そのような「アクセラレータ」の良い例は、NVIDIAまたはXeon PhiコプロセッサのGPUです。これがないと、科学またはエンジニアリングコンピューティングの分野のプロジェクトはほとんどできません。 ただし、このようなテクノロジーは実際には企業部門では使用されませんでした( 職場の仮想化ファームでのGPUの使用を除く)。
そのため、汎用コアに加えて専用のData Analytics Accelerator(DAX)コプロセッサーを含むOracle SPARC M7チップに基づくサーバーの出力は、「加速コンピューティング」が企業市場に浸透するための出発点と考えることができます。
DAXの主な目的は、コプロセッサーのRAMの内容を検索してメインコアをアンロードすることにより、インメモリコンピューティングを高速化することです。
検索操作をDAXに転送する必要がある場合、汎用カーネルは要求を生成し、それを「アクセラレータ」に送信して実行します。その後、メインコードの実行を続けます。 この場合、タスクはチップのすべてのアクセラレータで自動的に並列化され、結果がチップキャッシュに収集され(MapReduceと同様)、操作の完了がカーネルに通知されます。 コプロセッサーはチップのL3キャッシュに接続されているため、汎用カーネルとの迅速なやり取りや検索結果の転送が可能です。

DAXを使用してデータを検索できるようにするには、特別な形式(メモリ内列ストア)でメモリ内に配置する必要があることに注意してください。 この形式の特徴は、データを圧縮形式で保存できることです(圧縮アルゴリズムは独自のOracle Zipです)。これにより、RAMにより多くの情報を配置でき、チップとRAMを接続するバスの帯域幅を節約するため、アクセラレータによるデータ処理の速度にプラスの効果があります。 検索時、圧縮解除はDAXを使用してハードウェアで実行され、パフォーマンスには影響しません。 別の機能は、インメモリ列ストアを構成する多くのメモリセグメント(インメモリ圧縮ユニット-IMCU)のそれぞれの最小値と最大値を含むインデックスの存在です。 サンプルの「加速」には価格があります-メモリ内のデータの初期配置が長く、その間にデータが圧縮されて予備分析されます(一種のインデックス付け)。
現在、このテクノロジーの主な消費者はOracle Database 12cです。これは、DAXを使用して、インメモリカラムストアにあるテーブルの検索操作を高速化します。 DBMSは一部の操作を自動的にDAXに転送します。これにより、一部のクエリが大幅に高速化されます。
しかし、Jet Infosystemsの興味深い点は、興味深い詳細を隠し、コプロセッサーを使用して得られるメリットを正確に評価できない追加のオーバーヘッドを作成するOracle Database DBMSの形式の中間「ブラックボックス」なしでDAXテクノロジーを研究することでした。
サードパーティアプリケーションからのDAXコプロセッサーの使用
