この問題は、単純な明示的差分スキームによって2次元の場合に解決されました。 暗黙のスキームは好きではありません、そしてそれらは多くのメモリを必要とします。 通常の精度での計算には、小さなステップグリッドが必要です;単純な方法と比較すると、非常に長い時間がかかります。 したがって、パフォーマンスに最大の重点が置かれました。
JavaおよびC ++でのアルゴリズムの実装が示されています。

まえがき
約6年間、Matlabは計算やささいなことのための私の主要な言語でした。 その理由は、結果の記述と視覚化の容易さです。 そして、Borland C ++ 3.1から切り替えて以来、機能の進歩は明らかでした。 (Pythonでは、私は決して手探りしませんでしたが、C ++では弱くなりました)。
信頼できる信頼できる方法として、計算にFDTDが必要でした。 彼は2010-11年に問題の研究を始めました。 利用可能なパッケージは、使用方法を理解していないか、必要なものを知りませんでした。 私はすべてを明確に制御するプログラムを書くことにしました。 古典的な記事「 等方性媒体でのマクスウェル方程式を含む初期境界値問題の数値解 」を読んだ後、彼は3次元のケースを書きましたが、それを2次元のケースに単純化しました。 3Dが難しい理由は、後で説明します。
次に、Matlabコードを可能な限り最適化および簡素化しました。 すべての改善の後、2000x2000グリッドは107分で完成できることがわかりました。 i5-3.8 GHzで。 その後、この速度で十分でした。 便利なのは、Matlabでは、複雑なフィールドの計算がすぐに行われ、分布図を簡単に表示できることでした。 また、Matlabの速度は実質的に影響を受けなかったため、すべてが2倍と見なされました。 はい、私の標準的な計算は、フォトニック結晶を通る光の1パスです。
2つの問題がありました。 高精度でスペクトルを計算する必要があり、そのためには大きなグリッド幅を使用しました。 両方の座標の面積が2倍になると、計算時間が8倍になります(結晶サイズ*通過時間)。
私は引き続きMatlabを使用しましたが、Javaプログラマーになりました。 そして、異なるアルゴリズムのパフォーマンスを比較して、彼は何かを疑い始めました 。 たとえば、Matlabのバブルソート-ループ、配列、比較のみ-は、C ++またはJavaの6倍遅くなります。 そして、これは彼にとってまだ良いことです。 Matlabのオイラー仮説の5次元サイクルは400倍長くなります。
最初はC ++でFDTDを書き始めました。 組み込みのstd :: complexがありました。 しかし、その後、私はこの考えを放棄しました。 (Matlabにはこのような括弧がありません。コピーペーストは機能しませんでした。時間をかけなければなりませんでした)。 今、私はC ++をチェックしました- 複雑な数学は5倍の速度の損失を与えます。 これは多すぎる。 その結果、私はJavaで書きました。
「なぜJavaなのか?」という質問について少し。 パフォーマンスの詳細については後で説明します。 要するに-単純な非OOPコードでは、算術演算とループのみ-O3最適化または同じ速度のC ++、または最大+ 30%高速。 Java、インターフェース、グラフィックスの操作に精通しているというだけです。
FDTD-詳細
それでは、コードに移りましょう。 タスクとアルゴリズムの説明とともに、すべてを表示しようとします。 2次元の場合、Maxwell方程式のシステムは、TE波とTM波の2つの独立したサブシステムに分割されます。 TEのコード。 3つのコンポーネントがあります-電界Ezと磁気Hx、Hy。 簡単にするために、時間にはメートルの次元があります。
最初は、すべての計算がdoubleにキャストされるため、floatにポイントはないと考えました。 したがって、私はダブルのコードを提供します-それよりも少ないです。 すべての配列のサイズは+1であるため、インデックスはMatlabマトリックスと一致します(0からではなく1から)。
ソースコードのどこかに:
public static int nx = 4096;// . 2 . public static int ny = 500;//
主な方法:
初期変数の初期化
