
これらの記事は、中級レベルの開発者を対象としています。 読者は、C ++およびFortran *の一般的なプログラミング機能を使用して、プログラムのパフォーマンスを最適化しようとすることを前提としています。 アセンブラーと組み込み関数の使用は、経験豊富なユーザーに任せます。 著者は、プロセッサの命令セットのアーキテクチャと、データ構造の分析と設計に関する優れた記事を発行する多数の研究ジャーナルに精通するために、より詳細な資料を入手したい人に勧めています。
データとコードを整理するとき、2つの基本原則が使用されます。データの移動を最小限に抑え、データが使用されるエリアのできるだけ近くにデータを配置する必要があります。 データがプロセッサレジスタに(またはレジスタにできるだけ近い)落ちた場合、メモリから削除する前、または実行可能なプロセッサブロックから移動する前に、最も効果的に使用する必要があります。
データ配置
データを配置できる3つのレベルを検討します。 実行可能ブロックに最も近い場所は、プロセッサレジスタです。 レジスタ内のデータを処理できます。乗算と加算を適用し、比較と論理演算で使用します。 マルチコアプロセッサでは、通常、各コアには独自の1次キャッシュ(L1)があります。 一次キャッシュからレジスタにデータを非常に迅速に移動できます。 キャッシュにはいくつかのレベルがありますが、通常、最後のレベルのキャッシュ(LLC)はすべてのプロセッサコアに共通です。 中間キャッシュレベルの配置は、プロセッサモデルによって異なります。 これらのレベルは、すべてのニュークリアスに共通することも、各ニュークリアスごとに個別にすることもできます。 Intelプラットフォームでは、同じプラットフォーム内での一貫したキャッシュ操作がサポートされます(複数のプロセッサがある場合でも)。 キャッシュからレジスタへのデータの移動は、メインメモリからデータを取得するよりも高速です。
データの概略的な位置、プロセッサレジスタへの近接性、および相対アクセス時間を図に示します。 1.ブロックがレジスタに近いほど、データが実行のためにレジスタに到着するときの動きが速くなり、遅延が短くなります。 キャッシュは、遅延が最小の最速のメモリです。 速度の次はメインメモリです。 この記事の後半では、複数レベルのメモリデバイスについて説明しますが、メモリにはいくつかのレベルがあります。 メモリページがハードディスクまたはソリッドステートドライブ上のページングファイルの仮想メモリにある場合、速度は大幅に低下します。 ネットワーク(イーサネット、Infinibandなど)でデータを送受信する従来のMPIアーキテクチャは、ローカルシステムでデータを受信するよりも多くの遅延があります。 MPIアクセスのあるリモートシステムからデータを移動するときの速度は、使用する接続方法(イーサネット、Infiniband、Intel True Scale、またはIntel Omni Scale)によって異なる場合があります。
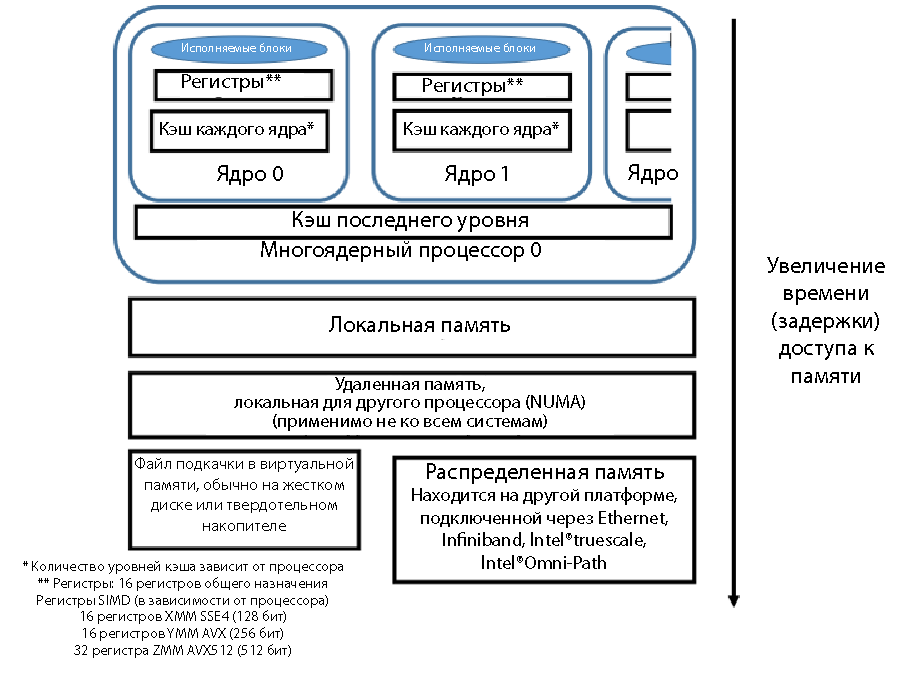
図1.メモリアクセス速度、データアクセスの相対的な遅延
実行可能ブロックに最も近い場所は、プロセッサレジスタです。 レジスタの数とレジスタへのデータのロードに関連する遅延、およびメモリを使用する操作のキューのサイズのために、レジスタ内の各値を一度使用して、すべての実行可能ブロックが完全に占有されるほど十分に速くデータを送信することは不可能です。 データが実行可能ブロックの近くにある場合、キャッシュから排出されるか、レジスタから削除される前に、このデータを再利用することをお勧めします。 一部の変数はレジスタ変数としてのみ存在し、メインメモリに保存されることはありません。 コンパイラは、大文字と小文字を区別する場合にのみ変数を使用する方が適切な場合を完全に認識するため、C / C ++でregisterキーワードを使用することは推奨されません。 コンパイラ自体は最適化の可能性を十分に認識しており、 registerキーワードを無視できます。
