ユニコードを実際に扱うには、少なくとも標準で作業できるすべての書記体系の機能を表面的に理解する必要があります。 しかし、これはすべての開発者が必要とするものですか? ノーと言います。 ほとんどの日常的なタスクでUnicodeを使用するには、合理的な最小限の情報があれば十分であり、必要に応じて標準に深く入り込みます。
この記事では、Unicodeの基本原則について説明し、開発者が日常業務で必ず遭遇する重要で実用的な問題に焦点を当てます。
なぜユニコードが必要なのですか?
Unicodeが登場する以前は、シングルバイトエンコーディングがほぼ普遍的に使用されていました。この場合、文字自体の境界、コンピュータのメモリ内の文字の表現、画面上の表示はかなりrather意的でした。 1つまたは別の各国語で作業している場合は、適切なエンコーディングフォントがシステムにインストールされているため、ユーザーにとって意味のある方法でディスクから画面にバイトを描画できます。
プリンターでテキストファイルを印刷し、紙のページに不明瞭な詐欺師のセットが表示された場合、これは対応するフォントが印刷デバイスにロードされておらず、バイトが意図したとおりに解釈されていないことを意味します。
特に、このアプローチ全体およびシングルバイトエンコーディングには、多くの重大な欠点がありました。
- 一度に操作できるのは256文字だけでした。最初の128文字はラテン文字と制御文字用に予約されていました。後半では、国のアルファベットに加えて、擬似グラフィック文字(╔╗)の場所を見つける必要がありました。
- フォントは特定のエンコーディングに関連付けられていました。
- 各エンコードは独自の文字セットを表し、欠落した文字がグラフィカルに類似した文字に置き換えられた場合、部分的な損失が発生した場合にのみ、別の文字セットへの変換が可能になりました。
- 異なるオペレーティングシステムを実行しているデバイス間でファイルを転送することは困難でした。 コンバータプログラムを使用するか、ファイルとともに追加のフォントを保持する必要がありました。 私たちが知っているインターネットの存在は不可能でした。
- アルファベット以外の文字体系(象形文字)が世界に存在しますが、これらは基本的にシングルバイトエンコーディングでは表現できません。
Unicodeの基礎
私たちは皆、コンピューターが理想的なエンティティーを知らないが、ビットとバイトで動作することを完全に理解しています。 しかし、コンピューターシステムはまだ機械ではなく人々によって作成されています。あなたと私にとっては、投機的な概念を操作し、抽象から具体へと移行する方が便利な場合があります。
重要! Unicode哲学の中心的な原則の1つは、シンボル、コンピューターでの表示、および出力デバイスでの表示の明確な区別です。
抽象Unicodeシンボルの概念が導入されます。これは、投機的な概念と、標準で定められた人々の間の合意という形でのみ存在します。 各Unicode文字は、そのコードポイントと呼ばれる負でない整数に関連付けられています。
そのため、たとえば、Unicode文字U + 041Fは大文字のキリル文字Pです。この文字をコンピューターのメモリで表すには、モニター画面に表示する数千の方法と同様に、いくつかの方法があります。 しかし、同時にP、アフリカでもPまたはU + 041Fになります。
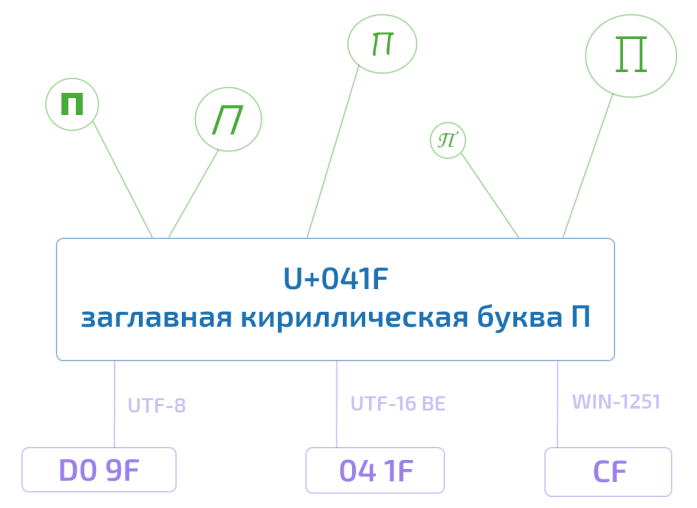
これは、インターフェースを実装から使い慣れたカプセル化または分離したもので、プログラミングで実証された概念です。
標準に従って、任意のテキストをUnicode文字のシーケンスとしてエンコードできることがわかりました
U+041F U+0440 U+0438 U+0432 U+0435 U+0442
紙に書いて封筒に入れて、地球のどこにでも送ってください。 彼らがユニコードの存在を知っていれば、テキストはあなたと私とまったく同じ方法で受け入れられます。 最後から2番目の文字が正確にキリル文字の小文字e (U + 0435)であり、ラテン語の小文字e (U + 0065)であるということを、彼らは少しも疑わないでしょう。 バイト表現については何も言わなかったことに注意してください。
Unicode文字は文字と呼ばれますが、文字、数字、句読点、象形文字など、従来の単純な意味の文字に常に対応するとは限りません。 (詳細については、スポイラーを参照してください。)
さまざまなUnicode文字の例
たとえば、純粋に技術的なUnicode文字があります。
句読点マーカーがあります。たとえば、U + 200F:書き込みの方向を右から左に変更するためのマーカーです。
さまざまな幅と目的のスペースのコホート全体があります(優れたHabrの記事を参照してください: ギャップに関するすべて(またはほとんどすべて) ):
組み合わせ可能な発音区別記号-さまざまなストローク、ドット、チルダなどがあり、前の文字とその記号の意味を変更/明確にします。 例:
