機械学習におけるニューラルネットワークのブームにもかかわらず、線形分類アルゴリズムの使用と解釈はずっと簡単です。 しかし同時に、サポートベクターメソッドやロジスティック回帰などの高度なメソッドを使用したくない場合もあります。また、すべてのデータを1つの大きな線形最小二乗回帰に入れたいという誘惑があります。さらに、MS Excelでも完全に構築できます。
このアプローチの問題は、入力データが線形に分離可能である場合でも、結果の分類器がそれらを分離しない可能性があることです。 たとえば、ポイントのセットの場合
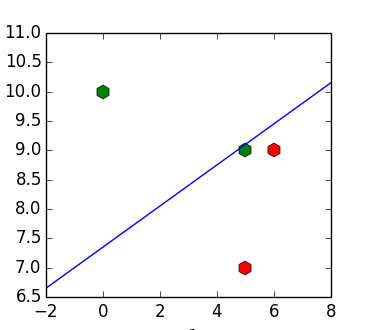
疑問が生じます-何らかの形でこの行動の特徴を取り除くことは可能ですか?
線形分類問題
まず、記事の主題を形式化します。
ダナ行列
>>> import numpy as np >>> X = np.array([[6, 9, 1], [5, 7, 1], [5, 9, 1], [0, 10, 1]]) >>> y = np.array([[1], [1], [-1], [-1]])
これを行う最も簡単な方法は、OLS回帰を構築することです
>>> w = np.dot(np.linalg.pinv(X), y) >>> w array([[ 0.15328467], [-0.4379562 ], [ 3.2189781 ]]) >>> np.dot(X, w) array([[ 0.19708029], [ 0.91970803], [ 0.04379562], [-1.16058394]])
線形分離可能性
記述の便宜上、各不等式を要素ごとに乗算します
>>> Y = y * X >>> Y array([[ 6, 9, 1], [ 5, 7, 1], [ -5, -9, -1], [ 0, -10, -1]])
この時点で、クラスの分離の条件は
ベクターを導入
>>> b = np.ones([4, 1]) >>> b[3] = 10 >>> w = np.dot(np.linalg.pinv(Y), b) >>> np.dot(Y, w) array([[ 0.8540146 ], [ 0.98540146], [ 0.81021898], [ 10.02919708]])
Ho Kashyapアルゴリズム
Ho Kashyapアルゴリズムは、
- OLS回帰係数を計算します(
)
- インデントベクトルを計算する
。
- 決定が同意しない場合(
)、ステップ1を繰り返します。
何らかの方法で計算したいインデントベクトル
>>> e = -np.inf * np.ones([4, 1]) >>> b = np.ones([4, 1]) >>> while np.any(e < 0): ... w = np.dot(np.linalg.pinv(Y), b) ... e = b - np.dot(Y, w) ... b = b - e * (e < 0) ... >>> b array([[ 1.], [ 1.], [ 1.], [ 12.]]) >>> w array([[ 2.], [-1.], [-2.]])
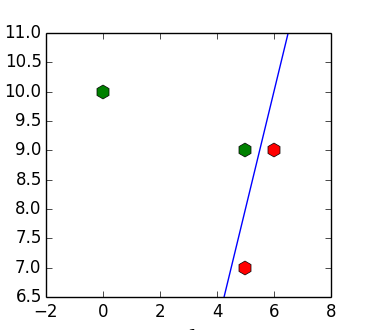
線形に分離可能なサンプルの場合、アルゴリズムは常に分離平面に収束し、収束します(すべての勾配要素が
線形に分離できないサンプルの場合、損失関数は任意に小さくできます。
Ho-Kashyapアルゴリズムと線形SVMの接続
オブジェクトが正しく分類されていれば、提起された最適化問題のエラー(
また、線形SVM損失関数の形式は次のとおりです。
したがって、Ho-Kashyapアルゴリズムによって解決される問題は、2次損失関数(分離平面から遠く離れた放射に対してより細かく罰金を科す)と分離ストリップの幅を無視する(つまり、最も近い場所から可能な限り離れた非平面を探す)正しく分類された要素、および任意の分割面)。
多次元の場合
MNC回帰は、 フィッシャーの 2クラス線形判別式の類似物であることを思い出してください(それらの解は定数まで一致します)。 Ho-Kashpyapアルゴリズムはケースにも適用できます
謝辞
便利なエディターのparpalak 。
オリジナル記事のrocket3 。
参照資料
(1) http://www.csd.uwo.ca/~olga/Courses/CS434a_541a/Lecture10.pdf
(2) http://research.cs.tamu.edu/prism/lectures/pr/pr_l17.pdf
(3) http://web.khu.ac.kr/~tskim/PatternClass Lec Note 07-1.pdf
(4)A.E. レプスキー、A.G。 Bronevich パターン認識のための数学的方法。 講座
(5)Tu J.、ゴンザレスR. パターン認識の原理
(6)R. Duda、P。Hart パターン認識およびシーン分析