式で実行されます。
<>[RETURN]
f< 1>[TAB]< 2>[TAB]< 3>[RETURN]
d< 1>[TAB]< 2>[TAB]< 3>[RETURN]
t[RETURN]
つまり 各行は改行文字で終了し(Enterキーを押す)、タイプフィールドとデータ要素の内側の行はタブ文字で区切られます(Tabキーを押す)。
最初の3種類の文字列を詳しく見てみましょう。
c (コマンド)
この行には、実行するコマンドが含まれている必要があります。 一般に、コマンドは端末の標準管理で使用されるコマンドと同じです。 次のように入力して、使用可能なコマンドのリスト全体を呼び出します。
chelp
t
f (フィールド)
この行には、入力したコマンドのフィールド識別子がリストされます。 フィールド間の分離はタブ文字によって実行されます。 これらの識別子はHEX形式で記述されており、どのフィールドが何に対応するかを理解するには、 ossimtに連絡する必要があります。 コマンドによって送信される情報の量に応じて、このタイプの複数の行がある場合があります。
d (データ)
この行には、前のタイプの行で指定された対応するフィールドに関連するデータがリストされます。 データもタブで区切られています。 このタイプの行数は、タイプフィールドの行数の倍数でなければならないことに注意してください。
フィールドやデータなどの行は、主にコマンドを入力した後に情報を表示するために使用されますが、システムに変更を加えるとき(例: チェンジステーションXXXX )、または追加のパラメーターを受け入れるコマンドを出力するとき(たとえば、 アラームを表示する )に使用できます これらの行を追加するには、 コマンドラインの後にだけで十分で、変更する対応するフィールドとデータをそれらに示します。
たとえば、ターミナルで入力する:
cha st 1000
f8003ff00
dI.C. Wiener
t
拡張子1000のIC Wienerの拡張子名を変更します。
厳密に言えば、 ossiなどの端末がいくつかあります 。 私は少なくとも3を知っています: ossi 、 ossi3 、 ossis 。 それらの間に大きな違いはありません。 表示される機能のうち、コマンドの結果を出力するときに、そのオシスだけがコマンド自体の文字列を返しません。
練習する
もちろん、説明されていることはすべて良いことです。 しかし、このプロトコルはどのように使用できますか? たとえば、たとえば、何らかの監視を行うことができます。 たとえば、メディアゲートウェイの監視を検討してください。
通常のステータスメディアゲートウェイとPythonコマンドがこれに役立ちます。
手順1:接続して情報を取得します。
import telnetlib tn = telnetlib.Telnet('127.0.0.1', '5023') # 5023 tn.read_until('login'.encode()) # tn.write('username\n'.encode()) tn.read_until('Password'.encode()) # tn.write('password\n'.encode()) tn.read_until('Pin'.encode()) # - tn.write('pin\n'.encode()) tn.read_until('Terminal'.encode()) # tn.write('ossi\n'.encode()) tn.read_until('t\n'.encode()) # \ # , tn.write('csta media-g\n'.encode()) # command tn.write('t\n'.encode()) # terminate output = tn.read_until('t\n'.encode()) # , terminate. output = output.decode('utf-8') #
これで、何でも作成できる行形式の情報が得られました。
出力
