Habréのブログでは、情報セキュリティに関連するトピックだけでなく、ソフトウェア開発の問題にも大きな注意を払っています 。たとえば、DevOps ツールの作成と実装のサイクルを実施しています 。 今日は、ドメイン固有言語(DSL)を使用して、Pythonを使用して特定の問題を解決する方法について説明します。
この資料は、PYCON RussiaカンファレンスでのPositive Technologies開発者Ivan Tsyganovのプレゼンテーションに基づいて作成されました( スライド 、 ビデオ )。
挑戦する
独自のログローテーションシステムを記述することにしたと想像してください。 明らかに、それを設定する必要があります。 実際のLog Rotate設定の構造は、Pythonの辞書に似ています。 この方法で、設定を辞書に書き込んでみましょう。
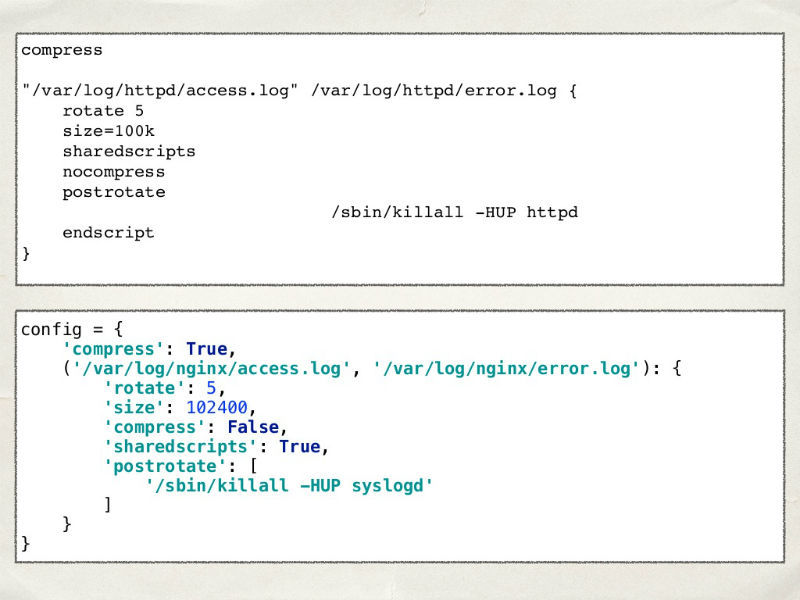
すべてがうまくいくようです-ファイルのリストがあり、ローテーション期間もあります、すべてが同じです。 唯一の違いは、Log Rotateでは、ファイルのサイズを測定するための単位を指定できることですが、構成ではまだです。 最初の考えは、それらを特別な行に設定して処理し、スペースで分割できるようにすることです。

これは、システムのユーザーが使用するサイズ(「1メガバイト+ 100キロバイト」)に特定のデルタを示す機会をユーザーに提供するように要求する瞬間まで機能する良い方法です。 なぜ彼らはそれを必要としなかったと言わなかったが、私たちはユーザーを愛している。 この機能を実装するには、正規表現を使用します。

動作しているように見えますが、ユーザーは加算、減算、乗算、除算の演算だけでなく、すべての算術演算もサポートしたいと考えています。 そしてここで、正規表現を使用してこのような問題を解決するのは良い考えではないことが明らかになります。 このサブジェクト指向の言語にとってははるかに優れています。
DSLとは何ですか?
Martin Fowlerの定義によれば、ドメイン固有言語(DSL)は、特定の分野に焦点を絞った、表現力が限られた言語です。
内部および外部DSLがあります。 前者にはPonyORM、WTForm、Djangoモデルなどのライブラリが含まれ、後者にはSQl、REGEXP、TeX / LaTeXが含まれます。 内部DSLは基本言語の一種の拡張であり、外部DSLは完全に独立した言語です。
タスク用の内部DSLを開発する場合、構成ファイル内で使用できる関数または定数を作成できます。

しかし、ベース言語によって課せられた制限は保持され、書き込み時に数値と変数(MB、KB)の間の余分な角括弧と乗算記号を取り除くことに成功しません。
外部DSLを使用すると、自分で構文を思い付くことができます。これにより、不要な角かっこと乗算記号を取り除くことができます。 ただし、言語のアナライザーを開発する必要があります。
タスクに戻る
しかし、構成ファイルをコードとは別に保存する必要がある場合はどうでしょうか? これで問題はありません。 構成辞書をYAMLファイルに保存して、ユーザーが編集できるようにするだけです。
技術的には、このYAMLは既に外部DSLであり、解析するためにアナライザーを必要としません。 既存のライブラリを使用してロードし、サイズフィールドのみを処理できます。

