 Voximplantクラウドプラットフォームは、電話やビデオ通話だけではありません。 また、私たちは絶えず改善と拡大を続けている「バッテリー」のセットです。 最も人気のある機能の1つ:呼び出し中にJavaScriptのsayメソッドを呼び出すだけで音声を合成する機能。 独自のスピーチシンセサイザーを開発するのが最善のアイデアです。数千の同時呼び出しを処理し、それぞれにリアルタイムJavaScriptロジックを提供できる、 プラスで記述されたテレコムバックエンドに特化しています。 パートナーソリューションを使用し、業界に登場する新しいものすべてを綿密に監視します。 数年後、Iron Womanのミームから離れたいと思います:)今週の週末に私たちがそれを修正した記事で、サウンド(音波)を生成するモデルであるWaveNetについて説明します。 その中で、WaveNetがどのように人の声に似た音声を生成し、既存の音声合成システムよりもはるかに自然な音を生成し、品質を50%以上向上させる方法を見ていきます。
Voximplantクラウドプラットフォームは、電話やビデオ通話だけではありません。 また、私たちは絶えず改善と拡大を続けている「バッテリー」のセットです。 最も人気のある機能の1つ:呼び出し中にJavaScriptのsayメソッドを呼び出すだけで音声を合成する機能。 独自のスピーチシンセサイザーを開発するのが最善のアイデアです。数千の同時呼び出しを処理し、それぞれにリアルタイムJavaScriptロジックを提供できる、 プラスで記述されたテレコムバックエンドに特化しています。 パートナーソリューションを使用し、業界に登場する新しいものすべてを綿密に監視します。 数年後、Iron Womanのミームから離れたいと思います:)今週の週末に私たちがそれを修正した記事で、サウンド(音波)を生成するモデルであるWaveNetについて説明します。 その中で、WaveNetがどのように人の声に似た音声を生成し、既存の音声合成システムよりもはるかに自然な音を生成し、品質を50%以上向上させる方法を見ていきます。
また、同じネットワークを使用して、音楽を含む他のサウンドを作成し、自動生成された楽曲の例を表示できることも示します(ピアノ)。
しゃべる車
人と機械が音声で通信できるようにすることは、人と人との相互作用についての人々の長年の夢です。 ディープニューラルネットワーク(鮮明な例はGoogle Voice Search )の使用により、コンピューターが人間の音声を理解する能力は過去数年間で大幅に向上しました。 ただし、一般的に音声合成または音声合成 (TTS)と呼ばれるプロセスである音声生成は、いわゆる連結TTSの使用に基づいています。 一人が録音した音声の短い断片の大きなデータベースを使用します。 次に、フラグメントが結合されてフレーズが形成されます。 このアプローチでは、新しいデータベースを記録せずに音声を変更することは困難です。たとえば、他の人の音声に変更したり、感情的な色付けを追加したりします。
