はじめに
以前の投稿で、画像処理にGPUを利用することがどれほど簡単かを説明しようとしました。 運命は、GPUのメディアンフィルタリングを改善しようとする機会であることがわかりました。 この投稿では、特にメディアンフィルタリングの例を使用して、画像処理でGPUからさらに高いパフォーマンスを得る方法を説明しようとします。 GPU GTX 780 tiを、ベクトルレジスタAVX2のセットを備えた最新のIntel Core i7 Skylake 4.0 GHzプロセッサで実行される最適化されたコードと比較します。 GPU GTX 780Tiの51 GPixels / secで3x3の2乗の達成されたフィルタリング速度と、単一精度で1 TFlopsあたり10.2 GPixels / secの3x3の2乗の特定のフィルタリング速度は、世界で最も高い知られています 。
何が起こっているのかを明確にするために、以前の投稿を読むことを強くお勧めします。この投稿は、既に書かれたバージョンを改善するためのヒント、推奨事項、アプローチです。 私たちが何をしているかを思い出させるには:
- ソースイメージの各ポイントに対して、特定の近傍(この場合は3x3 / 5x5)が取得されます。
- この近傍のポイントは、明るさの増加によってソートされます。
- ソートされた近傍の中間点が最終画像に記録されます。
中央値フィルター3x3正方形
GPUの画像処理コードを最適化する方法の1つは、繰り返される操作を見つけて強調表示し、単一のワープ内で一度だけ実行することです。 場合によっては、アルゴリズムをわずかに変更する必要があります。 フィルタリングを検討すると、1つのピクセルの周りに3x3の正方形をロードすることにより、隣接するスレッドが同じ論理演算と同じメモリロードを行うことがわかります。
__global__ __launch_bounds__(256, 8) void mFilter_33(const int H, const int W, const unsigned char * __restrict in, unsigned char *out) { int idx = threadIdx.x + blockIdx.x * blockDim.x + 1; int idy = threadIdx.y + blockIdx.y * blockDim.y * 4 + 1; unsigned a[9] = { 0, 0, 0, 0, 0, 0, 0, 0, 0 }; if (idx < W - 1) { for (int z3 = 0; z3 < 4; ++z3) { const int shift = 8 * (3 - z3); for (int z2 = 0; z2 < 3; ++z2) for (int z1 = 0; z1 < 3; ++z1) a[3 * z2 + z1] |= in[(idy - 1 + z2) * W + idx - 1 + z1] << shift; // <----- warp // 6 12 // idy += BL_Y; } /* */ } }
少し考えれば、同じ操作を1回だけ行うことでソートを改善できます。 わかりやすくするために、並べ替えがどのようになり、何が行われ、このアプローチの利点が何であるかを示します。
以前の投稿では、9つの要素に対して既に発明された不完全なブッチャーソートを使用しました。これにより、最小数の操作で条件演算子を使用せずに中央値を見つけることができます。 この並べ替えは、それぞれ独立した要素が並べ替えられる反復形式で表されますが、繰り返しの間に依存関係があります。 反復ごとに、ソート用の要素のペアが選択されます。
古いソート:
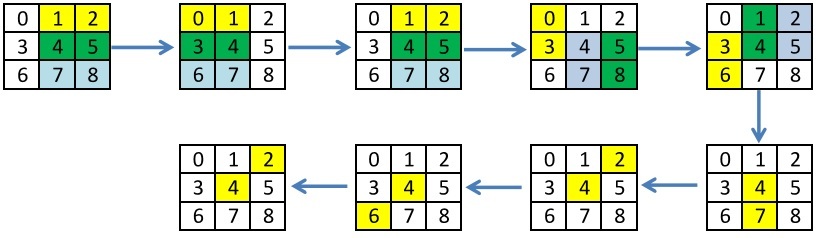
新しい並べ替え:

外観上、両方のアプローチは同じであると言えます。 しかし、操作の数と他のスレッドで計算された値を使用する機能の観点から最適化の観点からこれを見てみましょう。 列を一度だけロードおよびソートし、スレッド間で交換し、中央値をカウントできます。 これは視覚的に次のようになります。
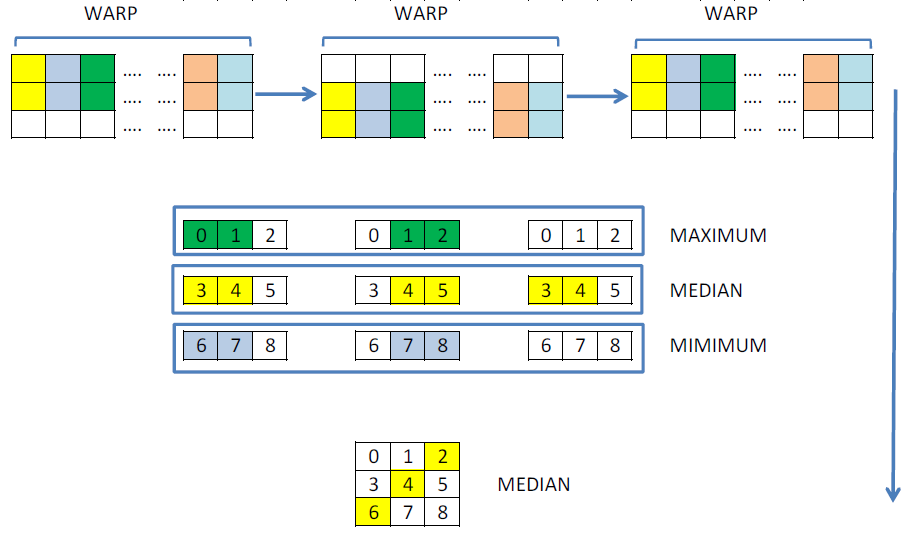
