
従来の信号処理手順を適用するには、加算および乗算演算が必要であるため、絶対スケールでのサンプルの表現が必要です。 しかし、信号処理に他のスケールを使用することはできますか? これについては、この記事で説明します。
事前に、著者はまともな金額を謝罪しますが、これは問題をできるだけ明確にするのに役立ちます。 また、エントロピーの推定にスケールコーディングを使用することについては、すでにここで述べました。
1.スケールの概念
従来のアナログからデジタルへの変換は、入力信号の各サンプルを、このサンプルが含まれる振幅スケールの間隔の数に関連付けます(図1)。
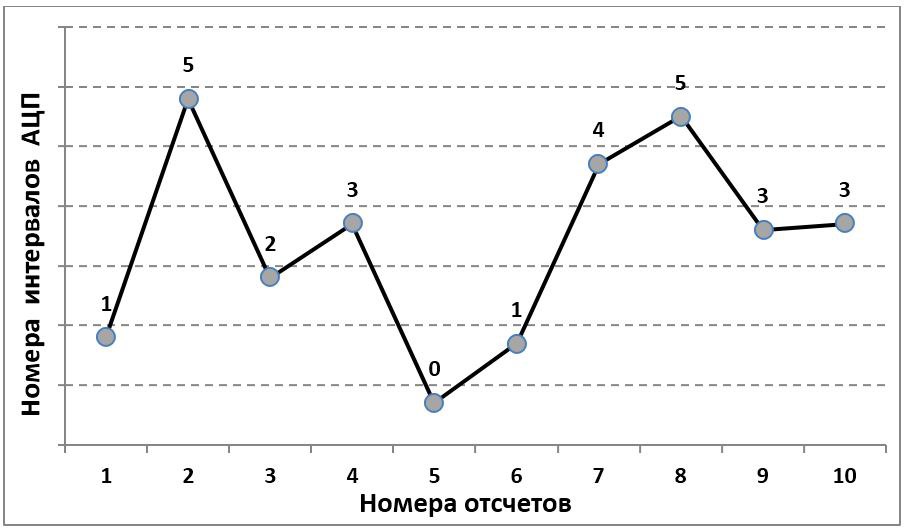
図 1.アナログからデジタルへの変換の原理
各参照のこの手順は、単一の測定と見なすことができます。 ADC間隔幅は、このような測定の最大誤差を決定します。 測定の理論(たとえば、[1]を参照)では、測定スケール(比較スケール)の概念が導入されています。 それらのいくつかに言及します。
- a)絶対スケール。 これは、標準(メートル、kgなど)との比較によって測定が行われる一般的なスケールです。 このスケールは、従来のADCに対応しています。 このスケールでの測定結果を追加および乗算できます。
- b)間隔スケール。 このスケールでは、選択された基準点と所定のスケールで測定が行われます。 例は摂氏と華氏での温度測定です。 間隔スケールでの測定結果を追加および乗算することはできません。
- c)順序スケール。 このスケールは、2つの値(より大きい、より小さい、または等しい)間の関係のみを決定しますが、一方の値が他方よりも大きいかどうかを決定することはできません。 このようなスケールの例は、参照をサンプル内のランクで置き換えることです。 算術演算はこのスケールのデータには適用できませんが、元の信号の単調変換には不変です。
2.数値時系列のクレイジースケール表現
相対スケールは、 定性データのデジタル化に自然に使用されます。 たとえば、測定された特性がセット{bad、good、very good}から値を取る場合。 しかし、ソースデータが数値である場合、相対的なスケールでそれらを表すポイントは何ですか? そして、彼らとどのように働くのですか? これらの2つの質問に対する答えを検討してください。
まず、数値データを相対スケールで表示する動機を決定します。 通常のアナログ-デジタル変換では、その原理は図に示されています。 1、入力値と出力値の比率は固定されており、時間に依存しません。 つまり、サンプル内の任意の2つのサンプルは互いに比較可能である、つまり、どちらが大きいか、どのくらいかを判断できます。 これらのステートメントは、入力の性質に関して常に正当化されていますか? 木のてっぺんのずれ角によって風速を推定するとします (たとえば、ビデオ監視カメラからの記録を処理することによって)。 2倍の偏向角は2倍の風速に対応すると主張できますか? 明らかにそうではありませんが、ここでの接続は非線形であり、そのパラメーターは正確にはわかりません。
