ソートアルゴリズム
この記事では、C ++で実装されたいくつかのソートアルゴリズムを比較して、大きなアンパックBCD番号のシーケンスに焦点を当てます。
この分析は、 Software Technologiesの夏のプラクティスとして実施しました。
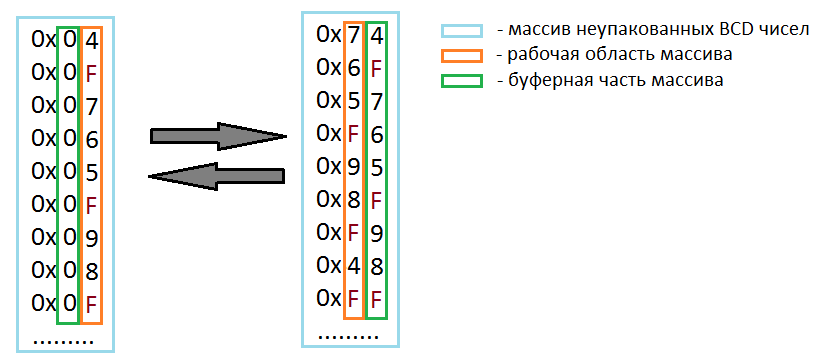
ソートされたシーケンスにはヘッダーがありません。その中の数字の長さは異なり、アライメントなしで保存されます。 数字の間には区切り文字があります(0xFF)。
ライブラリ関数を使用して並べ替えを実行するために、追加のデータレイヤーが導入されます。これには、それぞれ1つのBCD番号が含まれるメモリ領域へのポインターを含むコンテナがあります。 関係する比較:
1.ソートのマージ。
2.バッファを使用せずにソートをマージします。
3.自然なマージソート。
4.バッファーを使用しないNaturalマージソート。
5.変更された自然マージの並べ替え。
6.バッファを使用せずに変更された自然マージソート。
7. std ::ソート。
使用されるアルゴリズムのいくつかの機能
メモリバッファを追加せずにマージソートを実装すると、コンテナ内の各番号の未使用の4ビットが一時データの保存に使用されます(最初の反復では、上位4ビット、次にバッファ部分と作業部分がそれぞれスワップされます)。 バッファを使用した場合と使用しない場合のマージの実装はアップストリームです。
自然な並べ替えを実装すると、並べ替えられたセクションの境界が各反復で再び検出されます。
自然ソートの変更は、前の反復でソートされたサブシーケンスの最小サイズを記憶することです。 次の反復では、サブシーケンスを検索するときにこのサイズがスキップされ、現在のBCD番号(または番号間の境界に遷移が行われた場合は前のBCD番号)が検出され、自然なソートのようにサブシーケンスの終わりを検出する通常の手順が発生します。
テスト中
テスト中、私は「この記事」に焦点を当てました。
すべてのテストは、次の特性を持つコンピューターで実行されました。
プロセッサー-Intel Core 2 Duo E7400、
RAM-4ギガバイト。
各変数値に対して3つの測定が実行され、3つの測定すべての算術平均がグラフに表示されました。
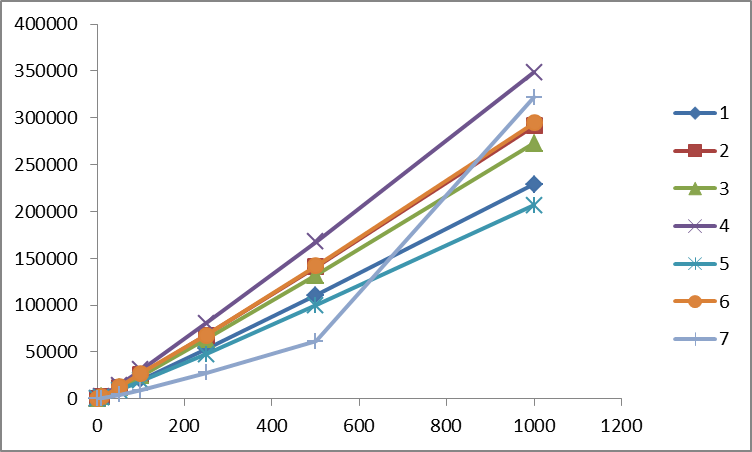
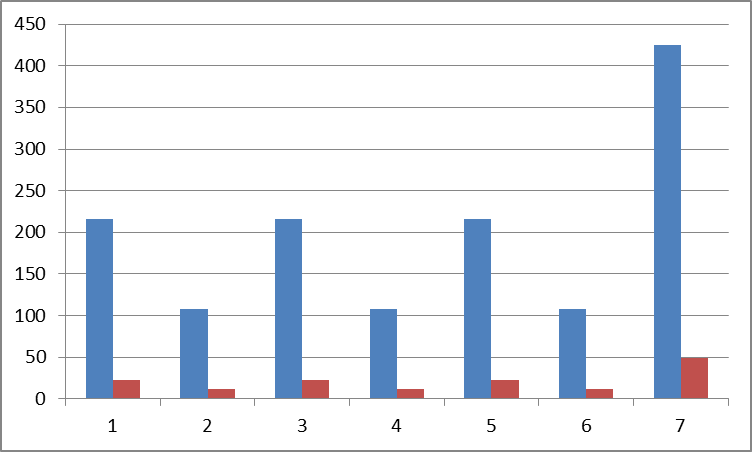
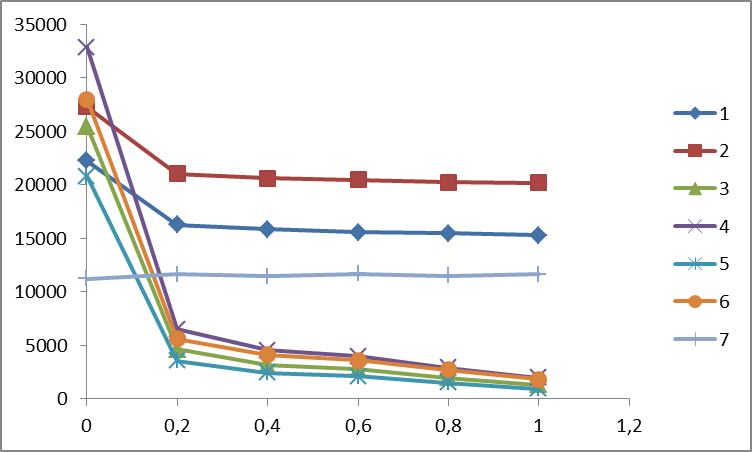