Pythonのパーサー
パーサーを作成するためのPythonの機能をご覧ください。
PLYライブラリ(Python Lex-Yacc)
アナライザーは、字句アナライザーと構文アナライザーで構成されています。 ソーステキストは、字句解析器の入力に送られます。字句解析器のタスクは、テキストをトークンのストリーム、つまり言語のプリミティブに分割することです。 このトークンのストリームはパーサーに入り、相互の相対的な位置の正確性をチェックします。 すべてが正常な場合、コード生成、実行、または抽象構文ツリーの構築が実行されます。
トークンは正規表現で記述されます:算術演算用の4つのトークン、ユニット、数字、および括弧用のトークン。 以下の式を字句アナライザに提供すると、次のトークンストリームに解析されます。

しかし、意味的に正しくない文字列を渡すと、意味のないトークンのセットを取得できます。

トークンの正しい場所を分析する際の不必要な作業を避けるために、言語の文法を記述する必要があります。

式は、数値または数字の後に測定単位、括弧内の式、または何らかの操作で区切られた2つの式であると定義します。
各ルールについて、それによって記述された条件が発生したときにパーサーが何をすべきかについての説明が必要です。 算術を扱っているので、乗算、角括弧などの演算の優先順位で、そのすべての規則に従うことも望ましいです。
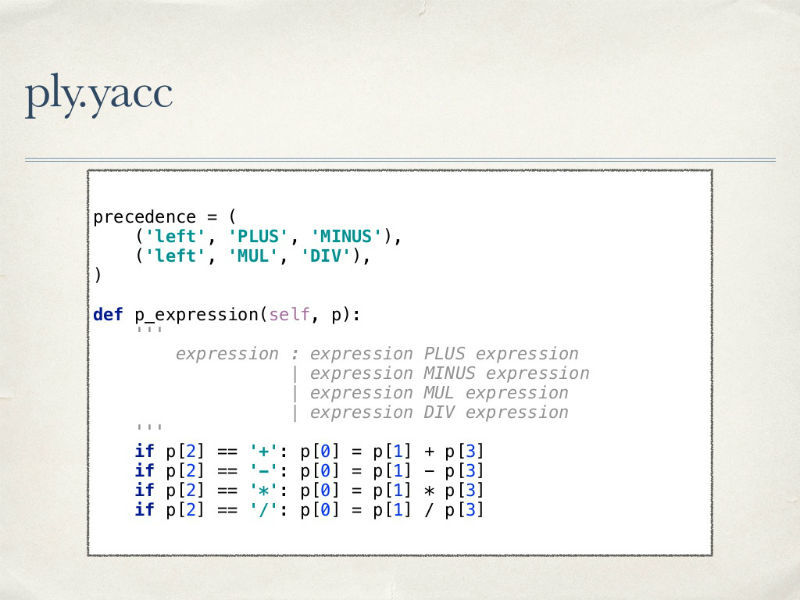
PLYツールの使用には多くの利点があります。柔軟性があり、アナライザーに便利なデバッグメカニズムを提供し、優れたエラー処理方法を提供し、ライブラリ自体のコードをよく読みます。
ただし、マイナスなしではできません。ツールの使用開始時の入力しきい値は非常に高く、PLYを使用するアナライザーは非常に冗長です。
Funcparserlibライブラリ
アナライザーを作成するためのもう1つの興味深いツールは、funcparserlibライブラリーです。 これは、機能的なパーサーの組み合わせです。 このライブラリを使用したアナライザーの開発も、正規表現の形式でのトークンの宣言から始まります。 次に、パーサー自体について説明します。プリミティブを指定し、使用する操作について説明します。これらの操作は、処理の便宜のために優先順位(乗算および除算/加算および減算)によってグループ化されます。