ただし、2つの任意の時点の風速を木の傾斜角から比較し、どちらが大きいかを判断できます。 したがって、 絶対スケールはここでは冗長であり 、その使用は非効率的なコーディングにつながるだけでなく、不当な判断の根拠を作成します(これには科学があふれています)。 同時に、このデータを表すには、順序(ランク)スケールで十分です。これは、絶対よりも短いコードを生成し、信頼できる情報のみをエンコードします。
次の例を考えてみましょう。 「シンプルな鉛筆のコストは、1970年よりも今日はいくらですか?」 正式には、価格がわかっているため、質問に答えることは難しくありません。 しかし、1970年の1ルーブルと2016年の1ルーブルは(実際のコンテンツという意味で)比類のないため、この答えは意味をなしません。 したがって、1970年と比較して、今日のコストが多かれ少なかれかどうかはまったく判断できません。 ただし、1970年と2016年には、その値を他の商品の値と比較したり、同じ年の月の値を比較したりできます。 したがって、 一部の数値シリーズでは、値は特定の時間間隔内でのみ比較可能です。 そのようなシリーズの場合、時系列のすべてのサンプルの比較可能性を想定しているため、ランクコーディングは適切ではありません。 この場合、以下で説明する別のタイプの順序スケールを使用する必要があります(ローカルランクコーディング)。
ランクおよびローカルランクコーディングの手順を直接検討する前に、これらすべての検討事項の実際的な重要性についていくつか説明します。 上記からすでに明らかなように、データの性質に対応しない絶対スケールを使用すると、2つのマイナスの結果につながります。
- データ量の非効率的な増加。
- 測定値の比率に関する誤った判断の前提条件の作成。
2番目の問題に関しては、データの量がすべて明らかであるため、このような判断には、たとえば、波形のパラメーターの推定が含まれることに注意してください。 そのため、単調な変換の結果として、正弦波信号はのこぎり波に、またはその逆に変換できます。 これは、たとえばスペクトル分析手順の誤った適用につながります。
このデータはどれくらい一般的ですか? 経済では-価格とさまざまなコースに関連するほとんどすべて。 社会学および統計学では、たとえば、さまざまな期間の人口の発生率に関するデータ。 医療診断の質が変わったため、それらを比較することはできません。 統計シリーズの分析において-興味のある指標を反映するが、おそらく非線形の方法でインデックスを扱っている場合。 電子工学および無線工学では、補償されていない非線形変換と制御されていない(スプリアスなど)信号変調が発生する状況が発生します。 例は脳波の電位の測定であり、結果は原則として可変のサブ電極抵抗によって変調されるため、時間内に近い読み取り値のみを比較することができます。
特定した問題はどの程度重要ですか? 結局のところ、テクノロジーの開発に伴うデータストレージのコストは下がりつつあり、誤った判断を単純に控えることができます。 事実、今日、人類は処理できるよりもはるかに多くのデータを生成し、このギャップは拡大しています。 それを克服するために、いわゆる ビッグデータ( ビッグデータ)のシステムと技術。 データの性質に応じてスケーリングされたコーディングを使用すると、自動処理のテクノロジーの効率が大幅に向上します。 まず 、これに基づいて、入力ストリームの速度が大幅に低下します。 第二に、機械学習の手順、パターンの自動検出など。 ソースデータの重要なプロパティのみに依存して、より正確に動作します。 一般に、自動分析用のデータを準備する手順は非常に重要であり、スケールコーディングがここで役割を果たすことができます。