開発者はコードを分析し、データがどのように使用され、どのくらいの期間存在する必要があるかを理解する必要があります。 「一時変数を作成する必要がありますか?」、「一時配列を作成する必要がありますか?」、「非常に多くの一時変数を保存する必要がありますか?」 生産性を向上させるプロセスでは、パフォーマンスメトリックを収集し、コードの実行にかなりの時間が費やされるモジュールまたはコードブランチへのデータの近似に集中する必要があります。 パフォーマンスデータを取得するための一般的なプログラムには、Intel VTune Amplifier XE、gprof、およびTau *が含まれます。
データの使用と再利用
行列乗算の例は、この段階を理解するのに最適です。 3つの正方n×n行列の行列乗算A = A + B * Cは、次に示すように、3つの単純なネストされたforループで表すことができます。
for (i=0;i<n; i++) // line 136 for (j = 0; j<n; j++) // line 137 for (k=0;k<n; k++) // line 138 A[i][j] += B[i][k]* C[k][j] ; // line 139
この順序の主な問題は、行列の縮小操作が含まれていることです(行138および139)。 行139の左側は単一の値です。 コンパイラは、138行目でサイクルを部分的に拡張し、SIMDレジスタを最大限に満たし、要素BおよびCから4または8個のピースを形成するには、これらのピースを1つの値に追加する必要があります。 4個または8個を1つの位置に追加することは、並列計算パフォーマンスを使用せず、最大の効率ですべてのSIMDレジスタを使用しないキャスト操作です。 キャスト操作を最小化または完全に排除することにより、並列処理のパフォーマンスを改善できます。 ループ内の行の左側に値が1つある場合、これはキャストの可能性を示しています。 行137の1回の繰り返しのデータアクセスパスを図4に示します。 2(i、j = 2)。

図2.合理化。 行列Aの単一の値
場合によっては、並べ替え操作を使用してキャストを削除できます。 2つの内部サイクルを交換する順序を検討してください。 浮動小数点演算の数は同じままです。 ただし、キャスト操作(行の左側の値を合計する)は除外されるため、プロセッサはすべてのSIMD実行可能ブロックとレジスタを使用できます。 これにより、生産性が大幅に向上します。
for (i=0;i<n; i++) // line 136 for (k = 0; k<n; k++) // line 137new for (j=0;j<n; j++) // line 138new a[i][j] += b[i][k]* c[k][j] ; // line 139
この後、要素AおよびCへの隣接アクセス。

図3.更新された隣接順序
初期順序ijkはスカラー乗算法です。 2つのベクトルのスカラー乗算を使用して、行列Aの各要素の値を計算します。次数ikjは、saxpy(単精度のA * X + Y)またはdaxpy(倍精度のA * X + Y)の演算です。 あるベクトルと定数の積は、別のベクトルに加算されます。 スカラー積とA * X + Y演算の両方がレベル1 BLASプロシージャです。 注文ikjでは、キャストは不要です。 行列Cの行のサブセットは、行列Bのスカラー値で乗算され、行列Aの行のサブセットに追加されます(コンパイラは、使用されるSIMDレジスタのサイズに応じてサブセットのサイズを決定します-SSE4、AVXまたはAVX512)。 137newサイクルの1回の繰り返しに対するメモリアクセスは、上記の図に示されています。 3(再びi、j = 2)。
スカラー乗算のキャストの例外は、パフォーマンスの大幅な向上です。 O2最適化レベルでは、Intelコンパイラーとgcc *の両方が、SIMDレジスターと実行可能ブロックを使用してベクトル化コードを作成します。 さらに、インテル®コンパイラーはjループとkループを自動的に交換します。 これは、コンパイラの最適化レポートで確認できます。最適化レポートは、 opt-reportコンパイラオプション(Linuxでは-qopt-report )を使用して取得できます。 最適化レポートは、デフォルトではファイルfilename.optrptに出力されます。 この場合、最適化レポートには次のテキストフラグメントが含まれます。