public static double[][] callFDTD(int nx, int ny, String method) { int i, j;// double x; // final double lambd = 1064e-9; // final double dx = lambd / 15; // . λ/10. , . final double dy = dx; // . final double period = 2e-6; // final double Q = 1.0;// final double n = 1;// final double prodol = 2 * n * period * period / lambd / Q; // final double omega = 2 * PI / lambd; // final double dt = dx / 2; // . , final double tau = 2e-5 * 999;// . . , . final double s = dt / dx; // final double k3 = (1 - s) / (1 + s);// final double w = 19e-7;// final double alpha = sin(0.0 / 180 * PI);// . . double[][] Ez = new double[nx + 1][ny + 1]; double[][] Hx = new double[nx][ny]; // double[][] Hy = new double[nx][ny];
final int begin = 10; // , . . final double mod = 0.008 * 2;// = 2*Δn; final double ds = dt * dt / dx / dx;//
誘電率の初期化(結晶格子)。 より正確には、定数との逆数。 離散関数(0または1)が使用されます。 実際のサンプルに近いようです。 もちろん、ここに何かを書くことができます:
double[][] e = new double[nx + 1][ny + 1]; for (i = 1; i < nx + 1; i++) { for (j = 1; j < ny + 1; j++) { e[i][j] = ds / (n + ((j < begin) ? 0 : (mod / 2) * (1 + signum(-0.1 + cos(2 * PI * (i - nx / 2.0 + 0.5) * dx / period) * sin(2 * PI * (j - begin) * dy / prodol))))); } }
結晶格子は次のようになります。

境界条件に使用される配列:
double[][] end = new double[2][nx + 1]; double[][] top = new double[2][ny + 1]; double[][] bottom = new double[2][ny + 1];
アカウントの制限時間。 ステップdt = dx / 2があるため、標準係数は2です。媒体が密である場合、または角度を付けて移動する必要がある場合は、さらに多くなります。
final int tMax = (int) (ny * 2.2);
メインサイクルを開始します。
for (int t = 1; t <= tMax; t++) { double tt = Math.min(t * s + 10, ny - 1);
ここでの変数ttは、わずかなマージンで、光の速度の制限を考慮しています。 光が届く可能性のある領域のみを考慮します。
複素数の代わりに、サインとコサインの2つのコンポーネントを個別に検討します。 ループ内で選択するよりも、速度のためにピースをコピーする方が良いと思いました。 おそらく、関数呼び出しまたはラムダに置き換えます。
switch (method) { case "cos": for (i = 1; i <= nx - 1; i++) { x = dx * (i - (double) nx / 2 + 0.5); // Ez[i][1] = exp(-pow(x, 2) / w / w - (t - 1) * dt / tau) * cos((x * alpha + (t - 1) * dt) * omega); } break;
罪
case "sin": for (i = 1; i <= nx - 1; i++) { x = dx * (i - (double) nx / 2 + 0.5); Ez[i][1] = exp(-pow(x, 2) / w / w - (t - 1) * dt / tau) * sin((x * alpha + (t - 1) * dt) * omega); } break; }