2016年3月上旬に、オラクルは独立開発者向けDAXアクセスAPI(Open DAX API)を開始しました。 DAXは、Oracleデータベースだけでなく、他のアプリケーションでも使用できるようになりました。
Oracleは、DBMSからだけでなく、さまざまなプログラミング言語(C、Python、Java)でSDKを使用してDAXをテストするために、全員をクラウドに招待しました 。 コプロセッサーのハードウェアと直接やり取りするように設計された低レベルAPIはSDK自体に加えて非常に複雑であるため、メインメモリーにあるデータ(libvector)を操作するための高レベルツールを提供する追加ライブラリを使用して、新しいテクノロジーに慣れることが提案されました。 その基礎に基づいて、DAXの動作を検証するために多くのテストが行われました。
SDKコンポーネント
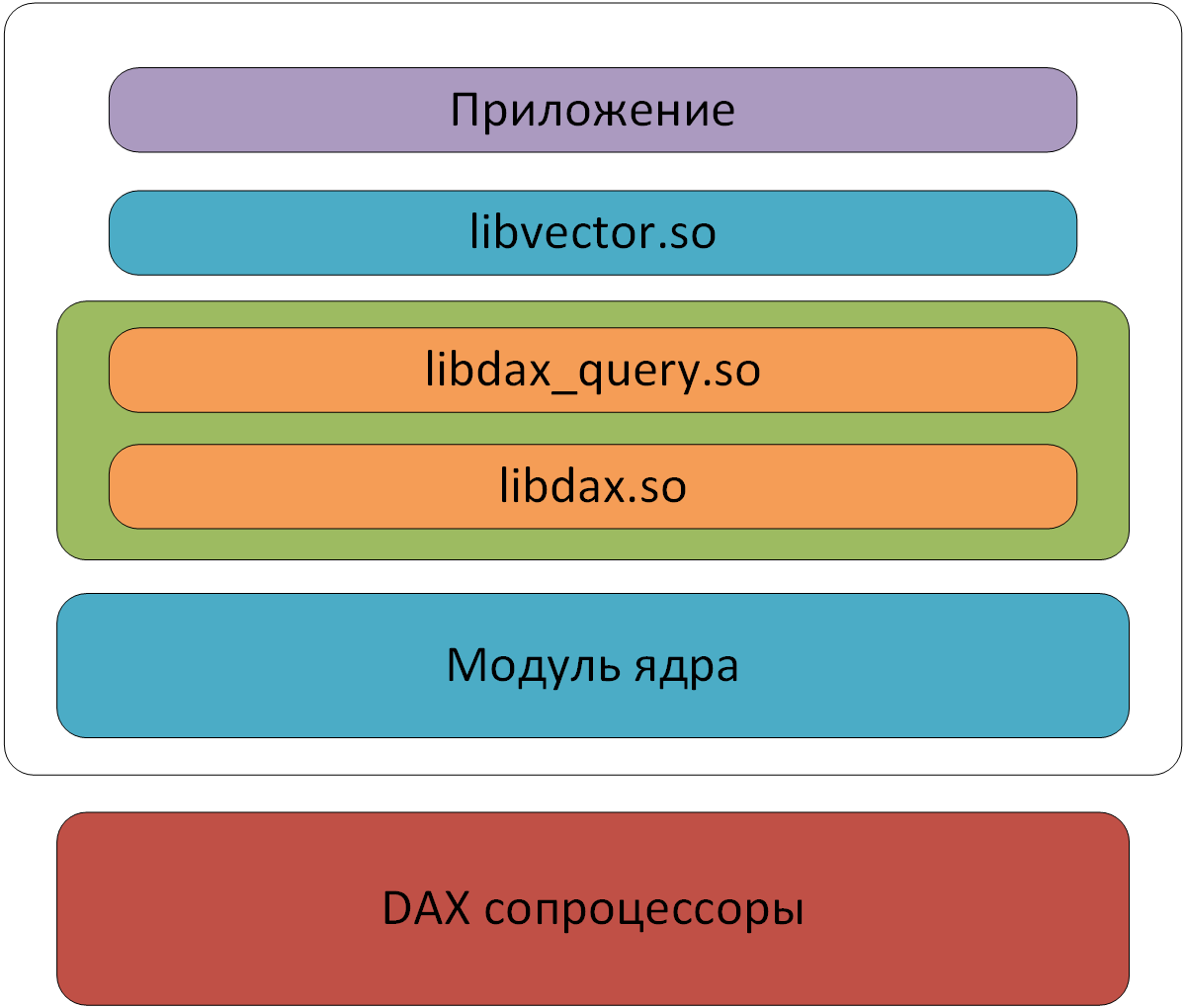
テストスクリプト
テストケースとして、単純な分析上の問題、つまり、特定の条件を満たすメモリ内にある整数配列内の値の検索を検討しました。 SQLクエリの形式では、このタスクは次のように記述できます。
SELECT value FROM values WHERE value BETWEEN value_low AND value_high;
このタスクは、すべての要素の古典的な列挙とDAXコプロセッサーの使用という2つの方法で解決される予定でした。
実装
Cでは、この問題の解決策はおよそ次のとおりでした。
#define RANDOM_SEED 42 int *values, *results; int low = VALUE_LOW, high = VALUE_HIGH; values = generate_random_values_array(NUM_VALUES, RANDOM_SEED); results = malloc(NUM_VALUES * sizeof(int)); for (i=0; i<NUM_VALUES; i++) { if (values[i] >= low && values[i] <= high) { results[n] = values[i]; n++; } }
検索する場合、結果はすぐに新しい配列に保存されることに注意してください。 繰り返しますが、上記のコードはメインプロセッサのコアで実行されます。
DAXの場合、結果の検索と取得は2つの操作に分けられます。
#include <vector.h> /* DAX */ #define RANDOM_SEED 42 int low = VALUE_LOW, high = VALUE_HIGH; vector valuesVec, bitVec, resultsVec; valuesVec = generate_random_values_vector(NUM_VALUES, RANDOM_SEED); /* */ bitVec = vector_in_range(valuesVec, &low, &high); /* , */ n = bit_vector_count(bitVec); /* , */ resultsVec = vector_extract(valuesVec, bitVec);