次に、スケーリングされたデータコーディングの特定の方法を検討します。
3.数値シリーズのランクコーディング
ランクコーディングは長い間知られており、特に仮説のノンパラメトリック検定の統計に使用されています。 図に示す信号の場合 1、対応するランクコードを図2に示します。 2.参照をそのランク、つまり昇順でソートされたサンプル内のシリアル番号で置き換えることにより取得されます。
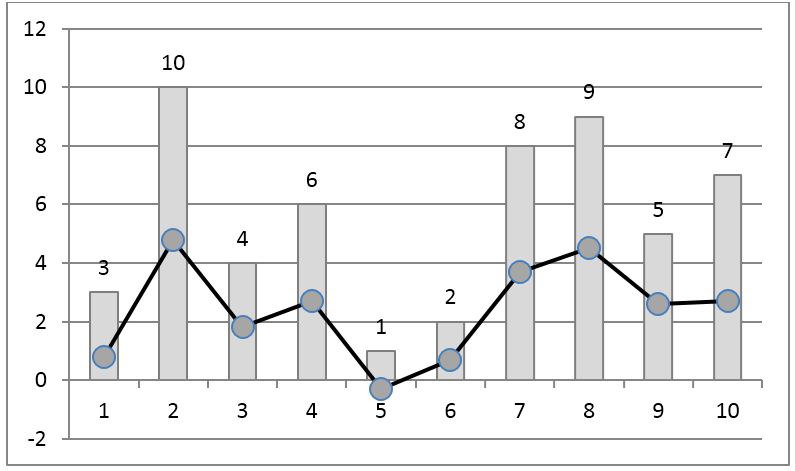
図 2.時系列のランクコーディング。 マーカーのある線は初期信号、バーはサンプルのランクです。
このコーディングの欠点は、選択に新しい要素を追加するとすべてのサンプルのランクが変わるという意味で、その非局所性です。 特に、最大サンプル値のランクは、常にサンプル内のサンプル数に等しくなります。 Pompe et al。[2]は、ランク値をサンプルの要素数で除算することを提案しました。 結果として、結果のコードは常に間隔[0,1]にあり、他のサンプルのランクに対する新しいサンプルの影響は大幅に減少します(図3)。
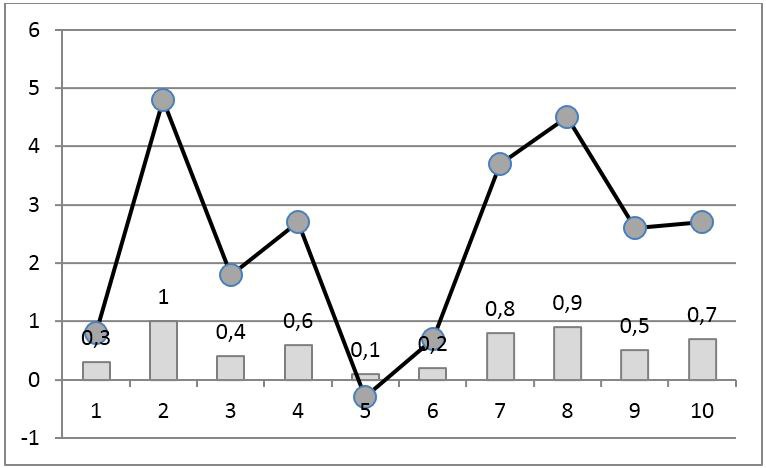
図 3. Pompeアルゴリズムなどによる時系列のコーディングのランク付け。 [2]。 マーカーのある線は初期信号、バーはサンプルのランクです。
4.数値シリーズのローカルランクコーディング
ランクコードの非局所性の問題は、ローカルランクコーディングを使用する別の方法で解決されます。 これを行うには、サンプルサンプルの比率が重要であると見なされ、保存する必要がある比較可能間隔を指定する必要があります。 比較可能間隔よりも互いに離れたサンプルの比率は、コーディング時に考慮されません。
ローカルランクコーディングのプロセスでは、元の系列のサンプル間の関係を比較可能な間隔だけ離れて繰り返す要素を持つコードが選択されます。 図の例 図3は、2つのサンプルの比較可能間隔を持つこのようなコードを示しています。 これは、各サンプルについて、左右の最も近い2つのサンプルとの関係が保存されることを意味します。
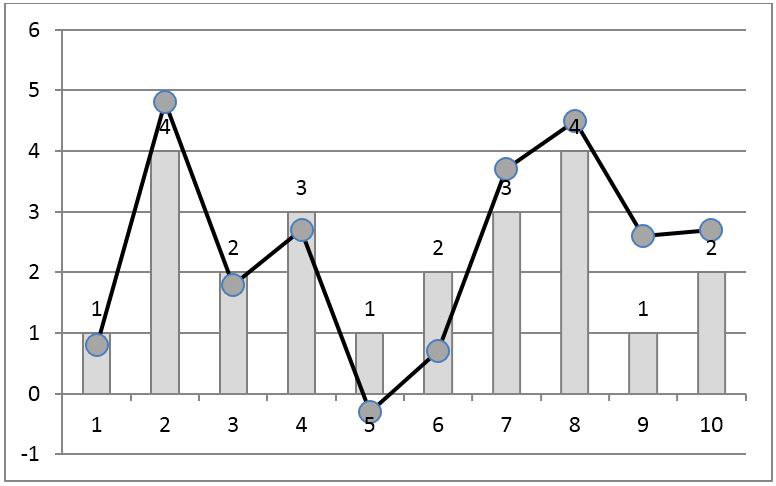
図 4.時系列のローカルランクコーディング。 マーカーのある線は初期信号、バーはサンプルのローカルランクです。
5.時系列の文字表現
カウントランク(グローバル、正規化、ローカル)は数値で表されます。 実際、ランクの加算と減算は意味をなさないため、これらは数値ではありません。 ランクは、2つのサンプル間の差の符号のみを反映し、その大きさは反映しません。 したがって、ランクは、要素が関係≤で順序付けられたセットです。 アルファベットのシンボルはシーケンス関係によって順序付けられ、それらの和と差は定義されていないため、このようなセットは常に特定のアルファベットにマッピングできます。