これにより、スピーチの作成に必要なすべての情報がモデルパラメーターに保存され、スピーチの性質をモデル設定で制御できるパラメトリックTTSに対する大きな需要が生じました。 ただし、これまでのところ、少なくとも英語などの言語の場合、パラメトリックTTSは連結オプションほど自然に聞こえません。 既存のパラメトリックモデルは、通常、 ボコーダーと呼ばれる特別なプロセッサを介して出力信号を駆動することで音を生成します。
WaveNetは、サンプルでオーディオ信号を生成することでパラダイムを変えています。 これにより、音声がより自然に聞こえるだけでなく、音楽などのあらゆる音を作成できます。
ウェーブネット
通常、研究者は、オーディオサンプルのモデリングを避けます。なぜなら、時間スケールで厳密に定義された形状の1秒あたり16,000以上のサンプルを大量に生成する必要があるからです。 各サンプルが以前のすべてのサンプルに依存する自己回帰モデルの構築(統計的に言えば、各予測分布は以前のすべての観測に条件付けられています)は難しいタスクです。
しかし、今年初めに公開されたPixelRNNおよびPixelCNNモデルは、一度に1ピクセルだけでなく、一度に1つのカラーチャンネルによって複雑で自然な画像を生成することが可能であることを示しました。 これにより、2次元PixelNetを1次元WaveNetに適合させることができました。

上記のアニメーションは、WaveNetデバイスを示しています。 これは畳み込みニューラルネットワークであり、層は異なる膨張係数を持ち、その受容野は深さとともに指数関数的に成長し、数千の時間間隔をカバーします。
トレーニング中、着信シーケンスは音声録音の例からの音波です。 トレーニング後、ネットワークを使用して合成フレーズを生成できます。 各サンプリングステップで、ネットワークによって計算された確率分布から値が計算されます。 次に、この値が入力に返され、次のステップのために新しい予測が行われます。 この方法でサンプルを作成することは、リソースを大量に消費するタスクですが、複雑で現実的なサウンドを生成する必要があることがわかりました。
最新技術の改善
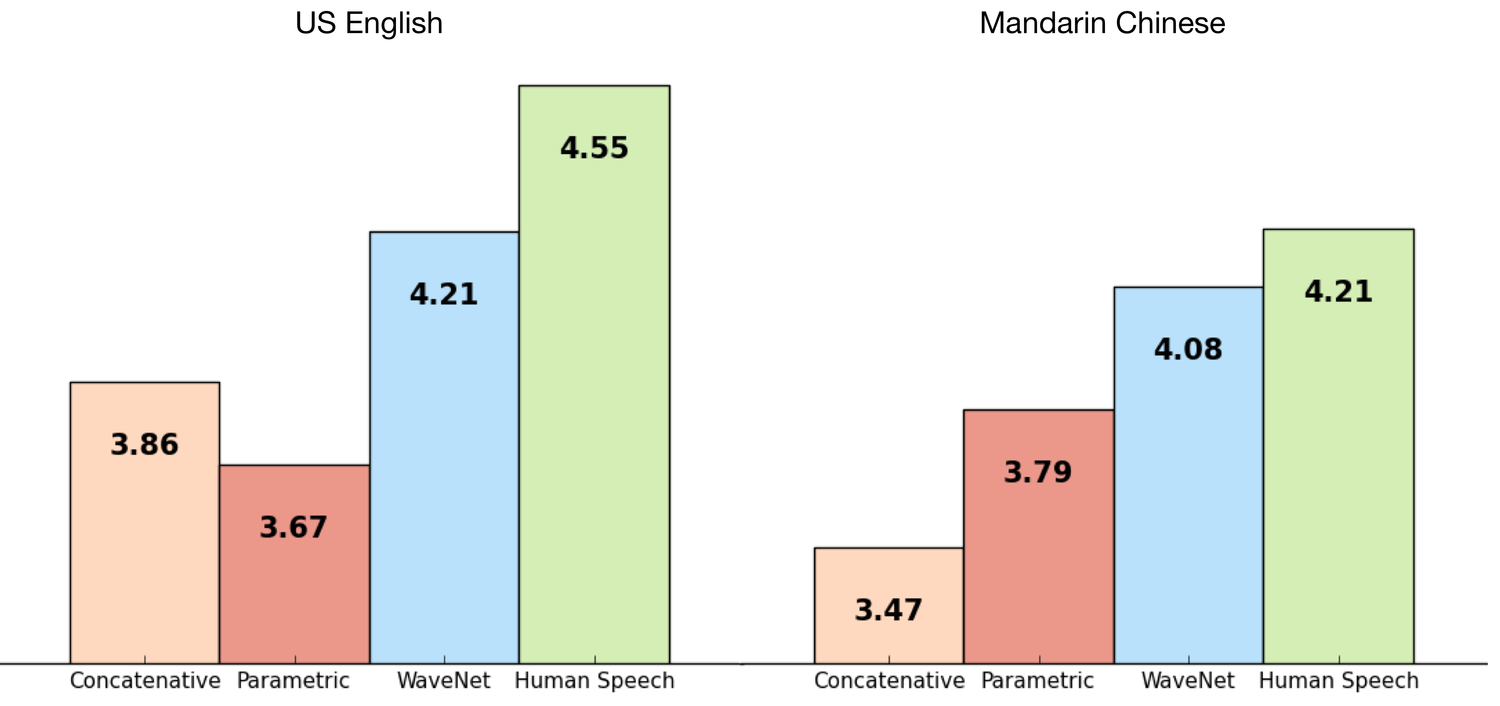
TTS Googleのデータセットを使用してWaveNetをトレーニングしたため、作業の品質を評価することができました。 以下のグラフは、Googleの最高のTTS(パラメトリックおよび連結)と比較したMOS(平均オピニオンスコア)との比較で、1〜5のスケールで品質を示しています。 MOSは主観的な音質テストを行う標準的な方法であり、テストでは100文が使用され、さらに500件の評価が収集されました。 ご覧のとおり、WaveNetsは英語と中国語の合成音声と実際の音声の品質のギャップを大幅に削減しました(以前の合成方法との違いは50%以上です)。
中国語と英語の両方について、Googleの現在のTTSは世界最高の1つと見なされているため、1つのモデルで両方の言語を大幅に改善することは大きな成果です。
以下にいくつか例を挙げて、聞いて比較できるようにします。
英語(アメリカ英語)
