Habréおよび当サイトの分析セクションでは、金融市場の動向とその行動に関する戦略について多くのことを書いています。 非常に多くの場合、金融モデルは、何らかの形で投機的な結論に基づいて構築されます。 そして、モデルがそのようなデータにどの程度依存するかは、その使用の適合性に依存します。 この指標は、リスクモデルを使用して計算できます。
Turing FinanceのWebサイト作成者であり、NMRQLヘッジファンドのアナリストであるStuart Reedは、金融モデルを使用した場合に起こりうるリスクの分析に関する興味深い記事を公開しました。 この資料では、リスクの発生に影響するいくつかの要因、つまりモデルを使用した場合の金銭的損失の確率について説明します。 この作業の要点をご紹介します。
偽施設
財務モデルの中心には、いくつかの仮定があります。 したがって、モデルを構築するとき、タスクを解決するのにモデルを不適切にするような仮定を避けることが重要です。 「オッカムのカミソリ」を忘れてはならず、エンティティを不必要に増やしてはいけません。 このルールは、機械学習をマスターするときに特に重要です。 この場合、この原則は次のように解釈できます。予測精度が等しい2つのモデルから選択できる場合、使用するパラメーターの数が少ない方が効果的です。
これは、「単純なモデルが複雑なモデルよりも優れている」という意味ではありません。 これは、危険な誤解の1つです。 主な条件は、予測の等価性です。 モデルの単純さについてではありません。 金融で複雑なコンピューティングテクノロジーを使用すると、どのモデルも難解で洗練されたものになりますが、同時により現実的になります。
偽施設には3つの種類があります。 これらの仮定は、通常は信仰に基づいて行われているため、モデルが完全に役に立たないと言う人はいません。 ポイントは、その非効率のリスクがあるということです。
1.直線性
線形性は、任意の2つの変数間の関係がグラフの直線を介して表現できるという仮定です。 相関のほとんどは2つの変数の線形比率であるため、このビューは財務分析に深く組み込まれています。
つまり、多くの人は当初、比率は線形であるべきだと確信していますが、実際には相関は非線形である場合があります。 そのようなモデルは、小規模な予測には有効かもしれませんが、すべての多様性をカバーするわけではありません。 別の方法は、非線形動作を想定することです。 この場合、モデルは記述されたシステムの複雑さや一貫性を完全にカバーしていない可能性があり、精度が不足している可能性があります。
つまり、非線形の関係を指定すると、線形測定では関係をまったく特定できないか、安定性と強度が過大評価されます。 ここで問題は何ですか?