ここでは、領域の入り口(左端の座標)に、角度アルファで、時間的に振動する半値幅wのガウスビームがあります。 それが、望ましい周波数/波長の「レーザー」放射が発生する方法です。
次に、 ムーアの吸収境界条件の下で一時配列をコピーします 。
for (i = 1; i <= nx; i++) { end[0][i] = Ez[i][ny - 1]; end[1][i] = Ez[i][ny]; } System.arraycopy(Ez[1], 0, top[0], 0, ny + 1); System.arraycopy(Ez[2], 0, top[1], 0, ny + 1); System.arraycopy(Ez[nx - 1], 0, bottom[0], 0, ny + 1); System.arraycopy(Ez[nx], 0, bottom[1], 0, ny + 1);
ここで、メインの計算、つまりフィールドの次のステップに進みます。 Maxwellの方程式の特徴は、磁場の時間変化が電気のみに依存することであり、逆もまた同様です。 これにより、簡単な差分スキームを作成できます。 初期の式は次のとおりです。
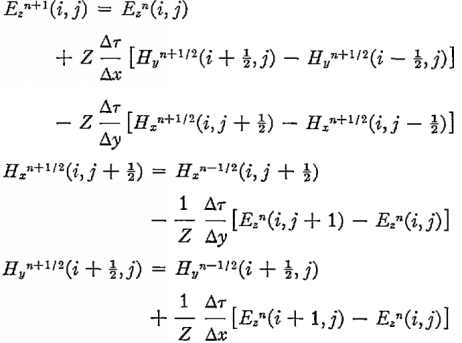
事前にすべての余分な定数を数え、寸法Hを置き換え、導入し、誘電率を考慮しました。 グリッドの元の式は0.5シフトしているため、配列EとNのインデックスと間違えないでください。長さは異なります-Eはさらに1です。
Eのエリアサイクル:
for (i = 2; i <= nx - 1; i++) { for (j = 2; j <= tt; j++) {// ? Ez[i][j] += e[i][j] * ((Hx[i][j - 1] - Hx[i][j] + Hy[i][j] - Hy[i - 1][j])); } }
そして、最後に境界条件を適用します。 差分スキームは極端なセルをカウントしないため、それらが必要です-それらのための式はありません。 何もしなければ、壁から光が反射します。 したがって、法線入射での反射を最小限に抑える方法を使用します。 上、下、右の3つの側面を処理します。 境界条件での生産性の損失は約1%です(小さいほどタスクが大きくなります)。
for (i = 1; i <= nx; i++) { Ez[i][ny] = end[0][i] + k3 * (end[1][i] - Ez[i][ny - 1]);//end } for (i = 1; i <= ny; i++) { Ez[1][i] = top[1][i] + k3 * (top[0][i] - Ez[2][i]);//verh kray Ez[nx][i] = bottom[0][i] + k3 * (bottom[1][i] - Ez[nx - 1][i]); }
境界線は左側が特別です-光線が生成されます。 前回同様。 さらに1ステップ先に進みます。
レーザー
switch (method) { case "cos": for (i = 1; i <= nx - 1; i++) { x = dx * (i - (double) nx / 2 + 0.5); Ez[i][1] = exp(-pow(x, 2) / w / w - (t - 1) * dt / tau) * cos((x * alpha + t * dt) * omega); } break; case "sin": for (i = 1; i <= nx - 1; i++) { x = dx * (i - (double) nx / 2 + 0.5); Ez[i][1] = exp(-pow(x, 2) / w / w - (t - 1) * dt / tau) * sin((x * alpha + t * dt) * omega); } break; }
磁場を計算するだけです。
for (i = 1; i <= nx - 1; i++) { // main Hx Hy for (j = 1; j <= tt; j++) { Hx[i][j] += Ez[i][j] - Ez[i][j + 1]; Hy[i][j] += Ez[i + 1][j] - Ez[i][j]; } } } // 3- .