'\ncsta media-g\nf6c02ff00\t6c08ff00\t6c0aff00\t6c0cff00\t6c03ff00\nf6c09ff00\t6c0bff00\t6c04ff00\t6c0fff01\t6c0fff02\nf6c0fff03\t6c0fff04\t6c0fff05\t6c0fff06\t6c0fff07\nf6c0fff08\t6c10ff09\t6c10ff0a\t6c10ff0b\t6c10ff0c\nf6c10ff0d\t6c10ff0e\t6c10ff0f\t6c10ff10\t6c11ff11\nf6c11ff12\t6c11ff13\t6c11ff14\t6c11ff15\t6c11ff16\nf6c11ff17\t6c11ff18\t6c12ff19\t6c12ff1a\t6c12ff1b\nf6c12ff1c\t6c12ff1d\t6c12ff1e\t6c12ff1f\t6c12ff20\nf6c13ff21\t6c13ff22\t6c13ff23\t6c13ff24\t6c13ff25\nf6c13ff26\t6c13ff27\t6c13ff28\nd0\t0\t0\t01\t0\nd0\t26\t40\t2 0| 0| 3|up\t5 0| 0| 2|up\nd8 0| 0| 3|up\t9 0| 0| 5|up\t10 0| 0| 3|up\t11 0| 0| 3|up\t12 0| 0| 1|up\nd13 0| 0| 0|up\t14 0| 0| 1|up\t15 0| 0| 0|up\t16 0| 0| 3|up\t180| 0| 0|up\nd19 0| 0| 0|up\t21 0| 0| 0|up\t22 0| 0| 0|up\t23 0| 0| 4|up\t24 0| 0| 1|up\nd25 0| 0| 1|up\t26 0| 0| 0|up\t27 0| 0| 0|up\t28 0| 0| 1|up\t29 0| 0| 1|up\nd30 0| 0| 1|up\t33 0| 0| 1|up\t34 0| 0| 5|up\t37 0| 0| 1|up\t\nd\t\t\t\t\nd\t\t\t\t\nd\t\t\nt\n'
ステップ2:受信した情報を解析します。
上記の行の種類に応じて、利用可能な情報を分離する必要があります。 なぜなら 1つのタイプの行数は複数になる場合があるため、それらのシーケンスを考慮する必要があります。
fields = {} # data = {} # lines = output.split('\n') # for line in lines: # if line.startswith('d'): # data data.update({ len(data): line[1:] # }) elif line.startswith('f'): # field fields.update({ len(fields): line[1:] }) elif line.startswith('t'): # terminate break else: # pass parse = { 'fields': fields, 'data': data, }
これらのアクションの結果として、次の解析変数を取得します。
解析する
{ 'fields': { 0: '6c02ff00\t6c08ff00\t6c0aff00\t6c0cff00\t6c03ff00', 1: '6c09ff00\t6c0bff00\t6c04ff00\t6c0fff01\t6c0fff02', 2: '6c0fff03\t6c0fff04\t6c0fff05\t6c0fff06\t6c0fff07', 3: '6c0fff08\t6c10ff09\t6c10ff0a\t6c10ff0b\t6c10ff0c', 4: '6c10ff0d\t6c10ff0e\t6c10ff0f\t6c10ff10\t6c11ff11', 5: '6c11ff12\t6c11ff13\t6c11ff14\t6c11ff15\t6c11ff16', 6: '6c11ff17\t6c11ff18\t6c12ff19\t6c12ff1a\t6c12ff1b', 7: '6c12ff1c\t6c12ff1d\t6c12ff1e\t6c12ff1f\t6c12ff20', 8: '6c13ff21\t6c13ff22\t6c13ff23\t6c13ff24\t6c13ff25', 9: '6c13ff26\t6c13ff27\t6c13ff28' }, 'data': { 0: '0\t0\t0\t01\t0', 1: '0\t26\t40\t2 0| 0| 3|up\t5 0| 0| 2|up', 2: '8 0| 0| 3|up\t9 0|0| 5|up\t10 0| 0| 3|up\t11 0| 0| 3|up\t12 0| 0| 1|up', 3: '13 0| 0| 0|up\t14 0| 0| 1|up\t15 0| 0| 0|up\t16 0| 0| 3|up\t18 0| 0| 0|up', 4: '19 0| 0| 0|up\t21 0| 0| 0|up\t22 0| 0| 0|up\t23 0| 0| 4|up\t24 0| 0| 1|up', 5: '25 0| 0| 1|up\t26 0| 0| 0|up\t27 0| 0| 0|up\t28 0| 0| 1|up\t29 0| 0|1|up', 6: '30 0| 0| 1|up\t33 0| 0| 1|up\t34 0| 0| 5|up\t37 0| 0| 1|up\t', 7: '\t\t\t\t', 8: '\t\t\t\t', 9: '\t\t' } }