ポートフォリオ管理では、多様化の利点は、選択した資産の履歴相関マトリックスの使用に基づいています。 2つの資産間の関係が非線形である場合(一部のデリバティブで発生するように)、相関はゲインを過大評価または過小評価します。 この状況では、ポートフォリオのリスクは予想よりも少なくなるか、または大きくなります。 会社が必要に応じて資本を予約し、異なるリスク要因間の線形関係を仮定すると、予約する必要がある資本の量にエラーが発生します。 ストレステストは、企業の実際のリスクを反映していません。
さらに、2つのデータクラス間の関係が非線形であるモデル分類の開発中に関係する場合、アルゴリズムは誤ってそれらを1つのデータクラスとみなす可能性があります。 線形分類器は、非線形データを処理することを学ぶことができます。そのためには、カーネルでトリックを使用する必要があります-スカラー積から任意のカーネルへの移行。
2.定常性
定常性の考えの意味は、金融モデルを作成するトレーダーが、それが抽出された変数または分布が時間的に一定であると確信しているということです。 多くの場合、定常性は完全に合理的な仮定です。 たとえば、「重い」定数が日々大きく変わることはほとんどありません。 それが定数である理由です。 しかし、適応システムである金融市場では、事態は少し混乱します。
モデルのリスクを評価する場合、相関、ボラティリティ、およびリスク要因が定常的でない可能性があることに留意する必要があります。 それらのそれぞれについて、反対の信念は彼ら自身のトラブルにつながります。
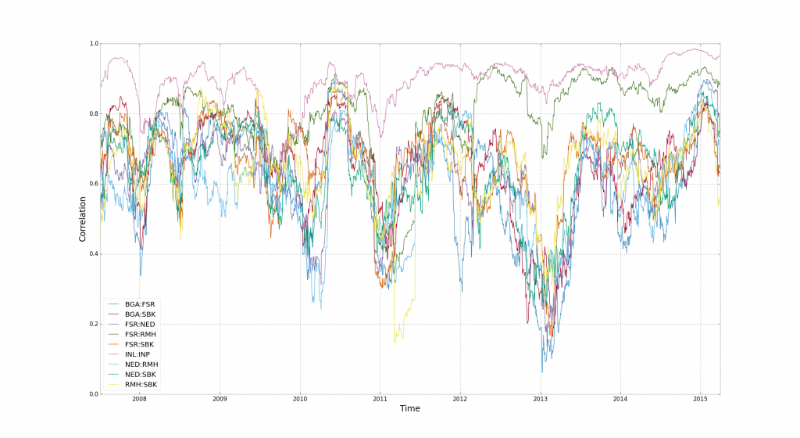
相関関係により、上に書かれています。 ここで、その定常性の採用は、ポートフォリオの多様化のリスクをゆがめます。 相関関係は不安定であり、市場の反転時に「リセット」されます。
このチャートは、南アフリカの15の財務指標の相関挙動を示しています。 ここで、相関が壊れる時間間隔を見ることができます。 スチュアートリードによると、それはすべて財務レバレッジ 、 レバレッジに関するものです。さまざまな業界の企業の株式は、それらを取引するトレーダーによって「接続」されています。
ボラティリティは、ほとんどの場合、定常変数で表されます。 特に、確率論的アプローチが株価モデルで使用される場合。 ボラティリティは、証券からの収入が時間とともにどの程度変化するかを決定する基準です。 たとえば、デリバティブの場合、ボラティリティが高いほど価格が高くなると考えられています。 デリバティブが価値を失う可能性が高いためです。 モデルがボラティリティを過小評価している場合、ほとんどの場合、デリバティブの価値が過小評価されています。
確率過程はブラックショールズモデルの根底にあり、ブラウン運動の原理に基づいています。 このモデルは、時間とともに一定のボラティリティを意味します。 CIRインジケーター (Cox-Ingerosoll-Rossモデル)を使用してランダムなボラティリティを決定し、このモデルとHestonモデルで可能な利益の範囲の違いを感じてください。