次に、残りの文法を記述する必要があります。このため、式がどのように見えるかを記述し、操作の優先順位を記述します。

funcparserlibの利点には、このライブラリのコンパクトさと柔軟性が含まれます。 同じコンパクトさのため、多くのことをあなたの手で行う必要があります-箱から出して利用できる多くの可能性はありません。 また、このライブラリは関数型パーサーの組み合わせであるため、関数型プログラミングの愛好家にアピールします。
パイパーシングライブラリ
アナライザーを作成する別のオプションは、pyparsingライブラリーです。 パーサーコードを見てください:
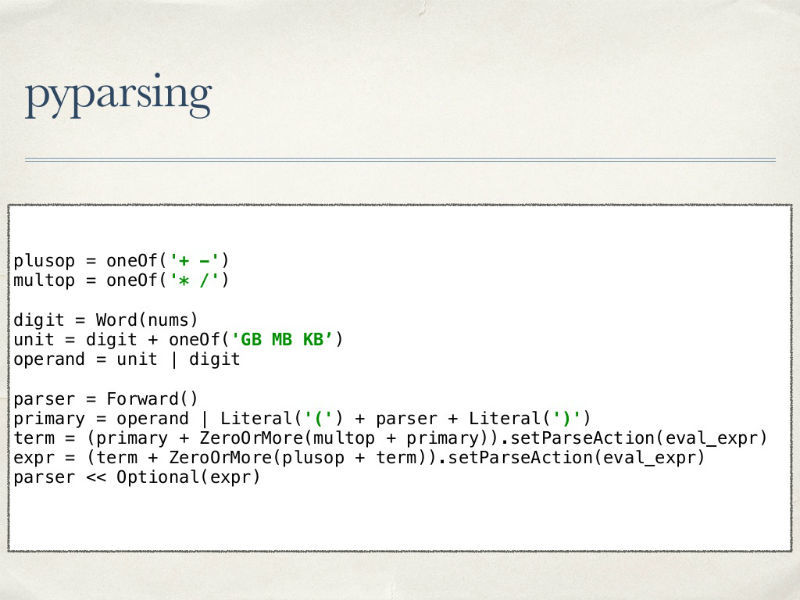
トークンはどこにも記述されていません。優先順位を考慮に入れて、最終言語と式の操作の記述にすべての注意が直ちに払われます。
すぐに利用できるpyparsingには、優先度を操作するためのメソッドなどの便利な基本要素があります。これにより、コードが簡素化され、理解しやすくなります。 さらに、機能を拡張し、独自のコンポーネントを作成する可能性があります。 一方、このツールは高品質のドキュメントが入手できることを自慢することはできません。また、結果のコンパクトアナライザーのデバッグは、PLYを使用した冗長アナライザーよりもはるかに困難です。
パフォーマンスはどうですか
説明した各ライブラリを使用する場合の作業の速度について話しましょう。 分析では、単純なケースを処理する場合、PLYが最速であることがわかりました。

テスト中、すべてのアナライザーにゼロから9999までのすべての数値を追加するタスクを「送り」ました。候補がミリ秒単位で示した結果は次のとおりです。

エラーメッセージ
ログローテーションシステムの構成内のフィールドの1つを解析するためにアナライザーを作成したことを忘れないでください。 明らかに、アナライザーでエラーが発生した場合、ユーザーはこのことをわかりやすい形式で通知する必要があります。どの行で、どの位置で、何が間違っていたかです。
PLYのもう1つのプラス-ライブラリには、字句解析および解析の段階で発生するエラーを処理するための組み込みメカニズムがあります。 この場合、パーサーの状態は失われません-エラーの後、作業を続けることができます

最終的に選択するもの
パーサー作成ツールの最終的な選択は、実装のタスクと条件によって異なります。 そのような組み合わせの多くは区別できます:
- すべてをすばやく説明する必要があるが、速度が重要でない場合は、pyparsingが非常に適しています。
- 関数型プログラミングが好きで、パフォーマンスもそれほど重要ではない場合-funcparserlibは当然の選択です。
- しかし、作業の速度が最も重要であり、教科書に従って「予想どおり」にすべてのルールを説明したい場合は、もちろん、PLYを選択する必要があります。
言語自体を使用してユーザーデータを処理できる場合は、そうするか、正規表現を使用する必要があります。 より複雑なケースでは、内部DSLの使用から始めるのが理にかなっており、このオプションが適切でない場合は、データ(Yaml、Json、XML)の構造化に既製の言語を使用し始めます。 上記のいずれでも問題を解決できない場合は、極端な場合に独自のアナライザーを作成する必要があります。