LOOP BEGIN at mm.c(136,4) remark #25444: Loopnest Interchanged: ( 1 2 3 ) --> ( 1 3 2 )
レポートは、並べ替えられたサイクルがベクトル化されたことも示しています。
LOOP BEGIN at mm.c(137,7) remark #15301: PERMUTED LOOP WAS VECTORIZED LOOP END
gccコンパイラ(バージョン4.1.2-55)は、ループを自動的に並べ替えません。 開発者は順序の変更に注意する必要があります。
ブロックサイクルにより、パフォーマンスがさらに向上します。 これにより、データの再利用が容易になります。 上記の表現(図3)では、中間サイクルの各反復で、長さn(およびスカラー値)の2つのベクトルが参照され、これら2つのベクトルの各要素は1回だけ使用されます。 nの値が大きい場合、ベクトルの各要素が中間ループの各反復の間にキャッシュからプッシュされる可能性があります。 サイクルをロックしてデータを再利用すると、パフォーマンスが再び向上します。
コードの最後のバージョンでは、サイクルjとkが並べ替えられ、ロックが適用されます。 コードは、 blockSizeのサイズの行列またはブロックのサブセットで実行されます 。 この単純な例では、 blockSizeはnコードの倍数です。
for (i = 0; i < n; i+=blockSize) for (k=0; k<n ; k+= blockSize) for (j = 0 ; j < n; j+=blockSize) for (iInner = i; iInner<i+blockSize; iInner++) for (kInner = k ; kInner<k+blockSize; kInner++) for (jInner = j ; jInner<j+blockSize ; jInner++) a[iInner,jInner] += b[iInner,kInner] * c[kInner, jInner]
このモデルでは、サイクルjの1つの反復からデータにアクセスすると、次のようになります。
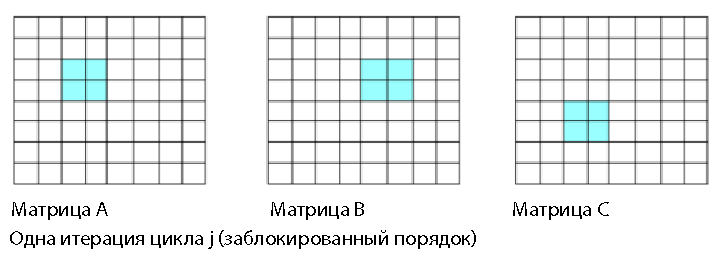
図4.ブロックモデルの表示
ブロックサイズが正しく選択されている場合、3つの内部ループの動作中に各ブロックがキャッシュ(および場合によってはSIMDレジスタ内)に残ると想定できます。 行列A、B、およびCの各要素は、SIMDレジスタから削除されるか、キャッシュから強制的に削除される前に、 blockSizeに等しい回数使用されます。 この場合、データの再利用はblockSizeに等しい回数だけ増加します 。 小さな行列を使用する場合、ブロックを使用しても実際にはゲインが得られません。 マトリックスのサイズが大きくなるほど、パフォーマンスの向上が大きくなります。
以下の表は、異なるコンパイラーを搭載したシステムで測定されたパフォーマンスの関係を示しています。 Intelコンパイラは137行目と138行目のループを自動的にスワップすることに注意してください。したがって、Intelコンパイラのパフォーマンスは、ijkとikjの順序で実質的に同じです。 これにより、インテル®コンパイラーの基本パフォーマンスもはるかに高いため、ベースと比較した場合の速度の向上は少ないようです。
| ご注文 | マトリックス/ブロックサイズ | Gcc * 4.1.2 -O2、ベースラインを超える速度/パフォーマンスの向上 | Intel 16.1-O2コンパイラ、ベースラインを超える速度/パフォーマンスの改善 |
|---|---|---|---|
| ijk | 1600 | 1(基本レベル) | 12.32 |
| ikj | 1600 | 6.25 | 12.33 |
| IKJブロック | 1600/8 | 6.44 | 8.44 |
| ijk | 4000 | 1(基本レベル) | 6.39 |
| ikj | 4000 | 6.04 | 6.38 |
