 多くの場合、オペレーティングシステムのネットワークサブシステムの監視は、パケット、オクテット、およびネットワークインターフェイスエラーのカウンターで終了します。 しかし、これはOSIモデルの第2レベルにすぎません!
多くの場合、オペレーティングシステムのネットワークサブシステムの監視は、パケット、オクテット、およびネットワークインターフェイスエラーのカウンターで終了します。 しかし、これはOSIモデルの第2レベルにすぎません!
一方では、ネットワークに関するほとんどの問題は物理層とリンク層でのみ発生しますが、他方では、ネットワークで動作するアプリケーションはTCPセッションレベルで動作し、下位レベルで何が起こっているかはわかりません。
かなり単純なTCP / IPスタックメトリックが分散システムのさまざまな問題にどのように役立つかを説明します。
ネットリンク
Linuxのnetstatユーティリティはほとんどの人が知っています。現在のすべてのTCP接続と追加情報を表示できます。 ただし、接続数が多い場合、netstatは長時間動作し、システムに大きな負荷をかける可能性があります。
接続情報を取得するより安価な方法があります-iproute2プロジェクトのssユーティリティです。
比較のために:
$ time netstat -an|wc -l 62109 real 0m0.467s user 0m0.288s sys 0m0.184s
$ time ss -ant|wc -l 62111 real 0m0.126s user 0m0.112s sys 0m0.016s
加速は、カーネルから接続情報を照会するためにnetlinkプロトコルを使用することにより実現されます。 エージェントはnetlinkを直接使用します。
化合物のカウント
免責事項:異なるスライスのメトリックの操作を説明するために、メトリックを操作するためのインターフェイス(dsl)を示しますが、これはオープンソースリポジトリでも実行できます 。
まず、サーバーに関してすべての接続をインバウンドとアウトバウンドに分割します。
特定の時点での各TCP接続はstateの 1つにあります 。これは、これによって保存される内訳です(これは便利な場合があります)。
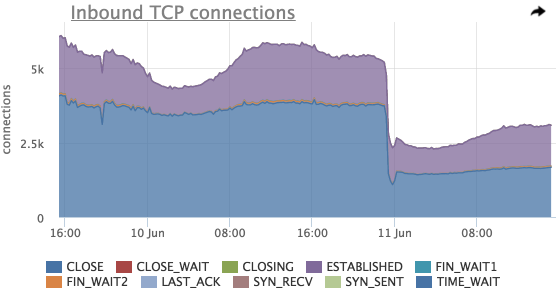
このグラフから、着信化合物の総数、状態ごとの化合物の分布を推定できます。
ここでは、 6月11日の直前に接続の総数が急激に減少していることもわかります。リスンポートのコンテキストで接続を見てみましょう。

このグラフは、最も重要なドロップがポート8014であったことを示しています。8014のみを見てみましょう(インターフェイスでは、目的の凡例項目をクリックするだけです)。

すべてのサーバーにわたる着信接続の数が変更されたかどうかを確認してみましょう。
マスク「srv10 *」でサーバーを選択します。
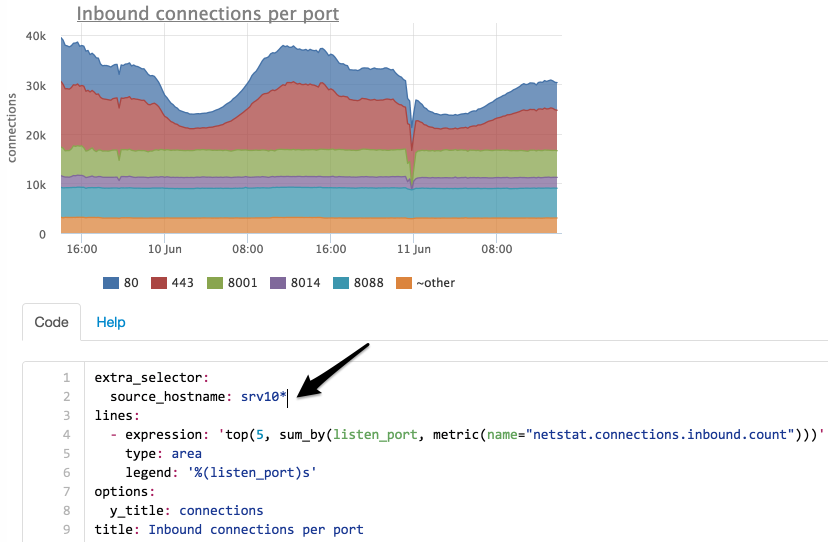
ポート8014の接続数は変更されていないことがわかりました。移行先のサーバーを見つけてください。