図 5.時系列のシンボリックローカルランクコードの例を示します。 サンプルの各サンプルの左右の2つの位置内で、シンボルシーケンスが元のシンボルシーケンスと同じ関係にあることを確認するのは簡単です。 3つ以上離れたサンプルの場合、比率は維持されません(たとえば、番号1と5のサンプル)。このようなサンプルは比較できないと見なされるためです。
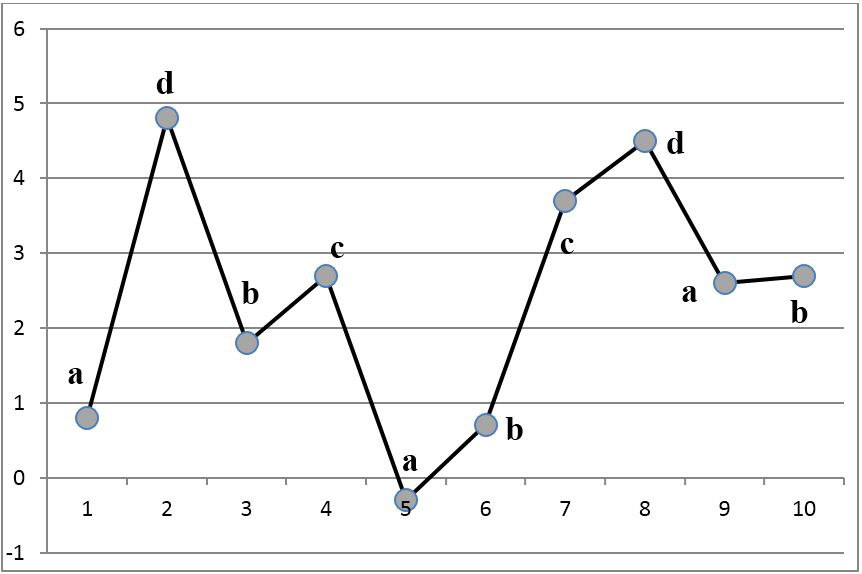
図 5.文字のローカルランクコーディング。
シンボリックローカルランクコーディングの方法は[3]で提案され、その計算のアルゴリズムは[4]で提供されます。 局所ランクコーディングの問題と、信号のエントロピーを推定するためのそのアプリケーションは、モノグラフ[5]で詳細に検討されています。
6.ランクデータの操作
既に述べたように、算術演算はランクスケールで提示されるデータには定義されていません。 ただし、これは、これらのデータに対してそのような操作が完全に禁止されていることを意味するものではなく、特定の場合には適用可能です。 たとえば、スペクトル分析を実行して、隠れた周期性を検索します。 ただし、エンコード中の波形に関する情報は失われるため、検出された最初の高調波のみを信頼できます。非線形エンコードにより、2番目以降の高調波が表示される場合があります。 ランク付けデータに相関分析を適用することもできます。
ただし、ランクデータは本質的にシンボリックであるため、次の種類の分析を完全に正しく適用することができます。
- 文字シリーズの統計分析(マルコフモデルなど);
- 正規表現を使用してパターンを検索し、これに基づいて時系列を予測します。
- 情報理論的分析(エントロピー、相互情報など)
これらのタイプのデータ分析は、信号の分析と認識、モデルの識別などの古典的なタスクに適用すると、新しい結果をもたらすこともあります。このため、データを絶対スケールで完全に表現できる場合にも、ランクスケールでの信号の表現は重要です。 特に、時系列のエントロピーを推定するときは、ランクスケールに切り替えることをお勧めします([2、3、5]を参照)。
7.少しの理論(そして間もなく終了)
ランクコードには、 連続的な1対1変換に対する不変性など、多くの興味深い特性があります。 したがって、 x(n)とe ^(x(n))のシリーズには、一致するランクコードがあります。 タイプx(n)およびe ^(x(n))の一連のエントロピー推定値は一致しなければならないため、これは、特に、時系列のエントロピーを推定する問題を解決するのに魅力的です。
しかし、スケールコーディングは、他の分野、特にビッグデータでその用途を見出すように思われます。 シンボリックシーケンスの処理は、十分に発達した知識と技術の領域であるため、数値シーケンスからシンボリックへの移行により、適用されたモデルと処理アルゴリズムの兵器庫を拡張できます。
一般的なデータおよび時系列データのスケールコーディングの理論的基礎は、特にデータ代数のどこかにあるはずです(著者はまだ質問を解決していません)。 主な考え方は、入力データの特性を考慮から除外し、測定手順の性質または特徴のためにそれらを重要でないと見なす場合、それらに対応する操作および関係が定義されたセットの要素を数値で表すことから始める必要があるということですデータに有効です。 したがって、サンプル間の差の絶対値が重要ではなく、これらの差の兆候のみを信頼できると言う場合、文字のアルファベットと同型のセットをすぐに取得します。