DAXの場合、条件を満たす値を検索する操作(vector_in_range関数)はビットベクトルを返し、それに基づいて、結果を持つ新しいベクトルが別のクエリ(vector_extract)によって生成されます。 検索されたレコードは、IMCUから抽出され、新しいIMCUに書き込まれます。これは、DAXを介して再びアクセスできます。
この方法により、値が条件を満たしているキーを見つける必要がある場合に、キー/値のデータセットを効果的に使用できます。 この場合、メモリ内に2つのデータ配列(キーのベクトルと値のベクトル)が形成されます。
vector keysVec, valuesVec; int low = VALUE_LOW, high = VALUE_HIGH; populateKeyValueVectors(&keysVec, &valueVec);
検索は、DAXを使用して値のベクトルで実行され、その結果はビットマップです。
bitVec = vector_in_range(valuesVec, &low, &high);
必要な要素を抽出するには、取得したビットマップをDAXを使用してキーベクトルに適用します。
resultsVec = vector_extract(keysVec, bitVec);
さらに、ANDやORなどの操作はビットベクトルのセットに対して実行できます。つまり、たとえばクエリのように、いくつかの比較の結果の組み合わせをDAXにシフトできます。
SELECT part FROM parts WHERE mass > 100 AND volume < 30;
ANDを介して2ビットベクトルを組み合わせた実験では、DAXでの呼び出しの利点が示されました。
bit_vector_and2(bitVec1, bitVec2);
次の形式のプロセッサでビットマップを結合する前に、要素単位(long型の要素)で:
for (i=0; i<elemcount; i++) { resultsRegularBitMap[i] = regularBitMap1[i] & regularBitMap2[i]; }
要素の数に応じて、実行速度の3〜6倍。
しかし、プログラムに戻ります。 配列の要素はランダムな整数であり、検索は-109〜109の範囲で実行されます(つまり、約半分の数が条件を満たします)。
私たちは、テスト実装の両方のバリアントを、配列内の数100万から5億で数回起動し、検索にかかった時間と、結果を再度使用できる新しい配列にコピーするのにかかった時間を測定しました。 古典的な列挙では、これら2つの操作を分離することは意味がありません。 要素のアドレス(8バイト)または要素自体(4バイト)を新しい配列にコピーする必要があります。
結果
そのため、以下は、配列要素の数でデータを検索および受信する時間のグラフです。