そしてもう1つ小さなこと:フーリエ変換を計算するための最終セグメントを転送する-遠方ゾーン(方向の空間)で画像を見つける:
int pos = method.equals("cos") ? 0 : 1; // BasicEx.forFurier[pos] = new double[nx]; // int endF = (int) (ny * 0.95);// for (i = 1; i <= nx; i++) { BasicEx.forFurier[pos][i - 1] = Ez[i][endF]; for (j = 1; j <= ny; j++) { Ez[i][j] = abs(Ez[i][j]);// ABS } // , - } Hx = null; // , Hy = null; e = null; return Ez; }
次に、2つのコンポーネントの正方形を追加し、強度の図を表示します。
for (int i = 0; i < nx + 1; i++) { for (int j = 0; j < ny + 1; j++) { co.E[i][j] = co.E[i][j] * co.E[i][j] + si.E[i][j] * si.E[i][j]; } }
別に、フーリエ変換を使用します。
fft.fft(forFurier[0], forFurier[1]);
高速フーリエを理解していないため、 最初に取得したものを取得しました 。 マイナス-幅は2の累乗のみです。
パフォーマンスについて
私にとって最も興味深いのは、MatlabからJavaに切り替えることで得られたものです。 Matlabでは、できる限りすべてを最適化しました。 Javaでは、基本的に内部ループ(複雑さn ^ 3)です。 Matlabは、2つのコンポーネントを一度に考慮するという事実をすでに考慮しています。 第一段階の速度(多ければ多いほど良い):
| Matlab | 1 |
| Matlabの行列 | 3.4 / 5.1 (フロート) |
| Javaダブル | 50 |
| C ++ gcc double | 48 |
| C ++ MSVSダブル | 55 |
| C ++ gcc float | 73 |
| C ++ MSVSフロート | 79 |
UPD。 Matlabの結果を追加しました。この場合、2サイクルが行列の減算に置き換えられました。
コンテストの主な参加者について説明します。
- Matlab-2011bおよび2014。32ビットの数値に切り替えると、速度がわずかに向上します。
- Javaは最初は7u79ですが、ほとんどは8u102です。 8はわずかに優れているように見えましたが、詳細に比較しませんでした。
- Microsoft VisualStudio 2015リリース構成
- MinGW、gcc 4.9.2 32ビット、2014年12月、常にO3最適化。 3月=コアi7、AVXなし。 私はラップトップにAVXがありませんが、ゲインがありません。
試験機:
- Pentium 2020m 2.4 GHz、ddr3-1600 1チャネル
- Core i5-4670 3.6-3.8 GHz、ddr3-1600 2チャネル
- Core i7-4771 3.7-3.9 GHz、ddr3-1333 2チャネル
- Athlon x3 3.1 GHz、ddr3-1333、非常に遅いメモリコントローラー。
2コアフェーズ
最初は、TEとTMのコンポーネントを順番にカウントしました。 ちなみに、これはメモリ不足の唯一のオプションです。 それから彼は2つのスレッドを書いた-シンプルなRunnable。 それはほんの少しの進歩です。 1行よりも20〜22%だけ高速です。 彼は理由を探し始めました。 スレッドは正常に機能しました。 2つのコアが100%で安定してロードされ、ラップトップの生存が妨げられました。
次に、パフォーマンスを把握しました。 RAMの速度に依存していることが判明しました。 コードはすでに読み取りの制限で機能していました。 私はフロートに切り替える必要がありました。 精度の検査により、致命的なエラーがないことが示されました。 視覚的な違いはまったくありません。 合計エネルギーは8桁異なりました。 積分変換後、スペクトルの最大値は0.7e-6です。 おそらく事実は、Javaがすべてを64ビット精度で考慮し、それから32に変換することです。
しかし、最も重要なのは、パフォーマンスが急上昇したことです。 2つのコアの全体的な効果とフロートへの移行+ 87〜102%。 (メモリが高速でコアが多いほど、ゲインが向上します)。 Athlon x3は少し増加しました。
C ++での実装は似ています-std ::スレッドを使用(最後を参照)。
現在の速度(2スレッド):
| Javaダブル | 61 |
| Javaフロート | 64-101 |
| C ++ gcc float | 87-110 |
| C ++ gcc 6.2 64ネイティブ | 99-122 |
| ビジュアルスタジオ | 112-149 |
(新しいコンパイラーは、16384のJavaと比較して非常に高いパフォーマンスを提供します。JavaとGCC-4.9 32は同時に失敗します)。
すべての見積もりは、1回の計算で実行されました。 なぜなら、プログラムを閉じずにGUIから再実行すると、さらに速度が上がるからです。 私見、jit-optimizationドライブ。
4コアフェーズ
まだ加速の余地があるように思えました。 4行バージョンについて設定しました。 一番下の行は、領域が半分に分割され、最初にE、次にNの2つのストリームにカウントされることです。
最初にRunnableに書きました。 それはひどく判明しました-加速はエリアの非常に広い幅のためだけでした。 新しいスレッドを生成するにはコストがかかりすぎます。 その後、彼はjava.util.concurrentを習得しました。 これで、タスクが割り当てられたスレッドの固定プールができました。