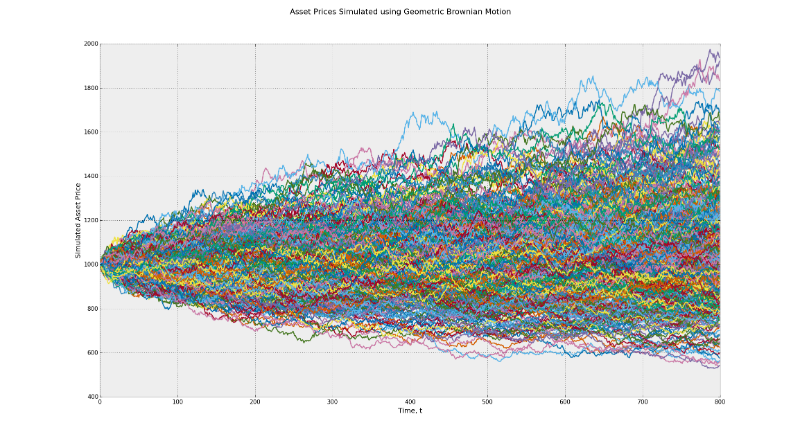
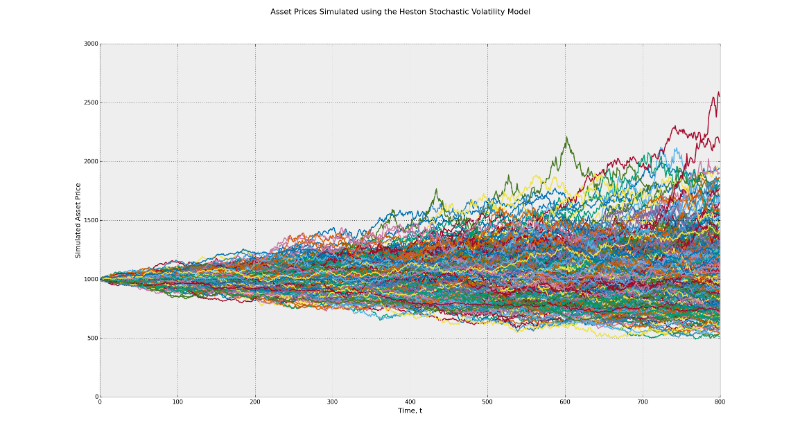
最初のグラフでは、潜在的な最終値の範囲は500〜2000です。2番目の場合、範囲は500〜2500です。これは、ボラティリティの影響の例です。 さらに、多くのトレーダーは、戦略のバックテストを実施する際に、デフォルトでリスク要因の恒常性の考え方を受け入れます。 現実には、市場の状態が真剣に変化すると、勢い、平均値の戻りなどの要因が異なる影響を与える可能性があります。
以下のGIFは、動的分布と、経時的な分布の変化に遺伝的アルゴリズムがどのように適応するかを示しています。 リスク管理を実装する場合、このような動的アルゴリズムを使用する必要があります。
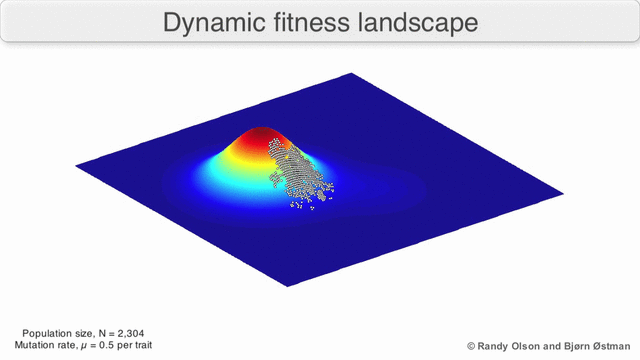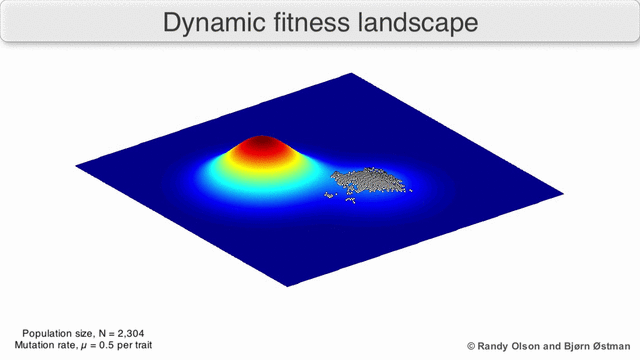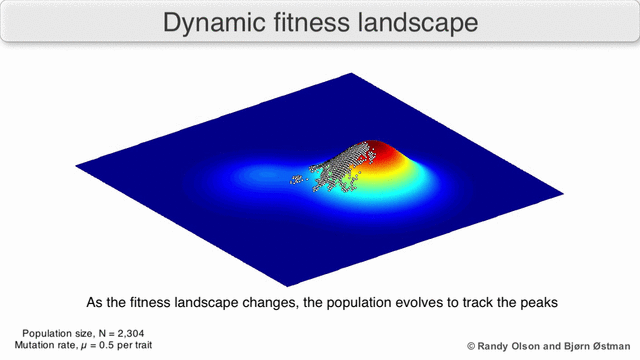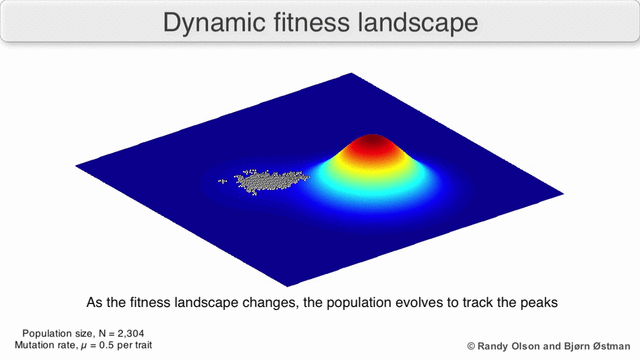
3.正常性
正規性の仮定は、ランダム変数が正規(ガウス)分布の原則に従うことを意味します。 これはいくつかの理由で便利です。 任意の数の正規分布の組み合わせは、最終的に正規分布になります。 また、数式を使用して管理するのも簡単です。つまり、数学者は、複雑な問題を解決するための基礎に基づいて調和の取れたシステムを作成できます。
キャッチは、デルタ正規アプローチを含む多くのモデルが、市場ポートフォリオのリターンにも正規分布があることを示唆していることです。 現在の市場では、収益性には過剰と長いテールがあります。 これは、多くの企業がテールリスクの影響を過小評価していることを意味し、市場危機を考慮(または考慮しない)しています。
一例は、1987年の市場の崩壊です。 その年の10月19日、世界中のほとんどの株式市場は20%以上を失いました。 すべてが正規分布に従う通常の世界では、これは不可能であることは注目に値します。
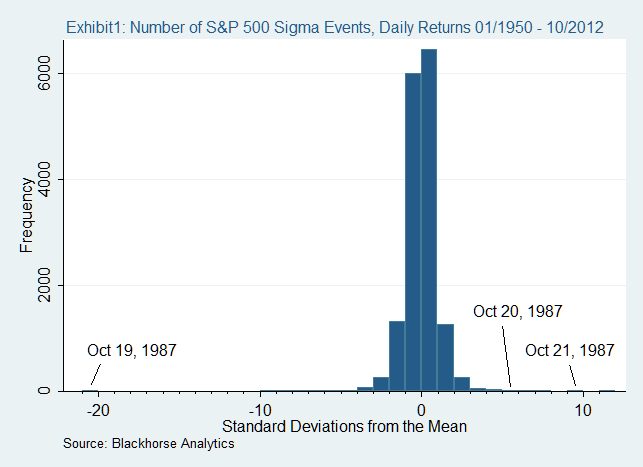
統計的歪み
統計は嘘をついている。 誰の利益も満たさない場合。 最終的に、それはすべてあなたがそれを計算する方法に依存します。 以下では、結果に影響する統計の歪みの最も一般的な原因について説明します。
4.サンプリングエラー
多くの場合、サンプリングエラーは統計結果の歪みにつながります。 簡単に言えば、サンプルで表されるパターンの確率は、実際のグループでの確率に直接依存します。 テンプレートを選択するにはいくつかの方法があります。 最も一般的なのは、ランダムサンプリング、体系的サンプリング、層別サンプリング、クラスターサンプリングです。