次のカーネルは、このようなアルゴリズムに対応しています。 交換には、共有メモリではなく、新しい__shfl操作を使用することにしました。これにより、同期せずに1つのワープ内で値を交換できます。 したがって、計算の繰り返しを部分的に回避することができます。
__global__ BOUNDS(BL_X, 2048 / BL_X) void mFilter_3x3(const int H, const int W, const unsigned char * __restrict in, unsigned char *out) { // int idx = threadIdx.x + blockIdx.x * blockDim.x; // , warp' idx = idx - 2 * (idx / 32); // 4, 4 int idy = threadIdx.y + blockIdx.y * blockDim.y * 4 + 1; unsigned a[9]; unsigned RE[3]; // bool bound = (idxW > 0 && idxW < 31 && idx < W - 1); // RE[0] = in[(idy - 1) * W + idx] | (in[(idy + 0) * W + idx] << 8) | (in[(idy + 1) * W + idx] << 16) | (in[(idy + 2) * W + idx] << 24); RE[1] = in[(idy + 0) * W + idx] | (in[(idy + 1) * W + idx] << 8) | (in[(idy + 2) * W + idx] << 16) | (in[(idy + 3) * W + idx] << 24); RE[2] = in[(idy + 1) * W + idx] | (in[(idy + 2) * W + idx] << 8) | (in[(idy + 3) * W + idx] << 16) | (in[(idy + 4) * W + idx] << 24); Sort(RE[0], RE[1]); Sort(RE[1], RE[2]); Sort(RE[0], RE[1]); // a[0] = __shfl_down(RE[0], 1); a[1] = RE[0]; a[2] = __shfl_up(RE[0], 1); a[3] = __shfl_down(RE[1], 1); a[4] = RE[1]; a[5] = __shfl_up(RE[1], 1); a[6] = __shfl_down(RE[2], 1); a[7] = RE[2]; a[8] = __shfl_up(RE[2], 1); // a[2] = __vmaxu4(a[0], __vmaxu4(a[1], a[2])); // Sort(a[3], a[4]); a[4] = __vmaxu4(__vminu4(a[4], a[5]), a[3]); // a[6] = __vminu4(a[6], __vminu4(a[7], a[8])); // Sort(a[2], a[4]); a[4] = __vmaxu4(__vminu4(a[4], a[6]), a[2]); // , if (idy + 0 < H - 1 && bound) out[(idy) * W + idx] = a[4] & 255; if (idy + 1 < H - 1 && bound) out[(idy + 1) * W + idx] = (a[4] >> 8) & 255; if (idy + 2 < H - 1 && bound) out[(idy + 2) * W + idx] = (a[4] >> 16) & 255; if (idy + 3 < H - 1 && bound) out[(idy + 3) * W + idx] = (a[4] >> 24) & 255; }
2番目の最適化は、各スレッドが一度に4ポイントではなく、2セットの4ポイントまたはNセットの4ポイントを処理できるという事実に関連しています。 これは、デバイスの負荷を最大化するために必要です。なぜなら、3x3フィルターだけでは、4ポイントの1セットでは十分ではないからです。
まだ実行可能な3番目の最適化は、画像の幅と高さを置き換えることです。 これにはいくつかの引数があります。