| IKJブロック | 4000/8 | 8.42 | 10.53 |
示されているサンプルコードは単純であり、両方のコンパイラがSIMD命令を生成します。 これは廃止されたgccコンパイラです。ここでは、コンパイラのパフォーマンスを比較するのではなく、キャストされるデータが並列処理される場合でも、操作とキャストの順序の影響を示すために使用されます。 多くのループはより複雑であり、コンパイラーは並列化の可能性を認識できません。 したがって、開発者は、完了するまでに最も時間がかかるコードの部分を調べ、コンパイラレポートを表示して、コンパイラが最適化を適用したかどうか、または個別に適用する必要があるかどうかを確認することをお勧めします。 また、データ量が大きくなりすぎた場合にデータをブロックすることの重要性にも注意してください。 2つのマトリックスのうち小さい方の場合、パフォーマンスは向上しません。 より大きなマトリックスの場合、生産性が大幅に向上します。 したがって、開発者はブロッキングを適用する前に、データとキャッシュの相対的なサイズを考慮する必要があります。 いくつかのネストされたループと対応する境界を追加することにより、開発者は元のコードに比べて2〜10倍の生産性の向上を達成できます。 これは、非常に合理的な労力で達成される生産性の大幅な向上です。
最適化されたライブラリの使用
ご存知のように、完璧に制限はありません。 ブロックコードは依然として最速では動作しません。IntelMath Kernel Library(Intel MKL)などの最適化されたLAPACKライブラリのBLAS DGEMMレベル3プロシージャを使用して高速化できます。 通常の線形代数およびフーリエ変換の場合、Intel Math Kernel Libraryなどの最新のライブラリは、単純なブロック化や並べ替えよりも効率的な最適化を提供します。 開発者は、可能な限りこのような最適化されたライブラリを使用することをお勧めします。
行列乗算用のそのようなライブラリがありますが、最適化されたライブラリは、ブロッキングを使用してパフォーマンスを改善できるすべての状況に対して存在するわけではありません。 行列乗算は、最適化の原理を説明する便利な例です。 この原理は、有限差分パターンにも適しています。
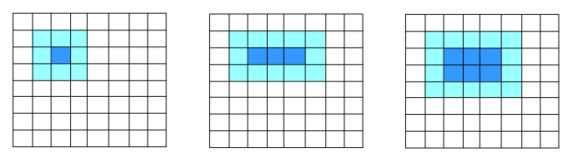
図5.ブロックモデルの2次元表現
単純な9ポイントパターンは、以下に示す強調表示されたブロックを使用して、中央ブロックの値を更新します。 1つの広告申込情報を更新するには、9つの値が使用されます。 隣接する要素を更新すると、これらの値のうち6つが再び使用されます。 コードが示されている順序で機能する場合、動作は隣接する図に示されているものと同様になります。3つの位置を更新するために15の値が使用されます。 さらに、この比率は徐々に1:3に近づいています。
図に示すように、データを2次元ブロックに入れると、 5、その後、6つの位置を更新するために、20個の値が使用され、2つのブロックのレジスタに配置されます。 比率は1:2に近づきます。
Cedric Andreolli による優れた記事「 3次元有限差分(3DFD)等方性コード(ISO)を最適化するための8つの方法」で、有限差分手法に精通することをお勧めします。 この記事では、ブロッキングだけでなく、他のメモリ最適化手法についても説明します。
おわりに
まとめると。 この記事では、開発者がプログラムに適用できる3つの例を示します。 まず、並列化キャストを回避するために操作を合理化します。 次に、データの再利用オプションを見つけ、ブロック構造をネストされたループに適用して、データの再利用をサポートします。 場合によっては、これにより生産性が2倍になります。 第三に、可能な限り最適化されたライブラリを使用します。 通常の開発者が並べ替えを使用して受信するコードよりも大幅に高速です。
完全なコードはこちらからダウンロードできます 。
第2部では、SIMDレジスタだけでなく、複数のコアでの負荷の並列化について説明します。 これに加えて、構造の偽共有と配列について説明します。