選択をポート8014のみに制限し、ポートではなくサーバーごとにグループ化しました。
これで、 srv101サーバーからの接続がsrv102に切り替えられたことは明らかです。
IPの内訳
多くの場合、異なるIPアドレスからの接続の数を確認する必要があります。 エージェントは、リッスンポートと状態だけでなく、このIPが同じネットワークセグメントにある場合はリモートIPによってもTCP接続の数を削除します(他のすべてのアドレスについてはメトリックが合計され、IPの代わりに「〜nonlocal」が表示されます)。
前の場合と同じ期間を考慮してください。
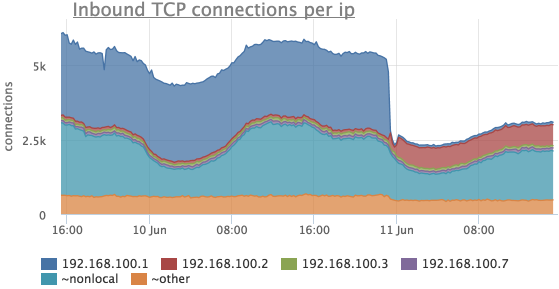
ここで、 192.168.100.1との接続がはるかに少なくなり、同時に192.168.100.2との接続があったことがわかります。
詳細ルール
実際、1つのメトリックで作業しましたが、非常に詳細なものでした。各インスタンスの識別子は次のようになります。
{name="netstat.connections.inbound.count", state="<TCP_STATE>", listen_ip="<IP>" listen_port="<PORT>" remote_ip="<REMOTE_IP>"}
たとえば、ロードされたフロントエンドサーバー上のクライアントの1つで、このメトリックの約700個のインスタンスが削除されています
TCPバックログ
TCP接続のメトリックにより、ネットワークを診断するだけでなく、サービスの問題を特定することもできます。
たとえば、ネットワークを介してクライアントにサービスを提供する一部のサービスが負荷に対処せず、新しい接続の処理を停止した場合、それらはキューに入れられます( バックログ )。
実際、次の2行があります。
- SYNキュー-指定されていない接続のキュー(受信したSYNパケット 、 SYN-ACKはまだ送信されていません)、サイズはsysctl net.ipv4.tcp_max_syn_backlogに従って制限されます。
- Acceptキュー-ACKパケットを受信した接続のキュー( 「トリプルハンドシェイク」の一部として)が、Acceptアプリケーションによって実行されなかった(キューはアプリケーションによって制限されます)
受け入れキューのACK制限に達すると、リモートホストパケットは単に破棄されるか、 RSTに送信されます(sysctl net.ipv4.tcp_abort_on_overflow変数の値に応じて)。
エージェントは、サーバー上のすべての待機ソケットの現在および最大の受け入れキュー値を削除します。
これらのメトリックには、サービスのバックログが90%以上使用されているかどうかを通知するグラフと事前構成されたトリガーがあります。

カウンターとプロトコルエラー
クライアントの1つのサイトがDDOS攻撃を受けた場合、モニタリングではネットワークインターフェイス上のトラフィックの増加のみが示されましたが、このトラフィックの内容に関するメトリックはまったく表示されませんでした。
現時点では、okmmeterはこの質問に対して明確な答えを出すことができません。スニッフィングをマスターし始めたばかりですが 、この問題についてはある程度の進歩を遂げています。
これらの着信トラフィックの放出について何かを理解してみましょう。
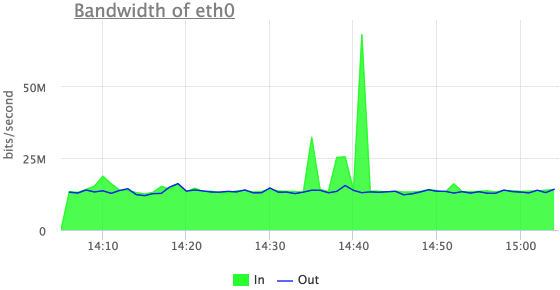