public static ExecutorService service = Executors.newFixedThreadPool(4); //…… cdl = new CountDownLatch(2); NewThreadE first = new NewThreadE(Ez, Hx, Hy, e, 2, nx / 2, tt, cdl); NewThreadE second = new NewThreadE(Ez, Hx, Hy, e, nx / 2 + 1, nx - 1, tt, cdl); service.execute(first); service.execute(second); try { cdl.await(); } catch (InterruptedException ex) { }
Hの場合:
cdl = new CountDownLatch(2); NewThreadH firstH = new NewThreadH(Ez, Hx, Hy, 1, nx / 2, tt, cdl); NewThreadH secondH = new NewThreadH(Ez, Hx, Hy, nx/2+1, nx-1, tt, cdl); service.execute(firstH); service.execute(secondH); try { cdl.await(); } catch (InterruptedException ex) { }
ストリーム内で半サイクルが実行されます。
クラスNewThreadE
public class NewThreadE implements Runnable { float[][] Ez; float[][] Hx; float[][] Hy; float[][] e; int iBegin; int iEnd; float tt; CountDownLatch cdl; public NewThreadE(float[][] E, float[][] H, float[][] H2, float[][] eps, int iBegi, int iEn, float ttt, CountDownLatch cdl) { this.cdl = cdl; Ez = E; Hx = H; Hy = H2; e = eps; iBegin = iBegi; iEnd = iEn; tt = ttt; } @Override public void run() { for (int i = iBegin; i <= iEnd; i++) { // main Ez for (int j = 2; j <= tt; j++) { Ez[i][j] += e[i][j] * ((Hx[i][j - 1] - Hx[i][j] + Hy[i][j] - Hy[i - 1][j])); } } cdl.countDown(); } }
Hの同様のクラスは、異なる境界と独自のサイクルです。
現在、常に4スレッドの増加があります-23から49%(.jar)。 幅が小さいほど良い-速度から判断すると、キャッシュメモリに入ります。 最大の利点は、長くて狭いタスクを数えることです。
| Java float 4スレッド | 86–151 |
| C ++ gcc float 4ストリーム | 122–162(128に近い) |
| C ++ gcc 6.2 64ネイティブ | 124–173 |
| ビジュアルスタジオ | 139–183 |
これまでのC ++の実装には、単純なstd ::スレッドのみが含まれています。 したがって、彼女にとっては、幅が広いほど良い。 16384で1024から47%の幅で5%のC ++アクセラレーション。
UPD。 GCC 6.2-64およびVisualStudioの結果を追加しました。 VSは古いGCCよりも13〜43%高速で、新しいGCCよりも3〜11%高速です。 64ビットコンパイラの主な機能は、幅広いタスクでの作業の高速化です。 また、Javaは小さなタスク(キャッシュ)に対してより並列化されており、C ++は幅広いタスクに対して-Visual StudioはJavaよりも61%高速です。
ご覧のとおり、最良の場合、Javaのゲインは49%です(ほぼ3コアのように)。 したがって、面白い事実があります-小さなタスクの場合、newFixedThreadPool(3)を設定するのが最善です。
大規模な場合-プロセッサのスレッド数-4または6-8。 別の面白い事実を指摘します。 Athlone x3では、フロートおよび2スレッドへの切り替えからの進捗はほとんどありませんでした-両方の最適化の32%。 C ++の「4」ノードコードからのゲインも小さく、1〜4カーネルで67%(両方ともfloat)です。 遅いメモリコントローラーと32ビットWindowsに書き戻すことができます。
しかし、4コアのJavaコードは問題なく機能しました。 3つのエグゼキュータースレッド+大規模タスク用の2コアバージョンの50.2%。 何らかの理由で、最悪の2コア実装は、可能な限り最高のマルチコア実装によって増幅されました。
Javaの4コアコードに関する最後のメモ。 現在の時間:
| 基本的な2次元サイクルEおよびH | 83% |
| その他、すべての初期初期化を考慮 | 16% |
| スポーン(4)スレッド | 約1%(プロファイラーで0.86) |
残りはほとんど時間を無駄にしないと考えて、メインサイクルを可能な限り最適化しようとしました。
また、C ++の4コアケースの完全なコードを投稿します。
.cpp
まだ[]を削除します。結果をどこかで使用する必要があるためです:)