各測定で、すべてのソートへの入力に同等のデータが提供されました。 時間はミリ秒 (横)、メモリはメガバイト (下)で示されます 。 並べ替えはシリアル番号の下で行われます。
シーケンス内の数値を超えない値による数値の場合、1〜1000 MBのBCD数値の処理速度。

MAX_INT(このシステムでは2の32乗)を超えない値による数値の場合、1〜1000 MBのBCD数値の処理速度。
10および100 MBのBCD番号をソートするためのメモリ消費。
さまざまなソートの100MB BCD番号を含むコンテナの処理速度。
非表示のテキスト
ソートは次のように定義されます
ソート済み=カウント/カウント
ここで、countはシーケンス内の連続した数字のペアの総数であり、countはペアの最初の数字が2番目の数字より小さいことが確実にわかっているペアの数です。
したがって、ソートの基準は[0、1]の間隔にあります。さらに、sortedness = 0の場合、完全にランダムなシーケンスを取得します。sortnessness= 1の場合、完全にソートされたシーケンスを取得します。
ソート済み=カウント/カウント
ここで、countはシーケンス内の連続した数字のペアの総数であり、countはペアの最初の数字が2番目の数字より小さいことが確実にわかっているペアの数です。
したがって、ソートの基準は[0、1]の間隔にあります。さらに、sortedness = 0の場合、完全にランダムなシーケンスを取得します。sortnessness= 1の場合、完全にソートされたシーケンスを取得します。
さまざまな容量の100MB BCD番号を含むコンテナの処理速度。
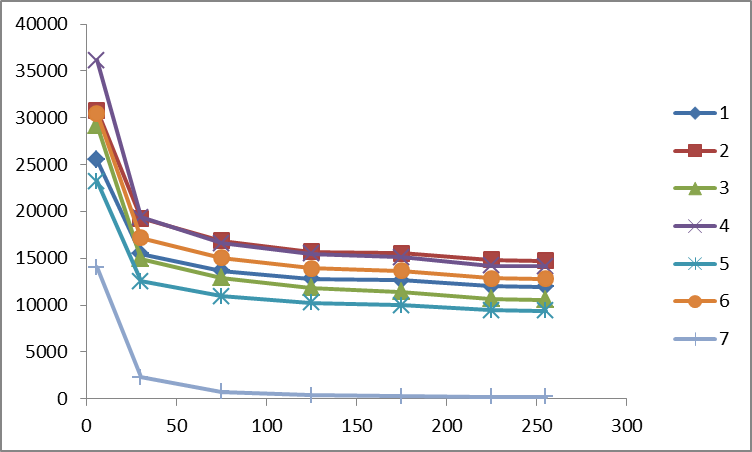
100 MBのBCD番号の異なるコンピューターの時間差を並べ替えます。
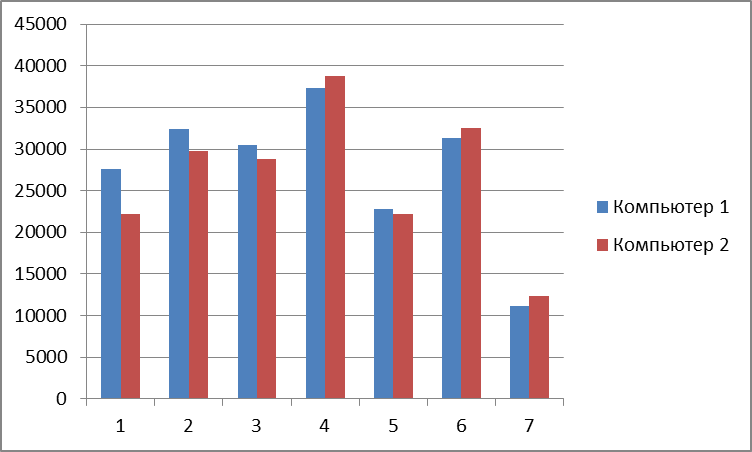
コンピューターの機能1:
-プロセッサー-Intel Core 2 Duo E7400、
-RAM-4ギガバイト。
コンピューターの機能2:
-プロセッサー-AMD A10-7300、
-RAM-4ギガバイト。
おわりに
実行されたテストに基づいて、ライブラリの並べ替えは中小規模のデータを2倍の速度で処理しますが、同時により多くのメモリを消費するため、RAMボリュームに匹敵するデータボリュームのパフォーマンスの低下を示し始めていると言えます。
追加のバッファーを使用しないソートは、対応するバッファーよりも平均して長く動作し、追加のバッファーを25%使用します。
自然なソートは、従来のマージソートよりも速度が15%劣りますが、その変更によりこのギャップが解消されます。