ここで、これは着信UDPトラフィックであることがわかりますが、3つの外れ値の最初はここでは見えません。
実際のところ、Linuxのプロトコル上のパケットカウンターは、パケットが正常に処理された場合にのみ増加します。
エラーを見てみましょう:
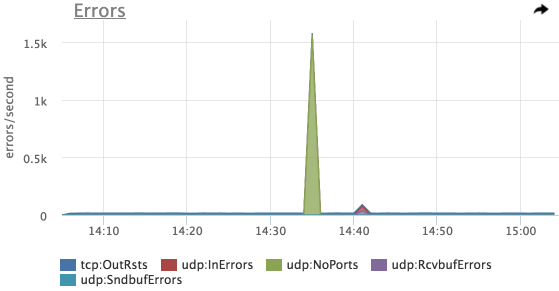
そして、ここに最初のピークがあります-UDPエラー:NoPorts (誰もリッスンしていないUPDポートで受信したデータグラムの数)
iperfを使用してこの例をエミュレートしましたが、最初の呼び出しでは、受信サーバーの必要なポートにパケットを含めませんでした。
TCPリレー
別途、TCPの再送信( TCPセグメントの再送信 )の数を示します 。
再送信だけでは、ネットワークでパケット損失が発生するわけではありません。
送信ノードが一定時間(RTO)内に受信確認(ACK)を受信しなかった場合、セグメントは再送信されます。
このタイムアウトは、最小の遅延を維持しながら保証されたデータ転送を保証するために、特定のホスト間のデータ転送時間(RTT)の測定に基づいて動的に計算されます。
実際には、再送信の回数は通常、サーバーの負荷と相関関係があり、絶対値ではなく、さまざまな異常を確認することが重要です。

このグラフでは、再送信の2つの外れ値が見られますが、同時にpostgresプロセスはこのサーバーのCPUを使用しました。

/ proc / net / snmpからプロトコルカウンターを取得します 。
コントラック
もう1つの一般的な問題は、Linuxのip_conntrackテーブルのオーバーフロー( iptablesを使用)です。この場合、Linuxはパケットのドロップを開始します。
これは、dmesgのメッセージで確認できます。
ip_conntrack: table full, dropping packet
エージェントは、ip_conntrackを使用して、このテーブルの現在のサイズと制限をサーバーから自動的に削除します。
また、okmeterには、ip_conntrackテーブルが90%以上満たされている場合に通知する自動トリガーがあります。
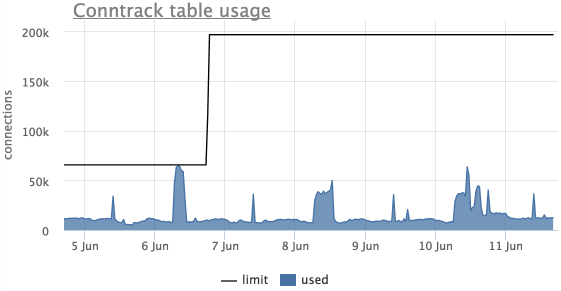
このグラフでは、テーブルがオーバーフローしており、制限が引き上げられており、もはや到達されていないことがわかります。
結論の代わりに
- メトリックの粒度は非常に重要です
- 何かがオーバーフローする可能性がある場合は、必ずそのような場所を監視する必要があります
- TCP / IP(RTT、空でない送信/受信キューを持つ接続)を介して多くの異なるものを削除しますが、これを正しく動作させる方法をまだ理解していません
標準チャートの例は、 デモプロジェクトにあります。
また、 Netstatチャートを見ることができます。