ステップ3:フィールドとデータを一致させます。
最後に、フィールド識別子をデータの特定の値にマッピングする必要があります。
result = {} # for i in range(len(parse['fields'])): # fids = parse['fields'][i].split('\t') # data = parse['data'][i].split('\t') for i in range(len(fids)): result.update({ fids[i]: data[i] # })
その結果、フィールド識別子がキーとして使用され、このフィールドに対応するデータが値として使用される辞書を取得します。
結果
{ '6c10ff0e': '21 0| 0| 0|up', '6c11ff16': '29 0| 0| 1|up', '6c13ff22': '', '6c0fff01': '2 0| 0| 3|up', '6c10ff0c': '18 0| 0| 0|up', '6c11ff15': '28 0| 0| 1|up', '6c10ff0d': '19 0| 0| 0|up', '6c12ff20': '', '6c10ff09': '14 0| 0| 1|up', '6c0fff03': '8 0| 0| 3|up', '6c10ff0f': '22 0| 0| 0|up', '6c11ff14': '27 0| 0| 0|up', '6c04ff00': '40', '6c13ff26': '', '6c10ff0b': '16 0| 0| 3|up', '6c10ff0a': '15 0| 0| 0|up', '6c0fff08': '13 0| 0| 0|up', '6c13ff25': '', '6c0cff00': '01', '6c12ff1f': '', '6c11ff18': '33 0| 0| 1|up', '6c13ff27': '', '6c11ff12': '25 0| 0| 1|up', '6c0fff06': '11 0| 0| 3|up', '6c0bff00': '26', '6c03ff00': '0', '6c11ff11': '24 0| 0| 1|up', '6c0aff00': '0', '6c10ff10': '23 0| 0| 4|up', '6c13ff28': '', '6c0fff07': '12 0| 0| 1|up', '6c12ff1b': '', '6c02ff00': '0', '6c0fff05': '10 0| 0| 3|up', '6c13ff23': '', '6c12ff1e': '', '6c08ff00': '0', '6c12ff1d': '', '6c12ff1a': '37 0| 0| 1|up', '6c11ff13': '26 0| 0| 0|up', '6c12ff1c': '', '6c13ff24': '', '6c13ff21': '', '6c0fff02': '5 0| 0| 2|up', '6c09ff00': '0', '6c12ff19': '34 0| 0| 5|up', '6c0fff04': '9 0| 0| 5|up', '6c11ff17': '30 0| 0| 1|up' }
最終:利益
そのため、メディアゲートウェイのステータスに関するすべての情報を含む辞書があります。 私たちはそれが何の識別子かを知ることができるだけです。 思い出すように、これはossimtを使用して行われます。 たとえば、 メジャーアラーム 、 マイナーアラーム 、 警告の各フィールドは、識別子6c02ff00、6c03ff00、6c04ff00に対応しています。 辞書でそれらを探しており、重大なエラーは1つもありませんが、40の警告しかありません。 あなたは生きることができます。
取得したデータを少し使用して、端末から直接利用できるメディアゲートウェイの非常に適切な監視を取得できます。 たとえば、次の図を取得できます。
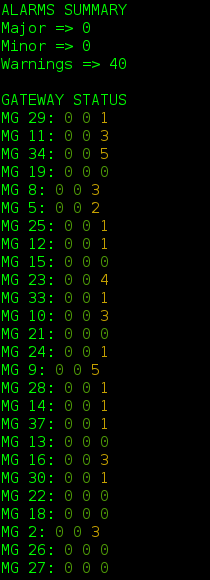
そして、あなたが幸運でなければ、これは:
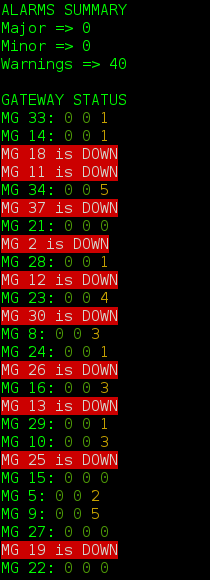
便宜上、このプロトコルを使用するための小さなクラスを開発しました 。 こちらで確認できます 。