言語タグ(U + E0001、U + E0020 – U + E007E、およびU + E007F)などのエキゾチックなものもあります。 テキスト表示の詳細に影響を与える可能性のある特定の言語オプション(たとえば、アメリカ英語とイギリス英語)に関連するテキストの特定のセクションをマークする機会として考えられました。
記号とは何か、書記素クラスター(読み取り:記号の単一の全体像として認識される)とUnicode記号とコードクォンタムの違いは、次回お知らせします。
- U + 0000:ヌル文字。
- U + D800 – U + DFFF:UTF-16エンコーディングファミリの10,000〜10FFFFの範囲のコード位置の技術的プレゼンテーションの上級および上級サロゲート(読み取り:BMNP / BMPの外部)。
- など
句読点マーカーがあります。たとえば、U + 200F:書き込みの方向を右から左に変更するためのマーカーです。
さまざまな幅と目的のスペースのコホート全体があります(優れたHabrの記事を参照してください: ギャップに関するすべて(またはほとんどすべて) ):
- U + 0020(スペース);
- U + 00A0(改行なしスペース、およびHTMLのnbsp;);
- U + 2002(半円形の空間またはEnスペース);
- U + 2003(ラウンドスパイまたはエムスペース);
- など
組み合わせ可能な発音区別記号-さまざまなストローク、ドット、チルダなどがあり、前の文字とその記号の意味を変更/明確にします。 例:
- U + 0300およびU + 0301:一次(急性)および二次(弱)ストレスの兆候。
- U + 0306:thのように短い(上付きの弧)。
- U + 0303:上付きチルダ;
- など
言語タグ(U + E0001、U + E0020 – U + E007E、およびU + E007F)などのエキゾチックなものもあります。 テキスト表示の詳細に影響を与える可能性のある特定の言語オプション(たとえば、アメリカ英語とイギリス英語)に関連するテキストの特定のセクションをマークする機会として考えられました。
記号とは何か、書記素クラスター(読み取り:記号の単一の全体像として認識される)とUnicode記号とコードクォンタムの違いは、次回お知らせします。
Unicodeコードスペース
Unicodeコードスペースは、0〜10FFFFの範囲の1,114,112コード位置で構成されます。 そのうち、128,237のみが標準の9番目のバージョンに値が割り当てられ、スペースの一部は私的使用のために予約されており、Unicodeコンソーシアムはこれらの特別な領域の位置に値を割り当てないことを約束します。
便宜上、スペース全体が17個のプレーンに分割されています(そのうち6個が現在使用されています)。 最近まで、U + 0000からU + FFFFまでのUnicode文字を含む基本的な多言語プレーン(Basic Multilingual Plane、BMP)のみを扱う必要があると言うのが慣習でした。 (少し先を見ます:BMPの文字はUTF-16では4バイトではなく2バイトで表されます)。 2016年には、この論文はすでに疑問視されています。 たとえば、人気の絵文字はユーザーメッセージに表示される場合があり、それらを正しく処理できる必要があります。
エンコーディング
インターネット経由でテキストを送信する場合は、一連のUnicode文字を一連のバイトとしてエンコードする必要があります。
Unicode標準には、UTF-8やUTF-16BE / UTF-16LEなどの多くのUnicodeエンコーディングの説明が含まれており、コード位置のスペース全体をエンコードできます。 これらのエンコーディング間の変換は、情報を失うことなく自由に実行できます。
また、シングルバイトエンコーディングをキャンセルした人はいませんでしたが、個々の非常に狭いUnicodeスペクトル(256以下のコード位置)をエンコードできます。 このようなエンコーディングの場合、テーブルが存在し、すべてのコーナーからアクセスできます。単一バイトの各値はUnicode文字に関連付けられています(たとえば、 CP1251.TXTを参照)。 制限はありますが、単一バイトのエンコーディングは、単一言語のテキスト情報の大規模な配列を扱う場合に非常に実用的であることがわかりました。
Unicodeエンコーディングのうち、インターネットで最も一般的なのはUTF-8(2008年に掌握)です。これは主に、費用対効果と7ビットASCIIとの透過的な互換性のためです。 ラテン文字とサービス文字、基本的な句読点と数字-つまり 7ビットASCII文字はすべて、ASCIIと同様に1バイトのUTF-8でエンコードされます。 いくつかのよりまれな象形文字を除き、多くの基本的なスクリプトのシンボルは、2バイトまたは3バイトで表されます。 最大の標準コード位置-10FFFF-は4バイトでエンコードされます。