単純なランダムサンプルでは、各パターンはパターンの一部になる可能性が等しくあります。 これはすべて、スタディエリアに1つのクラスのパターンが含まれる場合に適しています。 その後、簡単なサンプリングが高速で効率的です。 パターンのいくつかのクラスが利用可能な場合、別の状況が発生し、それぞれの確率はこれらのクラスに分散します。 この場合、サンプルは代表的ではなく、最終結果は歪められます。
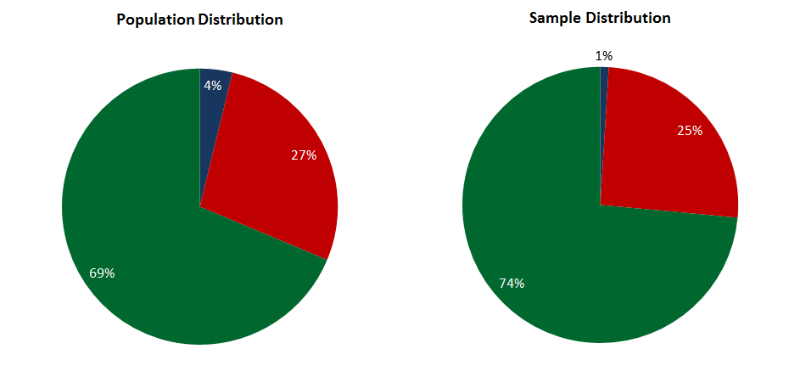
階層化されたサンプルは、特定の数のパターンがその重みに従って各クラスから選択される場合、ラベル付きデータに適している場合があります。 たとえば、3つのクラス-A、B、Cに属するパターンを指定しました。それらの間のパターンの分布は、それぞれ5%、70%、25%です。 つまり、100パターンのサンプルには、クラスA、70-Bおよび25-Cの5パターンが含まれます。このサンプルは代表的なものですが、ラベル付きデータにのみ使用できます。
マルチステージまたはクラスターサンプリングにより、タグなしデータへの階層化アプローチが可能になります。 最初の段階で、データはクラスターアルゴリズム(k-meansまたはantアルゴリズム)を使用してクラスに分割されます。 第2段階では、各クラスの重みと値に比例して選択が行われます。 ここでは、以前の方法の欠点は克服されていますが、結果はクラスターアルゴリズムの有効性に依存し始めています。
また、dimensionの悪態もあります。これは、使用されているサンプリング手法に依存しません。 つまり、代表的なサンプルに必要なパターンの数は、これらのパターンの属性とともに指数関数的に増加します。 特定のレベルでは、代表的なサンプルを作成することは実際上不可能になります。これは、歪みのない統計結果を取得することを意味します。
5.フィットエラー
いわゆるオーバーフィッティングは、モデルが基本的な統計的関係を確立する代わりに、データセット内のノイズ(ランダム性)を記述するときに発生します。 サンプル内のパフォーマンスは、サンプル外では素晴らしいものになります-いいえ。 このようなモデルは通常、一般化のレベルが低いと言われています。 過剰適合は、モデル自体が複雑すぎる(または学習戦略が単純すぎる)場合に発生します。 この場合の複雑さと重さは、モデルで構成できるパラメーターの1つです。
量子フォーラムでは、再フィッティングがどのように発生するかについての多くの説明を見つけることができます。 スチュアートリードは、量子が複雑なラディットの使用に対する態度を示すために、この間違いを故意に犯したと確信しています。 たとえば、取引におけるディープニューラルネットワーク。 一部の人は、単純な線形回帰が複雑なモデルを超えると言っています。 これらの人々は、モデルが単純すぎて統計的知恵を学ぶことができない場合、アンダーフィッティングの影響を考慮しません。