パラメトリック
例1
例2
連結
例1
例2
ウェーブネット
例1
例2
中国語(標準中国語)
パラメトリック
例1
例2
連結
例1
例2
ウェーブネット
例1
例2
あなたが言う必要があることを理解する
WaveNetを使用してテキストを音声に変換するには、テキストが何であるかを明確にする必要があります。 これを行うには、テキストを一連の言語的および音声的特性(それぞれが現在の音素、音節、単語などに関する情報を含む)に変換し、WaveNetに送信します。 これは、ネットワーク予測が以前のオーディオサンプルだけでなく、音声に変換するテキストにも依存することを意味します。
テキストデータなしでネットワークをトレーニングしても、音声を生成することはできますが、その場合は発言する必要があります。 以下の例からわかるように、これにより、実際の単語に、単語に似た生成音が散在する、ある種のチャタリングが発生します。
例1
例2
例3
例4
例5
例6
呼吸や口の動きなど、音声ではない音もWaveNetによって生成される場合があることに注意してください。 これは、オーディオデータ生成モデルの優れた柔軟性を示しています。
また、これらの例からわかるように、1つのWaveNetネットワークは、男性と女性のさまざまな音声の特性を調べることができます。 各声明に適切な声を選択する機会を彼女に与えるために、発言者の識別を使用するための条件をネットワークに設定します。 さらに興味深いことに、多くの異なる話者から学習することで、特定の音声のモデリングの質が向上します。これは、学習に何らかの形で知識を伝達する、その人の音声のみで学習する場合に比べます。
発言者のアイデンティティを変更することで、ネットワークに異なる声で同じことを言うことができます。
例1
例2
例3
例4
同様に、感情やアクセントなどの追加情報をモデル入力に送信して、音声をさらに多様で興味深いものにすることができます。
音楽を作る
WaveNetsはあらゆるオーディオをシミュレートするために使用できるため、音楽を生成することは興味深いと判断しました。 TTSを使用したシナリオとは異なり、特定の何かを(ノートで)再生するようにネットワークを構成しませんでしたが、反対に、ネットワークが必要なものを生成できるようにしました。 クラシックピアノ音楽からの入力についてネットワークをトレーニングした後、彼女はいくつかの魅力的な作品を作成しました。
例1
例2
例3
例4
例5
例6
WaveNetsは、一般にTTS、自動音楽作成、およびオーディオモデリングの多くの新しい可能性を開きます。 ニューラルネットワークを使用したサンプルの段階的な作成を使用して16KHzオーディオを作成するアプローチは一般にすでに機能していますが、このアプローチにより、最先端のTTSシステムよりも優れた結果を達成できることが判明しました。 私たちは熱意を持って他の可能なアプリケーションを検討します。
より詳細な情報については、このトピックに関する書面による研究を読むことをお勧めします。
Ex Machinaムービーから撮影した注意画像