UTF-8は可変長エンコーディングであることに注意してください。 その中の各Unicode文字は、最小長が1クォンタムのコードクォンタムのシーケンスで表されます。 数字の8は、コード単位のビット長-8ビットを意味します。 UTF-16エンコーディングファミリの場合、コードクォンタムサイズはそれぞれ16ビットです。 UTF-32の場合、32ビット。
キリル文字を含むHTMLページをネットワーク経由で送信する場合、UTF-8は非常に明確なメリットをもたらすことができます。 すべてのマークアップ、およびJavaScriptブロックとCSSブロックは、1バイトで効果的にエンコードされます。 たとえば、UTF-8のHabrのメインページは139Kbであり、UTF-16では既に256Kbです。 比較のために、一部の文字を保存する機能が失われたwin-1251を使用する場合、UTF-8と比較してサイズは11Kbから128Kbだけ縮小されます。
文字列情報をアプリケーションに保存するために、16ビットUnicodeエンコードが使用されることがよくあります。これは、そのシンプルさと、主要な世界の書記体系の文字が1つの16ビットクォンタムでエンコードされるためです。 したがって、たとえば、Javaは文字列の内部表現にUTF-16を正常に使用します。 Windowsオペレーティングシステム自体も、UTF-16を使用します。
いずれにせよ、Unicode空間にとどまっている間は、文字列情報が別のアプリケーションに保存される方法はそれほど重要ではありません。 ファイルからの読み取りやクリップボードへのコピーなど、アプリケーションの境界にあるすべての数百万以上のコード位置を内部ストレージ形式で正しくエンコードできる場合、情報の損失はなく、すべて問題ありません。
ディスクまたはネットワークソケットから読み取られたテキストを正しく解釈するには、まずそのエンコーディングを決定する必要があります。 これは、ユーザーが提供するメタ情報を使用して、テキスト内またはテキストの横に記録されるか、ヒューリスティックに決定されます。
乾燥残留物中
たくさんの情報があり、上記で書かれたすべての簡単な絞り込みをすることは理にかなっています:
- Unicodeは、文字、コンピューター上での文字の表現、および出力デバイスでの文字間の明確な区別を前提としています。
- Unicode文字は、文字、数字、句読点、象形文字など、従来の単純な意味の文字に常に対応するわけではありません。
- Unicodeコードスペースは、0〜10FFFFの範囲の1,114,112コード位置で構成されます。
- 基本的な多言語プレーンには、UTF-16で2バイトでエンコードされたU + 0000からU + FFFFまでのUnicode文字が含まれています。
- Unicodeエンコードを使用すると、Unicodeコード位置のスペース全体をエンコードでき、さまざまなエンコード間の変換は情報を失うことなく実行されます。
- シングルバイトエンコーディングを使用すると、Unicodeスペクトルのごく一部のみをエンコードできますが、大量の単一言語情報を扱う場合に役立ちます。
- UTF-8およびUTF-16エンコーディングのコード長は可変です。 UTF-8では、各Unicode文字を1、2、3、または4バイトでエンコードできます。 UTF-16では、2バイトまたは4バイト。
- テキスト情報を別のアプリケーションに保存するための内部形式は、Unicodeコード位置のスペース全体で正しく動作し、国境を越えたデータ転送中に損失がない限り、任意に設定できます。
コーディングに関する簡単なメモ
エンコーディングという用語と混同される場合があります。 Unicode内では、エンコードは2回行われます。 各Unicode文字にコード位置が割り当てられるという意味で、Unicode文字セットが初めてエンコードされるとき。 このプロセスの一環として、Unicode文字セットはコード化文字セットに変換されます。 2回目は、Unicode文字のシーケンスがバイト文字列に変換され、このプロセスはエンコードとも呼ばれます。
英語の用語では、コーディングとエンコードの2つの動詞がありますが、ネイティブスピーカーでさえ混乱することがよくあります。 さらに、用語文字セットまたは文字セットは、用語コード化文字セットの同義語として使用されます。
これらすべては、コンテキストに注意を払い、抽象Unicodeシンボルのコード位置とそのバイト表現の状況を区別することが理にかなっていると言います。
結論として
Unicodeにはさまざまな側面があり、1つの記事ですべてを網羅することは不可能です。 はい、不要です。 上記の情報は、基本原則を混同せず、ほとんどの日常的なタスクでテキストを操作するのに十分です(BMPを超えないでください)。 次の記事では、正規化について説明し、エンコードの開発のより完全な歴史的概要を説明し、ロシア語のUnicode用語の問題について説明し、UTF-8およびUTF-16を使用する実用的な側面について資料を作成します。