互いに削除されたサンプルの比較可能性の拒否は、すべての要素が比較可能ではない部分的に順序付けられたセットにつながります。 したがって、厳密に言えば、ローカルにランク付けされたコードの場合、アルファベットを選択する必要があります(アルファベットのすべての要素は比較可能であるため)が、別のタイプのセットを選択する必要があります。 これらのプロパティは、たとえば、関係≤で順序付けられた単語のセットによって所有され、Aのすべての文字が単語Bの対応する文字よりも小さい場合にのみ単語Aが単語Bよりも小さくなるように定義されます。したがって、単語cbgはただし、dhr(c <d&b <h&g <r)よりも、単語cbgとbcgは比較できません。 そのような代数的構造によるデータのコーディングの問題は、その研究者をまだ待っています。
概念的には、これはすべて情報の理論、つまりデータに含まれる情報の量を決定する問題に関するものです。 言われたことから、信号を含むデータの単純な数値表現は、特定の場合、信頼性のない関係をエンコードするため、非常に冗長であることが明らかです。 これは、明らかに、既知の統計的アルゴリズムまたはあまり知られていないアルゴリズムとは異なる新しいタイプの冗長性を表しています。 特定の制限の下で、信号内の目的の関係をエンコードできる最小のアルファベットを見つける問題を設定および解決することができます。 ローカルでランク付けされたコードの場合、この質問は[3]で部分的に検討されました。
また、ビッグデータ技術に適応した代数データと信号モデルが積極的な研究の対象となり、調査した問題だけでなく、これらの研究の機会になると想定することもできます。 したがって、この記事を終えると、信号のデジタル表現の問題は依然として関連しており、コテルニコフの定理(ステレオタイプを破るまでの時間)やデジタル信号処理の理論の他の古典的な結果の枠組みをはるかに超えています。
文学
1. Saati Thomas L.依存関係とフィードバックによる意思決定:分析ネットワーク。 あたり 英語から /科学。 編 A.V.アンドレイチコフ、O.N。アンドレイチコバ。 エド。 4番目。 -M。:レナンド、2015.360秒
2. Pompe B.非線形時系列分析におけるランキングとエントロピー推定//生理学的データの非線形分析。 スプリンガーベルリンハイデルベルク、1998年。-P. 67–90。
3. Tsvetkov OV。ランクコアを使用した振幅の変化に対して不変な生体信号のエントロピーの推定値の計算// Izv。 大学。 ラジオエレクトロニクス -1991。-第8。-S. 108–110。
4. Tsvetkov OV。ランクカーネルの比較に基づく数値シーケンスの近接度の推定// Izv。 大学。 ラジオエレクトロニクス -1992。-第8。-S. 28–33。
5.ツヴェトコフOV 物理学、生物学、技術におけるエントロピーデータ分析。 .: - «», 2015. 202 .
: ..
-: YuliyaCl
追伸 , - .