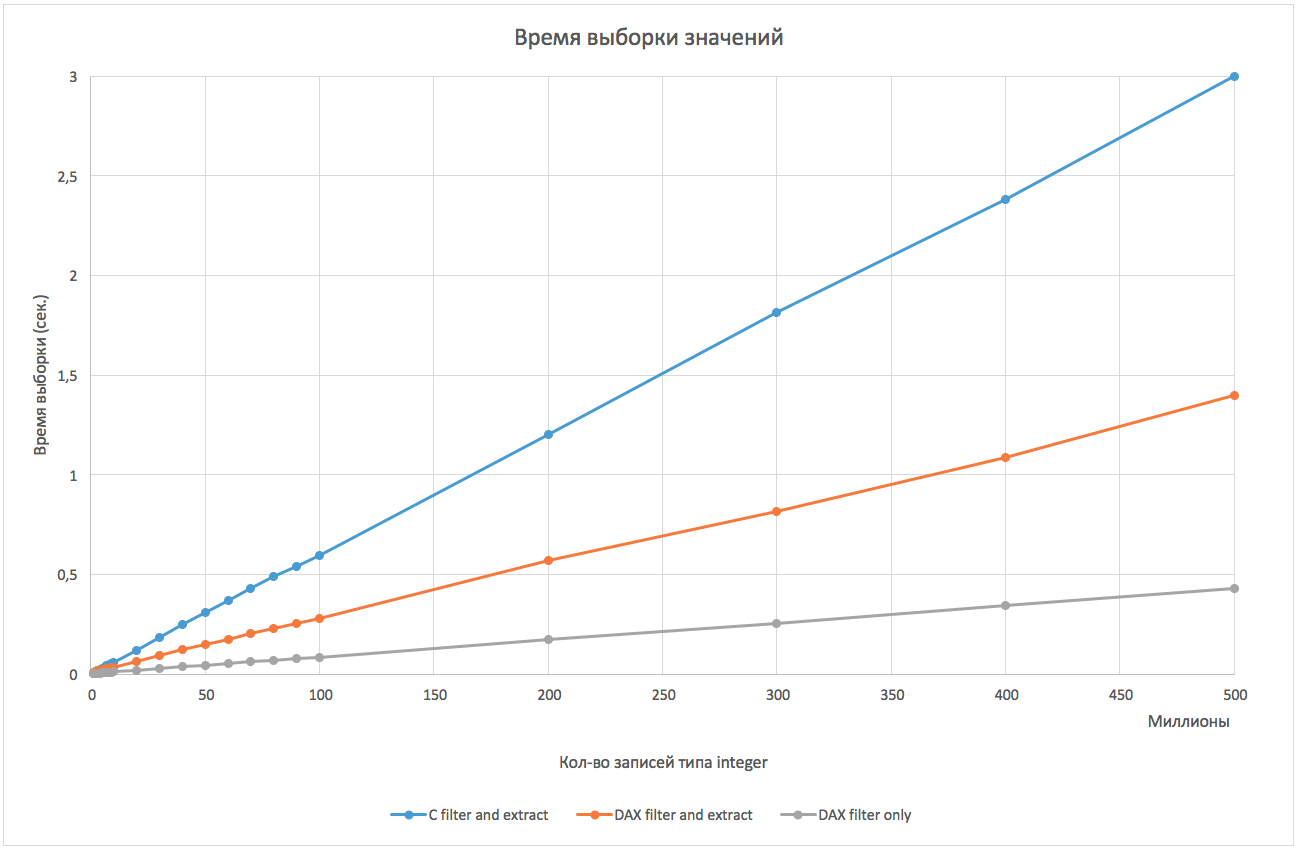
DAXを使用すると、単純な網羅的検索よりも2倍の優位性が示されました。 検索のみを比較した場合(見つかった値を保存せずに、「SELECT COUNT(*)」という形式の操作を実行するとき、またはビットマップを取得するために)、DAXの検索速度は5倍以上になります。
busstatユーティリティを使用して、システム内のコプロセッサの使用を監視できます。busstatユーティリティは、さまざまなプロセッサコンポーネント(busstat -w dax 30 1)からパフォーマンスメトリックを収集します。 テストの実行中に、32個のDAXコプロセッサーのうち8個の要求の並列化が観察されました(各M7プロセッサーには8個あります)。 複数のユーザープロセスを並行して使用する場合、負荷は32個すべてのコプロセッサーで確認できます。
もちろん、すべてのDAXアルゴリズムをプログラムで実装し(DAXの前にOracle Database In-Memory Optionに実装されていた)、追加の最適化を行い、DAXを使用した場合よりも印象的な結果を得ることができます(特に、タスクをすべてのプロセッサスレッドSPARC M7に手動で並列化した場合) ただし、DAXの目的は、プロセッサコアの作業を専用のコプロセッサに移行することです。 つまり 一般に、重要なのはパフォーマンスの向上そのものではなく、メインCPUの負荷を軽減する能力です。
その他の興味深い点
DAXのサンプルコードの中で、OracleエンジニアはApache Sparkのアプリケーションにサポートを実装しました。 メーカーによると、DAXを使用すると、生産性が6倍に向上しました。 最適化の本質は、DAXを介したビットマップを使用した多くの操作であり、プロセッサよりもはるかに高速でした。
結論
プログラムロジックの実行をプロセッサから特殊なデバイスに転送することは、その価値が再び証明されました。 特に、現在インメモリコンピューティングのような暑い地域で。
オープンAPIを介してDAXを使用する機能は、SPARCの世界に新しいソフトウェア製品をもたらすことができます。
ただし、Xeon Phiコプロセッサを使用して、既存のハードウェアソリューションのIntelプラットフォームに将来同様の機能を実装できます。 少なくともこの分野の研究はすでに進行中です。
ポスト台本
テストプログラムは、Solaris Studio 12.4コンパイラを使用して構築されました。 最大の最適化レベル(-xO5)が使用されたため、「古典的な」計算を大幅に高速化できました。 ソースコードはgithubで入手できます。
SPARC M7およびDAXは、Oracleの公式リリースです 。
この記事は、Jet Infosystems Computer Design CenterのシステムアーキテクトであるDmitry Glushenkoによって作成されました。 建設的なコメントを歓迎します。