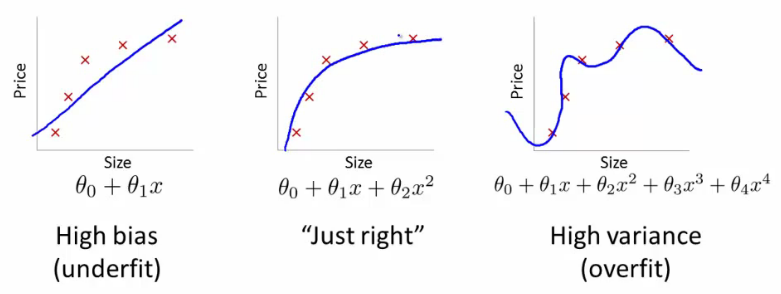
しかし、いずれにせよ、モデルがどんな統計的エラーを犯しても、トレーニング戦略に大きく依存します。 多くの研究者は、 交差検証手法を使用して過剰適合を回避しています 。 彼女は、データセットを代表的なセクションに分割します:トレーニング、テスト、および検証(結果の確認)。 データは、3つのセクションすべてを個別に実行します。 モデルに過剰適合の兆候が見られる場合、そのトレーニングは中断されます。 このアプローチの唯一の欠点:独立した検証には大量のデータが必要です。
6.耐久性
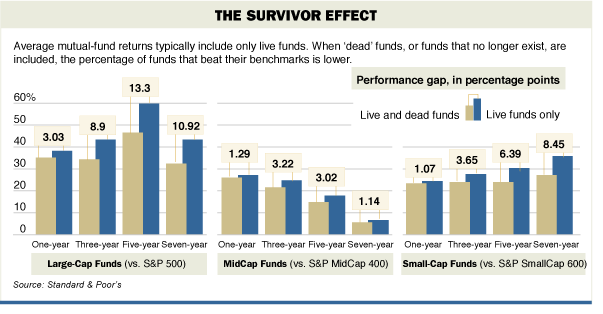
特定の期間にのみ存在する統計分析データに使用するのは間違いです。 この典型的な例は、ヘッジファンドの収益データの使用です。 過去30年間に、多くの資金が急増または崩壊しました。 ヘッジファンドのデータを使用する場合、現在機能しているもののみを使用する、とリード氏は述べた。 この場合、失敗につながるリスクは除外します。 この指標はサバイバー効果と呼ばれます。 仕組みを図に示します。
7.変数のスキップ
1つ以上の重要なカジュアル変数が省略されると、別のエラーが発生します。 モデルは、他の変数の値を過大評価することにより、欠落している変数を誤って補正する場合があります。 これは、含まれている変数が含まれていない変数と相関する場合に特に重要です。 最悪の場合、誤った予測を受け取ります。
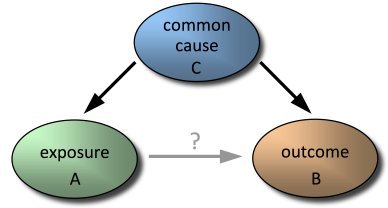
どの独立変数が予測の正確性に大きく貢献できるかを理解することは容易ではありません。 最も論理的な方法は、従属変数に関するほとんどの偏差を説明する変数を見つけることです。 このアプローチは、 ベストサブセットと呼ばれます。これは、従属変数への応答を最適に予測する変数のサブセットの検索です。 別の方法は、従属変数の偏差の原因となる固有ベクトル(利用可能な変数の線形結合)を見つけることです。 通常、このアプローチは主成分分析(PCA)と組み合わせて使用されます。 彼の問題は、彼がデータをオーバーマッチできることです。 最後に、モデルに変数を複数回追加できます。 このアプローチは、多重線形回帰および適応ニューラルネットワークで使用されます。
おわりに
何らかの歪みを生じさせないモデルを作成することはほとんど不可能です。
戦略の開発に関与するトレーダーが上記のエラーを回避できたとしても、人的要因は依然として残っています。 誰かがモデルを使用するからです-たとえそれがその作者であっても。
ただし、ここで重要な点は、すべての欠点と不正確さにもかかわらず、一部のモデルは依然として有用であり、他のモデルよりもうまく機能するということです。