#include <iostream> #include <complex> #include <stdio.h> #include <sys/time.h> #include <thread> using namespace std; void thE (float** &Ez, float** &Hx, float** &Hy, float** &e, int iBegin, int iEnd, int tt) { for (int i = iBegin; i <= iEnd; i++) // main Ez { for (int j = 2; j <= tt; j++) { Ez[i][j] += e[i][j] * ((Hx[i][j - 1] - Hx[i][j] + Hy[i][j] - Hy[i - 1][j])); } } } void thH (float** &Ez, float** &Hx, float** &Hy, int iBegin, int iEnd, int tt) { for (int i = iBegin; i <= iEnd; i++) { for (int j = 1; j <= tt; j++) { Hx[i][j] += Ez[i][j] - Ez[i][j + 1]; Hy[i][j] += Ez[i + 1][j] - Ez[i][j]; } } } void FDTDmainFunction (char m) { //m=c: cos, else sin int i,j; float x; const float dx=0.5*1e-7/1.4; const float dy=dx; const float period=1.2e-6; const float Q=1.5; const float n=1;//ne =1 const float lambd=1064e-9; const float prodol=2*n*period*period/lambd/Q; const int nx=1024; const int ny=700; float **Ez = new float *[nx+1]; for (i = 0; i < nx+1; i++) { Ez[i] = new float [ny+1]; for (j=0; j<ny+1; j++) { Ez[i][j]=0; } } float **Hx = new float *[nx]; for (i = 0; i < nx; i++) { Hx[i] = new float [ny]; for (j=0; j<ny; j++) { Hx[i][j]=0; } } float **Hy = new float *[nx]; for (i = 0; i < nx; i++) { Hy[i] = new float [ny]; for (j=0; j<ny; j++) { Hy[i][j]=0; } } const float omega=2*3.14159265359/lambd; const float dt=dx/2; const float s=dt/dx;//for MUR const float w=40e-7; const float alpha =tan(15.0/180*3.1416); float** e = new float *[nx+1]; for (i = 0; i < nx+1; i++) { e[i] = new float [ny+1]; for (j=0; j<ny+1; j++) { e[i][j]=dt*dt / dx/dx/1; } } const int tmax= (int) ny*1.9; for (int t=1; t<=tmax; t++) { int tt=min( (int) (t*s+10), (ny-1)); if (m == 'c') { for (i=1; i<=nx-1; i++) { x = dx*(i-(float)nx/2+0.5); Ez[i][1]=exp(-pow(x,2)/w/w)*cos((x*alpha+(t-1)*dt)*omega); } } else { for (i=1; i<=nx-1; i++) { x = dx*(i-(float)nx/2+0.5); Ez[i][1]=exp(-pow(x,2)/w/w)*sin((x*alpha+(t-1)*dt)*omega); } } std::thread thr01(thE, std::ref(Ez), std::ref(Hx), std::ref(Hy), std::ref(e), 2, nx / 2, tt); std::thread thr02(thE, std::ref(Ez), std::ref(Hx), std::ref(Hy), std::ref(e), nx / 2 + 1, nx - 1, tt); thr01.join(); thr02.join(); // H for (i=1; i<=nx-1; i++) { x = dx*(i-(float)nx/2+0.5); Ez[i][1]=exp(-pow(x,2)/w/w)*cos((x*alpha+t*dt)*omega); } std::thread thr03(thH, std::ref(Ez), std::ref(Hx), std::ref(Hy), 1, nx / 2, tt); std::thread thr04(thH, std::ref(Ez), std::ref(Hx), std::ref(Hy), nx / 2 + 1, nx - 1, tt); thr03.join(); thr04.join(); } } int main() { struct timeval tp; gettimeofday(&tp, NULL); double ms = tp.tv_sec * 1000 + (double)tp.tv_usec / 1000; std::thread thr1(FDTDmainFunction, 'c'); std::thread thr2(FDTDmainFunction, 's'); thr1.join(); thr2.join(); gettimeofday(&tp, NULL); double ms2 = tp.tv_sec * 1000 + (double)tp.tv_usec / 1000; cout << ms2-ms << endl; return 0; }
まだ[]を削除します。結果をどこかで使用する必要があるためです:)
これは最も単純なコードで、通常のラティスと境界条件はありません。 C ++では、2次元配列を宣言してスレッドを呼び出す方が効率的ですか?