- 通常、画像サイズには固定値があります。たとえば、一般的なフルHD、ウルトラHD、720pなどです。 プリコンパイルされたカーネルのセットのみを使用できます。 この最適化により、生産性が約10〜15%向上します。
- Cuda Toolkit 7.5を使用すると、動的コンパイルを実行でき、実行時に値の置換を実行できます。
完全に最適化されたコードは次のようになります。 ポイントの数を変えることにより、最大のパフォーマンスを得ることができます。 私の場合、numP_char = 3で最大のパフォーマンスが達成されました。つまり、3ポイントの4ポイントまたはスレッドあたり12ポイントです。
__global__ BOUNDS(BL_X, 2048 / BL_X) void mFilter_3x3(const unsigned char * __restrict in, unsigned char *out) { int idx = threadIdx.x + blockIdx.x * blockDim.x; idx = idx - 2 * (idx / 32); int idxW = threadIdx.x % 32; int idy = threadIdx.y + blockIdx.y * blockDim.y * (4 * numP_char) + 1; unsigned a[numP_char][9]; unsigned RE[numP_char][3]; bool bound = (idxW > 0 && idxW < 31 && idx < W - 1); #pragma unroll for (int z = 0; z < numP_char; ++z) { RE[z][0] = in[(idy - 1 + z * 4) * W + idx] | (in[(idy - 1 + 1 + z * 4) * W + idx] << 8) | (in[(idy - 1 + 2 + z * 4) * W + idx] << 16) | (in[(idy - 1 + 3 + z * 4) * W + idx] << 24); RE[z][1] = in[(idy + z * 4) * W + idx] | (in[(idy + 1 + z * 4) * W + idx] << 8) | (in[(idy + 2 + z * 4) * W + idx] << 16) | (in[(idy + 3 + z * 4) * W + idx] << 24); RE[z][2] = in[(idy + 1 + z * 4) * W + idx] | (in[(idy + 1 + 1 + z * 4) * W + idx] << 8) | (in[(idy + 1 + 2 + z * 4) * W + idx] << 16) | (in[(idy + 1 + 3 + z * 4) * W + idx] << 24); Sort(RE[z][0], RE[z][1]); Sort(RE[z][1], RE[z][2]); Sort(RE[z][0], RE[z][1]); a[z][0] = __shfl_down(RE[z][0], 1); a[z][1] = RE[z][0]; a[z][2] = __shfl_up(RE[z][0], 1); a[z][3] = __shfl_down(RE[z][1], 1); a[z][4] = RE[z][1]; a[z][5] = __shfl_up(RE[z][1], 1); a[z][6] = __shfl_down(RE[z][2], 1); a[z][7] = RE[z][2]; a[z][8] = __shfl_up(RE[z][2], 1); a[z][2] = __vmaxu4(a[z][0], __vmaxu4(a[z][1], a[z][2])); Sort(a[z][3], a[z][4]); a[z][4] = __vmaxu4(__vminu4(a[z][4], a[z][5]), a[z][3]); a[z][6] = __vminu4(a[z][6], __vminu4(a[z][7], a[z][8])); Sort(a[z][2], a[z][4]); a[z][4] = __vmaxu4(__vminu4(a[z][4], a[z][6]), a[z][2]); } #pragma unroll for (int z = 0; z < numP_char; ++z) { if (idy + z * 4 < H - 1 && bound) out[(idy + z * 4) * W + idx] = a[z][4] & 255; if (idy + 1 + z * 4 < H - 1 && bound) out[(idy + 1 + z * 4) * W + idx] = (a[z][4] >> 8) & 255; if (idy + 2 + z * 4 < H - 1 && bound) out[(idy + 2 + z * 4) * W + idx] = (a[z][4] >> 16) & 255; if (idy + 3 + z * 4 < H - 1 && bound) out[(idy + 3 + z * 4) * W + idx] = (a[z][4] >> 24) & 255; } }
5x5メディアンフィルター
残念ながら、5x5の正方形について他の並べ替えを思い付くことができませんでした。 保存できるのは、符号なしintの4つのポイントをダウンロードして結合することだけです。 すべての変換は3x3の正方形との類推によって実行できるため、さらに長いコードを作成する意味はありません。
この記事では、2つの正方形の操作と20の要素のオーバーレイを組み合わせるためのいくつかのアイデアについて説明します。 しかし、著者が提案した忘れっぽい選択ソート方法は、隣接する2つの5x5正方形を組み合わせた場合でも、25要素の不完全なブッチャーソートネットワークよりも多くの操作を実行します。
性能
最後に、最適化プロセスを通して取得できた数値をいくつか示します。
| リードタイム、ミリ秒 | 加速 | |||||
|---|---|---|---|---|---|---|
| スカラーCPU | AVX2 CPU | GPU | スカラー/ GPU | AVX2 / GPU | ||
| 3x3 1920x1080 | 22.9 | 0.255 | 0.044(47.1 GP / s) | 520 | 5.8 | |
| 3x3 4096x2160 | 97.9 | 1.33 | 0.172(51.4 GP / s) | 569 | 7.73 | |
| 5x5 1920x1080 | 134.3 | 1.47 | 0.260(7.9 GP / s) | 516 | 5.6 | |
| 5x5 4096x2160 | 569.2 | 6.69 | 1.000(8.8 GP / s) | 569 | 6.69 | |
おわりに
結論として、GPUのメディアンフィルタリングのすべての記事と実装の中で、2013年に公開された前述の記事 「GPUベースのメディアンフィルターの微調整された高速実装」が興味深いことに注目したいと思います。 この記事では、著者はソートに対するまったく異なるアプローチ、つまり忘却的選択方法を提案しました。 このメソッドの本質は、roundUp(N / 2)+ 1個の要素を取り、左から右へ、そして戻ることで、エッジに沿って最小要素と最大要素を取得することです。 次に、これらの要素を忘れて、残りの要素の1つを最後に追加して、プロセスを繰り返します。 追加するものがすでにない場合は、3つの要素の配列が得られ、そこから中央値を簡単に選択できます。 このアプローチの利点の1つは、既知のソートと比較して、使用されるレジスタの数が少ないことです。
この記事は、著者がテスラC2050で1.8 GPixels / secの結果を得たと述べています。 このカードの単精度のパワーは、1 TFlopsと推定されます。 テストに参加する780Tiのパワーは5 TFlopsと推定されます。 したがって、私が提案したアルゴリズムの1 TFlopsあたりの特定の計算速度は、記事の著者によって提案されたものより、3x3正方形で約5.5倍、5x5正方形で約2倍です。 この比較は完全に正しいわけではありませんが、真実により近いものです。 また、この記事では、その時点での実装が既知のすべての中で最速であることが言及されました。
AVX2バージョンと比較して達成された加速は平均6倍でした。 Pascalアーキテクチャに基づく新しいカードを使用する場合、このアクセラレーションは少なくとも2倍に増加する可能性があり、これは約100 GPixels /秒になります。