完璧ではありませんが、私にとっては-非常にクールです。 リアルタイムで再生される3Dシューティングゲーム-これが初めてです。
適用されたアプローチは、GOでのボットの作り方とアタリのゲームのやり方の両方と交差しています。 本質的に、これは「深層強化学習」です。 このトピックに関するロシア語での最も詳細な記事、おそらくこちら 。
一言で言えば。 関数Q(s、a)があるとします。 この関数は、状態sでアクションaを実行することによりシステムが返す利益を決定します。 ニューラルネットワークは、出力で関数Qの近似値が得られるようにトレーニングされます。その結果、各状況でのアクションの価格がわかります。 より詳細に理解するには、上記のテキストのいずれかを読むことをお勧めします。
3DシューティングゲームのAtariゲームで使用されている従来のアプローチは機能しません。 情報が多すぎる、不確実性が多すぎる。 Atariゲームでは、3〜4フレームのシーケンスに従って最適なアクションを実行できます。これは、そこで広く使用されており、入力に供給されます。 Alpha Goでは、著者は追加のシステムを使用して、Goのルールに従って最適なオプションを選別しました。
ここで著者はどのようにそれを処理しましたか? 結局のところ、内部エンジンを介して実行されませんか? すべてが非常にシンプルで興味深いことがわかりました。 グローバルに、3つの改善が行われました。
- トレーニング中に、エンジンからいくつかの追加情報が使用されました
- CNN出力で使用されるLSTM
- 2つのネットワークがトレーニングされました:「研究」と「戦闘」
今、もう少し詳細。
エンジンからの情報
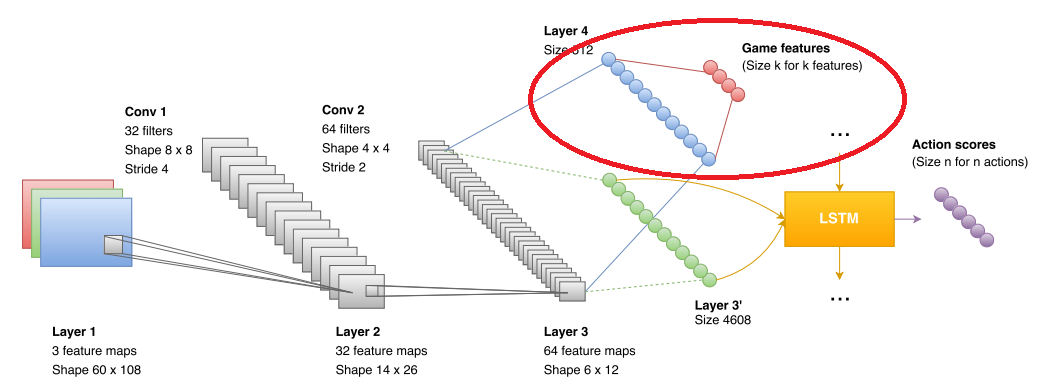
人が最初にDOOMに座ったとき、彼らは彼に言います:これは悪いモンスターです、彼は殺される必要があります。 人はモンスターが何であるかを理解している=>彼はすぐに習得した。 ニューラルネットワークはモンスターを見たことがない。 私は救急キットを見たことも、樽を見たこともありませんでした。 彼女は、あるものを他のものと区別する方法を知りません。
強化されたディープラーニングは、システムがそのターゲット機能によってのみ学習することを意味します。 しかし、しばしばこれは不可能です。 動いているピクセルの配列が敵であることを目的関数で理解することは不可能です。 まあ、できますが、長くて退屈です。 人は先験的な情報を持っています。 ネットワークにアップロードする必要があります。
したがって、著者はトレーニングで使用される追加のブロックを導入しました。 ネットワークが見るものをブロックに送信します(図では、赤い楕円でマークされています)。 データ形式は、「モンスターを見る」、「応急処置キットを見る」、「弾薬を見る」というスタイルのブール値です。 その結果、畳み込みネットワークは、敵、救急キット、および弾薬を認識するためのトレーニングを明確にしています。 ゲームフェーズでは、このブロックは使用されません。 より正確に使用されますが、以下でさらに詳しく説明します。 ただし、ネットワークの精度を高める機能の数は次のとおりです。
Lstm
LSTMは、畳み込みネットワークが受信するデータをうまく組み合わせることができるようなリカレントネットワークです。 AtariとAlpha GOの元の記事では、そのようなネットワークはありませんでしたが、それらは既に他のDQRプロジェクトで使用されていました(たとえば、同じAtariゲームで)。 したがって、ここでは特に新しいものはありませんでした。
2つのネットワーク
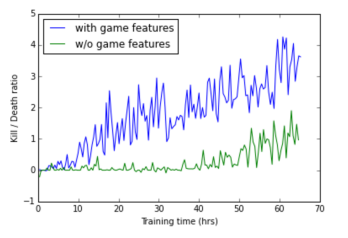
そして再び、著者たちは不快な瞬間に出くわしました。 リカレントネットワークは、数秒間どこかでデータ分析と予測を行いました(約10フレームのシーケンスでトレーニングし、1秒間に数回フレームを取得します(1/5 fps、fpsは指定されていません))。 彼女のより多くの世界的な予測は不正確でした。 さらに、ネットワークは「すぐに弾丸がなくなるので、何かを探し始めるといい」という概念を教えるのが困難です。 その結果、著者は2つの独立したネットワークを避けて作成しました。 あるネットワークは、救急キットとカートリッジを探すことができました。 2番目は、fragsを実行することです。
切り替えは、トレーニングの性質上、ネットワークが生成するまさに「モンスターの割り当て」により実行されます。 モンスターが見えない場合は、「研究ネットワーク」のソリューションが使用され、モンスターの出現後、ソリューションは「戦闘」になります。 研究ネットワークの導入の効果:
ところで、研究ネットワークは「戦闘」の特徴である「キャンピングカーの行動」でボットを殺します。
トレーニング中に、研究ネットワークに移動距離のプラスが書き出されました。
最終的に出てきたもの
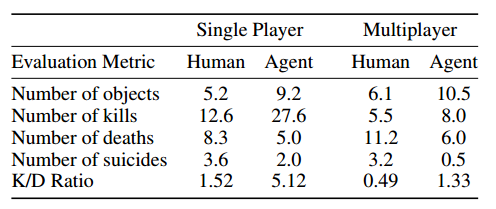
人的ネットワークは十分なマージンで勝ちます。 私の意見では、これが主なものです。
私はDQNの専門家ではありません。何かが完全に語られていないかもしれません。 専門家の意見を聞くのは面白いでしょう。 しかし、方法の選択、特に結果は、私にとって非常に印象的でした。
PS血まみれのトレーニングのいくつかの例:
* 水UHF!