8コア
そして、コアはもうありません。 タスクがメモリ上にない場合、さらに分割します。 ThreadPoolは低コストを提供するようです。 または、Fork-Join Frameworkに切り替えます。
私はチェックすることができました-最初の2つのスレッドを放棄し、1つのタスクをi7で4〜8個に分割します。 しかし、DDR-4または4チャネルの高速メモリを搭載したマシンでテストしている場合にのみ意味があります。
メモリ速度の不足を取り除く最良の方法は、ビデオカードを使用することです。 Cudaへの切り替えは、ビデオドライバーの更新を禁止している兄によって禁止されています(CとCudaを無視)。
まとめとあとがき
必要な2次元の問題を正確にすばやく解決できます。 4096x2000グリッドは、106秒で4コアで渡されます。 300ミクロンx 40層になります-最大サンプル数です。
2Dでは、32ビット精度で、わずかなメモリが必要です-最悪の場合、4バイト* 4配列* 2複雑なコンポーネント= 32バイト/ピクセル。
3Dでは、すべてがさらに悪化しています。 コンポーネントはすでに6です。 2つのストリームを拒否できます。コンポーネントを順番に読み取り、ネジに書き込みます。 誘電率の配列を保存することはできませんが、1サイクルで検討するか、非常に小さな周期セクションに沿って調整してください。 次に、16 GBのRAM(私の作業では最大)が895x895x895の領域に収まります。 「見る」のは普通です。 ただし、1回のパスで6〜7時間のみと見なされます。 タスクが4つの並列スレッドにうまく分割されている場合。 そして、εの計算を無視した場合。
スペクトルだけでは十分ではありません。 幅が1024の場合、必要な詳細が表示されません。 2048が必要です。これは200 GB以上のメモリです。 したがって、3次元の場合は困難です。 キャッシュSSDを使用してコードを開発しない場合。
PS Speedの見積もりはかなり荒いものでした。 Matlabは小さなタスクでのみチェックしました。 次に、4コアでタスク2048 * 1976(アナログ2000 * 2000)のJavaをチェックしました。 計算時間45.5秒。 Matlabからの加速141回 (確かに)。
可能な将来の計画:
*)純粋なC(++ではない)の速度を確認します。 ベンチマークゲームによると、常に高速です。
1)CおよびJavaの複雑なクラスを確認します。 たぶんCでは十分に早く実装されます。 確かに、それらはすべて8バイト以上になると思います。
2)MSVSですべての2コアバージョンと4コアバージョンをドロップし、最適化設定を見つけます。
3)ラムダ/ストリームがメインサイクルまたは追加のサイクルを高速化できるかどうかを確認します。
4)通常のGUIを作成してすべてを選択し、結果を視覚化します。
99)Cudaバージョンを書きます。
興味のある方は、FDTDやその他の計算方法、フォトニック結晶について説明します。
Githubに2つのバージョンを投稿しました。
1)パラメーター選択インターフェースの基本的な2行
2) 4行
どちらも絵とスペクトルを描きます。 ピクセル単位で-2048を超える幅は使用しないでください。コンソールから領域のサイズを取得する方法も知っています。